堆分配
翻译内容: 这是对原文章 Heap Allocation 的社区中文翻译。它可能不完整,过时或者包含错误。可以在 这个 Issue 上评论和提问!
翻译者: @Liuliuliu7.
本文为我们的内核添加堆分配支持。首先,它介绍了动态内存,并展示了 Rust 的借用检查器如何防止常见的分配错误。接着,它实现了 Rust 基本的分配接口,创建了堆内存区域,并实现了一个分配器 crate。本文结束时,内置的 alloc crate 中的所有分配和集合类型都将在我们的内核中可用。
这个系列的 blog 在GitHub上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在底部留言。你可以在post-10找到这篇文章的完整源码。
目录
🔗局部变量与静态变量
目前,我们的内核中使用了两类变量:局部变量和静态(static) 变量。局部变量存储在调用栈上,仅在函数返回前有效。静态变量存储在固定的内存位置,在程序的整个生命周期内有效。
🔗局部变量
局部变量存储在调用栈上,调用栈是一个支持 push 和 pop 操作的栈数据结构。在每次函数调用时,编译器会将函数的参数、返回地址和局部变量压入栈中:

上述示例展示了 outer 函数调用 inner 函数后的调用栈。调用栈首先包含 outer 的局部变量。在调用 inner 时,参数 1 和返回地址被压入栈中。然后控制权转移到 inner,其局部变量也被压入。
在 inner 函数返回后,其调用栈部分被弹出,仅保留 outer 的局部变量:

我们看到,inner 的局部变量仅在函数返回前有效。Rust 编译器保证了这些变量的生命周期,如果我们其生命周期外使用该变量(例如返回一个局部变量的引用),则会抛出错误:
fn inner(i: usize) -> &'static u32 {
let z = [1, 2, 3];
&z[i]
}
在此示例中返回局部变量的引用没有意义,但在某些情况下,我们希望变量的生命周期超过函数。例如,在我们的内核中加载中断描述符表时,我们需要使用 static 变量来延长生命周期。
🔗静态变量
静态变量存储在与栈分开的固定内存位置中,其内存位置由链接器在编译时分配并编码在可执行文件中。静态变量在程序的整个运行期间始终存在,因此具有 'static 生命周期,局部变量总是可以引用它们:
![与 outer/inner 示例相同,但 inner 有一个静态变量 Z: [u32; 3] = [1,2,3]; 并返回 &Z[i] 引用](https://os.phil-opp.com/zh-CN/heap-allocation/call-stack-static.svg)
在上述示例中,当 inner 函数返回时,其调用栈分被销毁。静态变量存储在永不销毁的独立内存区域,因此 &Z[1] 引用在返回后仍然有效。
除了 'static 生命周期,静态变量还有一个有用的特性:它们的内存位置在编译时已知,因此访问时无需引用。我们在 println 宏中利用了这一点:通过内部使用静态Writer,调用宏时无需 &mut Writer 引用,这在异常处理程序中尤为有用,因为在这些场景中我们无法访问其他变量。
然而,静态变量的这一特性带来了一个关键缺点:它们默认是只读的。Rust 强制执行这一点,因为如果多个线程同时修改静态变量,会导致数据竞争。修改静态变量的唯一方法是将其封装在 Mutex 类型中,以确保任何时候只有一个 &mut 引用存在。我们已经为静态 VGA 缓冲区 Writer使用了 Mutex。
🔗动态内存
局部变量和静态变量结合已经非常强大,足以应对大多数使用场景。然而,它们各有局限性:
- 局部变量:仅在函数或块结束前有效,因为它们存储在调用栈上,函数返回后即被销毁。
- 静态变量:在程序整个运行期间始终存在,无法在不再需要时回收和重用其内存。此外,它们的所有权语义不明确,可被所有函数访问,因此修改时需使用
Mutex保护。
局部变量和静态变量的另一个限制是它们只能有固定大小,因此无法存储动态增长的集合。(Rust 中有关于非固定大小值的提案,允许动态大小的局部变量,但仅适用于特定场景。)
