分页实现
翻译内容: 这是对原文章 Paging Implementation 的社区中文翻译。它可能不完整,过时或者包含错误。可以在 这个 Issue 上评论和提问!
这篇文章展示了如何在我们的内核中实现分页支持。它首先探讨了使物理页表帧能够被内核访问的不同技术,并讨论了它们各自的优点和缺点。然后,它实现了一个地址转换功能和一个创建新映射的功能。
这个系列的 blog 在GitHub上开放开发,如果你有任何问题,请在这里开一个 issue 来讨论。当然你也可以在底部留言。你可以在post-09找到这篇文章的完整源码。
目录
🔗介绍
前文已经对分页的概念做了介绍。通过比较分页和分段来证明分页的优势,然后解释了分页和页表如何工作,最后介绍了x86_64的4级页表设计。此时 bootloader 已经为内核建立了一个页表层次结构,这意味着内核已经在虚拟地址上运行。这样做提高了安全性,因为非法的内存访问会导致页面故障异常,而不是修改任意的物理内存。
这篇文章最后说,我们不能从内核中访问页表,因为它们存储在物理内存中,而内核已经在虚拟地址上运行。
这篇文章探讨了使页表框能够被内核访问的不同方法。接下来将讨论每种方法的优点和缺点,最后决定内核采用哪种方法。
为了实现这个方法,我们需要 bootloader 的支持,所以首先要配置它。之后将实现一个遍历页表层次结构的函数,以便将虚拟地址转换为物理地址。最后,我们学习如何在页表中创建新的映射,以及如何为创建新的页表找到未使用的内存框。
🔗访问页表
从内核中访问页表并不像它看起来那么容易。为了理解这个问题,让我们再看一下上一篇文章中的4级页表层次结构的例子。

这里重要的是,每个页面条目都存储了下一个表的 物理 地址。这就避免了对这些地址也要进行翻译,这对性能不利,而且容易造成无休止的翻译循环。
此时的问题是,内核无法直接访问物理地址,因为内核也是在虚拟地址之上运行的。例如,当访问地址4 KiB时,访问的是 虚拟 地址4 KiB,而不是存储4级页表的 物理 地址4 KiB。
因此,为了访问页表框架,我们需要将一些虚拟页面映射到它们。有不同的方法来创建这些映射,这些映射都允许我们访问任意的页表框架。
🔗直接映射
一个简单的解决方案是所有页表的身份映射。

在这个例子中,我们看到各种直接映射的页表框架。页表的物理地址也是有效的虚拟地址,这样我们就可以很容易地访问从CR3寄存器开始的各级页表。
然而,它使虚拟地址空间变得杂乱无章,并使寻找较大尺寸的连续内存区域更加困难。例如,想象一下,我们想在上述图形中创建一个大小为1000 KiB的虚拟内存区域,例如: memory-mapping a file。我们不能在28 KiB处开始区域,因为它将与1004 KiB处已经映射的页面相撞。所以我们必须进一步寻找,直到找到一个足够大的未映射区域,例如在1008 KiB。这是一个类似于segmentation的碎片化问题。
同样,这也使得创建新的页表更加困难,因为我们需要找到对应的页还没有被使用的物理框。例如,让我们假设我们为我们的内存映射文件保留了 虚拟 1000 KiB内存区域,从1008 KiB开始。现在我们不能再使用任何物理地址在1000 KiB和2008 KiB之间的帧,因为我们不能对它进行 identity map 。
🔗映射一个固定的偏移
为了避免虚拟地址空间的杂乱问题,我们可以使用一个单独的内存区域来进行页表映射。因此,我们不是以直接映射页表帧,而是以虚拟地址空间中的固定偏移量来映射它们。例如,偏移量可以是10 TiB。

通过使用范围为10 TiB...(10 TiB + 物理内存大小)的虚拟内存专门用于页表映射,避免了直接映射的碰撞问题。只有当虚拟地址空间比物理内存大小大得多时,保留如此大的虚拟地址空间区域才有可能。这在x86_64上不是一个问题,因为48位的地址空间有256 TiB大。
这种方法仍然有一个缺点,即每当我们创建一个新的页表时,我们都需要创建一个新的映射。另外,它不允许访问其他地址空间的页表,这在创建新进程时是很有用的。
🔗映射完整的物理内存
我们可以通过映射完整的物理内存来解决这些问题,而不是只映射页表框架。

这种方法允许我们的内核访问任意的物理内存,包括其他地址空间的页表框架。保留的虚拟内存范围的大小与以前一样,不同的是它不再包含未映射的页面。
这种方法的缺点是,需要额外的页表来存储物理内存的映射。这些页表需要存储在某个地方,所以它们会占用一部分物理内存,这在内存较小的设备上可能是个问题。
然而,在x86_64上,我们可以使用大小为2 MiB的巨大页面进行映射,而不是默认的4 KiB页面。这样,映射32 GiB的物理内存只需要132 KiB的页表,因为只需要一个3级表和32个2级表。巨大页面也是更有效的缓存,因为它们在转换查找缓冲器(TLB)中使用的条目更少。
🔗临时映射
对于物理内存数量非常少的设备,我们可以在需要访问页表帧时,只对其进行临时映射页表。为了能够创建临时映射,我们只需要一个 identity-mapped 的1级表。

该图中的第1级表控制着虚拟地址空间的前2 MiB。这是因为它可以通过从CR3寄存器开始,按照第4级、第3级和第2级页面表中的第0个条目到达。索引为8的条目将地址为32 KiB的虚拟页映射到地址为32 KiB的物理帧,从而对1级表本身进行身份映射。图形显示了这种 identity-mapping ,在 “32 KiB “处有一个水平箭头。
通过写到 identity-mapped 的1级表,我们的内核可以创建多达511个临时映射(512减去直接映射需要的条目)。在上面的例子中,内核创建了两个临时映射。
- 通过将第1级表的第0条映射到地址为
24 KiB的帧,它创建了一个0 KiB的虚拟页到第2级页表的物理帧的临时映射,虚线箭头所示。 - 通过将第1级表的第9条映射到地址为
4 KiB的帧,它创建了一个36 KiB的虚拟页与第4级页表的物理帧的临时映射,虚线箭头所示。
现在内核可以通过写到0KiB页来访问2级页表,通过写到36KiB页来访问4级页表。
访问具有临时映射的任意页表框架的过程是:
- 在身份映射的第1级表中搜索一个自由条目。
- 将该条目映射到我们想要访问的页表的物理帧。
- 通过映射到该条目的虚拟页面访问目标框中。
- 将该条目设置为未使用,从而再次删除临时映射。
这种方法重复使用相同的512个虚拟页来创建映射,因此只需要4 KiB的物理内存。缺点是有点麻烦,尤其是一个新的映射可能需要对多个表层进行修改,这意味着我们需要多次重复上述过程。
🔗递归页表
另一种有趣的方法是根本不需要额外的页表,即映射页表的递归。这种方法背后思想是将一个条目从第4级页面表映射到第4级表本身。通过这样做,我们有效地保留了虚拟地址空间的一部分,并将所有当前和未来的页表框架映射到该空间。
让我们通过一个例子来了解这一切是如何进行的。

