CPU异常处理
翻译内容: 这是对原文章 CPU Exceptions 的社区中文翻译。它可能不完整,过时或者包含错误。可以在 这个 Issue 上评论和提问!
翻译者: @liuyuran. With contributions from @JiangengDong 和 @Byacrya.
CPU异常在很多情况下都有可能发生,比如访问无效的内存地址,或者在除法运算里除以0。为了处理这些错误,我们需要设置一个 中断描述符表 来提供异常处理函数。在文章的最后,我们的内核将能够捕获 断点异常 并在处理后恢复正常执行。
这个系列的blog在GitHub上开放开发,如果你有任何问题,请在这里开一个issue来讨论。当然你也可以在底部留言。你可以在post-05找到这篇文章的完整源码。
🔗简述
异常信号会在当前指令触发错误时被触发,例如执行了除数为0的除法。当异常发生后,CPU会中断当前的工作,并立即根据异常类型调用对应的错误处理函数。
在x86架构中,存在20种不同的CPU异常类型,以下为最重要的几种:
- Page Fault: 页错误是被非法内存访问触发的,例如当前指令试图访问未被映射过的页,或者试图写入只读页。
- Invalid Opcode: 该错误是说当前指令操作符无效,比如在不支持SSE的旧式CPU上执行了 SSE 指令。
- General Protection Fault: 该错误的原因有很多,主要原因就是权限异常,即试图使用用户态代码执行核心指令,或是修改配置寄存器的保留字段。
- Double Fault: 当错误发生时,CPU会尝试调用错误处理函数,但如果 在调用错误处理函数过程中 再次发生错误,CPU就会触发该错误。另外,如果没有注册错误处理函数也会触发该错误。
- Triple Fault: 如果CPU调用了对应
Double Fault异常的处理函数依然没有成功,该错误会被抛出。这是一个致命级别的 三重异常,这意味着我们已经无法捕捉它,对于大多数操作系统而言,此时就应该重置数据并重启操作系统。
在 OSDev wiki 可以看到完整的异常类型列表。
🔗中断描述符表
要捕捉CPU异常,我们需要设置一个 中断描述符表 (Interrupt Descriptor Table, IDT),用来捕获每一个异常。由于硬件层面会不加验证的直接使用,所以我们需要根据预定义格式直接写入数据。符表的每一行都遵循如下的16字节结构。
| Type | Name | Description |
|---|---|---|
| u16 | Function Pointer [0:15] | 处理函数地址的低位(最后16位) |
| u16 | GDT selector | 全局描述符表中的代码段标记。 |
| u16 | Options | (如下所述) |
| u16 | Function Pointer [16:31] | 处理函数地址的中位(中间16位) |
| u32 | Function Pointer [32:63] | 处理函数地址的高位(剩下的所有位) |
| u32 | Reserved |
Options字段的格式如下:
| Bits | Name | Description |
|---|---|---|
| 0-2 | Interrupt Stack Table Index | 0: 不要切换栈, 1-7: 当处理函数被调用时,切换到中断栈表的第n层。 |
| 3-7 | Reserved | |
| 8 | 0: Interrupt Gate, 1: Trap Gate | 如果该比特被置为0,当处理函数被调用时,中断会被禁用。 |
| 9-11 | must be one | |
| 12 | must be zero | |
| 13‑14 | Descriptor Privilege Level (DPL) | 执行处理函数所需的最小特权等级。 |
| 15 | Present |
每个异常都具有一个预定义的IDT序号,比如 invalid opcode 异常对应6号,而 page fault 异常对应14号,因此硬件可以直接寻找到对应的IDT条目。 OSDev wiki中的 异常对照表 可以查到所有异常的IDT序号(在Vector nr.列)。
通常而言,当异常发生时,CPU会执行如下步骤:
- 将一些寄存器数据入栈,包括指令指针以及 RFLAGS 寄存器。(我们会在文章稍后些的地方用到这些数据。)
- 读取中断描述符表(IDT)的对应条目,比如当发生 page fault 异常时,调用14号条目。
- 判断该条目确实存在,如果不存在,则触发 double fault 异常。
- 如果该条目属于中断门(interrupt gate,bit 40 被设置为0),则禁用硬件中断。
- 将 GDT 选择器载入代码段寄存器(CS segment)。
- 跳转执行处理函数。
不过现在我们不必为4和5多加纠结,未来我们会单独讲解全局描述符表和硬件中断的。
🔗IDT类型
与其创建我们自己的IDT类型映射,不如直接使用 x86_64 crate 内置的 InterruptDescriptorTable 结构,其实现是这样的:
#[repr(C)]
pub struct InterruptDescriptorTable {
pub divide_by_zero: Entry<HandlerFunc>,
pub debug: Entry<HandlerFunc>,