为解决这些缺点,编程语言通常提供第三种内存区域,称为堆,用于存储变量。堆通过 allocate 和 deallocate 两个函数支持运行时_动态内存分配_:allocate 函数返回指定大小的空闲内存块,用于存储变量,该变量在被 deallocate 函数释放前一直存在。
以下是一个示例:
![inner 函数调用 allocate(size_of([u32; 3])),写入 z.write([1,2,3]);,并返回 (z as *mut u32).offset(i)。outer 函数对返回的 y 执行 deallocate(y, size_of(u32))。](https://os.phil-opp.com/zh-CN/heap-allocation/call-stack-heap.svg)
在此,inner 函数使用堆内存而非静态变量来存储 z。它首先分配所需大小的内存块,返回一个 *mut u32 裸指针。然后使用 ptr::write 方法将数组 [1,2,3] 写入。最后使用 offset 函数计算第 i 个元素的指针并返回。(为简洁起见,此示例函数省略了部分必需的类型转换和 unsafe 块)
分配的内存在调用 deallocate 显式释放前一直存在。因此,虽然 inner 返回并销毁其调用栈部分,返回的指针仍然有效。与静态内存相比,堆内存的优势在于释放后内存可被重用,我们在 outer 中通过 deallocate 调用实现了这一点。之后,情况如下:
![调用栈包含 outer 的局部变量,堆包含 z[0] 和 z[2],但不再包含 z[1]。](https://os.phil-opp.com/zh-CN/heap-allocation/call-stack-heap-freed.svg)
我们看到 z[1] 已被释放,可在下一次 allocate 调用时被重用。然而,z[0] 和 z[2] 从未被释放,这被称为内存泄漏,常导致程序内存消耗过高(想象在循环中反复调用 inner 的后果)。这可能导致严重的问题,但动态分配还可能引发更危险的错误。
🔗常见错误
除了内存泄漏(其虽不利但不会使程序易受攻击),还有两种后果更严重的常见错误:
- 释放后使用(use-after-free):在对变量
deallocate后继续使用,这将导致未定义行为,常被攻击者利用以执行任意代码。 - 双重释放(double-free):意外对变量进行两次释放,可能释放了在同一位置重新分配的其他内存块,从而导致释放后使用漏洞。
这些漏洞广为人知,但即使在复杂项目中,最优秀的程序员也难以完全避免。例如,2019 年 Linux 中发现的释放后使用漏洞可导致任意代码执行。通过搜索 use-after-free linux {年份} 通常能找到相关结果。这表明即使最优秀的程序员在复杂项目中也难以正确处理动态内存。
为避免这些问题,许多语言(如 Java 或 Python)使用*垃圾回收(garbage collection)*来自动管理动态内存。程序员无需手动调用 deallocate,而程序会定期暂停并扫描未使用的堆变量,并自动释放它们,从而避免上述漏洞。但这种方法的缺点是定期扫描会造成性能开销以及可能的长时间暂停。
Rust 采用了不同的方法:通过所有权概念,在编译时检查动态内存操作的正确性,无需垃圾回收即可避免上述漏洞,这意味着无性能开销。另一个好处是程序员仍能像在 C 或 C++ 中一样精细控制动态内存。
🔗Rust 中的分配
Rust 标准库不需要程序员直接调用 allocate 和 deallocate,而是提供抽象类型隐式调用这些函数。最重要的类型是 Box,用于堆分配值。它提供 Box::new 构造函数,其接受一个值,调用 allocate 获取所需大小的内存,并将值移动到堆上新分配的空间中。为了释放堆内存,Box 实现了Drop trait,并在变量离开作用域时调用 deallocate:
{
let z = Box::new([1,2,3]);
[…]
} // z 离开作用域,`deallocate` 被调用
这种模式有一个奇怪的名字,称为资源获取即初始化(简称为RAII),起源于 C++,用于实现类似 std::unique_ptr 的类型。
仅靠这种类型无法防止所有释放后使用错误,因为程序员可能在 Box 超出作用域并释放堆内存后仍持有引用:
