Double Fault'lar
Çevrilmiş İçerik: Bu, Double Faults adlı gönderinin topluluk tarafından yapılmış bir çevirisidir. Eksik, güncel olmayan veya hata içeriyor olabilir. Lütfen herhangi bir sorunu bildirin!
Translation by @rhotav.
Bu yazı, CPU bir exception handler’ı çağırmayı başaramadığında meydana gelen double fault exception’ını ayrıntılı olarak inceliyor. Bu exception’ı işleyerek, sistem sıfırlamasına neden olan ölümcül triple fault’lardan kaçınıyoruz. Triple fault’ları her durumda önlemek için, double fault’ları ayrı bir kernel stack’inde yakalamak üzere bir Interrupt Stack Table da kuruyoruz.
Bu blog GitHub üzerinde açık biçimde geliştirilmektedir. Herhangi bir sorun veya sorunuz varsa lütfen orada bir issue açın. Ayrıca sayfanın en altına yorum bırakabilirsiniz. Bu yazının eksiksiz kaynak kodu post-06 dalında bulunabilir.
İçindekiler
🔗Double Fault Nedir?
Basit terimlerle, bir double fault, CPU bir exception handler’ı çağırmayı başaramadığında meydana gelen özel bir exception’dır. Örneğin, bir page fault tetiklendiğinde ancak Interrupt Descriptor Table’de (IDT) kayıtlı bir page fault handler’ı olmadığında meydana gelir. Yani, exception’ları olan programlama dillerindeki yakala-tümünü (catch-all) bloklarına biraz benzer; örneğin C++’taki catch(...) veya Java ya da C#’taki catch(Exception e) gibi.
Bir double fault, normal bir exception gibi davranır. 8 vektör numarasına sahiptir ve onun için IDT’de normal bir handler fonksiyonu tanımlayabiliriz. Bir double fault handler’ı sağlamak gerçekten önemlidir, çünkü bir double fault işlenmezse ölümcül bir triple fault meydana gelir. Triple fault’lar yakalanamaz ve çoğu donanım buna bir sistem sıfırlamasıyla tepki verir.
🔗Bir Double Fault Tetiklemek
Bir handler fonksiyonu tanımlamadığımız bir exception’ı tetikleyerek bir double fault’a yol açalım:
// src/main.rs içinde
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// bir page fault tetikle
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// önceki gibi
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}Geçersiz 0xdeadbeef adresine yazmak için unsafe kullanıyoruz. Bu sanal adres, sayfa tablolarında fiziksel bir adrese eşlenmemiştir, bu yüzden bir page fault meydana gelir. IDT’mizde bir page fault handler’ı kaydetmedik, bu yüzden bir double fault meydana gelir.
Kernel’imizi şimdi başlattığımızda, sonsuz bir önyükleme döngüsüne (boot loop) girdiğini görüyoruz. Önyükleme döngüsünün nedeni şudur:
- CPU
0xdeadbeef’e yazmaya çalışır, bu da bir page fault’a neden olur. - CPU IDT’deki karşılık gelen girdiye bakar ve hiçbir handler fonksiyonunun belirtilmediğini görür. Böylece page fault handler’ını çağıramaz ve bir double fault meydana gelir.
- CPU double fault handler’ının IDT girdisine bakar, ancak bu girdi de bir handler fonksiyonu belirtmez. Böylece bir triple fault meydana gelir.
- Bir triple fault ölümcüldür. QEMU buna çoğu gerçek donanım gibi tepki verir ve bir sistem sıfırlaması yapar.
Yani bu triple fault’u önlemek için, ya page fault’lar için bir handler fonksiyonu ya da bir double fault handler’ı sağlamamız gerekir. Triple fault’lardan her durumda kaçınmak istiyoruz, bu yüzden işlenmemiş tüm exception tipleri için çağrılan bir double fault handler’ıyla başlayalım.
🔗Bir Double Fault Handler’ı
Bir double fault, hata koduna sahip normal bir exception’dır, bu yüzden breakpoint handler’ımıza benzer bir handler fonksiyonu belirtebiliriz:
// src/interrupts.rs içinde
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // yeni
idt
};
}
// yeni
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
}Handler’ımız kısa bir hata mesajı yazdırır ve exception stack frame’inin dökümünü alır. Double fault handler’ının hata kodu her zaman sıfırdır, bu yüzden onu yazdırmak için bir neden yoktur. Breakpoint handler’ından bir fark, double fault handler’ının ıraksayan (diverging) olmasıdır. Bunun nedeni, x86_64 mimarisinin bir double fault exception’ından geri dönmeye izin vermemesidir.
