خطاهای دوگانه
محتوای ترجمه شده: این یک ترجمه از جامعه کاربران برای پست Double Faults است. ممکن است ناقص، منسوخ شده یا دارای خطا باشد. لطفا هر گونه مشکل را در این ایشو گزارش دهید!
ترجمه توسط @hamidrezakp و @MHBahrampour.
این پست به طور دقیق جزئیات استثنای خطای دوگانه (ترجمه: double fault exception) را بررسی میکند، این استثنا هنگامی رخ میدهد که CPU نتواند یک کنترل کننده استثنا را فراخوانی کند. با کنترل این استثنا، از بروز خطاهای سه گانه (ترجمه: triple faults) کشنده که باعث ریست (کلمه: reset) شدن سیستم میشوند، جلوگیری میکنیم. برای جلوگیری از خطاهای سه گانه در همه موارد، ما همچنین یک Interrupt Stack Table را تنظیم کردهایم تا خطاهای دوگانه را روی یک پشته هسته جداگانه بگیرد.
این بلاگ بصورت آزاد روی گیتهاب توسعه داده شده است. اگر شما مشکل یا سوالی دارید، لطفاً آنجا یک ایشو باز کنید. شما همچنین میتوانید در زیر این پست کامنت بگذارید. منبع کد کامل این پست را میتوانید در بِرَنچ post-06 پیدا کنید.
فهرست مطالب
🔗خطای دوگانه چیست؟
به عبارت ساده، خطای دوگانه یک استثنای به خصوص است و هنگامی رخ میدهد که CPU نتواند یک کنترل کننده استثنا را فراخوانی کند. به عنوان مثال، این اتفاق هنگامی رخ میدهد که یک page fault (ترجمه: خطای صفحه) رخ دهد اما هیچ کنترل کننده خطایی در جدول توصیف کننده وقفه (ترجمه: Interrupt Descriptor Table) ثبت نشده باشد. بنابراین به نوعی شبیه بلاکهای همه گیر در زبانهای برنامهنویسی با استثناها میباشد، به عنوان مثال catch(...) در ++C یا catch(Exception e) در جاوا و #C.
خطای دوگانه مانند یک استثنای عادی رفتار میکند. دارای شماره وکتور (کلمه: vector) 8 است و ما میتوانیم یک تابع طبیعی کنترل کننده برای آن در IDT تعریف کنیم. تهیه یک کنترل کننده خطای دوگانه بسیار مهم است، زیرا اگر یک خطای دوگانه کنترل نشود، یک خطای کشنده سه گانه رخ میدهد. خطاهای سه گانه قابل کشف نیستند و اکثر سخت افزارها با تنظیم مجدد سیستم واکنش نشان میدهند.
🔗راهاندازی یک خطای دوگانه
بیایید یک خطای دوگانه را با راهاندازی (ترجمه: triggering) یک استثنا برای آن ایجاد کنیم، ما هنوز یک تابع کنترل کننده تعریف نکردهایم:
// in src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// trigger a page fault
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}برای نوشتن در آدرس نامعتبر 0xdeadbeef از unsafe استفاده میکنیم. آدرس مجازی در جداول صفحه به آدرس فیزیکی مپ نمیشود، بنابراین خطای صفحه رخ میدهد. ما یک کنترل کننده خطای صفحه در IDT خود ثبت نکردهایم، بنابراین یک خطای دوگانه رخ میدهد.
حال وقتی هسته را اجرا میکنیم، میبینیم که وارد یک حلقه بوت بیپایان میشود. دلایل حلقه بوت به شرح زیر است:
۱. سیپییو سعی به نوشتن در 0xdeadbeef دارد، که باعث خطای صفحه میشود.
۲. سیپییو به ورودی مربوطه در IDT نگاه میکند و میبیند که هیچ تابع کنترل کنندهای مشخص نشده است. بنابراین، نمیتواند کنترل کننده خطای صفحه را فراخوانی کند و یک خطای دوگانه رخ میدهد.
۳. سیپییو ورودی IDT کنترل کننده خطای دو گانه را بررسی میکند، اما این ورودی هم تابع کنترل کنندهای را مشخص نمیکند. بنابراین، یک خطای سهگانه رخ میدهد.