let x = {
let z = Box::new([1,2,3]);
&z[1]
}; // z 超出作用域,调用 `deallocate`
println!("{}", x);
这就是 Rust 的所有权起作用的地方。它通过为每个引用分配一个抽象生命周期(引用有效的范围)解决此问题。在上述示例中,x 引用了 z 数组,因此在 z 超出作用域后失效。在 playground 运行上述代码,Rust 编译器会报错:
error[E0597]: `z[_]` does not live long enough
--> src/main.rs:4:9
|
2 | let x = {
| - borrow later stored here
3 | let z = Box::new([1,2,3]);
| - binding `z` declared here
4 | &z[1]
| ^^^^^ borrowed value does not live long enough
5 | }; // z goes out of scope and `deallocate` is called
| - `z[_]` dropped here while still borrowed
这一术语初看可能有些复杂。获取值的引用称为 借用,类似于现实中的借用:临时访问对象,但需在某时归还,且不能销毁。通过检查所有借用在对象销毁前结束,Rust 编译器保证不会发生释放后使用情况。
Rust 的所有权系统不仅防止释放后使用,还提供与 Java 或 Python 等垃圾回收语言相同的完全内存安全。此外,它保证线程安全,在多线程代码中比这些语言更安全。最重要的是,所有检查在编译时进行,与 C 的手动内存管理相比没有运行时开销。
🔗使用场景
我们了解了 Rust 中动态内存分配的基础,但何时使用?我们的内核在不使用动态内存的情况下已经取得了很大进展,为何现在需要?
首先,动态内存分配总会带来一些性能开销,因为每次分配需在堆上寻找空闲槽。因此,在性能敏感的内核代码中,局部变量通常更优。然而,在某些情况下,动态内存分配是最佳选择。
基本规则是,动态内存适用于具有动态生命周期或可变大小的变量。最重要的动态生命周期类型是 Rc,它跟踪被包裹变量的引用数,并在所有引用超出作用域后释放。具有可变大小的类型包括 Vec、String 等集合类型,这些类型在用满时分配更大内存,复制所有元素,然后释放旧分配。
对于我们的内核,未来实现多任务时,我们主要需要集合类型,例如存储活动任务列表。
🔗分配器接口
实现堆分配器的第一步是添加对内置 alloc crate 的依赖。与 core crate 类似,它是标准库的子集,包含分配和集合类型。在 lib.rs 中添加:
// in src/lib.rs
extern crate alloc;
与普通依赖不同,我们无需修改 Cargo.toml。因为 alloc crate 作为标准库的一部分提供给 Rust 编译器,编译器已经了解了这个 crate。通过 extern crate 语句,我们指定编译器去尝试包含它。(出于历史原因,所有依赖都需要 extern crate 语句,这现在是可选的。)
由于我们为自定义目标编译,无法使用 Rust 安装中预编译的 alloc 版本。需通过在 .cargo/config.toml 中添加 unstable.build-std 数组,指示 cargo 从源代码重新编译这个 crate:
# in .cargo/config.toml
[unstable]
build-std = ["core", "compiler_builtins", "alloc"]
现在编译器将重新编译并包含 alloc crate。
#[no_std] crate 中默认禁用 alloc crate 的原因是 alloc crate 有额外要求。编译项目时,我们会看到错误:
error: no global memory allocator found but one is required; link to std or add
#[global_allocator] to a static item that implements the GlobalAlloc trait.
