Async/Await
Çevrilmiş İçerik: Bu, Async/Await adlı gönderinin topluluk tarafından yapılmış bir çevirisidir. Eksik, güncel olmayan veya hata içeriyor olabilir. Lütfen herhangi bir sorunu bildirin!
Translation by @rhotav.
Bu yazıda, işbirlikçi çoklu görevi (cooperative multitasking) ve Rust’ın async/await özelliğini inceliyoruz. Future trait’inin tasarımı, durum makinesi (state machine) dönüşümü ve pinning dahil olmak üzere, async/await’in Rust’ta nasıl çalıştığına ayrıntılı bir göz atıyoruz. Ardından, asenkron bir klavye görevi ve temel bir executor oluşturarak kernel’imize async/await için temel destek ekliyoruz.
Bu blog GitHub üzerinde açık biçimde geliştirilmektedir. Herhangi bir sorun veya sorunuz varsa lütfen orada bir issue açın. Ayrıca sayfanın en altına yorum bırakabilirsiniz. Bu yazının eksiksiz kaynak kodu post-12 dalında bulunabilir.
🔗Çoklu Görev (Multitasking)
Çoğu işletim sisteminin temel özelliklerinden biri, birden çok görevi eşzamanlı olarak yürütme yeteneği olan çoklu görevdir (multitasking). Örneğin, bu yazıya bakarken muhtemelen bir metin düzenleyici veya terminal penceresi gibi başka programlarınız da açık. Yalnızca tek bir tarayıcı pencereniz açık olsa bile, muhtemelen masaüstü pencerelerinizi yönetmek, güncellemeleri kontrol etmek veya dosyaları indekslemek için çeşitli arka plan görevleri vardır.
Tüm görevler paralel çalışıyormuş gibi görünse de, bir CPU çekirdeğinde bir seferde yalnızca tek bir görev yürütülebilir. Görevlerin paralel çalıştığı yanılsamasını oluşturmak için, işletim sistemi aktif görevler arasında hızla geçiş yapar; böylece her biri biraz ilerleme kaydedebilir. Bilgisayarlar hızlı olduğundan, çoğu zaman bu geçişleri fark etmeyiz.
Tek çekirdekli CPU’lar bir seferde yalnızca tek bir görev yürütebilirken, çok çekirdekli CPU’lar birden çok görevi gerçekten paralel bir şekilde çalıştırabilir. Örneğin, 8 çekirdekli bir CPU 8 görevi aynı anda çalıştırabilir. Çok çekirdekli CPU’ları nasıl kuracağımızı gelecekteki bir yazıda açıklayacağız. Bu yazı için, basitlik adına tek çekirdekli CPU’lara odaklanacağız. (Tüm çok çekirdekli CPU’ların yalnızca tek bir aktif çekirdekle başladığını belirtmekte fayda var, bu yüzden onları şimdilik tek çekirdekli CPU’lar olarak ele alabiliriz.)
İki tür çoklu görev vardır: İşbirlikçi çoklu görev, diğer görevlerin ilerleme kaydedebilmesi için görevlerin CPU kontrolünü düzenli olarak bırakmasını gerektirir. Kesintili (preemptive) çoklu görev, thread’leri keyfi zaman noktalarında zorla duraklatarak değiştirmek için işletim sistemi işlevselliğini kullanır. Aşağıda, çoklu görevin iki biçimini daha ayrıntılı inceleyecek ve ilgili avantaj ve dezavantajlarını tartışacağız.
🔗Kesintili (Preemptive) Çoklu Görev
Kesintili çoklu görevin arkasındaki fikir, görevlerin ne zaman değiştirileceğini işletim sisteminin kontrol etmesidir. Bunun için, her interrupt’ta CPU’nun kontrolünü yeniden ele geçirdiği gerçeğinden yararlanır. Bu, sisteme yeni girdi geldiğinde görevlerin değiştirilmesini mümkün kılar. Örneğin, fare hareket ettiğinde veya bir ağ paketi geldiğinde görevleri değiştirmek mümkün olurdu. İşletim sistemi ayrıca, bir donanım timer’ını o süreden sonra bir interrupt gönderecek şekilde yapılandırarak bir görevin çalışmasına izin verilen kesin süreyi de belirleyebilir.
Aşağıdaki grafik, bir donanım interrupt’ında görev değiştirme sürecini gösterir:

İlk satırda, CPU A programının A1 görevini yürütüyor. Diğer tüm görevler duraklatılmıştır. İkinci satırda, CPU’ya bir donanım interrupt’ı geliyor. Donanım Interrupt’ları yazısında açıklandığı gibi, CPU A1 görevinin yürütülmesini hemen durdurur ve interrupt descriptor table’da (IDT) tanımlanmış interrupt handler’a atlar. Bu interrupt handler aracılığıyla, işletim sistemi artık CPU’nun kontrolüne yeniden sahiptir; bu da A1 görevini sürdürmek yerine B1 görevine geçmesine olanak tanır.