Kernel’imizi şimdi başlattığımızda, double fault handler’ının çağrıldığını görmeliyiz:
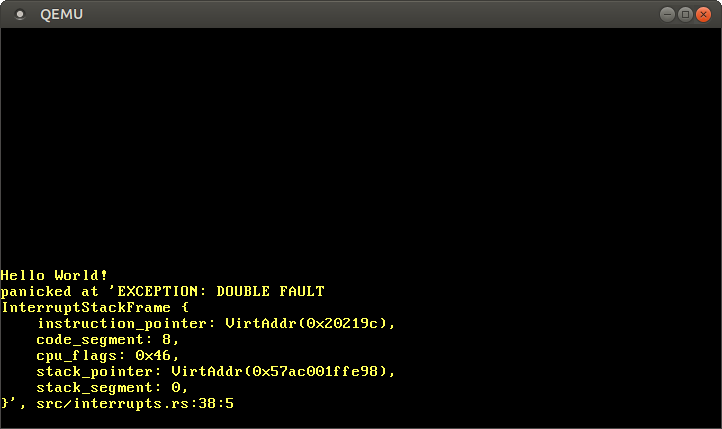
İşe yaradı! Bu sefer olan şuydu:
- CPU
0xdeadbeef’e yazmaya çalışır, bu da bir page fault’a neden olur. - Önceki gibi, CPU IDT’deki karşılık gelen girdiye bakar ve hiçbir handler fonksiyonunun tanımlanmadığını görür. Böylece bir double fault meydana gelir.
- CPU – artık mevcut olan – double fault handler’ına atlar.
CPU artık double fault handler’ını çağırabildiği için, triple fault (ve önyükleme döngüsü) artık meydana gelmez.
Bu oldukça basitti! Peki neden bu konu için koca bir yazıya ihtiyacımız var? Şöyle ki, artık double fault’ların çoğunu yakalayabiliyoruz, ancak mevcut yaklaşımımızın yeterli olmadığı bazı durumlar var.
🔗Double Fault’ların Nedenleri
Özel durumlara bakmadan önce, double fault’ların tam nedenlerini bilmemiz gerekiyor. Yukarıda oldukça belirsiz bir tanım kullandık:
Bir double fault, CPU bir exception handler’ı çağırmayı başaramadığında meydana gelen özel bir exception’dır.
“Çağırmayı başaramadığında” tam olarak ne anlama geliyor? Handler mevcut değil mi? Handler takas yoluyla diske mi alındı (swapped out)? Peki bir handler kendisi exception’a neden olursa ne olur?
Örneğin, şu durumlarda ne olur:
- bir breakpoint exception’ı meydana gelir, ancak karşılık gelen handler fonksiyonu swapped out’tur?
- bir page fault meydana gelir, ancak page fault handler’ı swapped out’tur?
- bir divide-by-zero handler’ı bir breakpoint exception’ına neden olur, ancak breakpoint handler’ı swapped out’tur?
- kernel’imiz stack’ini taşırır ve guard page’e isabet edilir?
Neyse ki, AMD64 kılavuzunun (PDF) tam bir tanımı var (Bölüm 8.2.9’da). Ona göre, “bir double fault exception’ı, önceki (ilk) bir exception handler’ının işlenmesi sırasında ikinci bir exception meydana geldiğinde meydana gelebilir”. “Gelebilir” önemlidir: Yalnızca exception’ların çok belirli kombinasyonları bir double fault’a yol açar. Bu kombinasyonlar şunlardır:
Yani, örneğin bir divide-by-zero fault’unu takip eden bir page fault sorun değildir (page fault handler’ı çağrılır), ancak bir divide-by-zero fault’unu takip eden bir general-protection fault bir double fault’a yol açar.
Bu tablonun yardımıyla, yukarıdaki soruların ilk üçünü yanıtlayabiliriz:
- Bir breakpoint exception’ı meydana gelir ve karşılık gelen handler fonksiyonu swapped out’sa, bir page fault meydana gelir ve page fault handler’ı çağrılır.