错误原因是 alloc crate 需要一个堆分配器,并且它需要实现 allocate 和 deallocate 函数。在 Rust 中,堆分配器由 GlobalAlloc 特性描述,错误信息中提到了这个特性。为了实现堆分配器,
我们需将 #[global_allocator] 属性应用到一个实现了 GlobalAlloc 特性的 static 变量。
🔗GlobalAlloc 特性
GlobalAlloc 特性定义了堆分配器必须提供的函数。该特性比较特殊,因为程序员几乎从不直接使用它。相反,当使用 alloc crate 的分配和集合类型时,编译器会自动插入对该特性方法的适当调用。
由于我们需要为所有分配器类型实现该特性,仔细查看其声明是值得的:
pub unsafe trait GlobalAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
unsafe fn realloc(
&self,
ptr: *mut u8,
layout: Layout,
new_size: usize
) -> *mut u8 { ... }
}
它定义了两个必需的方法 alloc 和 dealloc,对应于我们在示例中使用的 allocate 和 deallocate 函数:
alloc方法接受一个Layout实例作为参数,该实例描述了分配内存所需的大小和对齐方式。它返回一个指向所分配内存块第一个字节的裸指针。alloc方法不返回显式错误值,而是通过返回空指针来表示分配错误。虽然这有点非常规,但优点是易于包装现有系统分配器,因为它们使用相同的约定。dealloc方法是其对应物,负责再次释放内存块。它接收两个参数:由alloc返回的指针和分配时使用的Layout。
该特性还定义了 alloc_zeroed 和 realloc 两个方法,其有默认实现:
- alloc_zeroed 方法:等同于调用
alloc后将内存块置零,这就是默认实现。分配器可以提供更高效的实现。 - realloc 方法:允许扩展或缩小分配。默认实现是分配新内存块,复制旧分配内容。分配器可以提供更高效的实现,例如原地扩展/缩小。
🔗不安全性
需要注意的一点是,特性本身及其所有方法都被声明为 unsafe:
- 将特性声明为
unsafe的原因是,程序员必须保证分配器类型的特性实现是正确的。例如,alloc方法绝不能返回已使用的内存块,因为这会导致未定义行为。 - 同样,其方法声明为
unsafe的原因是,调用者在调用方法时必须确保各种不变量,例如,传递给alloc的Layout指定了非零大小。这和实际使用关系不大,因为这些方法通常由编译器直接调用,编译器会确保满足要求。
🔗虚拟分配器
了解分配器类型应提供的功能后,我们创建一个简单的虚拟分配器,在 allocator 模块中:
// in src/lib.rs
pub mod allocator;
我们的虚拟分配器只实现特性的最小要求,并且调用 alloc 总是返回错误,它看起来如下:
// in src/allocator.rs
use alloc::alloc::{GlobalAlloc, Layout};
use core::ptr::null_mut;
pub struct Dummy;
unsafe impl GlobalAlloc for Dummy {
unsafe fn alloc(&self, _layout: Layout) -> *mut u8 {
null_mut()
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
panic!("dealloc should be never called")
}
}
这个结构体无需任何字段,所以我们定义它为零大小类型。如上所述,alloc 始终返回空指针,这表示一个分配错误。由于从不返回内存,dealloc 不应被调用。因此 dealloc 只是简单调用 panic。alloc_zeroed 和 realloc 有默认实现,无需手动提供。
我们现在有了一个虚拟分配器,但我们需要告诉 Rust 编译器应使用此分配器。这时需要使用 #[global_allocator] 属性。
🔗#[global_allocator] 属性
#[global_allocator] 属性告诉 Rust 编译器应使用哪个分配器实例作为全局堆分配器。该属性只能用于实现了 GlobalAlloc 特性的 static 变量。让我们将 Dummy 分配器的一个实例注册为全局分配器:
// in src/allocator.rs
#[global_allocator]
static ALLOCATOR: Dummy = Dummy;
由于 Dummy 是零大小类型,初始化无需指定字段。
此静态变量应该可以修复编译错误。现在可使用 alloc 的分配和集合类型。例如,使用 Box 在堆上分配值:
// in src/main.rs
extern crate alloc;
use alloc::boxed::Box;
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] print "Hello World!", call `init`, create `mapper` and `frame_allocator`