与本文开头的例子的唯一区别是在4级表中的索引511处增加了一个条目,它被映射到物理帧4 KiB,即4级表本身的帧。
通过让CPU跟随这个条目进行翻译,它不会到达3级表,而是再次到达同一个4级表。这类似于一个调用自身的递归函数,因此这个表被称为 递归页表 。重要的是,CPU假定4级表的每个条目都指向3级表,所以它现在把4级表当作3级表。这是因为所有级别的表在x86_64上都有完全相同的布局。
在我们开始实际翻译之前,通过跟随递归条目一次或多次,我们可以有效地缩短CPU所穿越的层数。例如,如果我们跟随递归条目一次,然后进入第3级表,CPU会认为第3级表是第2级表。再往前走,它把第2级表当作第1级表,把第1级表当作映射的框架。这意味着我们现在可以读写第1级页表了,因为CPU认为它是映射的帧。下面的图形说明了这五个转换步骤。

同样地,我们可以在开始翻译之前,先跟随递归条目两次,将遍历的层数减少到两个。

让我们一步一步地看下去。首先,CPU跟踪4级表的递归条目,认为它到达了3级表。然后,它再次跟踪递归条目,认为它到达了2级表。但实际上,它仍然是在第4级表中。当CPU现在跟随一个不同的条目时,它到达了一个3级表,但认为它已经在1级表上。因此,当下一个条目指向第2级表时,CPU认为它指向了映射的框架,这使得我们能够读写第2级表。
访问第3级和第4级表的方法是一样的。为了访问第3级表,我们沿着递归条目走了三次,诱使CPU认为它已经在第1级表上了。然后我们跟随另一个条目,到达第3级表,CPU将其视为一个映射的框架。对于访问第4级表本身,我们只需跟随递归条目四次,直到CPU将第4级表本身视为映射的框架(在下面的图形中为蓝色)。

可能需要一些时间来理解这个概念,但在实践中效果相当好。
在下面的章节中,我们将解释如何构建虚拟地址,用于跟随递归条目一次或多次。在我们的实现中,我们不会使用递归分页,所以你不需要阅读它就可以继续阅读本帖。如果你感兴趣,只需点击 “地址计算” 来展开。
地址计算
我们看到,在实际翻译之前,我们可以通过跟随递归条目一次或多次访问所有级别的表。由于进入四级表的索引直接来自于虚拟地址,我们需要为这种技术构建特殊的虚拟地址。请记住,页表的索引是以如下方式从地址派生的。

让我们假设我们想访问映射一个特定页面的第1级页面表。正如我们上面所学到的,这意味着我们必须在继续使用第4级、第3级和第2级索引之前,跟随递归条目一次。为了做到这一点,我们将地址的每个块向右移动一个块,并将原来的4级索引设置为递归条目的索引。