🔗Durumu Kaydetmek
Görevler keyfi zaman noktalarında kesintiye uğradığından, bazı hesaplamaların ortasında olabilirler. Onları daha sonra sürdürebilmek için, işletim sistemi görevin çağrı stack’i ve tüm CPU register’larının değerleri dahil tüm durumunu yedeklemelidir. Bu sürece bağlam değiştirme (context switch) denir.
Çağrı stack’i çok büyük olabileceğinden, işletim sistemi her görev değişiminde çağrı stack’i içeriğini yedeklemek yerine, tipik olarak her görev için ayrı bir çağrı stack’i kurar. Kendi stack’ine sahip böyle bir göreve yürütme thread’i (thread of execution) ya da kısaca thread denir. Her görev için ayrı bir stack kullanarak, bir bağlam değiştirmede yalnızca register içeriklerinin kaydedilmesi gerekir (program sayacı ve stack pointer dahil). Bu yaklaşım, bir bağlam değiştirmenin performans yükünü en aza indirir; ki bu çok önemlidir, çünkü bağlam değiştirmeleri genellikle saniyede 100 kez meydana gelir.
🔗Tartışma
Kesintili çoklu görevin ana avantajı, işletim sisteminin bir görevin izin verilen yürütme süresini tam olarak kontrol edebilmesidir. Bu sayede, görevlerin işbirliği yapacağına güvenmeye gerek kalmadan, her görevin CPU süresinden adil bir pay almasını garanti edebilir. Bu, özellikle üçüncü taraf görevler çalıştırırken veya birden çok kullanıcı bir sistemi paylaştığında önemlidir.
Kesintinin dezavantajı, her görevin kendi stack’ine ihtiyaç duymasıdır. Paylaşılan bir stack’e kıyasla, bu görev başına daha yüksek bellek kullanımıyla sonuçlanır ve genellikle sistemdeki görev sayısını sınırlar. Bir başka dezavantaj da, işletim sisteminin her görev değişiminde, görev register’ların yalnızca küçük bir alt kümesini kullanmış olsa bile her zaman tam CPU register durumunu kaydetmek zorunda olmasıdır.
Kesintili çoklu görev ve thread’ler bir işletim sisteminin temel bileşenleridir, çünkü güvenilmeyen kullanıcı alanı programlarını çalıştırmayı mümkün kılarlar. Bu kavramları gelecekteki yazılarda tüm ayrıntılarıyla tartışacağız. Ancak bu yazı için, kernel’imiz için de yararlı yetenekler sağlayan işbirlikçi çoklu göreve odaklanacağız.
🔗İşbirlikçi (Cooperative) Çoklu Görev
İşbirlikçi çoklu görev, çalışan görevleri keyfi zaman noktalarında zorla duraklatmak yerine, her görevin CPU kontrolünü gönüllü olarak bırakana kadar çalışmasına izin verir. Bu, görevlerin kendilerini uygun zaman noktalarında, örneğin zaten bir G/Ç işlemini beklemeleri gerektiğinde, duraklatmasına olanak tanır.
İşbirlikçi çoklu görev, coroutine’ler veya async/await biçiminde olduğu gibi, sıklıkla dil seviyesinde kullanılır. Fikir, ya programcının ya da derleyicinin programa, CPU kontrolünü bırakan ve diğer görevlerin çalışmasına izin veren yield işlemleri eklemesidir. Örneğin, karmaşık bir döngünün her yinelemesinden sonra bir yield eklenebilir.
İşbirlikçi çoklu görevi asenkron işlemlerle birleştirmek yaygındır. Bir işlem bitene kadar beklemek ve bu süre boyunca diğer görevlerin çalışmasını önlemek yerine, asenkron işlemler henüz bitmediyse bir “hazır değil” durumu döndürür. Bu durumda, bekleyen görev diğer görevlerin çalışmasına izin vermek için bir yield işlemi yürütebilir.
🔗Durumu Kaydetmek
Görevler duraklama noktalarını kendileri tanımladığından, durumlarını kaydetmek için işletim sistemine ihtiyaç duymazlar. Bunun yerine, kendilerini duraklatmadan önce devam etmek için ihtiyaç duydukları durumu tam olarak kaydedebilirler; bu da çoğu zaman daha iyi performansla sonuçlanır. Örneğin, karmaşık bir hesaplamayı henüz bitirmiş bir görev, ara sonuçlara artık ihtiyaç duymadığı için yalnızca hesaplamanın nihai sonucunu yedeklemesi gerekebilir.