pub non_maskable_interrupt: Entry<HandlerFunc>,
pub breakpoint: Entry<HandlerFunc>,
pub overflow: Entry<HandlerFunc>,
pub bound_range_exceeded: Entry<HandlerFunc>,
pub invalid_opcode: Entry<HandlerFunc>,
pub device_not_available: Entry<HandlerFunc>,
pub double_fault: Entry<HandlerFuncWithErrCode>,
pub invalid_tss: Entry<HandlerFuncWithErrCode>,
pub segment_not_present: Entry<HandlerFuncWithErrCode>,
pub stack_segment_fault: Entry<HandlerFuncWithErrCode>,
pub general_protection_fault: Entry<HandlerFuncWithErrCode>,
pub page_fault: Entry<PageFaultHandlerFunc>,
pub x87_floating_point: Entry<HandlerFunc>,
pub alignment_check: Entry<HandlerFuncWithErrCode>,
pub machine_check: Entry<HandlerFunc>,
pub simd_floating_point: Entry<HandlerFunc>,
pub virtualization: Entry<HandlerFunc>,
pub security_exception: Entry<HandlerFuncWithErrCode>,
// some fields omitted
}
每一个字段都是 idt::Entry<F> 类型,这个类型包含了一条完整的IDT条目(定义参见上文)。 其泛型参数 F 定义了中断处理函数的类型,在有些字段中该参数为 HandlerFunc,而有些则是 HandlerFuncWithErrCode,而对于 page fault 这种特殊异常,则为 PageFaultHandlerFunc。
首先让我们看一看 HandlerFunc 类型的定义:
type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
这是一个针对 extern "x86-interrupt" fn 类型的 类型别名。extern 关键字使用 外部调用约定 定义了一个函数,这种定义方式多用于和C语言代码通信(extern "C" fn),那么这里的外部调用约定又究竟调用了哪些东西?
🔗中断调用约定
异常触发十分类似于函数调用:CPU会直接跳转到处理函数的第一个指令处开始执行,执行结束后,CPU会跳转到返回地址,并继续执行之前的函数调用。
然而两者最大的不同点是:函数调用是由编译器通过 call 指令主动发起的,而错误处理函数则可能会由 任何 指令触发。要了解这两者所造成影响的不同,我们需要更深入的追踪函数调用。
调用约定 指定了函数调用的详细信息,比如可以指定函数的参数存放在哪里(寄存器,或者栈,或者别的什么地方)以及如何返回结果。在 x86_64 Linux 中,以下规则适用于C语言函数(指定于 System V ABI 标准):
- 前六个整型参数从寄存器传入
rdi,rsi,rdx,rcx,r8,r9 - 其他参数从栈传入
- 函数返回值存放在
rax和rdx
注意,Rust并不遵循C ABI,而是遵循自己的一套规则,即 尚未正式发布的 Rust ABI 草案,所以这些规则仅在使用 extern "C" fn 对函数进行定义时才会使用。
🔗保留寄存器和临时寄存器
调用约定将寄存器分为两部分:保留寄存器 和 临时寄存器 。
保留寄存器 的值应当在函数调用时保持不变,所以被调用的函数( “callee” )只有在保证“返回之前将这些寄存器的值恢复到初始值“的前提下,才被允许覆写这些寄存器的值, 在函数开始时将这类寄存器的值存入栈中,并在返回之前将之恢复到寄存器中是一种十分常见的做法。
而 临时寄存器 则相反,被调用函数可以无限制的反复写入寄存器,若调用者希望此类寄存器在函数调用后保持数值不变,则需要自己来处理备份和恢复过程(例如将其数值保存在栈中),因而这类寄存器又被称为 caller-saved。
在 x86_64 架构下,C调用约定指定了这些寄存器分类:
| 保留寄存器 | 临时寄存器 |
|---|---|
rbp, rbx, rsp, r12, r13, r14, r15 | rax, rcx, rdx, rsi, rdi, r8, r9, r10, r11 |
| callee-saved | caller-saved |
编译器已经内置了这些规则,因而可以自动生成保证程序正常执行的指令。例如绝大多数函数的汇编指令都以 push rbp 开头,也就是将 rbp 的值备份到栈中(因为它是 callee-saved 型寄存器)。
🔗保存所有寄存器数据