۴. خطای سه گانه کشنده است. QEMU مانند اکثر سخت افزارهای واقعی به آن واکنش نشان داده دستور ریست شدن سیستم را صادر میکند.
بنابراین برای جلوگیری از این خطای سهگانه، باید یک تابع کنترل کننده برای خطاهای صفحه یا یک کنترل کننده خطای دوگانه ارائه دهیم. ما میخواهیم در همه موارد از خطاهای سه گانه جلوگیری کنیم، بنابراین بیایید با یک کنترل کننده خطای دوگانه شروع کنیم که برای همه انواع استثنا بدون کنترل فراخوانی میشود.
🔗کنترل کننده خطای دوگانه
خطای دوگانه یک استثنا عادی با کد خطا است، بنابراین میتوانیم یک تابع کنترل کننده مشابه کنترل کننده نقطه شکست (ترجمه: breakpoint) تعیین کنیم:
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // new
idt
};
}
// new
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
}کنترل کننده ما یک پیام خطای کوتاه چاپ میکند و قاب پشته استثنا را تخلیه میکند. کد خطای کنترل کننده خطای دوگانه همیشه صفر است، بنابراین دلیلی برای چاپ آن وجود ندارد. یک تفاوت در کنترل کننده نقطه شکست این است که کنترل کننده خطای دوگانه diverging (ترجمه: واگرا) است. چون معماری x86_64 امکان بازگشت از یک استثنا خطای دوگانه را ندارد.
حال وقتی هسته را اجرا میکنیم، باید ببینیم که کنترل کننده خطای دوگانه فراخوانی میشود:
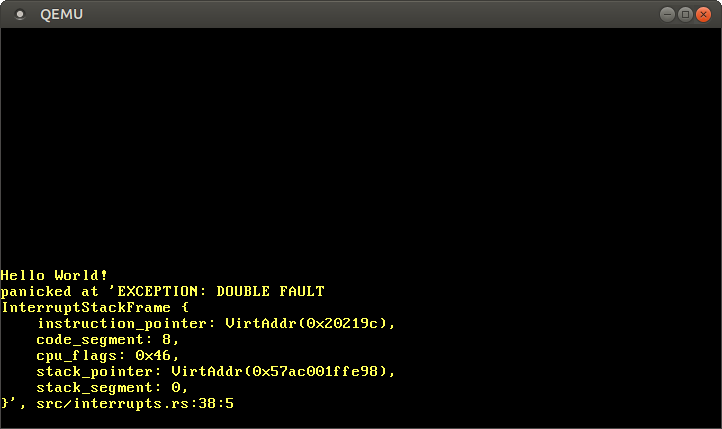
کار کرد! آنچه این بار اتفاق میافتد بصورت زیر است:
۱. سیپییو سعی به نوشتن در 0xdeadbeef دارد، که باعث خطای صفحه میشود.
۲. مانند قبل، سیپییو به ورودی مربوطه در IDT نگاه میکند و میبیند که هیچ تابع کنترل کنندهای مشخص نشده است. بنابراین، یک خطای دوگانه رخ میدهد.
۳. سیپییو به کنترل کننده خطای دوگانه - که اکنون وجود دارد - میرود.
خطای سه گانه (و حلقه بوت) دیگر رخ نمیدهد، زیرا اکنون CPU میتواند کنترل کننده خطای دوگانه را فراخوانی کند.
این کاملاً ساده بود! پس چرا ما برای این موضوع به یک پست کامل نیاز داریم؟ خب، ما اکنون قادر به ردیابی اکثر خطاهای دوگانه هستیم، اما مواردی وجود دارد که رویکرد فعلی ما کافی نیست.
🔗علل رخ داد خطای دوگانه
قبل از بررسی موارد خاص، باید علل دقیق خطاهای دوگانه را بدانیم. در بالا، ما از یک تعریف کاملا مبهم استفاده کردیم:
خطای دوگانه یک استثنای به خصوص است و هنگامی رخ میدهد که CPU نتواند یک کنترل کننده استثنا را فراخوانی کند.