İşbirlikçi görevlerin dil destekli uygulamaları çoğu zaman, duraklamadan önce çağrı stack’inin gereken kısımlarını bile yedekleyebilir. Bir örnek olarak, Rust’ın async/await uygulaması, hâlâ gereken tüm yerel değişkenleri otomatik olarak üretilen bir struct’ta saklar (aşağıya bakın). Duraklamadan önce çağrı stack’inin ilgili kısımlarını yedekleyerek, tüm görevler tek bir çağrı stack’ini paylaşabilir; bu da görev başına çok daha düşük bellek tüketimiyle sonuçlanır. Bu, bellek tükenmeden neredeyse keyfi sayıda işbirlikçi görev oluşturmayı mümkün kılar.
🔗Tartışma
İşbirlikçi çoklu görevin dezavantajı, işbirliği yapmayan bir görevin potansiyel olarak sınırsız süre çalışabilmesidir. Böylece, kötü niyetli veya hatalı bir görev diğer görevlerin çalışmasını önleyebilir ve tüm sistemi yavaşlatabilir ve hatta bloklayabilir. Bu nedenle, işbirlikçi çoklu görev yalnızca tüm görevlerin işbirliği yapacağı bilindiğinde kullanılmalıdır. Karşı örnek olarak, işletim sistemini keyfi kullanıcı seviyesindeki programların işbirliğine bağımlı kılmak iyi bir fikir değildir.
Ancak, işbirlikçi çoklu görevin güçlü performans ve bellek avantajları, onu özellikle asenkron işlemlerle birlikte bir programın içinde kullanım için iyi bir yaklaşım kılar. Bir işletim sistemi kernel’i, asenkron donanımla etkileşen, performansa kritik bir program olduğundan, işbirlikçi çoklu görev eşzamanlılığı uygulamak için iyi bir yaklaşım gibi görünür.
🔗Rust’ta Async/Await
Rust dili, async/await biçiminde işbirlikçi çoklu görev için birinci sınıf destek sağlar. Async/await’in ne olduğunu ve nasıl çalıştığını inceleyebilmeden önce, future’ların ve asenkron programlamanın Rust’ta nasıl çalıştığını anlamamız gerekir.
🔗Future’lar
Bir future, henüz mevcut olmayabilecek bir değeri temsil eder. Bu, örneğin başka bir görev tarafından hesaplanan bir tamsayı veya ağdan indirilen bir dosya olabilir. Future’lar, değer mevcut olana kadar beklemek yerine, değere ihtiyaç duyulana kadar yürütmeye devam etmeyi mümkün kılar.
🔗Örnek
Future kavramı en iyi küçük bir örnekle açıklanır:

Bu sıra diyagramı, dosya sisteminden bir dosya okuyan ve ardından bir foo fonksiyonunu çağıran bir main fonksiyonunu gösterir. Bu süreç iki kez tekrarlanır: bir kez senkron bir read_file çağrısıyla ve bir kez asenkron bir async_read_file çağrısıyla.
Senkron çağrıyla, main fonksiyonunun dosya, dosya sisteminden yüklenene kadar beklemesi gerekir. Ancak o zaman, sonucu yeniden beklemesini gerektiren foo fonksiyonunu çağırabilir.
Asenkron async_read_file çağrısıyla, dosya sistemi doğrudan bir future döndürür ve dosyayı arka planda asenkron olarak yükler. Bu, main fonksiyonunun foo’yu çok daha erken çağırmasına olanak tanır; o da dosya yüklemesiyle paralel çalışır. Bu örnekte, dosya yüklemesi foo dönmeden önce bile biter, bu yüzden main, foo döndükten sonra daha fazla beklemeden doğrudan dosyayla çalışabilir.
🔗Rust’ta Future’lar
Rust’ta future’lar, şöyle görünen Future trait’i ile temsil edilir:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>;
}İlişkili tip (associated type) Output, asenkron değerin tipini belirtir. Örneğin, yukarıdaki diyagramdaki async_read_file fonksiyonu, Output’u File olarak ayarlanmış bir Future örneği döndürürdü.
poll metodu, değerin zaten mevcut olup olmadığını kontrol etmeye olanak tanır. Şöyle görünen bir Poll enum’ı döndürür:
pub enum Poll<T> {
Ready(T),
Pending,
}Değer zaten mevcut olduğunda (örneğin dosya diskten tamamen okunduğunda), Ready varyantında sarmalanmış olarak döndürülür. Aksi takdirde, çağırana değerin henüz mevcut olmadığını bildiren Pending varyantı döndürülür.
poll metodu iki argüman alır: self: Pin<&mut Self> ve cx: &mut Context. İlki, Self değerinin bellek konumuna pin’lenmiş (pinned) olması dışında normal bir &mut self referansına benzer şekilde davranır. Pin’i ve neden gerekli olduğunu anlamak, önce async/await’in nasıl çalıştığını anlamadan zordur. Bu yüzden onu bu yazının ilerleyen kısmında açıklayacağız.
cx: &mut Context parametresinin amacı, asenkron göreve, örneğin dosya sistemi yüklemesine, bir Waker örneği geçirmektir. Bu Waker, asenkron görevin (kendisinin veya bir kısmının) bittiğini, örneğin dosyanın diskten yüklendiğini bildirmesine olanak tanır. Ana görev, Future hazır olduğunda bilgilendirileceğini bildiğinden, poll’u tekrar tekrar çağırmasına gerek yoktur. Bu süreci bu yazının ilerleyen kısmında kendi waker tipimizi uyguladığımızda daha ayrıntılı açıklayacağız.