区别于函数调用,异常在执行 任何 指令时都有可能发生。在大多数情况下,我们在编译期不可能知道程序跑起来会发生什么异常。比如编译器无法预知某条指令是否会触发 page fault 或者 stack overflow。
正因我们不知道异常会何时发生,所以我们无法预先保存寄存器。这意味着我们无法使用依赖调用方备份 (caller-saved) 的寄存器的调用传统作为异常处理程序。因此,我们需要一个保存所有寄存器的传统。x86-interrupt 恰巧就是其中之一,它可以保证在函数返回时,寄存器里的值均返回原样。
但请注意,这并不意味着所有寄存器都会在进入函数时备份入栈。编译器仅会备份被函数覆写的寄存器,继而为只使用几个寄存器的短小函数生成高效的代码。
🔗中断栈帧
当一个常规函数调用发生时(使用 call 指令),CPU会在跳转目标函数之前,将返回地址入栈。当函数返回时(使用 ret 指令),CPU会在跳回目标函数之前弹出返回地址。所以常规函数调用的栈帧看起来是这样的:

对于错误和中断处理函数,仅仅压入一个返回地址并不足够,因为中断处理函数通常会运行在一个不那么一样的上下文中(栈指针、CPU flags等等)。所以CPU在遇到中断发生时是这么处理的:
- 对齐栈指针: 任何指令都有可能触发中断,所以栈指针可能是任何值,而部分CPU指令(比如部分SSE指令)需要栈指针16字节边界对齐,因此CPU会在中断触发后立刻为其进行对齐。
- 切换栈 (部分情况下): 当CPU特权等级改变时,例如当一个用户态程序触发CPU异常时,会触发栈切换。该行为也可能被所谓的 中断栈表 配置,在特定中断中触发,关于该表,我们会在下一篇文章做出讲解。
- 压入旧的栈指针: 当中断发生后,栈指针对齐之前,CPU会将栈指针寄存器(
rsp)和栈段寄存器(ss)的数据入栈,由此可在中断处理函数返回后,恢复上一层的栈指针。 - 压入并更新
RFLAGS寄存器:RFLAGS寄存器包含了各式各样的控制位和状态位,当中断发生时,CPU会改变其中的部分数值,并将旧值入栈。 - 压入指令指针: 在跳转中断处理函数之前,CPU会将指令指针寄存器(
rip)和代码段寄存器(cs)的数据入栈,此过程与常规函数调用中返回地址入栈类似。 - 压入错误码 (针对部分异常): 对于部分特定的异常,比如 page faults ,CPU会推入一个错误码用于标记错误的成因。
- 执行中断处理函数: CPU会读取对应IDT条目中描述的中断处理函数对应的地址和段描述符,将两者载入
rip和cs以开始运行处理函数。
所以 中断栈帧 看起来是这样的:

在 x86_64 crate 中,中断栈帧已经被 InterruptStackFrame 结构完整表达,该结构会以 &mut 的形式传入处理函数,并可以用于查询错误发生的更详细的原因。但该结构并不包含错误码字段,因为只有极少量的错误会传入错误码,所以对于这类需要传入 error_code 的错误,其函数类型变为了 HandlerFuncWithErrCode。
🔗幕后花絮
x86-interrupt 调用约定是一个十分厉害的抽象,它几乎隐藏了所有错误处理函数中的凌乱细节,但尽管如此,了解一下水面下发生的事情还是有用的。我们来简单介绍一下被 x86-interrupt 隐藏起来的行为:
- 传递参数: 绝大多数指定参数的调用约定都是期望通过寄存器取得参数的,但事实上这是无法实现的,因为我们不能在备份寄存器数据之前就将其复写。
x86-interrupt的解决方案时,将参数以指定的偏移量放到栈上。 - 使用
iretq返回: 由于中断栈帧和普通函数调用的栈帧是完全不同的,我们无法通过ret指令直接返回,所以此时必须使用iretq指令。 - 处理错误码: 部分异常传入的错误码会让错误处理更加复杂,它会造成栈指针对齐失效(见下一条),而且需要在返回之前从栈中弹出去。好在
x86-interrupt为我们挡住了这些额外的复杂度。但是它无法判断哪个异常对应哪个处理函数,所以它需要从函数参数数量上推断一些信息,因此程序员需要为每个异常使用正确的函数类型。当然你已经不需要烦恼这些,x86_64crate 中的InterruptDescriptorTable已经帮助你完成了定义。 - 对齐栈: 对于一些指令(尤其是SSE指令)而言,它们需要提前进行16字节边界对齐操作,通常而言CPU在异常发生之后就会自动完成这一步。但是部分异常会由于传入错误码而破坏掉本应完成的对齐操作,此时
x86-interrupt会为我们重新完成对齐。
如果你对更多细节有兴趣:我们还有关于使用 裸函数 展开异常处理的一个系列章节,参见 文末。
🔗实现
那么理论知识暂且到此为止,该开始为我们的内核实现CPU异常处理了。首先我们在 src/interrupts.rs 创建一个模块,并加入函数 init_idt 用来创建一个新的 InterruptDescriptorTable:
// in src/lib.rs
pub mod interrupts;
// in src/interrupts.rs
use x86_64::structures::idt::InterruptDescriptorTable;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
}
现在我们就可以添加处理函数了,首先给 breakpoint exception 添加。该异常是一个绝佳的测试途径,因为它唯一的目的就是在 int3 指令执行时暂停程序运行。