عبارت “fails to invoke” دقیقا چه معنایی دارد؟ کنترل کننده وجود ندارد؟ کنترل کننده خارج شده (منظور این است که آیا صفحه مربوط به کنترل کننده از حافظه خارج شده)؟ و اگر کنترل کننده خودش باعث رخ دادن یک استثناها شود، چه اتفاقی رخ میدهد؟
به عنوان مثال، چه اتفاقی میافتد اگر:
۱. یک استثنای نقطه شکست رخ میدهد، آیا تابع کنترل کننده مربوطه خارج شده است؟ ۲. یک خطای صفحه رخ میدهد، آیا کنترل کننده خطای صفحه خارج شده است؟ ۳. کنترل کنندهی «تقسیم بر صفر» باعث رخ دادن یک استثنای نقطه شکست میشود، آیا کنترل کننده نقطه شکست خارج شده است؟ ۴. هسته ما پشته خود را سرریز میکند و آیا صفحه محافظ (ترجمه: guard page) ضربه میخورد؟
خوشبختانه، کتابچه راهنمای AMD64 (PDF) یک تعریف دقیق دارد (در بخش 8.2.9). مطابق آن، “یک استثنای خطای دوگانه میتواند زمانی اتفاق بیفتد که یک استثنا دوم هنگام کار با یک کنترل کننده استثنا قبلی (اول) رخ دهد”. “می تواند” مهم است: فقط ترکیبی بسیار خاص از استثناها منجر به خطای دوگانه میشود. این ترکیبات عبارتند از:
بنابراین به عنوان مثال، یک خطای تقسیم بر صفر (ترجمه: Divide-by-zero) و به دنبال آن خطای صفحه (ترجمه: Page Fault)، خوب است (کنترل کننده خطای صفحه فراخوانی میشود)، اما خطای تقسیم بر صفر و به دنبال آن یک خطای محافظت عمومی (ترجمه: General Protection) منجر به خطای دوگانه می شود.
با کمک این جدول میتوانیم به سه مورد اول از سوالهای بالا پاسخ دهیم:
۱. اگر یک استثنای نقطه شکست اتفاق بیفتد و تابع مربوط به کنترل کننده آن خارج شده باشد، یک خطای صفحه رخ میدهد و کنترل کننده خطای صفحه فراخوانی میشود. ۲. اگر خطای صفحه رخ دهد و کنترل کننده خطای صفحه خارج شده باشد، یک خطای دوگانه رخ میدهد و کنترل کننده خطای دوگانه فراخوانی میشود. ۳. اگر یک کنترل کننده تقسیم بر صفر باعث استثنای نقطه شکست شود، CPU سعی میکند تا کنترل کننده نقطه شکست را فراخوانی کند. اگر کنترل کننده نقطه شکست خارج شده باشد، یک خطای صفحه رخ میدهد و کنترل کننده خطای صفحه فراخوانی میشود.
در حقیقت، حتی موارد استثنا بدون تابع کنترل کننده در IDT نیز از این طرح پیروی میکند: وقتی استثنا رخ میدهد، CPU سعی میکند ورودی IDT مربوطه را بخواند. از آنجا که ورودی 0 است، که یک ورودی IDT معتبر نیست، یک خطای محافظت کلی رخ میدهد. ما یک تابع کنترل کننده برای خطای محافظت عمومی نیز تعریف نکردیم، بنابراین یک خطای محافظت عمومی دیگر رخ میدهد. طبق جدول، این منجر به یک خطای دوگانه میشود.
🔗سرریزِ پشتهی هسته
بیایید به سوال چهارم نگاه کنیم:
چه اتفاقی میافتد اگر هسته ما پشته خود را سرریز کند و صفحه محافظ ضربه بخورد؟
یک صفحه محافظ یک صفحه حافظه ویژه در پایین پشته است که امکان تشخیصِ سرریز پشته را فراهم میکند. صفحه به هیچ قاب فیزیکی مپ نشده است، بنابراین دسترسی به آن باعث خطای صفحه میشود به جای اینکه بی صدا حافظه دیگر را خراب کند. بوتلودر یک صفحه محافظ برای پشته هسته ما تنظیم میکند، بنابراین سرریز پشته باعث خطای صفحه میشود.