🔗Future’larla Çalışmak
Artık future’ların nasıl tanımlandığını biliyor ve poll metodunun arkasındaki temel fikri anlıyoruz. Ancak, future’larla nasıl etkili bir şekilde çalışacağımızı hâlâ bilmiyoruz. Sorun, future’ların henüz mevcut olmayabilecek asenkron görevlerin sonuçlarını temsil etmesidir. Ancak pratikte, çoğu zaman bu değerlere daha fazla hesaplama için doğrudan ihtiyaç duyarız. Yani soru şu: İhtiyaç duyduğumuzda bir future’ın değerini nasıl verimli bir şekilde alabiliriz?
🔗Future’ları Beklemek
Olası bir cevap, bir future hazır hale gelene kadar beklemektir. Bu, şuna benzer bir şey olabilir:
let future = async_read_file("foo.txt");
let file_content = loop {
match future.poll(…) {
Poll::Ready(value) => break value,
Poll::Pending => {}, // hiçbir şey yapma
}
}Burada poll’u bir döngüde tekrar tekrar çağırarak future’ı aktif olarak bekliyoruz. poll’a verilen argümanlar burada önemli değil, bu yüzden onları atladık. Bu çözüm işe yarasa da, çok verimsizdir; çünkü değer mevcut hale gelene kadar CPU’yu meşgul tutarız.
Daha verimli bir yaklaşım, future mevcut hale gelene kadar mevcut thread’i bloklamak olabilir. Bu, elbette, yalnızca thread’leriniz varsa mümkündür, bu yüzden bu çözüm kernel’imiz için, en azından şimdilik, çalışmaz. Bloklamanın desteklendiği sistemlerde bile, genellikle istenmez; çünkü asenkron bir görevi tekrar senkron bir göreve dönüştürür ve böylece paralel görevlerin potansiyel performans avantajlarını engeller.
🔗Future Kombinatörleri
Beklemeye bir alternatif, future kombinatörleri kullanmaktır. Future kombinatörleri, Iterator trait’inin metotlarına benzer şekilde, future’ları birbirine zincirlemeye ve birleştirmeye olanak tanıyan map gibi metotlardır. Future’ı beklemek yerine, bu kombinatörler kendileri bir future döndürür; o da poll’da eşleme (mapping) işlemini uygular.
Bir örnek olarak, bir Future<Output = String>’i bir Future<Output = usize>’e dönüştürmek için basit bir string_len kombinatörü şöyle görünebilir:
struct StringLen<F> {
inner_future: F,
}
impl<F> Future for StringLen<F> where F: Future<Output = String> {
type Output = usize;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
match self.inner_future.poll(cx) {
Poll::Ready(s) => Poll::Ready(s.len()),
Poll::Pending => Poll::Pending,
}
}
}
fn string_len(string: impl Future<Output = String>)
-> impl Future<Output = usize>
{
StringLen {
inner_future: string,
}
}
// Kullanım
fn file_len() -> impl Future<Output = usize> {
let file_content_future = async_read_file("foo.txt");
string_len(file_content_future)
}Bu kod, pinning’i ele almadığı için tam olarak çalışmaz, ancak bir örnek olarak yeterlidir. Temel fikir, string_len fonksiyonunun verilen bir Future örneğini, aynı zamanda Future’u uygulayan yeni bir StringLen struct’ına sarmalamasıdır. Sarmalanan future poll edildiğinde, iç future’ı poll eder. Değer henüz hazır değilse, sarmalanan future’dan da Poll::Pending döndürülür. Değer hazırsa, dize Poll::Ready varyantından çıkarılır ve uzunluğu hesaplanır. Sonrasında, yine Poll::Ready’de sarmalanır ve döndürülür.
Bu string_len fonksiyonuyla, bir asenkron dizenin uzunluğunu onu beklemeden hesaplayabiliriz. Fonksiyon yine bir Future döndürdüğünden, çağıran döndürülen değer üzerinde doğrudan çalışamaz, yine kombinatör fonksiyonları kullanması gerekir. Bu sayede, tüm çağrı grafiği asenkron hale gelir ve bir noktada, örneğin main fonksiyonunda, birden çok future’ı bir kerede verimli bir şekilde bekleyebiliriz.
Kombinatör fonksiyonlarını elle yazmak zor olduğundan, genellikle kütüphaneler tarafından sağlanırlar. Rust standart kütüphanesinin kendisi henüz kombinatör metotları sağlamasa da, yarı resmi (ve no_std uyumlu) futures crate’i sağlar. Onun FutureExt trait’i, sonucu keyfi closure’larla manipüle etmek için kullanılabilen map veya then gibi üst düzey kombinatör metotları sağlar.