let x = Box::new(41);
// […] call `test_main` in test mode
println!("It did not crash!");
blog_os::hlt_loop();
}
注意,我们需要在 main.rs 中也指定 extern crate alloc 语句。这是必须的,因为 lib.rs 和 main.rs 被视为单独的 crate。但是我们无需创建另一个 #[global_allocator] 静态变量,因为全局分配器适用于项目中的所有 crate。事实上,在另一个 crate 中指定额外的分配器会引发错误。
当我们运行上述代码时,会看到发生了一个 panic:
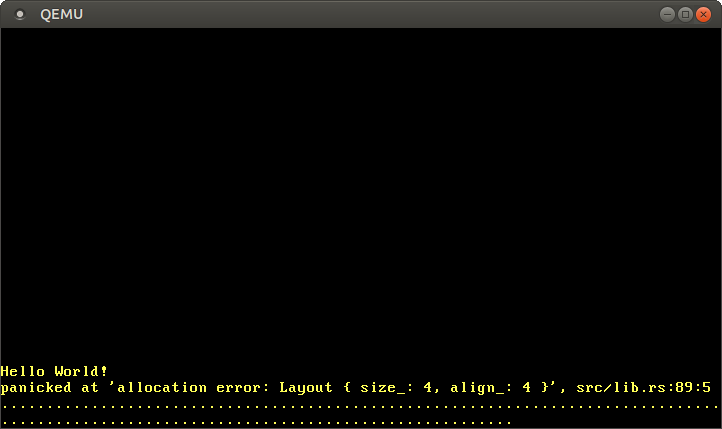
发生 panic 是因为 Box::new 函数隐式调用了全局分配器的 alloc 函数。我们的虚拟分配器始终返回空指针,因此每次分配都会失败。要修复此问题,我们需要创建一个能够返回可用内存的分配器。
🔗创建内核堆
在创建真正的分配器之前,我们首先需要创建一个堆内存区域,分配器可以从中分配内存。为此,我们需要为堆区域定义一个虚拟内存范围,然后将该区域映射到物理内存。有关虚拟内存和页表的概述,请参阅文章“内存分页初探”。
第一步是为堆定义一个虚拟内存区域。我们可以选择任何喜欢的虚拟地址范围,只要它尚未用于其他内存区域。让我们将其定义为从地址 0x_4444_4444_0000 开始的内存,以便以后轻松识别堆指针:
// in src/allocator.rs
pub const HEAP_START: usize = 0x_4444_4444_0000;
pub const HEAP_SIZE: usize = 100 * 1024; // 100 KiB
堆大小暂定为 100 KiB,未来可根据需要增加。
如果我们现在尝试使用这个堆区域,会发生页面错误,因为虚拟内存区域尚未映射到物理内存。为解决此问题,我们创建一个 init_heap 函数,使用我们在 “页面实现” 文章中介绍的 Mapper API 映射堆页面:
// in src/allocator.rs
use x86_64::{
structures::paging::{
mapper::MapToError, FrameAllocator, Mapper, Page, PageTableFlags, Size4KiB,
},
VirtAddr,
};
pub fn init_heap(
mapper: &mut impl Mapper<Size4KiB>,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) -> Result<(), MapToError<Size4KiB>> {
let page_range = {
let heap_start = VirtAddr::new(HEAP_START as u64);
let heap_end = heap_start + HEAP_SIZE - 1u64;
let heap_start_page = Page::containing_address(heap_start);
let heap_end_page = Page::containing_address(heap_end);
Page::range_inclusive(heap_start_page, heap_end_page)
};
for page in page_range {
let frame = frame_allocator
.allocate_frame()
.ok_or(MapToError::FrameAllocationFailed)?;
let flags = PageTableFlags::PRESENT | PageTableFlags::WRITABLE;
unsafe {
mapper.map_to(page, frame, flags, frame_allocator)?.flush()
};
}
Ok(())
}
该函数接受对 Mapper 和 FrameAllocator 实例的可变引用,两者都通过使用 Size4KiB 作为泛型参数限制为 4 KiB 页面。函数的返回值是一个 Result,成功返回单元类型 (),失败返回MapToError,这是 Mapper::map_to 方法返回的错误类型。在这里重用错误类型是有意义的,因为 map_to 方法是此函数的主要错误来源。
实现可分为两个部分:
-
创建页面范围:为了创建我们希望映射的页面范围,我们将
HEAP_START指针转换为VirtAddr类型。然后通过加上HEAP_SIZE计算堆结束地址。因为我们想要包含地址边界(堆最后一个字节的地址),因此减去 1。接下来,使用containing_address函数将地址转换为Page类型。最后,使用Page::range_inclusive函数从起始和结束页面创建页面范围。 -
映射页面:第二步是映射我们刚创建的页面范围中的所有页面。为此,我们使用
for循环迭代这些页面。对每个页面,我们执行以下操作:-
使用