هنگامی که خطای صفحه رخ میدهد، پردازنده به دنبال کنترل کننده خطای صفحه در IDT است و سعی میکند تا قاب پشته وقفه را به پشته پوش میکند. با این حال، اشارهگر پشته فعلی هنوز به صفحه محافظی اشاره میکند که موجود نیست. بنابراین، خطای صفحه دوم رخ میدهد، که باعث خطای دوگانه میشود (مطابق جدول فوق).
بنابراین حالا پردازنده سعی میکند کنترل کننده خطای دوگانه را فراخوانی کند. با این حال، هنگام رخ دادن خطای دوگانه پردازنده سعی میکند تا قاب پشته استثنا را نیز پوش کند. اشارهگر پشته هنوز به سمت صفحه محافظ است، بنابراین یک خطای صفحه سوم رخ میهد که باعث یک خطای سهگانه و راه اندازی مجدد سیستم میشود. بنابراین کنترل کننده خطای دوگانه فعلی ما نمیتواند از خطای سهگانه در این مورد جلوگیری کند.
بیایید خودمان امتحان کنیم! ما میتوانیم با فراخوانی تابعی که به طور بیوقفه بازگشت مییابد، به راحتی سرریز پشته هسته را تحریک کنیم (باعث رخ دادن یک سرریز پشته هسته شویم):
// in src/main.rs
#[unsafe(no_mangle)] // don't mangle the name of this function
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
}
// trigger a stack overflow
stack_overflow();
[…] // test_main(), println(…), and loop {}
}وقتی این کد را در QEMU امتحان میکنیم، میبینیم که سیستم دوباره وارد یک حلقه بوت میشود.
بنابراین چگونه میتوانیم از بروز این مشکل جلوگیری کنیم؟ ما نمیتوانیم پوش کردن قاب پشته استثنا را حذف کنیم، زیرا پردازنده خود این کار را انجام میدهد. بنابراین ما باید به نحوی اطمینان حاصل کنیم که وقتی یک استثنای خطای دوگانه رخ میدهد، پشته همیشه معتبر است. خوشبختانه، معماری x86_64 راه حلی برای این مشکل دارد.
🔗تعویض پشتهها
معماری x86_64 قادر است در صورت وقوع یک استثنا به یک پشته از پیش تعریف شده و شناخته شده تعویض شود. این تعویض در سطح سخت افزاری اتفاق میافتد، بنابراین میتوان آن را قبل از اینکه پردازنده قاب پشته استثنا را پوش کند، انجام داد.
مکانیزم تعویض به عنوان Interrupt Stack Table (IST) پیادهسازی میشود. IST جدولی است با 7 اشارهگر برای دسته های معروف. در شبه کد شبیه Rust:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}برای هر کنترل کننده استثنا، میتوانیم یک پشته از IST از طریق فیلد stack_pointers مربوط به IDT entry انتخاب کنیم. به عنوان مثال، ما میتوانیم از اولین پشته در IST برای کنترل کننده خطای دوگانه استفاده کنیم. هرگاه خطای دوگانه رخ دهد، پردازنده به طور خودکار به این پشته تغییر میکند. این تعویض قبل از پوش کردن هر چیزی اتفاق میافتد، بنابراین از خطای سهگانه جلوگیری میکند.
🔗IST و TSS
جدول پشته وقفه (ترجمه: Interrupt Stack Table: IST) بخشی از یک ساختار قدیمی است که به آن سگمنت وضعیت پروسه (Task State Segment: TSS) گفته میشود. TSS برای نگهداری اطلاعات مختلف (به عنوان مثال وضعیت ثبات پردازنده) در مورد یک پروسه در حالت 32 بیتی استفاده میشد و به عنوان مثال برای تعویض سختافزاری context (ترجمه: hardware context switching) استفاده میشد. با این حال، تعویض سختافزاری context دیگر در حالت 64 بیتی پشتیبانی نمیشود و قالب TSS کاملاً تغییر کرده است.
در x86_64، دیگر TSS هیچ اطلاعات خاصی برای پرسهها ندارد. در عوض، دو جدول پشته را در خود جای داده است (IST یکی از آنهاست). تنها فیلد مشترک بین TSS 32-bit و TSS 64-bit اشارهگر به بیتمپ مجوزهای پورت I/O است.