为了访问该页的第2级表,我们将每个索引块向右移动两个块,并将原第4级索引的块和原第3级索引都设置为递归条目的索引。

访问第3级表的工作方式是将每个块向右移动三个块,并使用原第4级、第3级和第2级地址块的递归索引。

最后,我们可以通过将每个区块向右移动四个区块,并对除偏移外的所有地址区块使用递归索引来访问第四级表。

现在我们可以计算出所有四级页表的虚拟地址。我们甚至可以通过将索引乘以8(一个页表项的大小)来计算出一个精确指向特定页表项的地址。
下表总结了访问不同种类框架的地址结构。
| Virtual Address for | Address Structure ([octal]) |
|---|---|
| Page | 0o_SSSSSS_AAA_BBB_CCC_DDD_EEEE |
| Level 1 Table Entry | 0o_SSSSSS_RRR_AAA_BBB_CCC_DDDD |
| Level 2 Table Entry | 0o_SSSSSS_RRR_RRR_AAA_BBB_CCCC |
| Level 3 Table Entry | 0o_SSSSSS_RRR_RRR_RRR_AAA_BBBB |
| Level 4 Table Entry | 0o_SSSSSS_RRR_RRR_RRR_RRR_AAAA |
而AAA是第4级索引,BBB是第3级索引,CCC是第2级索引,DDD是映射框架的第1级索引,EEEE是其中的偏移。RRR是递归条目的索引。当一个索引(三位数)被转换为一个偏移量(四位数)时,它是通过乘以8(页表项的大小)来完成。有了这个偏移量,产生的地址直接指向相应的页表项。
SSSSSS是符号扩展位,这意味着它们都是第47位的副本。这是对x86_64架构上有效地址的特殊要求。上篇文章解释过。
我们使用八进制数字来表示地址,因为每个八进制字符代表三个比特,这使我们能够清楚地分开不同页表层的9比特索引。这在十六进制系统中是不可能的,每个字符代表四个比特。
🔗在Rust代码中
为了在Rust代码中构建这样的地址,可以使用位操作。
// 你想访问其对应的页表的虚拟地址
let addr: usize = […];
let r = 0o777; // 递归索引
let sign = 0o177777 << 48; // 符号扩展
// 检索我们要翻译的地址的页表索引
let l4_idx = (addr >> 39) & 0o777; // level 4 索引
let l3_idx = (addr >> 30) & 0o777; // level 3 索引
let l2_idx = (addr >> 21) & 0o777; // level 2 索引
let l1_idx = (addr >> 12) & 0o777; // level 1 索引
let page_offset = addr & 0o7777;
// 计算页表的地址
let level_4_table_addr =
sign | (r << 39) | (r << 30) | (r << 21) | (r << 12);
let level_3_table_addr =
sign | (r << 39) | (r << 30) | (r << 21) | (l4_idx << 12);
let level_2_table_addr =
sign | (r << 39) | (r << 30) | (l4_idx << 21) | (l3_idx << 12);
let level_1_table_addr =
sign | (r << 39) | (l4_idx << 30) | (l3_idx << 21) | (l2_idx << 12);上面的代码假设索引为0o777(511)的最后一个4级条目是递归映射的。目前不是这样的,所以这段代码还不能工作。请看下面如何告诉bootloader来设置递归映射。
除了手工进行位操作外,你可以使用x86_64板块的递归页表类型,它为各种页表操作提供安全的抽象。例如,下面的代码显示了如何将一个虚拟地址转换为其映射的物理地址。
// in src/memory.rs
use x86_64::structures::paging::{Mapper, Page, PageTable, RecursivePageTable};
use x86_64::{VirtAddr, PhysAddr};
/// 从第4级地址创建一个RecursivePageTable实例。
let level_4_table_addr = […];
let level_4_table_ptr = level_4_table_addr as *mut PageTable;
let recursive_page_table = unsafe {
let level_4_table = &mut *level_4_table_ptr;
RecursivePageTable::new(level_4_table).unwrap();
}
/// 检索给定虚拟地址的物理地址
let addr: u64 = […]
let addr = VirtAddr::new(addr);
let page: Page = Page::containing_address(addr);
// 进行翻译
let frame = recursive_page_table.translate_page(page);
frame.map(|frame| frame.start_address() + u64::from(addr.page_offset()))同样,这个代码需要一个有效的递归映射。有了这样的映射,缺失的 level_4_table_addr 可以像第一个代码例子那样被计算出来。
递归分页是一种有趣的技术,它显示了页表中的单个映射可以有多么强大。它比较容易实现,而且只需要少量的设置(只是一个单一的递归条目),所以它是第一次实验分页的一个好选择。
然而,它也有一些弊端:
- 它占据了大量的虚拟内存(512 GiB)。在大的48位地址空间中,这不是一个大问题,但它可能会导致次优的缓存行为。
- 它只允许轻松访问当前活动的地址空间。通过改变递归条目,访问其他地址空间仍然是可能的,但切换回来时需要一个临时映射。我们在(已过期的)Remap The Kernel 文章“地址空间 “中描述了如何做到这一点。
- 它在很大程度上依赖于x86的页表格式,在其他架构上可能无法工作。
🔗支持引导器
所有这些方法的设置都需要对页表进行修改。例如,需要创建物理内存的映射,或者需要对4级表的一个条目进行递归映射。问题是,如果没有访问页表的现有方法,我们就无法创建这些所需的映射。
这意味着我们需要 bootloader 的帮助,bootloader 创建了内核运行的页表。Bootloader 可以访问页表,所以它可以创建内核需要的任何映射。在目前的实现中,“bootloader” 工具箱支持上述两种方法,通过 cargo features 进行控制。
map_physical_memory功能将某处完整的物理内存映射到虚拟地址空间。因此,内核可以访问所有的物理内存,并且可以遵循映射完整物理内存的方法。- 有了 “recursive_page_table” 功能,bootloader会递归地映射4级page table的一个条目。这允许内核访问页表,如递归页表部分所述。
我们为我们的内核选择了第一种方法,因为它很简单,与平台无关,而且更强大(它还允许访问非页表框架)。为了启用所需的引导程序支持,我们在 “引导程序” 的依赖中加入了 “map_physical_memory“功能。
[dependencies]
bootloader = { version = "0.9", features = ["map_physical_memory"]}启用这个功能后,bootloader 将整个物理内存映射到一些未使用的虚拟地址范围。为了将虚拟地址范围传达给我们的内核,bootloader 传递了一个 启动信息 结构。
🔗启动信息
Bootloader 板块定义了一个BootInfo结构,包含了它传递给我们内核的所有信息。这个结构还处于早期阶段,所以在更新到未来的 semver-incompatible bootloader 版本时,可能会出现一些故障。在启用 “map_physical_memory” 功能后,它目前有两个字段 “memory_map” 和 “physical_memory_offset”。
memory_map字段包含了可用物理内存的概览。它告诉我们的内核,系统中有多少物理内存可用,哪些内存区域被保留给设备,如VGA硬件。内存图可以从BIOS或UEFI固件中查询,但只能在启动过程的早期查询。由于这个原因,它必须由引导程序提供,因为内核没有办法在以后检索到它。在这篇文章的后面我们将需要内存图。physical_memory_offset告诉我们物理内存映射的虚拟起始地址。通过把这个偏移量加到物理地址上,我们得到相应的虚拟地址。这使得我们可以从我们的内核中访问任意的物理内存。- 这个物理内存偏移可以通过在Cargo.toml中添加一个
[package.metadata.bootloader]表并设置physical-memory-offset = "0x0000f00000000000"(或任何其他值)来定制。然而,请注意,如果bootloader遇到物理地址值开始与偏移量以外的空间重叠,也就是说,它以前会映射到其他早期的物理地址的区域,就会出现恐慌。所以一般来说,这个值越高(>1 TiB)越好。