- Bir page fault meydana gelir ve page fault handler’ı swapped out’sa, bir double fault meydana gelir ve double fault handler’ı çağrılır.
- Bir divide-by-zero handler’ı bir breakpoint exception’ına neden olursa, CPU breakpoint handler’ını çağırmaya çalışır. Breakpoint handler’ı swapped out’sa, bir page fault meydana gelir ve page fault handler’ı çağrılır.
Aslında, IDT’de handler fonksiyonu olmayan bir exception durumu bile bu şemayı izler: Exception meydana geldiğinde, CPU karşılık gelen IDT girdisini okumaya çalışır. Girdi 0 olduğundan ve bu geçerli bir IDT girdisi olmadığından, bir general protection fault meydana gelir. General protection fault için de bir handler fonksiyonu tanımlamadık, bu yüzden başka bir general protection fault meydana gelir. Tabloya göre, bu bir double fault’a yol açar.
🔗Kernel Stack Taşması
Dördüncü soruya bakalım:
Kernel’imiz stack’ini taşırır ve guard page’e isabet edilirse ne olur?
Guard page, bir stack’in en altında bulunan ve stack taşmalarını tespit etmeyi mümkün kılan özel bir bellek sayfasıdır. Bu sayfa herhangi bir fiziksel frame’e eşlenmemiştir, bu yüzden ona erişmek, sessizce başka belleği bozmak yerine bir page fault’a neden olur. Bootloader, kernel stack’imiz için bir guard page kurar, bu yüzden bir stack taşması bir page fault’a neden olur.
Bir page fault meydana geldiğinde, CPU IDT’de page fault handler’ını arar ve interrupt stack frame’i stack’e push’lamaya çalışır. Ancak mevcut stack pointer hâlâ mevcut olmayan guard page’e işaret eder. Böylece ikinci bir page fault meydana gelir; bu da (yukarıdaki tabloya göre) bir double fault’a neden olur.
Yani CPU şimdi double fault handler’ını çağırmaya çalışır. Ancak bir double fault’ta CPU exception stack frame’ini de push’lamaya çalışır. Stack pointer hâlâ guard page’e işaret eder, bu yüzden üçüncü bir page fault meydana gelir; bu da bir triple fault’a ve bir sistem yeniden başlatmasına neden olur. Yani mevcut double fault handler’ımız bu durumda bir triple fault’u önleyemez.
Bunu kendimiz deneyelim! Sonsuza dek özyineleyen (recurse) bir fonksiyon çağırarak kolayca bir kernel stack taşmasına yol açabiliriz:
// src/main.rs içinde
#[unsafe(no_mangle)] // bu fonksiyonun adını parçalama (mangle etme)
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // her özyinelemede, dönüş adresi push'lanır
}
// bir stack taşması tetikle
stack_overflow();
[…] // test_main(), println(…) ve loop {}
}Bu kodu QEMU’da denediğimizde, sistemin yeniden bir önyükleme döngüsüne girdiğini görüyoruz.
Peki bu sorundan nasıl kaçınabiliriz? Exception stack frame’inin push’lanmasını atlayamayız, çünkü CPU’nun kendisi bunu yapar. Bu yüzden, bir double fault exception’ı meydana geldiğinde stack’in her zaman geçerli olduğundan bir şekilde emin olmamız gerekir. Neyse ki, x86_64 mimarisinin bu soruna bir çözümü var.
🔗Stack’leri Değiştirmek
x86_64 mimarisi, bir exception meydana geldiğinde önceden tanımlanmış, bilinen-iyi bir stack’e geçebilir. Bu geçiş donanım seviyesinde gerçekleşir, bu yüzden CPU exception stack frame’ini push’lamadan önce gerçekleştirilebilir.
Geçiş mekanizması bir Interrupt Stack Table (IST) olarak uygulanmıştır. IST, bilinen-iyi stack’lere işaret eden 7 işaretçiden oluşan bir tablodur. Rust benzeri sözde kod (pseudocode) ile:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}Her exception handler’ı için, karşılık gelen IDT girdisindeki stack_pointers alanı aracılığıyla IST’ten bir stack seçebiliriz. Örneğin, double fault handler’ımız IST’teki ilk stack’i kullanabilir. Sonra CPU, ne zaman bir double fault meydana gelse otomatik olarak bu stack’e geçer. Bu geçiş, herhangi bir şey push’lanmadan önce gerçekleşir ve triple fault’u önler.