فرمت TSS 64-bit مانند زیر است:
| فیلد | نوع |
|---|---|
| (reserved) | u32 |
| Privilege Stack Table | [u64; 3] |
| (reserved) | u64 |
| Interrupt Stack Table | [u64; 7] |
| (reserved) | u64 |
| (reserved) | u16 |
| I/O Map Base Address | u16 |
وقتی سطح ممتاز تغییر میکند، پردازنده از Privilege Stack Table استفاده میکند. به عنوان مثال، اگر یک استثنا در حالی که CPU در حالت کاربر است (سطح ممتاز 3) رخ دهد، CPU معمولاً قبل از فراخوانی کنترل کننده استثنا، به حالت هسته تغییر میکند (سطح امتیاز 0). در این حالت، CPU به پشته صفرم در جدول پشته ممتاز تغییر وضعیت می دهد (از آنجا که 0، سطح ممتاز هدف است). ما هنوز هیچ برنامه حالت کاربر نداریم، بنابراین اکنون این جدول را نادیده میگیریم.
🔗ایجاد یک TSS
بیایید یک TSS جدید ایجاد کنیم که شامل یک پشته خطای دوگانه جداگانه در جدول پشته وقفه خود باشد. برای این منظور ما به یک ساختار TSS نیاز داریم. خوشبختانه کریت x86_64 از قبل حاوی ساختار TaskStateSegment است که میتوانیم از آن استفاده کنیم.
ما TSS را در یک ماژول جدید به نام gdt ایجاد میکنیم (نام این ماژول بعداً برایتان معنا پیدا میکند):
// in src/lib.rs
pub mod gdt;
// in src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(&raw const STACK);
let stack_end = stack_start + STACK_SIZE as u64;
stack_end
};
tss
};
}ما از lazy_static استفاده میکنیم زیرا ارزیابی کننده ثابت راست هنوز آنقدر توانمند نیست که بتواند این مقداردهی اولیه را در زمان کامپایل انجام دهد. ما تعریف میکنیم که ورودی صفرم IST پشته خطای دوگانه است (هر اندیس دیگری از IST نیز قابل استفاده است). سپس آدرس بالای یک پشته خطای دوگانه را در ورودی صفرم مینویسیم. ما آدرس بالایی را مینویسیم زیرا پشتههای x86 به سمت پایین رشد میکنند، یعنی از آدرسهای بالا به آدرسهای پایین میآیند.
ما هنوز مدیریت حافظه را پیاده سازی نکردهایم، بنابراین روش مناسبی برای اختصاص پشته جدید نداریم.
در عوض، فعلاً از یک آرایه static mut به عنوان حافظه پشته استفاده میکنیم.
مهم است که یک static mut باشد و نه یک استاتیک تغییرناپذیر (ترجمه: immutable)، زیرا در غیر این صورت bootloader آن را به یک صفحه فقط خواندنی نگاشت میکند.
توجه داشته باشید که این پشته خطای دوگانه فاقد صفحه محافظ در برابر سرریز پشته است. یعنی ما نباید هیچ کاری که اضافه شدن ایتمی در پشته شود را انجام دهیم زیرا سرریز پشته ممکن است حافظه زیر پشته را خراب کند.
🔗بارگذاری TSS
اکنون که TSS جدیدی ایجاد کردیم، به روشی نیاز داریم که به CPU بگوییم باید از آن استفاده کند. متأسفانه این کمی دشوار است، زیرا TSS به دلایل تاریخی از سیستم سگمنتبندی (ترجمه: segmentation) استفاده میکند. به جای بارگذاری مستقیم جدول، باید توصیفگر سگمنت جدیدی را به جدول توصیفگر سراسری (Global Descriptor Table: GDT) اضافه کنیم. سپس میتوانیم TSS خود را با فراخوانی دستور ltr با اندیس GDT مربوطه بارگذاری کنیم. (دلیل اینکه نام ماژول را gdt گذاشتیم نیز همین بود).