Bootloader将 BootInfo 结构以 &'static BootInfo参数的形式传递给我们的内核,并传递给我们的_start函数。我们的函数中还没有声明这个参数,所以让我们添加它。
// in src/main.rs
use bootloader::BootInfo;
#[unsafe(no_mangle)]
pub extern "C" fn _start(boot_info: &'static BootInfo) -> ! { // new argument
[…]
}以前省去这个参数并不是什么问题,因为x86_64的调用惯例在CPU寄存器中传递第一个参数。因此,当这个参数没有被声明时,它被简单地忽略了。然而,如果我们不小心使用了一个错误的参数类型,那将是一个问题,因为编译器不知道我们入口点函数的正确类型签名。
🔗entry_point 宏
由于我们的_start函数是在外部从引导程序中调用的,所以没有对我们的函数签名进行检查。这意味着我们可以让它接受任意参数而不出现任何编译错误,但在运行时它会失败或导致未定义行为。
为了确保入口点函数总是具有引导程序所期望的正确签名,bootloader板块提供了一个entry_point宏,它提供了一种类型检查的方法来定义一个Rust函数作为入口点。让我们重写我们的入口点函数来使用这个宏。
// in src/main.rs
use bootloader::{BootInfo, entry_point};
entry_point!(kernel_main);
fn kernel_main(boot_info: &'static BootInfo) -> ! {
[…]
}我们不再需要使用extern "C"或no_mangle作为我们的入口点,因为宏为我们定义了真正的低级_start入口点。kernel_main函数现在是一个完全正常的Rust函数,所以我们可以为它选择一个任意的名字。重要的是,它是经过类型检查的,所以当我们使用一个错误的函数签名时,例如增加一个参数或改变参数类型,就会发生编译错误。
让我们在我们的lib.rs中进行同样的修改。
// in src/lib.rs
#[cfg(test)]
use bootloader::{entry_point, BootInfo};
#[cfg(test)]
entry_point!(test_kernel_main);
/// Entry point for `cargo test`
#[cfg(test)]
fn test_kernel_main(_boot_info: &'static BootInfo) -> ! {
// like before
init();
test_main();
hlt_loop();
}由于这个入口点只在测试模式下使用,我们在所有项目中添加了#[cfg(test)]属性。我们给我们的测试入口点一个独特的名字test_kernel_main,以避免与我们的main.rs的kernel_main混淆。我们现在不使用BootInfo参数,所以我们在参数名前加上_,以消除未使用变量的警告。
🔗实现
现在我们可以访问物理内存了,我们终于可以开始实现我们的页表代码了。首先,我们将看一下我们的内核目前运行的活动页表。第二步,我们将创建一个转换函数,返回一个给定的虚拟地址所映射到的物理地址。作为最后一步,我们将尝试修改页表,以便创建一个新的映射。
在我们开始之前,我们为我们的代码创建一个新的memory模块。
// in src/lib.rs
pub mod memory;对于该模块,我们创建一个空的src/memory.rs文件。
🔗访问页表
在上一篇文章的结尾,我们试图查看我们的内核运行的页表,但是由于我们无法访问CR3寄存器所指向的物理帧而失败了。我们现在可以通过创建一个active_level_4_table函数来继续,该函数返回对活动的4级页面表的引用。
// in src/memory.rs
use x86_64::{
structures::paging::PageTable,
VirtAddr,
};
/// 返回一个对活动的4级表的可变引用。
///
/// 这个函数是不安全的,因为调用者必须保证完整的物理内存在传递的
/// `physical_memory_offset`处被映射到虚拟内存。另外,这个函数
/// 必须只被调用一次,以避免别名"&mut "引用(这是未定义的行为)。
pub unsafe fn active_level_4_table(physical_memory_offset: VirtAddr)
-> &'static mut PageTable
{
use x86_64::registers::control::Cr3;
let (level_4_table_frame, _) = Cr3::read();
let phys = level_4_table_frame.start_address();
let virt = physical_memory_offset + phys.as_u64();
let page_table_ptr: *mut PageTable = virt.as_mut_ptr();
unsafe { &mut *page_table_ptr }
}首先,我们从CR3寄存器中读取活动的4级表的物理帧。然后我们取其物理起始地址,将其转换为u64,并将其添加到physical_memory_offset中,得到页表框架映射的虚拟地址。最后,我们通过as_mut_ptr方法将虚拟地址转换为*mut PageTable原始指针,然后不安全地从它创建一个&mut PageTable引用。我们创建一个&mut引用,而不是&引用,因为我们将在本篇文章的后面对页表进行突变。
现在我们可以用这个函数来打印第4级表格的条目。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
use blog_os::memory::active_level_4_table;
use x86_64::VirtAddr;
println!("Hello World{}", "!");
blog_os::init();
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let l4_table = unsafe { active_level_4_table(phys_mem_offset) };
for (i, entry) in l4_table.iter().enumerate() {
if !entry.is_unused() {
println!("L4 Entry {}: {:?}", i, entry);
}
}
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
blog_os::hlt_loop();
}首先,我们将 “BootInfo” 结构的 “physical_memory_offset “转换为 VirtAddr,并将其传递给 active_level_4_table 函数。然后我们使用iter函数来迭代页表条目,并使用enumerate组合器为每个元素增加一个索引i。我们只打印非空的条目,因为所有512个条目在屏幕上是放不下的。
当我们运行它时,我们看到以下输出。
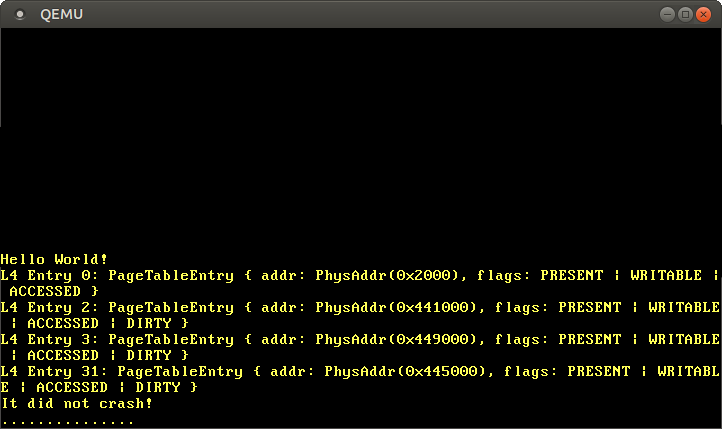
我们看到有各种非空条目,它们都映射到不同的3级表。有这么多区域是因为内核代码、内核堆栈、物理内存映射和启动信息都使用独立的内存区域。
为了进一步遍历页表,看一下三级表,我们可以把一个条目的映射帧再转换为一个虚拟地址。
// in the `for` loop in src/main.rs
use x86_64::structures::paging::PageTable;
if !entry.is_unused() {
println!("L4 Entry {}: {:?}", i, entry);
// get the physical address from the entry and convert it
let phys = entry.frame().unwrap().start_address();
let virt = phys.as_u64() + boot_info.physical_memory_offset;
let ptr = VirtAddr::new(virt).as_mut_ptr();
let l3_table: &PageTable = unsafe { &*ptr };
// print non-empty entries of the level 3 table
for (i, entry) in l3_table.iter().enumerate() {
if !entry.is_unused() {
println!(" L3 Entry {}: {:?}", i, entry);
}
}
}对于查看2级和1级表,我们对3级和2级条目重复这一过程。你可以想象,这很快就会变得非常冗长,所以我们不在这里展示完整的代码。