🔗IST ve TSS
Interrupt Stack Table (IST), Task State Segment (TSS) adı verilen eski bir miras (legacy) yapının parçasıdır. TSS, 32-bit modda bir görev (task) hakkında çeşitli bilgi parçalarını (örneğin işlemci register durumu) tutardı ve örneğin donanımsal bağlam değiştirme (hardware context switching) için kullanılırdı. Ancak donanımsal bağlam değiştirme 64-bit modda artık desteklenmez ve TSS’nin biçimi tamamen değişmiştir.
x86_64’te, TSS artık göreve özgü hiçbir bilgi tutmaz. Bunun yerine iki stack tablosu tutar (IST bunlardan biridir). 32-bit ve 64-bit TSS arasındaki tek ortak alan, G/Ç portu izinleri bit eşlemine (I/O port permissions bitmap) işaretçidir.
64-bit TSS aşağıdaki biçime sahiptir:
| Alan | Tip |
|---|---|
| (ayrılmış) | u32 |
| Privilege Stack Table | [u64; 3] |
| (ayrılmış) | u64 |
| Interrupt Stack Table | [u64; 7] |
| (ayrılmış) | u64 |
| (ayrılmış) | u16 |
| I/O Map Base Address | u16 |
Privilege Stack Table, ayrıcalık seviyesi değiştiğinde CPU tarafından kullanılır. Örneğin, CPU kullanıcı modundayken (ayrıcalık seviyesi 3) bir exception meydana gelirse, CPU normalde exception handler’ını çağırmadan önce kernel moduna (ayrıcalık seviyesi 0) geçer. Bu durumda CPU, Privilege Stack Table’daki 0. stack’e geçerdi (çünkü 0 hedef ayrıcalık seviyesidir). Henüz hiç kullanıcı modu programımız yok, bu yüzden şimdilik bu tabloyu yok sayacağız.
🔗Bir TSS Oluşturmak
Interrupt stack table’ında ayrı bir double fault stack’i içeren yeni bir TSS oluşturalım. Bunun için bir TSS struct’ına ihtiyacımız var. Neyse ki, x86_64 crate’i kullanabileceğimiz bir TaskStateSegment struct’ını zaten içeriyor.
TSS’yi yeni bir gdt modülünde oluşturuyoruz (bu ad daha sonra anlam kazanacak):
// src/lib.rs içinde
pub mod gdt;
// src/gdt.rs içinde
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(&raw const STACK);
let stack_end = stack_start + STACK_SIZE as u64;
stack_end
};
tss
};
}lazy_static kullanıyoruz, çünkü Rust’ın const evaluator’ı bu başlatmayı derleme zamanında yapacak kadar henüz güçlü değil. 0. IST girdisinin double fault stack’i olduğunu tanımlıyoruz (başka herhangi bir IST indeksi de işe yarardı). Ardından, bir double fault stack’inin en üst adresini 0. girdiye yazıyoruz. En üst adresi yazıyoruz, çünkü x86’da stack’ler aşağı doğru büyür; yani yüksek adreslerden düşük adreslere doğru.
Henüz bellek yönetimi uygulamadık, bu yüzden yeni bir stack ayırmanın düzgün bir yolu yok. Bunun yerine, şimdilik stack deposu olarak bir static mut dizisi kullanıyoruz. Bunun değiştirilemez bir static değil, bir static mut olması önemlidir; çünkü aksi takdirde bootloader onu salt okunur bir sayfaya eşler. Bunu daha sonraki bir yazıda düzgün bir stack ayırmasıyla değiştireceğiz.
Bu double fault stack’inin, stack taşmasına karşı koruyan bir guard page’i olmadığını unutmayın. Bu, double fault handler’ımızda stack-yoğun hiçbir şey yapmamamız gerektiği anlamına gelir, çünkü bir stack taşması stack’in altındaki belleği bozabilir.