🔗جدول توصیفگر سراسری
جدول توصیفگر سراسری (GDT) یک یادگاری است که قبل از اینکه صفحهبندی به صورت استاندارد تبدیل شود، برای تقسیمبندی حافظه استفاده میشد. این مورد همچنان در حالت 64 بیتی برای موارد مختلف مانند پیکربندی هسته/کاربر یا بارگذاری TSS مورد نیاز است.
جدول توصیفگر سراسری، ساختاری است که شامل بخشهای برنامه است. قبل از اینکه صفحهبندی به استاندارد تبدیل شود، از آن در معماریهای قدیمی استفاده میشد تا برنامه ها را از یکدیگر جدا کند. برای کسب اطلاعات بیشتر در مورد سگمنتبندی، فصل مربوط به این موضوع در کتاب “Three Easy Pieces” را مطالعه کنید. در حالی که سگمنتبندی در حالت 64 بیتی دیگر پشتیبانی نمیشود، GDT هنوز وجود دارد. بیشتر برای دو چیز استفاده میشود: جابجایی بین فضای هسته و فضای کاربر، و بارگذاری ساختار TSS.
🔗ایجاد یک GDT
بیایید یک GDT استاتیک ایجاد کنیم که شامل یک بخش برای TSS استاتیک ما باشد:
// in src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.append(Descriptor::kernel_code_segment());
gdt.append(Descriptor::tss_segment(&TSS));
gdt
};
}ما دوباره از lazy_static استفاده میکنیم، زیرا ارزیابی کننده ثابت راست هنوز آنقدر توانمند نیست. ما یک GDT جدید با یک کد سگمنت و یک بخش TSS ایجاد میکنیم.
🔗بارگذاری GDT
برای بارگذاری GDT، یک تابع جدید gdt::init ایجاد میکنیم که آن را از تابع init فراخوانی میکنیم:
// in src/gdt.rs
pub fn init() {
GDT.load();
}
// in src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}اکنون GDT ما بارگذاری شده است (از آنجا که تابع start_، تابع init را فراخوانی میکند)، اما هنوز حلقه بوت را هنگامِ سرریز پشته مشاهده میکنیم.
🔗مراحل پایانی
مشکل این است که سگمنتهای GDT هنوز فعال نیستند زیرا سگمنت و ثباتهای TSS هنوز حاوی مقادیر GDT قدیمی هستند. ما همچنین باید ورودی خطای دوگانه IDT را اصلاح کنیم تا از پشته جدید استفاده کند.
به طور خلاصه، باید موارد زیر را انجام دهیم:
۱. بارگذاری مجدد ثبات کد سگمنت: ما GDT خود را تغییر دادیم، بنابراین باید cs، ثبات کد سگمنت را بارگذاری مجدد کنیم. این مورد الزامی است زیرا انتخابگر سگمنت قدیمی میتواند اکنون توصیفگر دیگری از GDT را نشان دهد (به عنوان مثال توصیف کننده TSS).
۲. بارگذاری TSS: ما یک GDT بارگذاری کردیم که شامل یک انتخابگر TSS است، اما هنوز باید به CPU بگوییم که باید از آن TSS استفاده کند.
۳. بروزرسانی ورودی IDT: به محض اینکه TSS بارگذاری شد، CPU به یک جدول پشته وقفه معتبر (IST) دسترسی دارد. سپس میتوانیم به CPU بگوییم که باید با تغییر در ورودی IDT خطای دوگانه از پشته خطای دوگانه جدید استفاده کند.
برای دو مرحله اول، ما نیاز به دسترسی به متغیرهای code_selector و tss_selector در تابع gdt::init داریم. میتوانیم با تبدیل آنها به بخشی از استاتیک از طریق ساختار جدید Selectors به این هدف برسیم:
// in src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.append(Descriptor::kernel_code_segment());
let tss_selector = gdt.append(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}اکنون میتوانیم با استفاده از انتخابگرها، ثبات بخش cs را بارگذاری مجدد کرده و TSS را بارگذاری کنیم:
// in src/gdt.rs
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}ما با استفاده از CS::set_reg ثبات کد سگمنت را بارگذاری مجدد میکنیم و برای بارگذاری TSS با از load_tss استفاده میکنیم. توابع به عنوان unsafe علامت گذاری شدهاند، بنابراین برای فراخوانی آنها به یک بلوک unsafe نیاز داریم. چون ممکن است با بارگذاری انتخابگرهای نامعتبر، ایمنی حافظه از بین برود.