🔗Avantajlar
Future kombinatörlerinin büyük avantajı, işlemleri asenkron tutmalarıdır. Asenkron G/Ç arayüzleriyle birlikte, bu yaklaşım çok yüksek performansa yol açabilir. Future kombinatörlerinin trait uygulamalı normal struct’lar olarak uygulanması, derleyicinin onları aşırı derecede optimize etmesine olanak tanır. Daha fazla ayrıntı için, future’ların Rust ekosistemine eklenmesini duyuran Zero-cost futures in Rust yazısına bakın.
🔗Dezavantajlar
Future kombinatörleri çok verimli kod yazmayı mümkün kılsa da, tip sistemi ve closure tabanlı arayüz nedeniyle bazı durumlarda kullanımları zor olabilir. Örneğin, şöyle bir kod düşünün:
fn example(min_len: usize) -> impl Future<Output = String> {
async_read_file("foo.txt").then(move |content| {
if content.len() < min_len {
Either::Left(async_read_file("bar.txt").map(|s| content + &s))
} else {
Either::Right(future::ready(content))
}
})
}Burada foo.txt dosyasını okuyor ve ardından dosya içeriğine dayalı ikinci bir future zincirlemek için then kombinatörünü kullanıyoruz. İçerik uzunluğu verilen min_len’den küçükse, farklı bir bar.txt dosyasını okuyor ve map kombinatörünü kullanarak onu content’e ekliyoruz. Aksi takdirde, yalnızca foo.txt’nin içeriğini döndürüyoruz.
then’e geçirilen closure için move anahtar kelimesini kullanmamız gerekir; çünkü aksi takdirde min_len için bir yaşam süresi hatası olurdu. Either sarmalayıcısının nedeni, if ve else bloklarının her zaman aynı tipte olması gerektiğidir. Bloklarda farklı future tipleri döndürdüğümüz için, onları tek bir tipte birleştirmek için sarmalayıcı tipi kullanmalıyız. ready fonksiyonu bir değeri, hemen hazır olan bir future’a sarmalar. Fonksiyon burada gereklidir, çünkü Either sarmalayıcısı sarmalanan değerin Future’u uygulamasını bekler.
Tahmin edebileceğiniz gibi, bu daha büyük projeler için hızla çok karmaşık koda yol açabilir. Ödünç almalar (borrowing) ve farklı yaşam süreleri söz konusu olduğunda özellikle karmaşık hale gelir. Bu nedenle, asenkron kodu yazmayı kökten daha basit hale getirme hedefiyle, Rust’a async/await desteği eklemek için çok emek harcandı.
🔗Async/Await Örüntüsü
Async/await’in arkasındaki fikir, programcının normal senkron kod gibi görünen, ancak derleyici tarafından asenkron koda dönüştürülen kod yazmasına izin vermektir. async ve await olmak üzere iki anahtar kelimeye dayanarak çalışır. async anahtar kelimesi, senkron bir fonksiyonu bir future döndüren asenkron bir fonksiyona dönüştürmek için bir fonksiyon imzasında kullanılabilir:
async fn foo() -> u32 {
0
}
// yukarıdaki, derleyici tarafından kabaca şuna çevrilir:
fn foo() -> impl Future<Output = u32> {
future::ready(0)
}Bu anahtar kelime tek başına o kadar yararlı olmazdı. Ancak, async fonksiyonların içinde, bir future’ın asenkron değerini almak için await anahtar kelimesi kullanılabilir:
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}Bu fonksiyon, kombinatör fonksiyonları kullanan yukarıdaki example fonksiyonunun doğrudan bir çevirisidir. .await operatörünü kullanarak, herhangi bir closure veya Either tipine ihtiyaç duymadan bir future’ın değerini alabiliriz. Sonuç olarak, kodumuzu tıpkı normal senkron kod yazar gibi yazabiliriz; tek farkla ki bu hâlâ asenkron koddur.
🔗Durum Makinesi Dönüşümü
Perde arkasında, derleyici async fonksiyonunun gövdesini, her .await çağrısının farklı bir durumu temsil ettiği bir durum makinesine (state machine) dönüştürür. Yukarıdaki example fonksiyonu için, derleyici aşağıdaki dört duruma sahip bir durum makinesi oluşturur:

Her durum, fonksiyondaki farklı bir duraklama noktasını temsil eder. “Başlangıç” ve “Son” durumları, fonksiyonu yürütülmesinin başında ve sonunda temsil eder. “foo.txt’yi bekliyor” durumu, fonksiyonun şu anda ilk async_read_file sonucunu beklediğini temsil eder. Benzer şekilde, “bar.txt’yi bekliyor” durumu, fonksiyonun ikinci async_read_file sonucunu beklediği duraklama noktasını temsil eder.