breakpoint exception 通常被用在调试器中:当程序员为程序打上断点,调试器会将对应的位置覆写为 int3 指令,CPU执行该指令后,就会抛出 breakpoint exception 异常。在调试完毕,需要程序继续运行时,调试器就会将原指令覆写回 int3 的位置。如果要了解更多细节,请查阅 “调试器是如何工作的” 系列。
不过现在我们还不需要覆写指令,只需要打印一行日志,表明接收到了这个异常,然后让程序继续运行即可。那么我们就来创建一个简单的 breakpoint_handler 方法并加入IDT中:
// in src/interrupts.rs
use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
use crate::println;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
}
extern "x86-interrupt" fn breakpoint_handler(
stack_frame: InterruptStackFrame)
{
println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
}
现在,我们的处理函数应当会输出一行信息以及完整的栈帧。
但当我们尝试编译的时候,报出了下面的错误:
error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
--> src/main.rs:53:1
|
53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
54 | | println!("EXCEPTION: BREAKPOINT\n{:#?}", stack_frame);
55 | | }
| |_^
|
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
这是因为 x86-interrupt 并不是稳定特性,需要手动启用,只需要在我们的 lib.rs 中加入 #![feature(abi_x86_interrupt)] 开关即可。
🔗载入 IDT
要让CPU使用新的中断描述符表,我们需要使用 lidt 指令来装载一下,x86_64 的 InterruptDescriptorTable 结构提供了 load 函数用来实现这个需求。让我们来试一下:
// in src/interrupts.rs
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.load();
}
再次尝试编译,又出现了新的错误:
error: `idt` does not live long enough
--> src/interrupts/mod.rs:43:5
|
43 | idt.load();
| ^^^ does not live long enough
44 | }
| - borrowed value only lives until here
|
= note: borrowed value must be valid for the static lifetime...
原来 load 函数要求的生命周期为 &'static self ,也就是整个程序的生命周期,其原因就是CPU在接收到下一个IDT之前会一直使用这个描述符表。如果生命周期小于 'static ,很可能就会出现使用已释放对象的bug。
问题至此已经很清晰了,我们的 idt 是创建在栈上的,它的生命周期仅限于 init 函数执行期间,之后这部分栈内存就会被其他函数调用,CPU再来访问IDT的话,只会读取到一段随机数据。好在 InterruptDescriptorTable::load 被严格定义了函数生命周期限制,这样 Rust 编译器就可以在编译时就发现这些潜在问题。
要修复这些错误很简单,让 idt 具备 'static 类型的生命周期即可,我们可以使用 Box 在堆上申请一段内存,并转化为 'static 指针即可,但问题是我们正在写的东西是操作系统内核,(暂时)并没有堆这种东西。
作为替代,我们可以试着直接将IDT定义为 'static 变量:
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
然而这样就会引入一个新问题:静态变量是不可修改的,这样我们就无法在 init 函数中修改里面的数据了,所以需要把变量类型修改为 static mut:
static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
unsafe {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
}
这样就不会有编译错误了,但是这并不符合官方推荐的编码习惯,因为理论上说 static mut 类型的变量很容易形成数据竞争,所以需要用 unsafe 代码块 修饰调用语句。
🔗懒加载拯救世界
好在还有 lazy_static 宏可以用,区别于普通 static 变量在编译器求值,这个宏可以使代码块内的 static 变量在第一次取值时求值。所以,我们完全可以把初始化代码写在变量定义的代码块里,同时也不影响后续的取值。