اکنون که یک TSS معتبر و جدول پشته وقفه را بارگذاری کردیم، میتوانیم اندیس پشته را برای کنترل کننده خطای دوگانه در IDT تنظیم کنیم:
// in src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
}
idt
};
}روش set_stack_index ایمن نیست زیرا فراخوان (ترجمه: caller) باید اطمینان حاصل کند که اندیس استفاده شده معتبر است و قبلاً برای استثنای دیگری استفاده نشده است.
همین! اکنون CPU باید هر زمان که خطای دوگانه رخ داد، به پشته خطای دوگانه برود. بنابراین، ما میتوانیم همه خطاهای دوگانه، از جمله سرریزهای پشته هسته را بگیریم:
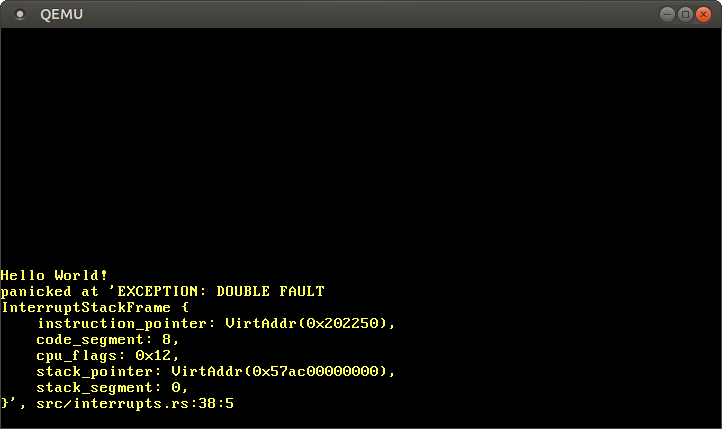
از این به بعد هرگز نباید شاهد خطای سهگانه باشیم! برای اطمینان از اینکه موارد بالا را به طور تصادفی نقض نمیکنیم، باید یک تست برای این کار اضافه کنیم.
🔗تست سرریز پشته
برای آزمایش ماژول gdt جدید و اطمینان از اینکه مدیر خطای دوگانه به درستی هنگام سرریز پشته فراخوانی شده است، میتوانیم یک تست یکپارچه اضافه کنیم. ایده این است که یک خطای دوگانه در تابع تست ایجاد کنید و تأیید کنید که مدیر خطای دوگانه فراخوانی میشود.
بیایید با یک طرح مینیمال شروع کنیم:
// in tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}مانند تست panic_handler، تست بدون یک test harness اجرا خواهد شد. زیرا پس از یک خطای دوگانه نمیتوانیم اجرا را ادامه دهیم، بنابراین بیش از یک تست منطقی نیست. برای غیرفعال کردن test harness برای این تست، موارد زیر را به Cargo.toml اضافه میکنیم:
# in Cargo.toml
[[test]]
name = "stack_overflow"
harness = falseحال باید cargo test --test stack_overflow بصورت موفقیتآمیز کامپایل شود. البته این تست با شکست مواجه میشود، زیرا ماکروی unimplemented پنیک میکند.
🔗پیادهسازی start_
پیادهسازی تابع start_ مانند این است:
// in tests/stack_overflow.rs
use blog_os::serial_print;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// trigger a stack overflow
stack_overflow();
panic!("Execution continued after stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
}برای راهاندازی یک GDT جدید، تابع gdt::init را فراخوانی میکنیم. به جای فراخوانی تابع interrupts::init_idt، تابع init_test_idt را فراخوانی میکنیم که بزودی توضیح داده میشود. زیرا ما میخواهیم یک مدیر خطای دوگانه سفارشی ثبت کنیم که به جای پنیک کردن، دستور exit_qemu(QemuExitCode::Success) را انجام میدهد.