Durum makinesi, her poll çağrısını olası bir durum geçişi yaparak Future trait’ini uygular:

Diyagram, durum geçişlerini temsil etmek için oklar ve alternatif yolları temsil etmek için baklava şekilleri kullanır. Örneğin, foo.txt dosyası hazır değilse, “hayır” ile işaretli yol izlenir ve “foo.txt’yi bekliyor” durumuna ulaşılır. Aksi takdirde, “evet” yolu izlenir. Açıklamasız küçük kırmızı baklava, example fonksiyonunun if content.len() < 100 dalını temsil eder.
İlk poll çağrısının fonksiyonu başlattığını ve henüz hazır olmayan bir future’a ulaşana kadar çalışmasına izin verdiğini görüyoruz. Yoldaki tüm future’lar hazırsa, fonksiyon, sonucunu Poll::Ready’de sarmalanmış olarak döndürdüğü “Son” durumuna kadar çalışabilir. Aksi takdirde, durum makinesi bir bekleme durumuna girer ve Poll::Pending döndürür. Bir sonraki poll çağrısında, durum makinesi ardından son bekleme durumundan başlar ve son işlemi yeniden dener.
🔗Durumu Kaydetmek
Son bekleme durumundan devam edebilmek için, durum makinesinin mevcut durumu dahili olarak takip etmesi gerekir. Buna ek olarak, bir sonraki poll çağrısında yürütmeye devam etmek için ihtiyaç duyduğu tüm değişkenleri kaydetmesi gerekir. İşte derleyicinin gerçekten parladığı yer burası: Hangi değişkenlerin ne zaman kullanıldığını bildiğinden, tam olarak ihtiyaç duyulan değişkenlere sahip struct’ları otomatik olarak üretebilir.
Bir örnek olarak, derleyici yukarıdaki example fonksiyonu için aşağıdaki gibi struct’lar üretir:
// Yukarı kaydırmak zorunda kalmamanız için `example` fonksiyonu yeniden
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
// Derleyici tarafından üretilen durum struct'ları:
struct StartState {
min_len: usize,
}
struct WaitingOnFooTxtState {
min_len: usize,
foo_txt_future: impl Future<Output = String>,
}
struct WaitingOnBarTxtState {
content: String,
bar_txt_future: impl Future<Output = String>,
}
struct EndState {}“Başlangıç” ve “foo.txt’yi bekliyor” durumlarında, content.len() ile sonraki karşılaştırma için min_len parametresinin saklanması gerekir. “foo.txt’yi bekliyor” durumu buna ek olarak, async_read_file çağrısının döndürdüğü future’ı temsil eden bir foo_txt_future saklar. Durum makinesi devam ettiğinde bu future’ın tekrar poll edilmesi gerekir, bu yüzden kaydedilmesi gerekir.
“bar.txt’yi bekliyor” durumu, bar.txt hazır olduğunda sonraki dize birleştirmesi için content değişkenini içerir. Ayrıca, bar.txt’nin devam eden yüklemesini temsil eden bir bar_txt_future saklar. content.len() karşılaştırmasından sonra artık ihtiyaç duyulmadığı için, struct min_len değişkenini içermez. “son” durumunda, fonksiyon zaten tamamlanana kadar çalıştığı için hiçbir değişken saklanmaz.
Bunun yalnızca derleyicinin üretebileceği kodun bir örneği olduğunu unutmayın. Struct adları ve alan düzeni uygulama detaylarıdır ve farklı olabilir.
🔗Tam Durum Makinesi Tipi
Derleyici tarafından üretilen kesin kod bir uygulama detayı olsa da, üretilen durum makinesinin example fonksiyonu için nasıl görünebileceğini hayal etmek anlamaya yardımcı olur. Farklı durumları temsil eden ve gereken değişkenleri içeren struct’ları zaten tanımladık. Onların üzerine bir durum makinesi oluşturmak için, onları bir enum’da birleştirebiliriz:
enum ExampleStateMachine {
Start(StartState),
WaitingOnFooTxt(WaitingOnFooTxtState),
WaitingOnBarTxt(WaitingOnBarTxtState),
End(EndState),
}Her durum için ayrı bir enum varyantı tanımlıyor ve karşılık gelen durum struct’ını her varyanta bir alan olarak ekliyoruz. Durum geçişlerini uygulamak için, derleyici example fonksiyonuna dayalı bir Future trait uygulaması üretir:
impl Future for ExampleStateMachine {
type Output = String; // `example`'ın dönüş tipi
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output> {
loop {
match self { // TODO: pinning'i ele al
ExampleStateMachine::Start(state) => {…}
ExampleStateMachine::WaitingOnFooTxt(state) => {…}
ExampleStateMachine::WaitingOnBarTxt(state) => {…}
ExampleStateMachine::End(state) => {…}
}
}
}
}Future’ın Output tipi String’tir, çünkü example fonksiyonunun dönüş tipidir. poll fonksiyonunu uygulamak için, bir loop içinde mevcut durum üzerinde bir match ifadesi kullanıyoruz. Fikir, mümkün olduğu sürece bir sonraki duruma geçmek ve devam edemediğimizde açık bir return Poll::Pending kullanmaktır.