FrameAllocator::allocate_frame方法分配页面应映射到的物理内存。当没有更多内存时,该方法返回None。我们通过Option::ok_or方法将其映射到MapToError::FrameAllocationFailed错误,并使用问号操作符 在错误情况下提前返回。 -
为页面设置必需的
PRESENT标志和WRITABLE标志。这些标志允许读写访问,这对堆内存来说是合理的。 -
使用
Mapper::map_to方法在活动页面表中创建映射。该方法可能失败,因此我们再次使用问号操作符将错误转发给调用者。成功时,该方法返回一个MapperFlush实例,我们可以使用其flush方法更新转换后备缓冲区(简称TLB)。
-
最后一步是在 kernel_main 中调用此函数:
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
use blog_os::allocator; // new import
use blog_os::memory::{self, BootInfoFrameAllocator};
println!("Hello World{}", "!");
blog_os::init();
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let mut mapper = unsafe { memory::init(phys_mem_offset) };
let mut frame_allocator = unsafe {
BootInfoFrameAllocator::init(&boot_info.memory_map)
};
// new
allocator::init_heap(&mut mapper, &mut frame_allocator)
.expect("heap initialization failed");
let x = Box::new(41);
// […] call `test_main` in test mode
println!("It did not crash!");
blog_os::hlt_loop();
}
我们在这里展示了完整的函数以提供上下文。新增的只有导入 blog_os::allocator 和对 allocator::init_heap 函数的调用。如果 init_heap 函数返回错误,我们使用 Result::expect 方法触发 panic,因为目前我们没有更好的错误处理方式。
我们现在有了一个已映射的堆内存区域,可以开始使用了。但调用 Box::new 时仍使用旧的 Dummy 分配器,因此运行时仍会看到 “out of memory” 错误。下面我们通过使用真正的分配器来修复这个问题。
🔗使用分配器 Crate
由于实现分配器较复杂,我们先使用一个外部分配器 crate。我们将在下一篇文章中学习如何实现自己的分配器。
适用于 no_std 应用的简单分配器 crate 是 [linked_list_allocator] crate。其名称源于它使用链表数据结构来跟踪已释放的内存区域。有关此方法的详细解释,请参阅下一篇文章。
要使用该 crate,我们首先需要在 Cargo.toml 中添加对其的依赖:
# in Cargo.toml
[dependencies]
linked_list_allocator = "0.9.0"
然后用这个 crate 所提供的分配器替换虚拟分配器:
// in src/allocator.rs
use linked_list_allocator::LockedHeap;
#[global_allocator]
static ALLOCATOR: LockedHeap = LockedHeap::empty();
该结构体名为 LockedHeap,因为它使用 spinning_top::Spinlock 类型进行同步。这是必须的,因为多个线程可能同时访问 ALLOCATOR 静态变量。与使用自旋锁或互斥锁时一样,我们需要小心以避免造成死锁。这意味着我们不应在中断处理程序中执行任何分配,因为它们可能在任意时间运行并中断正在进行的分配。
仅将 LockedHeap 设置为全局分配器还不够。原因是使用了 empty 构造函数,该函数创建了一个没有可用内存的分配器。与我们的虚拟分配器一样,它在 alloc 时始终返回错误。要解决此问题,我们需要在创建堆后初始化分配器:
// in src/allocator.rs
pub fn init_heap(
mapper: &mut impl Mapper<Size4KiB>,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) -> Result<(), MapToError<Size4KiB>> {
// […] map all heap pages to physical frames
// new
unsafe {
ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE);
}
Ok(())
}