手动遍历页表是很有趣的,因为它有助于了解CPU是如何进行转换的。然而,大多数时候,我们只对给定的虚拟地址的映射物理地址感兴趣,所以让我们为它创建一个函数。
🔗翻译地址
为了将虚拟地址转换为物理地址,我们必须遍历四级页表,直到到达映射的帧。让我们创建一个函数来执行这种转换。
// in src/memory.rs
use x86_64::PhysAddr;
/// 将给定的虚拟地址转换为映射的物理地址,如果地址没有被映射,则为`None'。
///
/// 这个函数是不安全的,因为调用者必须保证完整的物理内存在传递的`physical_memory_offset`处被映射到虚拟内存。
pub unsafe fn translate_addr(addr: VirtAddr, physical_memory_offset: VirtAddr)
-> Option<PhysAddr>
{
translate_addr_inner(addr, physical_memory_offset)
}我们将该函数转发到一个安全的translate_addr_inner函数,以限制unsafe的范围。正如我们在上面指出的,Rust把一个unsafe fn的完整主体当作一个大的不安全块。通过调用一个私有的安全函数,我们使每个unsafe操作再次明确。
私有内部函数包含真正的实现:
// in src/memory.rs
/// 由 `translate_addr`调用的私有函数。
///
/// 这个函数是安全的,可以限制`unsafe`的范围,
/// 因为Rust将不安全函数的整个主体视为不安全块。
/// 这个函数只能通过`unsafe fn`从这个模块的外部到达。
fn translate_addr_inner(addr: VirtAddr, physical_memory_offset: VirtAddr)
-> Option<PhysAddr>
{
use x86_64::structures::paging::page_table::FrameError;
use x86_64::registers::control::Cr3;
// 从CR3寄存器中读取活动的4级 frame
let (level_4_table_frame, _) = Cr3::read();
let table_indexes = [
addr.p4_index(), addr.p3_index(), addr.p2_index(), addr.p1_index()
];
let mut frame = level_4_table_frame;
// 遍历多级页表
for &index in &table_indexes {
// 将该框架转换为页表参考
let virt = physical_memory_offset + frame.start_address().as_u64();
let table_ptr: *const PageTable = virt.as_ptr();
let table = unsafe {&*table_ptr};
// 读取页表条目并更新`frame`。
let entry = &table[index];
frame = match entry.frame() {
Ok(frame) => frame,
Err(FrameError::FrameNotPresent) => return None,
Err(FrameError::HugeFrame) => panic!("huge pages not supported"),
};
}
// 通过添加页面偏移量来计算物理地址
Some(frame.start_address() + u64::from(addr.page_offset()))
}我们没有重复使用active_level_4_table函数,而是再次从CR3寄存器读取4级帧。我们这样做是因为它简化了这个原型的实现。别担心,我们一会儿就会创建一个更好的解决方案。
VirtAddr结构已经提供了计算四级页面表索引的方法。我们将这些索引存储在一个小数组中,因为它允许我们使用for循环遍历页表。在循环之外,我们记住了最后访问的frame,以便以后计算物理地址。frame在迭代时指向页表框架,在最后一次迭代后指向映射的框架,也就是在跟随第1级条目之后。
在这个循环中,我们再次使用physical_memory_offset将帧转换为页表引用。然后我们读取当前页表的条目,并使用PageTableEntry::frame函数来检索映射的框架。如果该条目没有映射到一个框架,我们返回None。如果该条目映射了一个巨大的2 MiB或1 GiB页面,我们就暂时慌了。
让我们通过翻译一些地址来测试我们的翻译功能。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// new import
use blog_os::memory::translate_addr;
[…] // hello world and blog_os::init
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let addresses = [
// the identity-mapped vga buffer page
0xb8000,
// some code page
0x201008,
// some stack page
0x0100_0020_1a10,
// virtual address mapped to physical address 0
boot_info.physical_memory_offset,
];
for &address in &addresses {
let virt = VirtAddr::new(address);
let phys = unsafe { translate_addr(virt, phys_mem_offset) };
println!("{:?} -> {:?}", virt, phys);
}
[…] // test_main(), "it did not crash" printing, and hlt_loop()
}当我们运行它时,我们看到以下输出。
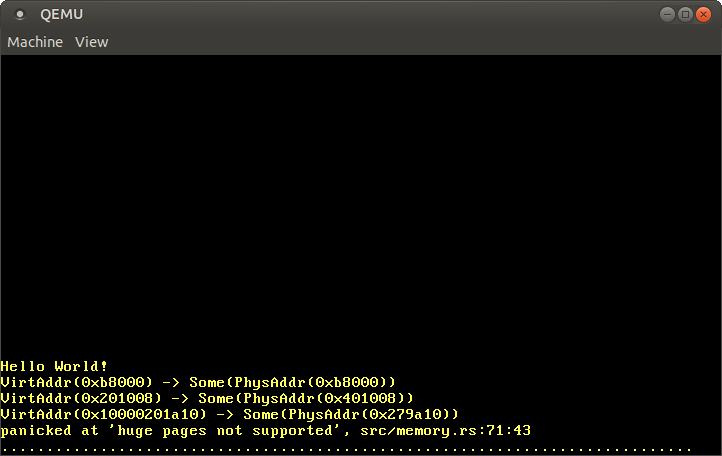
正如预期的那样,身份映射的地址0xb8000翻译成了相同的物理地址。代码页和堆栈页翻译成了一些任意的物理地址,这取决于引导程序如何为我们的内核创建初始映射。值得注意的是,最后12位在翻译后总是保持不变,这是有道理的,因为这些位是page offset,不是翻译的一部分。
由于每个物理地址都可以通过添加physical_memory_offset来访问,physical_memory_offset地址的翻译本身应该指向物理地址0。然而,翻译失败了,因为映射使用了巨大的页面来提高效率,而我们的实现还不支持。
🔗使用 OffsetPageTable
将虚拟地址转换为物理地址是操作系统内核中的一项常见任务,因此x86_64内核为它提供了一个抽象。这个实现已经支持巨大的页面和除了 “translate_addr “之外的其他几个页表函数,所以我们将在下面使用它,而不是在我们自己的实现中添加巨大的页面支持。
抽象的基础是两个特征,它们定义了各种页表映射功能。
Mapper特质在页面大小上是通用的,并提供对页面进行操作的函数。例如translate_page,它将一个给定的页面翻译成相同大小的框架,以及map_to,它在页面表中创建一个新的映射。Translate特性提供了与多个页面大小有关的函数,如translate_addr或一般translate。
特质只定义接口,不提供任何实现。x86_64板块目前提供了三种类型来实现不同要求的特征。OffsetPageTable 类型假设完整的物理内存被映射到虚拟地址空间的某个偏移处。MappedPageTable更灵活一些。它只要求每个页表帧在一个可计算的地址处被映射到虚拟地址空间。最后,递归页表类型可以用来通过递归页表访问页表框架。
在我们的例子中,bootloader在physical_memory_offset变量指定的虚拟地址上映射完整的物理内存,所以我们可以使用OffsetPageTable类型。为了初始化它,我们在memory模块中创建一个新的init函数。
use x86_64::structures::paging::OffsetPageTable;
/// 初始化一个新的OffsetPageTable。
///
/// 这个函数是不安全的,因为调用者必须保证完整的物理内存在
/// 传递的`physical_memory_offset`处被映射到虚拟内存。另
/// 外,这个函数必须只被调用一次,以避免别名"&mut "引用(这是未定义的行为)。
pub unsafe fn init(physical_memory_offset: VirtAddr) -> OffsetPageTable<'static> {
unsafe {
let level_4_table = active_level_4_table(physical_memory_offset);
OffsetPageTable::new(level_4_table, physical_memory_offset)
}
}
// 私下进行