Basitlik için, yalnızca sadeleştirilmiş kod gösteriyor ve pinning, sahiplik, yaşam süreleri vb. konularını ele almıyoruz. Bu yüzden bu ve aşağıdaki kod sözde kod (pseudo-code) olarak ele alınmalı ve doğrudan kullanılmamalıdır. Tabii ki, gerçek derleyici tarafından üretilen kod, muhtemelen farklı bir şekilde de olsa, her şeyi doğru ele alır.
Kod alıntılarını küçük tutmak için, her match kolunun kodunu ayrı ayrı sunuyoruz. Start durumuyla başlayalım:
ExampleStateMachine::Start(state) => {
// `example`'ın gövdesinden
let foo_txt_future = async_read_file("foo.txt");
// `.await` işlemi
let state = WaitingOnFooTxtState {
min_len: state.min_len,
foo_txt_future,
};
*self = ExampleStateMachine::WaitingOnFooTxt(state);
}Durum makinesi, tam olarak fonksiyonun başındayken Start durumundadır. Bu durumda, example fonksiyonunun gövdesindeki tüm kodu ilk .await’e kadar yürütürüz. .await işlemini ele almak için, self durum makinesinin durumunu, WaitingOnFooTxtState struct’ının yapımını da içeren WaitingOnFooTxt’ye değiştiririz.
match self {…} ifadesi bir döngüde yürütüldüğünden, yürütme sonra WaitingOnFooTxt koluna atlar:
ExampleStateMachine::WaitingOnFooTxt(state) => {
match state.foo_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(content) => {
// `example`'ın gövdesinden
if content.len() < state.min_len {
let bar_txt_future = async_read_file("bar.txt");
// `.await` işlemi
let state = WaitingOnBarTxtState {
content,
bar_txt_future,
};
*self = ExampleStateMachine::WaitingOnBarTxt(state);
} else {
*self = ExampleStateMachine::End(EndState);
return Poll::Ready(content);
}
}
}
}Bu match kolunda, önce foo_txt_future’ın poll fonksiyonunu çağırıyoruz. Hazır değilse, döngüden çıkıyor ve Poll::Pending döndürüyoruz. Bu durumda self, WaitingOnFooTxt durumunda kaldığından, durum makinesindeki bir sonraki poll çağrısı aynı match koluna girecek ve foo_txt_future’ı poll etmeyi yeniden deneyecek.
foo_txt_future hazır olduğunda, sonucu content değişkenine atıyoruz ve example fonksiyonunun kodunu yürütmeye devam ediyoruz: content.len(), durum struct’ında kaydedilen min_len’den küçükse, bar.txt dosyası asenkron olarak okunur. .await işlemini yine bir durum değişikliğine, bu kez WaitingOnBarTxt durumuna çeviriyoruz. match’i bir döngü içinde yürüttüğümüz için, yürütme sonrasında doğrudan yeni durumun match koluna atlar; orada bar_txt_future poll edilir.
else dalına girersek, başka bir .await işlemi gerçekleşmez. Fonksiyonun sonuna ulaşır ve content’i Poll::Ready’de sarmalanmış olarak döndürürüz. Ayrıca mevcut durumu End durumuna değiştiririz.
WaitingOnBarTxt durumunun kodu şöyle görünür:
ExampleStateMachine::WaitingOnBarTxt(state) => {
match state.bar_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(bar_txt) => {
*self = ExampleStateMachine::End(EndState);
// `example`'ın gövdesinden
return Poll::Ready(state.content + &bar_txt);
}
}
}WaitingOnFooTxt durumuna benzer şekilde, bar_txt_future’ı poll ederek başlıyoruz. Hâlâ beklemedeyse, döngüden çıkıyor ve Poll::Pending döndürüyoruz. Aksi takdirde, example fonksiyonunun son işlemini gerçekleştirebiliriz: content değişkenini future’dan gelen sonuçla birleştirmek. Durum makinesini End durumuna güncelliyor ve ardından sonucu Poll::Ready’de sarmalanmış olarak döndürüyoruz.
Son olarak, End durumunun kodu şöyle görünür:
ExampleStateMachine::End(_) => {
panic!("poll called after Poll::Ready was returned");
}Future’lar Poll::Ready döndürdükten sonra tekrar poll edilmemelidir, bu yüzden zaten End durumundayken poll çağrılırsa panic yapıyoruz.
Artık derleyici tarafından üretilen durum makinesinin ve Future trait uygulamasının nasıl görünebileceğini biliyoruz. Pratikte, derleyici kodu farklı bir şekilde üretir. (İlgileniyorsanız, uygulama şu anda coroutine’lere dayanır, ancak bu yalnızca bir uygulama detayıdır.)