🔗TSS’yi Yüklemek
Artık yeni bir TSS oluşturduğumuza göre, CPU’ya onu kullanması gerektiğini söylemenin bir yoluna ihtiyacımız var. Ne yazık ki, bu biraz zahmetlidir, çünkü TSS (tarihsel nedenlerle) segmentasyon sistemini kullanır. Tabloyu doğrudan yüklemek yerine, Global Descriptor Table’a (GDT) yeni bir segment tanımlayıcısı eklememiz gerekir. Sonra TSS’mizi, ilgili GDT indeksiyle ltr komutunu çağırarak yükleyebiliriz. (Modülümüze gdt adını vermemizin nedeni budur.)
🔗Global Descriptor Table
Global Descriptor Table (GDT), paging fiilî standart haline gelmeden önce bellek segmentasyonu (memory segmentation) için kullanılan bir kalıntıdır. Ancak 64-bit modda hâlâ çeşitli şeyler için gereklidir; örneğin kernel/kullanıcı modu yapılandırması veya TSS yükleme gibi.
GDT, programın segment’lerini içeren bir yapıdır. Paging standart haline gelmeden önce, daha eski mimarilerde programları birbirinden yalıtmak için kullanılırdı. Segmentasyon hakkında daha fazla bilgi için, ücretsiz “Three Easy Pieces” kitabının aynı adlı bölümüne göz atın. Segmentasyon 64-bit modda artık desteklenmese de, GDT hâlâ vardır. Çoğunlukla iki şey için kullanılır: Kernel alanı ile kullanıcı alanı arasında geçiş yapmak ve bir TSS yapısını yüklemek.
🔗Bir GDT Oluşturmak
TSS static’imiz için bir segment içeren statik bir GDT oluşturalım:
// src/gdt.rs içinde
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.append(Descriptor::kernel_code_segment());
gdt.append(Descriptor::tss_segment(&TSS));
gdt
};
}Önceki gibi, yine lazy_static kullanıyoruz. Bir kod segmenti ve bir TSS segmenti olan yeni bir GDT oluşturuyoruz.
🔗GDT’yi Yüklemek
GDT’mizi yüklemek için, init fonksiyonumuzdan çağıracağımız yeni bir gdt::init fonksiyonu oluşturuyoruz:
// src/gdt.rs içinde
pub fn init() {
GDT.load();
}
// src/lib.rs içinde
pub fn init() {
gdt::init();
interrupts::init_idt();
}Artık GDT’miz yüklenmiş durumda (çünkü _start fonksiyonu init’i çağırıyor), ancak stack taşmasında hâlâ önyükleme döngüsünü görüyoruz.
🔗Son Adımlar
Sorun, GDT segmentlerinin henüz aktif olmamasıdır; çünkü segment ve TSS register’ları hâlâ eski GDT’den gelen değerleri içerir. Ayrıca double fault IDT girdisini, yeni stack’i kullanacak şekilde değiştirmemiz gerekir.
Özetle, aşağıdakileri yapmamız gerekir:
- Kod segmenti register’ını yeniden yükle: GDT’mizi değiştirdik, bu yüzden kod segmenti register’ı
cs’yi yeniden yüklemeliyiz. Bu gereklidir, çünkü eski segment seçicisi artık farklı bir GDT tanımlayıcısına (örneğin bir TSS tanımlayıcısına) işaret ediyor olabilir. - TSS’yi yükle: Bir TSS seçicisi içeren bir GDT yükledik, ancak yine de CPU’ya o TSS’yi kullanması gerektiğini söylememiz gerekiyor.
- IDT girdisini güncelle: TSS’miz yüklenir yüklenmez, CPU geçerli bir interrupt stack table’a (IST) erişir. Sonra double fault IDT girdimizi değiştirerek CPU’ya yeni double fault stack’imizi kullanması gerektiğini söyleyebiliriz.
İlk iki adım için, gdt::init fonksiyonumuzda code_selector ve tss_selector değişkenlerine erişmemiz gerekiyor. Bunu, onları yeni bir Selectors struct’ı aracılığıyla static’in parçası yaparak başarabiliriz:
// src/gdt.rs içinde
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.append(Descriptor::kernel_code_segment());
let tss_selector = gdt.append(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}Artık seçicileri, cs register’ını yeniden yüklemek ve TSS’mizi yüklemek için kullanabiliriz:
// src/gdt.rs içinde
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}Kod segmenti register’ını CS::set_reg kullanarak yeniden yüklüyor ve TSS’yi load_tss kullanarak yüklüyoruz. Fonksiyonlar unsafe olarak işaretlenmiştir, bu yüzden onları çağırmak için bir unsafe bloğuna ihtiyacımız var. Bunun nedeni, geçersiz seçiciler yükleyerek bellek güvenliğini bozmanın mümkün olabilmesidir.