unsafe fn active_level_4_table(physical_memory_offset: VirtAddr)
-> &'static mut PageTable
{…}该函数接受 “physical_memory_offset “作为参数,并返回一个新的 “OffsetPageTable “实例,该实例具有 “静态 “寿命。这意味着该实例在我们内核的整个运行时间内保持有效。在函数体中,我们首先调用 “active_level_4_table “函数来获取4级页表的可变引用。然后我们用这个引用调用OffsetPageTable::new 函数。作为第二个参数,new函数希望得到物理内存映射开始的虚拟地址,该地址在physical_memory_offset变量中给出。
从现在开始,active_level_4_table函数只能从init函数中调用,因为它在多次调用时很容易导致别名的可变引用,这可能导致未定义的行为。出于这个原因,我们通过删除pub指定符使该函数成为私有的。
我们现在可以使用Translate::translate_addr方法而不是我们自己的memory::translate_addr函数。我们只需要在kernel_main中修改几行。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// new: different imports
use blog_os::memory;
use x86_64::{structures::paging::Translate, VirtAddr};
[…] // hello world and blog_os::init
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
// new: initialize a mapper
let mapper = unsafe { memory::init(phys_mem_offset) };
let addresses = […]; // same as before
for &address in &addresses {
let virt = VirtAddr::new(address);
// new: use the `mapper.translate_addr` method
let phys = mapper.translate_addr(virt);
println!("{:?} -> {:?}", virt, phys);
}
[…] // test_main(), "it did not crash" printing, and hlt_loop()
}我们需要导入Translate特性,以便使用它提供的translate_addr方法。
当我们现在运行它时,我们看到和以前一样的翻译结果,不同的是,巨大的页面翻译现在也在工作。
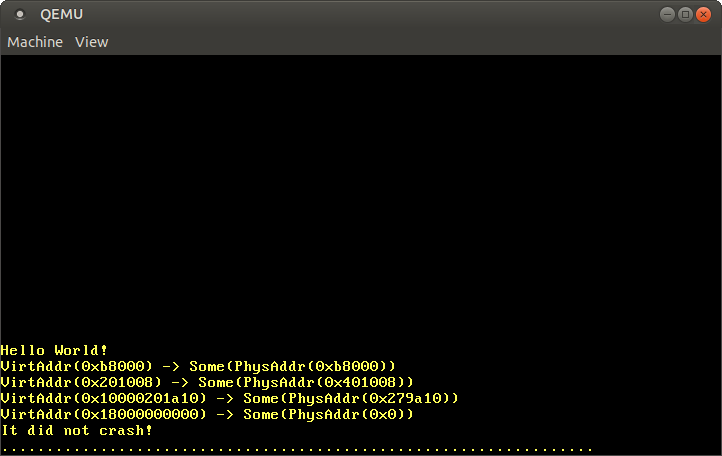
正如预期的那样,0xb8000的翻译以及代码和堆栈地址与我们自己的翻译函数保持一致。此外,我们现在看到,虚拟地址physical_memory_offset被映射到物理地址0x0。
通过使用MappedPageTable类型的翻译函数,我们可以免除实现巨大页面支持的工作。我们还可以访问其他的页面函数,如map_to,我们将在下一节使用。
在这一点上,我们不再需要memory::translate_addr和memory::translate_addr_inner函数,所以我们可以删除它们。
🔗创建一个新的映射
到目前为止,我们只看了页面表而没有修改任何东西。让我们改变这种情况,为一个以前没有映射的页面创建一个新的映射。
我们将使用Mapper特性的map_to函数来实现,所以让我们先看一下这个函数。文档告诉我们,它需要四个参数:我们想要映射的页面,该页面应该被映射到的框架,一组页面表项的标志,以及一个frame_allocator。之所以需要框架分配器,是因为映射给定的页面可能需要创建额外的页表,而页表需要未使用的框架作为后备存储。
🔗create_example_mapping 函数
我们实现的第一步是创建一个新的create_example_mapping函数,将一个给定的虚拟页映射到0xb8000,VGA文本缓冲区的物理帧。我们选择这个帧是因为它允许我们很容易地测试映射是否被正确创建。我们只需要写到新映射的页面,看看是否看到写的内容出现在屏幕上。
create_example_mapping 函数看起来像这样:
// in src/memory.rs
use x86_64::{
PhysAddr,
structures::paging::{Page, PhysFrame, Mapper, Size4KiB, FrameAllocator}
};
/// 为给定的页面创建一个实例映射到框架`0xb8000`。
pub fn create_example_mapping(
page: Page,
mapper: &mut OffsetPageTable,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) {
use x86_64::structures::paging::PageTableFlags as Flags;
let frame = PhysFrame::containing_address(PhysAddr::new(0xb8000));
let flags = Flags::PRESENT | Flags::WRITABLE;
let map_to_result = unsafe {
// FIXME: 这并不安全,我们这样做只是为了测试。
mapper.map_to(page, frame, flags, frame_allocator)
};
map_to_result.expect("map_to failed").flush();
}除了应该被映射的 “page “之外,该函数还希望得到一个对 “OffsetPageTable “实例和 “frame_allocator “的可变引用。参数 “frame_allocator “使用impl Trait语法,在所有实现FrameAllocator特征的类型中是通用的。该特性在PageSize特性上是通用的,可以处理标准的4 KiB页面和巨大的2 MiB/1 GiB页面。我们只想创建一个4 KiB的映射,所以我们设置通用参数为Size4KiB。
map_to方法是不安全的,因为调用者必须确保该帧没有被使用。原因是两次映射同一帧可能导致未定义的行为,例如当两个不同的&mut引用指向同一物理内存位置时。在我们的例子中,我们重新使用了已经被映射的VGA文本缓冲区帧,所以我们打破了所需的条件。然而,create_example_mapping函数只是一个临时的测试函数,在这篇文章之后会被删除,所以它是可以的。为了提醒我们不安全,我们在这行上加了一个FIXME注释。
除了 “page “和 “unused_frame “之外,“map_to “方法还需要一组用于映射的标志和对 “frame_allocator “的引用,这将在稍后解释。对于标志,我们设置了PRESENT标志,因为所有有效的条目都需要它,而WRITABLE标志是为了使映射的页面可写。关于所有可能的标志的列表,请参见上一篇文章的页表格式部分。
map_to函数可能失败,所以它返回一个Result。由于这只是一些不需要健壮的示例代码,我们只是使用expect来在发生错误时进行恐慌。成功后,该函数返回一个MapperFlush类型,该类型提供了一个简单的方法,用其flush方法从翻译查找缓冲区(TLB)冲刷新映射的页面。像Result一样,该类型使用#[must_use]属性,在我们不小心忘记使用它时发出警告。
🔗一个假的 FrameAllocator
为了能够调用create_example_mapping,我们需要首先创建一个实现FrameAllocator特质的类型。如上所述,如果map_to需要新的页表,该特质负责为其分配框架。
让我们从简单的情况开始,假设我们不需要创建新的页面表。对于这种情况,一个总是返回 “无 “的框架分配器就足够了。我们创建这样一个空框架分配器来测试我们的映射函数。
// in src/memory.rs
/// 一个总是返回`None'的FrameAllocator。
pub struct EmptyFrameAllocator;
unsafe impl FrameAllocator<Size4KiB> for EmptyFrameAllocator {
fn allocate_frame(&mut self) -> Option<PhysFrame> {
None
}
}实现FrameAllocator是不安全的,因为实现者必须保证分配器只产生未使用的帧。否则,可能会发生未定义的行为,例如,当两个虚拟页被映射到同一个物理帧时。我们的 “空框架分配器 “只返回 “无”,所以在这种情况下,这不是一个问题。
🔗选择一个虚拟页面
我们现在有一个简单的框架分配器,我们可以把它传递给我们的create_example_mapping函数。然而,分配器总是返回 “无”,所以只有在创建映射时不需要额外的页表框架时,这才会起作用。为了理解什么时候需要额外的页表框架,什么时候不需要,让我们考虑一个例子。