我们使用 LockedHeap 类型内部自旋锁的 lock 方法获取封装后 Heap 实例的独立引用,然后传入堆边界作为参数,在其上调用 init 方法。由于 init 函数已经尝试写入堆内存,我们必须在映射堆页面之后再进行初始化堆。
初始化堆后,我们现在可以正确地使用内置 [alloc] crate 的所有分配和集合类型:
// in src/main.rs
use alloc::{boxed::Box, vec, vec::Vec, rc::Rc};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] initialize interrupts, mapper, frame_allocator, heap
// 在堆上分配数字
let heap_value = Box::new(41);
println!("heap_value at {:p}", heap_value);
// 创建动态大小向量
let mut vec = Vec::new();
for i in 0..500 {
vec.push(i);
}
println!("vec at {:p}", vec.as_slice());
// 创建引用计数向量,计数为 0 时释放
let reference_counted = Rc::new(vec![1, 2, 3]);
let cloned_reference = reference_counted.clone();
println!("current reference count is {}",Rc::strong_count(&cloned_reference));
core::mem::drop(reference_counted);
println!("reference count is {} now", Rc::strong_count(&cloned_reference));
// […] call `test_main` in test context
println!("It did not crash!");
blog_os::hlt_loop();
}
此代码示例展示了 Box、Vec 和 Rc 类型的一些用法。对于 Box 和 Vec 类型,我们使用 {:p} 格式说明符 打印底层的堆指针。为了展示 Rc,我们创建了一个引用计数的堆值,并使用 Rc::strong_count 函数打印丢弃一个引用实例(使用 core::mem::drop)前后的当前引用计数。
当我们运行的时候,可以看到如下结果:
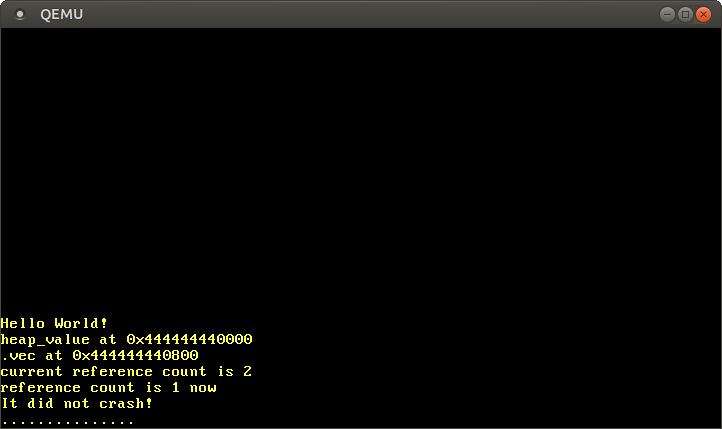
正如预期的那样,我们看到 Box 和 Vec 的值都位于堆上,从其以 0x_4444_4444_* 为前缀的指针可以看出。引用计数的值也符合预期,在调用 clone 后引用计数为 2,其中一个引用实例被丢弃后又变为 1。
向量从偏移量 0x800 处开始的原因并不是因为 Box 分配了 0x800 字节大小的内存,而是由于向量需要增加容量时发生的[重新分配]。例如,当向量的容量是 32 且我们尝试添加下一个元素时,向量会在幕后分配一个容量为 64 的新数组,并复制所有元素。然后它会释放旧的分配。
当然,alloc crate 中还有许多其他的分配和集合类型,我们现在都可以在内核中使用,包括:
- 线程安全的引用计数指针
Arc - 字符串类型
String] 和format!宏 LinkedList- 可增长的环形缓冲区
VecDeque BinaryHeap优先队列BTreeMap和BTreeSet
当我们想要实现线程列表、调度队列或支持 async/await 时,这些类型将变得非常有用。
🔗添加测试
为了确保我们不会意外地破坏新的内存分配代码,我们应该为其添加一个集成测试。我们首先创建一个新的 tests/heap_allocation.rs 文件,内容如下:
// in tests/heap_allocation.rs
#![no_std]
#![no_main]
#![feature(custom_test_frameworks)]
#![test_runner(blog_os::test_runner)]
#![reexport_test_harness_main = "test_main"]
extern crate alloc;
use bootloader::{entry_point, BootInfo};
use core::panic::PanicInfo;
entry_point!(main);
fn main(boot_info: &'static BootInfo) -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
我们复用了 lib.rs 中的 test_runner 和 test_panic_handler 函数。因为我们想测试内存分配,所以通过 extern crate alloc 语句导入了 alloc crate。关于测试样板代码的更多信息,请查看 Testing 这篇文章。
main 函数的实现如下:
// in tests/heap_allocation.rs
fn main(boot_info: &'static BootInfo) -> ! {