在 创建VGA字符缓冲的单例 时我们已经引入了 lazy_static crate,所以我们可以直接使用 lazy_static! 来创建IDT:
// in src/interrupts.rs
use lazy_static::lazy_static;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt
};
}
pub fn init_idt() {
IDT.load();
}
现在碍眼的 unsafe 代码块成功被去掉了,尽管 lazy_static! 的内部依然使用了 unsafe 代码块,但是至少它已经抽象为了一个安全接口。
🔗跑起来
最后一步就是在 main.rs 里执行 init_idt 函数以在我们的内核里装载IDT,但不要直接调用,而应在 lib.rs 里封装一个 init 函数出来:
// in src/lib.rs
pub fn init() {
interrupts::init_idt();
}
这样我们就可以把所有初始化逻辑都集中在一个函数里,从而让 main.rs 、 lib.rs 以及单元测试中的 _start 共享初始化逻辑。
现在我们更新一下 main.rs 中的 _start 函数,调用 init 并手动触发一次 breakpoint exception:
// in src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init(); // new
// invoke a breakpoint exception
x86_64::instructions::interrupts::int3(); // new
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}
当我们在QEMU中运行之后(cargo run),效果是这样的:
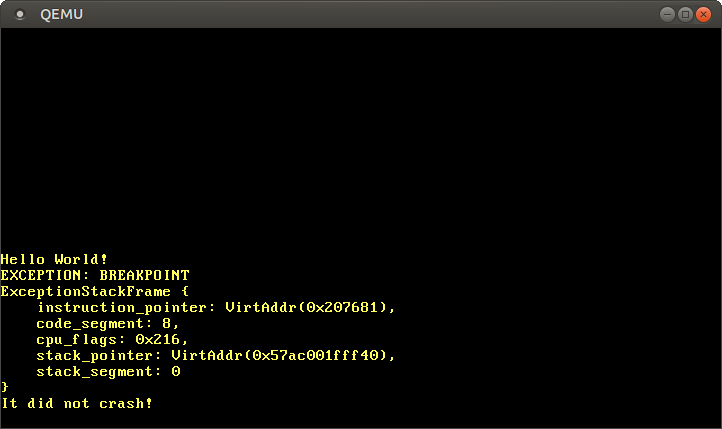
成功了!CPU成功调用了中断处理函数并打印出了信息,然后返回 _start 函数打印出了 It did not crash!。
我们可以看到,中断栈帧告诉了我们当错误发生时指令和栈指针的具体数值,这些信息在我们调试意外错误的时候非常有用。
🔗添加测试
那么让我们添加一个测试用例,用来确保以上工作成果可以顺利运行。首先需要在 _start 函数中调用 init:
// in src/lib.rs
/// Entry point for `cargo test`
#[cfg(test)]
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
init(); // new
test_main();
loop {}
}
注意,这里的 _start 会在 cargo test --lib 这条命令的上下文中运行,而 lib.rs 的执行环境完全独立于 main.rs,所以我们需要在运行测试之前调用 init 装载IDT。
那么我们接着创建一个测试用例 test_breakpoint_exception:
// in src/interrupts.rs
#[test_case]
fn test_breakpoint_exception() {
// invoke a breakpoint exception
x86_64::instructions::interrupts::int3();
}
该测试仅调用了 int3 函数以触发 breakpoint exception,通过查看这个函数是否能够继续运行下去,就可以确认我们对应的中断处理函数是否工作正常。
现在,你可以执行 cargo test 来运行所有测试,或者执行 cargo test --lib 来运行 lib.rs 及其子模块中包含的测试,最终输出如下:
blog_os::interrupts::test_breakpoint_exception... [ok]
🔗黑魔法有点多?
相对来说,x86-interrupt 调用约定和 InterruptDescriptorTable 类型让错误处理变得直截了当,如果这对你来说太过于神奇,进而想要了解错误处理中的所有隐秘细节,我们推荐读一下这些:“使用裸函数处理错误” 系列文章展示了如何在不使用 x86-interrupt 的前提下创建IDT。但是需要注意的是,这些文章都是在 x86-interrupt 调用约定和 x86_64 crate 出现之前的产物,这些东西属于博客的 第一版,不排除信息已经过期了的可能。
🔗接下来是?
我们已经成功捕获了第一个异常,并从异常中成功恢复,下一步就是试着捕获所有异常,如果有未捕获的异常就会触发致命的triple fault,那就只能重启整个系统了。下一篇文章会展开说我们如何通过正确捕捉double faults来避免这种情况。
评论
你有问题需要解决,想要分享反馈,或者讨论更多的想法吗?请随时在这里留下评论!请使用尽量使用英文并遵循 Rust 的 code of conduct. 这个讨论串将与 discussion on GitHub 直接连接,所以你也可以直接在那边发表评论
Instead of authenticating the giscus application, you can also comment directly on GitHub.
请尽可能使用英语评论。