图中左边是虚拟地址空间,右边是物理地址空间,中间是页表。页表被存储在物理内存框架中,用虚线表示。虚拟地址空间包含一个地址为0x803fe00000的单一映射页,用蓝色标记。为了将这个页面转换到它的框架,CPU在4级页表上行走,直到到达地址为36 KiB的框架。
此外,该图用红色显示了VGA文本缓冲区的物理帧。我们的目标是使用create_example_mapping函数将一个先前未映射的虚拟页映射到这个帧。由于我们的EmptyFrameAllocator总是返回None,我们想创建映射,这样就不需要分配器提供额外的帧。这取决于我们为映射选择的虚拟页。
图中显示了虚拟地址空间中的两个候选页,都用黄色标记。一个页面在地址0x803fdfd000,比映射的页面(蓝色)早3页。虽然4级和3级页表的索引与蓝色页相同,但2级和1级的索引不同(见上一篇)。2级表的不同索引意味着这个页面使用了一个不同的1级表。由于这个1级表还不存在,如果我们选择该页作为我们的例子映射,我们就需要创建它,这就需要一个额外的未使用的物理帧。相比之下,地址为0x803fe02000的第二个候选页就没有这个问题,因为它使用了与蓝色页面相同的1级页表。因此,所有需要的页表都已经存在。
总之,创建一个新的映射的难度取决于我们想要映射的虚拟页。在最简单的情况下,该页的1级页表已经存在,我们只需要写一个条目。在最困难的情况下,该页是在一个还不存在第三级的内存区域,所以我们需要先创建新的第三级、第二级和第一级页表。
为了用 “EmptyFrameAllocator “调用我们的 “create_example_mapping “函数,我们需要选择一个所有页表都已存在的页面。为了找到这样的页面,我们可以利用bootloader在虚拟地址空间的第一兆字节内加载自己的事实。这意味着这个区域的所有页面都存在一个有效的1级表。因此,我们可以选择这个内存区域中任何未使用的页面作为我们的例子映射,比如地址为0的页面。通常情况下,这个页面应该保持未使用状态,以保证解读空指针会导致页面故障,所以我们知道bootloader没有将其映射。
🔗创建映射
现在我们有了调用create_example_mapping函数所需的所有参数,所以让我们修改kernel_main函数来映射虚拟地址0的页面。由于我们将页面映射到VGA文本缓冲区的帧上,我们应该能够在之后通过它写到屏幕上。实现起来是这样的。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
use blog_os::memory;
use x86_64::{structures::paging::Page, VirtAddr}; // 新的导入
[…] // hello world and blog_os::init
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let mut mapper = unsafe { memory::init(phys_mem_offset) };
let mut frame_allocator = memory::EmptyFrameAllocator;
// 映射未使用的页
let page = Page::containing_address(VirtAddr::new(0));
memory::create_example_mapping(page, &mut mapper, &mut frame_allocator);
// 通过新的映射将字符串 `New!` 写到屏幕上。
let page_ptr: *mut u64 = page.start_address().as_mut_ptr();
unsafe { page_ptr.offset(400).write_volatile(0x_f021_f077_f065_f04e)};
[…] // test_main(), "it did not crash" printing, and hlt_loop()
}我们首先通过调用 “create_example_mapping “函数为地址为0的页面创建映射,并为 “mapper “和 “frame_allocator “实例提供一个可变的引用。这将页面映射到VGA文本缓冲区框架,所以我们应该在屏幕上看到对它的任何写入。
然后我们将页面转换为原始指针,并写一个值到偏移量400。我们不写到页面的开始,因为VGA缓冲区的顶行被下一个println直接移出了屏幕。我们写值0x_f021_f077_f065_f04e,表示白色背景上的字符串 “New!” 。正如我们在 “VGA文本模式” 帖子中所学到的,对VGA缓冲区的写入应该是不稳定的,所以我们使用write_volatile方法。
当我们在QEMU中运行它时,我们看到以下输出。
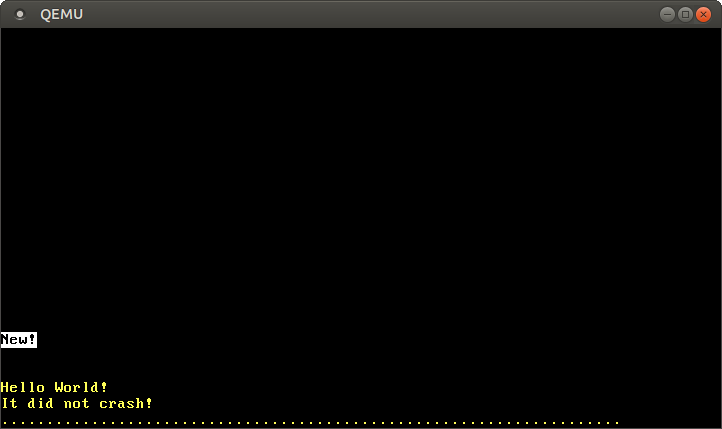
屏幕上的 “New!” 是由我们写到页0引起的,这意味着我们成功地在页表中创建了一个新的映射。
创建该映射只是因为负责地址为0的页面的1级表已经存在。当我们试图映射一个还不存在一级表的页面时,map_to函数失败了,因为它试图通过用EmptyFrameAllocator分配帧来创建新的页表。当我们试图映射0xdeadbeaf000而不是0页面时,我们可以看到这种情况发生。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
[…]
let page = Page::containing_address(VirtAddr::new(0xdeadbeaf000));
[…]
}当我们运行它时,出现了恐慌,并有以下错误信息。
panicked at 'map_to failed: FrameAllocationFailed', /…/result.rs:999:5为了映射那些还没有一级页表的页面,我们需要创建一个合适的FrameAllocator。但是我们如何知道哪些帧是未使用的,以及有多少物理内存是可用的?
🔗分配页框
为了创建新的页表,我们需要创建一个合适的框架分配器。为了做到这一点,我们使用由bootloader传递的memory_map,作为BootInfo结构的一部分。
// in src/memory.rs
use bootloader::bootinfo::MemoryMap;
/// 一个FrameAllocator,从bootloader的内存地图中返回可用的 frames。
pub struct BootInfoFrameAllocator {
memory_map: &'static MemoryMap,
next: usize,
}
impl BootInfoFrameAllocator {
/// 从传递的内存 map 中创建一个FrameAllocator。
///
/// 这个函数是不安全的,因为调用者必须保证传递的内存 map 是有效的。
/// 主要的要求是,所有在其中被标记为 "可用 "的帧都是真正未使用的。
pub unsafe fn init(memory_map: &'static MemoryMap) -> Self {
BootInfoFrameAllocator {
memory_map,
next: 0,
}
}
}该结构有两个字段。一个是对bootloader传递的内存 map 的 'static 引用,一个是跟踪分配器应该返回的下一帧的 next字段。
正如我们在启动信息部分所解释的,内存图是由 BIOS/UEFI 固件提供的。它只能在启动过程的早期被查询,所以引导程序已经为我们调用了相应的函数。内存地图由MemoryRegion结构列表组成,其中包含每个内存区域的起始地址、长度和类型(如未使用、保留等)。