use blog_os::allocator;
use blog_os::memory::{self, BootInfoFrameAllocator};
use x86_64::VirtAddr;
blog_os::init();
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let mut mapper = unsafe { memory::init(phys_mem_offset) };
let mut frame_allocator = unsafe {
BootInfoFrameAllocator::init(&boot_info.memory_map)
};
allocator::init_heap(&mut mapper, &mut frame_allocator)
.expect("heap initialization failed");
test_main();
loop {}
}
它与我们 main.rs 中的 kernel_main 函数非常相似,不同之处在于我们没有调用 println,没有包含任何分配示例,并且无条件地调用了test_main。
现在我们已经准备好添加一些测试用例。首先,我们添加一个使用 Box 执行简单分配的测试,并检查分配的值以确保基本的分配功能正常工作:
// in tests/heap_allocation.rs
use alloc::boxed::Box;
#[test_case]
fn simple_allocation() {
let heap_value_1 = Box::new(41);
let heap_value_2 = Box::new(13);
assert_eq!(*heap_value_1, 41);
assert_eq!(*heap_value_2, 13);
}
正如预期,测试验证了没有发生分配错误。
接下来,我们迭代地构建一个大型向量,以测试大内存分配和多次内存分配(多次内存分配是由重新分配造成的):
// in tests/heap_allocation.rs
use alloc::vec::Vec;
#[test_case]
fn large_vec() {
let n = 1000;
let mut vec = Vec::new();
for i in 0..n {
vec.push(i);
}
assert_eq!(vec.iter().sum::<u64>(), (n - 1) * n / 2);
}
我们通过将其与 n-th partial sum 的公式进行比较来验证总和。这使我们确保分配的值都时正确的。
作为第三个测试,我们连续创建一万个分配
// in tests/heap_allocation.rs
use blog_os::allocator::HEAP_SIZE;
#[test_case]
fn many_boxes() {
for i in 0..HEAP_SIZE {
let x = Box::new(i);
assert_eq!(*x, i);
}
}
该测试确保分配器会重用已释放的内存进行后续分配,否则内存会耗尽。这看起来对于一个分配器来说可能是一个显而易见的要求,但有些分配器并不会这样做。一个例子就是将在下一篇文章中解释的 bump 分配器。
运行集成测试:
> cargo test --test heap_allocation
Running 3 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
所有三项测试都已成功!你也可以调用 cargo test(不带 --test 参数)来运行所有的单元测试和集成测试。
🔗总结
本文介绍了动态内存,并解释了它的必要性及应用场景。我们了解了 Rust 的借用检查器如何防止常见的漏洞,以及 Rust 的内存分配 API 的工作原理。
在通过一个虚拟分配器实现了 Rust 分配器接口的最小版本后,我们为内核创建了一个合适的堆内存区域。为此,我们定义了堆的虚拟地址范围,然后使用上一篇文章中的 Mapper 和 FrameAllocator 将该范围的所有页面映射到物理内存。
最后,我们添加了对 linked_list_allocator crate 的依赖,为内核添加了一个合适的分配器。有了这个分配器,我们就可以使用 Box、Vec 以及 alloc crate 中的其他分配和集合类型了。
🔗下篇预告
尽管我们在这篇文章中已经添加了堆分配支持,但大部分工作都留给了 linked_list_allocator crate。下一篇文章将详细展示如何从头开始实现一个分配器。它将介绍多种可能的分配器设计,展示如何实现它们的简单版本,并解释它们的优缺点。
评论
你有问题需要解决,想要分享反馈,或者讨论更多的想法吗?请随时在这里留下评论!请使用尽量使用英文并遵循 Rust 的 code of conduct. 这个讨论串将与 discussion on GitHub 直接连接,所以你也可以直接在那边发表评论
Instead of authenticating the giscus application, you can also comment directly on GitHub.
请尽可能使用英语评论。