Artık geçerli bir TSS ve interrupt stack table yüklediğimize göre, IDT’de double fault handler’ımız için stack indeksini ayarlayabiliriz:
// src/interrupts.rs içinde
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // yeni
}
idt
};
}set_stack_index metodu unsafe’tir, çünkü çağıranın, kullanılan indeksin geçerli olduğundan ve başka bir exception için zaten kullanılmadığından emin olması gerekir.
İşte bu kadar! Artık CPU, ne zaman bir double fault meydana gelse double fault stack’ine geçmeli. Böylece, kernel stack taşmaları dahil tüm double fault’ları yakalayabiliyoruz:
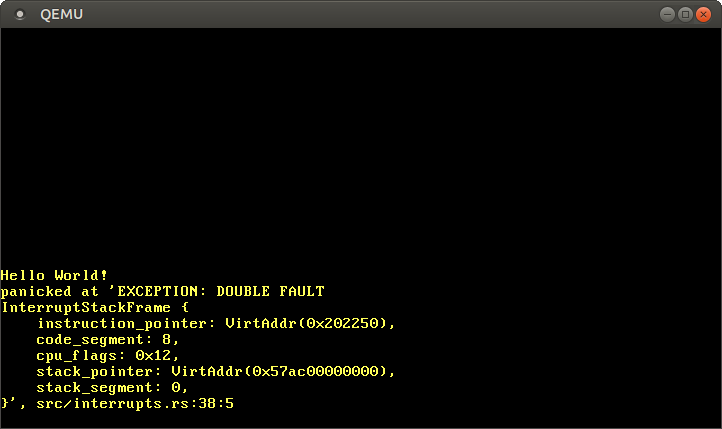
Bundan sonra bir triple fault’u bir daha asla görmememiz gerekir! Yukarıdakileri yanlışlıkla bozmadığımızdan emin olmak için, bunun için bir test eklemeliyiz.
🔗Bir Stack Taşması Testi
Yeni gdt modülümüzü test etmek ve double fault handler’ının bir stack taşmasında doğru şekilde çağrıldığından emin olmak için, bir entegrasyon testi ekleyebiliriz. Fikir, test fonksiyonunda bir double fault’a yol açmak ve double fault handler’ının çağrıldığını doğrulamaktır.
Minimal bir iskeletle başlayalım:
// tests/stack_overflow.rs içinde
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}panic_handler testimiz gibi, bu test de bir test harness’i olmadan çalışacak. Bunun nedeni, bir double fault’tan sonra çalıştırmaya devam edemememizdir, bu yüzden birden fazla test mantıklı değildir. Test için test harness’ini devre dışı bırakmak amacıyla, Cargo.toml dosyamıza aşağıdakini ekliyoruz:
# Cargo.toml içinde
[[test]]
name = "stack_overflow"
harness = falseArtık cargo test --test stack_overflow başarıyla derlenmeli. Test elbette başarısız oluyor, çünkü unimplemented makrosu panic yapıyor.
🔗_start’ı Uygulamak
_start fonksiyonunun uygulaması şöyle görünür:
// tests/stack_overflow.rs içinde
use blog_os::serial_print;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// bir stack taşması tetikle
stack_overflow();
panic!("Execution continued after stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // her özyinelemede, dönüş adresi push'lanır
volatile::Volatile::new(0).read(); // kuyruk özyineleme optimizasyonlarını önle
}Yeni bir GDT başlatmak için gdt::init fonksiyonumuzu çağırıyoruz. interrupts::init_idt fonksiyonumuzu çağırmak yerine, birazdan açıklanacak bir init_test_idt fonksiyonunu çağırıyoruz. Bunun nedeni, panic yapmak yerine bir exit_qemu(QemuExitCode::Success) yapan özel bir double fault handler’ı kaydetmek istememizdir.
stack_overflow fonksiyonu, main.rs’imizdeki fonksiyonla neredeyse aynıdır. Tek fark, fonksiyonun sonunda, kuyruk çağrısı eliminasyonu (tail call elimination) adı verilen bir derleyici optimizasyonunu önlemek için Volatile tipini kullanarak ek bir volatile okuma gerçekleştirmemizdir. Bu optimizasyon, diğer şeylerin yanı sıra, derleyicinin son ifadesi özyinelemeli bir fonksiyon çağrısı olan bir fonksiyonu normal bir döngüye dönüştürmesine olanak tanır. Böylece fonksiyon çağrısı için ek bir stack frame oluşturulmaz, bu yüzden stack kullanımı sabit kalır.