init函数用一个给定的内存映射初始化一个BootInfoFrameAllocator。next字段被初始化为0,并将在每次分配帧时增加,以避免两次返回相同的帧。由于我们不知道内存映射的可用帧是否已经在其他地方被使用,我们的init函数必须是不安全的,以要求调用者提供额外的保证。
🔗一个 usable_frames 方法
在我们实现FrameAllocator特性之前,我们添加一个辅助方法,将内存映射转换为可用帧的迭代器。
// in src/memory.rs
use bootloader::bootinfo::MemoryRegionType;
impl BootInfoFrameAllocator {
/// 返回内存映射中指定的可用框架的迭代器。
fn usable_frames(&self) -> impl Iterator<Item = PhysFrame> {
// 从内存 map 中获取可用的区域
let regions = self.memory_map.iter();
let usable_regions = regions
.filter(|r| r.region_type == MemoryRegionType::Usable);
// 将每个区域映射到其地址范围
let addr_ranges = usable_regions
.map(|r| r.range.start_addr()..r.range.end_addr());
// 转化为一个帧起始地址的迭代器
let frame_addresses = addr_ranges.flat_map(|r| r.step_by(4096));
// 从起始地址创建 `PhysFrame` 类型
frame_addresses.map(|addr| PhysFrame::containing_address(PhysAddr::new(addr)))
}
}这个函数使用迭代器组合方法将初始的MemoryMap转化为可用的物理帧的迭代器。
- 首先,我们调用
iter方法,将内存映射转换为多个MemoryRegion的迭代器。 - 然后我们使用
filter方法跳过任何保留或其他不可用的区域。Bootloader为它创建的所有映射更新了内存地图,所以被我们的内核使用的帧(代码、数据或堆栈)或存储启动信息的帧已经被标记为InUse或类似的。因此,我们可以确定 “可使用” 的帧没有在其他地方使用。 - 之后,我们使用
map组合器和Rust的range语法将我们的内存区域迭代器转化为地址范围的迭代器。 - 接下来,我们使用
flat_map将地址范围转化为帧起始地址的迭代器,使用step_by选择每4096个地址。由于4096字节(=4 KiB)是页面大小,我们得到了每个帧的起始地址。Bootloader对所有可用的内存区域进行页对齐,所以我们在这里不需要任何对齐或舍入代码。通过使用flat_map而不是map,我们得到一个Iterator<Item = u64>而不是Iterator<Item = Iterator<Item = u64>。 - 最后,我们将起始地址转换为
PhysFrame类型,以构建一个Iterator<Item = PhysFrame>。
该函数的返回类型使用了impl Trait特性。这样,我们可以指定返回某个实现Iterator特质的类型,项目类型为PhysFrame,但不需要命名具体的返回类型。这在这里很重要,因为我们不能命名具体的类型,因为它依赖于不可命名的闭包类型。
🔗实现 FrameAllocator Trait
现在我们可以实现 FrameAllocator trait:
// in src/memory.rs
unsafe impl FrameAllocator<Size4KiB> for BootInfoFrameAllocator {
fn allocate_frame(&mut self) -> Option<PhysFrame> {
let frame = self.usable_frames().nth(self.next);
self.next += 1;
frame
}
}我们首先使用usable_frames方法,从内存 map 中获得一个可用帧的迭代器。然后,我们使用Iterator::nth函数来获取索引为self.next的帧(从而跳过(self.next - 1)帧)。在返回该帧之前,我们将self.next增加1,以便在下次调用时返回下一帧。
这个实现不是很理想,因为它在每次分配时都会重新创建usable_frame分配器。最好的办法是直接将迭代器存储为一个结构域。这样我们就不需要nth方法了,可以在每次分配时直接调用next。这种方法的问题是,目前不可能将 “impl Trait “类型存储在一个结构字段中。当 named existential types 完全实现时,它可能会在某一天发挥作用。
🔗使用 BootInfoFrameAllocator
我们现在可以修改我们的kernel_main函数来传递一个BootInfoFrameAllocator实例,而不是EmptyFrameAllocator。
// in src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
use blog_os::memory::BootInfoFrameAllocator;
[…]
let mut frame_allocator = unsafe {
BootInfoFrameAllocator::init(&boot_info.memory_map)
};
[…]
}通过启动信息框架分配器,映射成功了,我们又在屏幕上看到了白底黑字的 “New!” 。在幕后,map_to方法以如下方式创建了丢失的页表。
- 使用传递的
frame_allocator来分配一个未使用的框架。 - 将框架归零,创建一个新的、空的页表。
- 将上一级表的条目映射到该框架。
- 继续下一级的表。
虽然我们的create_example_mapping函数只是一些示例代码,但我们现在能够为任意的页面创建新的映射。这对于分配内存或在未来的文章中实现多线程是至关重要的。
此时,我们应该再次删除create_example_mapping函数,以避免意外地调用未定义的行为,正如 上面 所解释的那样。
🔗总结
在这篇文章中,我们了解了访问页表物理框架的不同技术,包括直接映射、完整物理内存的映射、临时映射和递归页表。我们选择了映射完整的物理内存,因为它简单、可移植,而且功能强大。
我们不能在没有页表访问的情况下从我们的内核映射物理内存,所以我们需要bootloader的支持。bootloader板块支持通过可选的 cargo 板块功能创建所需的映射。它以“&BootInfo “参数的形式将所需信息传递给我们的内核。
对于我们的实现,我们首先手动遍历页表以实现翻译功能,然后使用x86_64板块的MappedPageTable类型。我们还学习了如何在页表中创建新的映射,以及如何在引导程序传递的内存映射之上创建必要的 “FrameAllocator”。
🔗下篇文章是什么?
评论
你有问题需要解决,想要分享反馈,或者讨论更多的想法吗?请随时在这里留下评论!请使用尽量使用英文并遵循 Rust 的 code of conduct. 这个讨论串将与 discussion on GitHub 直接连接,所以你也可以直接在那边发表评论
Instead of authenticating the giscus application, you can also comment directly on GitHub.
请尽可能使用英语评论。