تابع stack_overflow تقریباً مشابه تابع موجود در main.rs است. تنها تفاوت این است که برای جلوگیری از بهینهسازی کامپایلر موسوم به tail call elimination، در پایان تابع، یک خواندنِ [فرارِ] (ترجمه: volatile) اضافه به وسیله نوع Volatile انجام میدهیم. از جمله، این بهینهسازی به کامپایلر اجازه میدهد تابعی را که آخرین عبارت آن فراخوانی تابع بازگشتی است، به یک حلقه طبیعی تبدیل کند. بنابراین، هیچ قاب پشته اضافی برای فراخوانی تابع ایجاد نمیشود، پس استفاده از پشته ثابت میماند.
با این حال، در مورد ما، ما میخواهیم که سرریز پشته اتفاق بیفتد، بنابراین در انتهای تابع یک دستور خواندن فرار ساختگی اضافه میکنیم، که کامپایلر مجاز به حذف آن نیست. بنابراین، تابع دیگر tail recursive نیست و از تبدیل به یک حلقه جلوگیری میشود. ما همچنین صفت allow(unconditional_recursion) را اضافه میکنیم تا اخطار کامپایلر را در مورد تکرار بیوقفه تابع خاموش نگه دارد.
🔗تست IDT
همانطور که در بالا ذکر شد، این تست به IDT مخصوص خود با یک مدیر خطای دوگانه سفارشی نیاز دارد. پیادهسازی به این شکل است:
// in tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}پیادهسازی بسیار شبیه IDT طبیعی ما در interrupts.rs است. مانند IDT عادی، برای مدیر خطای دوگانه به منظور جابجایی به پشتهای جداگانه، یک اندیس پشته را در IST تنظیم میکنیم. تابع init_test_idt با استفاده از روش load، آیدیتی را بر روی پردازنده بارگذاری میکند.
🔗مدیر خطای دوگانه
تنها قسمت جامانده، مدیر خطای دوگانه است که به این شکل پیادهسازی میشود:
// in tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}هنگامی که مدیر خطای دوگانه فراخوانی میشود، از QEMU با یک کد خروج موفقیتآمیز خارج میشویم، که تست را بعنوان «قبول شده» علامتگذاری میداند. از آنجا که تستهای یکپارچه اجراییهای کاملاً مجزایی هستند، باید صفت [feature(abi_x86_interrupt)]!# را در بالای فایل تست تنظیم کنیم.
اکنون میتوانیم تست را از طریق cargo test --test stack_overflow (یا cargo test برای اجرای همه تستها) انجام دهیم. همانطور که انتظار میرفت، خروجی stack_overflow... [ok ] را در کنسول مشاهده میکنیم. خط set_stack_index را کامنت کنید: این امر باعث میشود تست از کار بیفتد.
🔗خلاصه
در این پست یاد گرفتیم که خطای دوگانه چیست و در چه شرایطی رخ میدهد. ما یک مدیر خطای دوگانه پایه اضافه کردیم که پیام خطا را چاپ میکند و یک تست یکپارچه برای آن اضافه کردیم.
ما همچنین تعویض پشته پشتیبانی شده سختافزاری را در استثناهای خطای دوگانه فعال کردیم تا در سرریز پشته نیز کار کند. در حین پیادهسازی آن، ما با سگمنت وضعیت پروسه (TSS)، جدول پشته وقفه (IST) و جدول توصیف کننده سراسری (GDT) آشنا شدیم، که برای سگمنتبندی در معماریهای قدیمی استفاده میشد.
🔗بعدی چیست؟
پست بعدی نحوه مدیریت وقفههای دستگاههای خارجی مانند تایمر، صفحه کلید یا کنترل کنندههای شبکه را توضیح میدهد. این وقفههای سختافزاری بسیار شبیه به استثناها هستند، به عنوان مثال آنها هم از طریق IDT ارسال میشوند. با این حال، برخلاف استثناها، مستقیماً روی پردازنده رخ نمیدهند. در عوض، یک interrupt controller این وقفهها را جمع کرده و بسته به اولویت، آنها را به CPU میفرستد. در بخش بعدی، مدیر وقفه Intel 8259 (“PIC”) را بررسی خواهیم کرد و نحوه پیادهسازی پشتیبانی صفحه کلید را یاد خواهیم گرفت.
نظرات
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English and follow Rust's code of conduct. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
لطفا نظرات خود را در صورت امکان به انگلیسی بنویسید.