Ancak bizim durumumuzda stack taşmasının gerçekleşmesini istiyoruz, bu yüzden fonksiyonun sonuna, derleyicinin kaldırmasına izin verilmeyen sahte (dummy) bir volatile okuma ifadesi ekliyoruz. Böylece fonksiyon artık kuyruk özyinelemeli (tail recursive) olmaz ve bir döngüye dönüştürülmesi önlenir. Fonksiyonun sonsuza dek özyinelediğine dair derleyici uyarısını susturmak için allow(unconditional_recursion) özniteliğini de ekliyoruz.
🔗Test IDT’si
Yukarıda belirtildiği gibi, testin özel bir double fault handler’ı olan kendi IDT’sine ihtiyacı var. Uygulama şöyle görünür:
// tests/stack_overflow.rs içinde
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}Uygulama, interrupts.rs’teki normal IDT’mize çok benzer. Normal IDT’de olduğu gibi, ayrı bir stack’e geçmek için double fault handler’ı için IST’te bir stack indeksi ayarlıyoruz. init_test_idt fonksiyonu, IDT’yi load metodu aracılığıyla CPU’ya yükler.
🔗Double Fault Handler’ı
Eksik tek parça, double fault handler’ımız. Şöyle görünür:
// tests/stack_overflow.rs içinde
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}Double fault handler’ı çağrıldığında, QEMU’dan testi geçti olarak işaretleyen bir başarı çıkış koduyla çıkıyoruz. Entegrasyon testleri tamamen ayrı çalıştırılabilir dosyalar olduğundan, test dosyamızın başına #![feature(abi_x86_interrupt)] özniteliğini yeniden ayarlamamız gerekir.
Artık testimizi cargo test --test stack_overflow aracılığıyla (veya tüm testleri çalıştırmak için cargo test) çalıştırabiliriz. Beklendiği gibi, konsolda stack_overflow... [ok] çıktısını görüyoruz. set_stack_index satırını yorum satırı haline getirmeyi deneyin; bu, testin başarısız olmasına neden olmalı.
🔗Özet
Bu yazıda, bir double fault’un ne olduğunu ve hangi koşullar altında meydana geldiğini öğrendik. Bir hata mesajı yazdıran temel bir double fault handler’ı ekledik ve onun için bir entegrasyon testi ekledik.
Ayrıca, stack taşmasında da çalışması için double fault exception’larında donanım destekli stack değiştirmeyi etkinleştirdik. Onu uygularken, task state segment’i (TSS), içerdiği interrupt stack table’ı (IST) ve daha eski mimarilerde segmentasyon için kullanılan global descriptor table’ı (GDT) öğrendik.
🔗Sırada ne var?
Bir sonraki yazı, zamanlayıcılar (timer), klavyeler veya ağ denetleyicileri gibi harici cihazlardan gelen interrupt’ların nasıl işleneceğini açıklar. Bu donanım interrupt’ları exception’lara çok benzer; örneğin, onlar da IDT aracılığıyla yönlendirilir. Ancak exception’ların aksine, doğrudan CPU üzerinde ortaya çıkmazlar. Bunun yerine, bir interrupt controller bu interrupt’ları toplar ve önceliklerine bağlı olarak CPU’ya iletir. Bir sonraki yazıda Intel 8259 (“PIC”) interrupt controller’ını inceleyecek ve klavye desteğinin nasıl uygulanacağını öğreneceğiz.
Yorumlar
Bir sorunuz mu var, geri bildirim paylaşmak veya fikirlerinizi tartışmak mı istiyorsunuz? Buraya yorum bırakmaktan çekinmeyin! Lütfen İngilizce kullanın ve Rust'ın davranış kurallarına uyun. Bu yorum dizisi doğrudan GitHub'daki bir tartışmaya bağlıdır, dolayısıyla isterseniz oraya da yorum yapabilirsiniz.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Mümkünse yorumlarınızı İngilizce bırakınız.