Bulmacanın son parçası, example fonksiyonunun kendisi için üretilen koddur. Hatırlayın, fonksiyon başlığı şöyle tanımlanmıştı:
async fn example(min_len: usize) -> StringTüm fonksiyon gövdesi artık durum makinesi tarafından uygulandığından, fonksiyonun yapması gereken tek şey durum makinesini başlatmak ve onu döndürmektir. Bunun için üretilen kod şöyle görünebilir:
fn example(min_len: usize) -> ExampleStateMachine {
ExampleStateMachine::Start(StartState {
min_len,
})
}Fonksiyon artık bir async değiştiricisine sahip değil, çünkü artık Future trait’ini uygulayan bir ExampleStateMachine tipini açıkça döndürüyor. Beklendiği gibi, durum makinesi Start durumunda yapılandırılır ve karşılık gelen durum struct’ı min_len parametresiyle başlatılır.
Bu fonksiyonun durum makinesinin yürütülmesini başlatmadığına dikkat edin. Bu, Rust’taki future’ların temel bir tasarım kararıdır: ilk kez poll edilene kadar hiçbir şey yapmazlar.
🔗Pinning
Bu yazıda pinning’e birçok kez rastladık. Şimdi nihayet pinning’in ne olduğunu ve neden gerekli olduğunu inceleme zamanı.
🔗Kendine Referans Veren Struct’lar
Yukarıda açıklandığı gibi, durum makinesi dönüşümü her duraklama noktasının yerel değişkenlerini bir struct’ta saklar. example fonksiyonumuz gibi küçük örnekler için bu basitti ve herhangi bir soruna yol açmadı. Ancak değişkenler birbirine referans verdiğinde işler zorlaşır. Örneğin, şu fonksiyonu düşünün:
async fn pin_example() -> i32 {
let array = [1, 2, 3];
let element = &array[2];
async_write_file("foo.txt", element.to_string()).await;
*element
}Bu fonksiyon, 1, 2 ve 3 içerikleriyle küçük bir array oluşturur. Ardından son dizi elemanına bir referans oluşturur ve onu bir element değişkeninde saklar. Sonra, dizeye dönüştürülmüş sayıyı asenkron olarak bir foo.txt dosyasına yazar. Son olarak, element tarafından referans verilen sayıyı döndürür.
Fonksiyon tek bir await işlemi kullandığından, elde edilen durum makinesinin üç durumu vardır: başlangıç, son ve “yazmayı bekliyor”. Fonksiyon argüman almaz, bu yüzden başlangıç durumu için struct boştur. Önceki gibi, son durum için struct da boştur, çünkü bu noktada fonksiyon bitmiştir. “yazmayı bekliyor” durumu için struct daha ilginçtir:
struct WaitingOnWriteState {
array: [1, 2, 3],
element: 0x1001c, // son dizi elemanının adresi
}Hem array hem de element değişkenlerini saklamamız gerekir, çünkü element dönüş değeri için gereklidir ve array, element tarafından referans verilir. element bir referans olduğundan, referans verilen elemana bir işaretçi (yani bir bellek adresi) saklar. Burada örnek bir bellek adresi olarak 0x1001c kullandık. Gerçekte, array alanının son elemanının adresi olması gerekir, bu yüzden struct’ın bellekte nerede yaşadığına bağlıdır. Böyle iç işaretçilere sahip struct’lara, kendilerini alanlarından birinden referans verdikleri için kendine referans veren (self-referential) struct’lar denir.
🔗Kendine Referans Veren Struct’ların Sorunu
Kendine referans veren struct’ımızın iç işaretçisi, bellek düzenine baktığımızda belirgin hale gelen temel bir soruna yol açar:

array alanı 0x10014 adresinde ve element alanı 0x10020 adresinde başlar. 0x1001c adresine işaret eder, çünkü son dizi elemanı bu adreste yaşar. Bu noktada her şey hâlâ yolunda. Ancak, bu struct’ı farklı bir bellek adresine taşıdığımızda bir sorun ortaya çıkar:

Struct’ı biraz taşıdık, böylece artık 0x10024 adresinde başlıyor. Bu, örneğin struct’ı bir fonksiyon argümanı olarak geçirdiğimizde veya farklı bir stack değişkenine atadığımızda olabilir. Sorun, son array elemanı artık 0x1002c adresinde yaşamasına rağmen element alanının hâlâ 0x1001c adresine işaret etmesidir. Böylece işaretçi sarkar (dangling) ve bir sonraki poll çağrısında tanımsız davranışın meydana gelmesiyle sonuçlanır.
🔗Olası Çözümler
Sarkan işaretçi sorununu çözmenin üç temel yaklaşımı vardır:
-
Taşımada işaretçiyi güncelle: Fikir, struct bellekte her taşındığında iç işaretçiyi güncellemektir; böylece taşımadan sonra hâlâ geçerli olur. Ne yazık ki, bu yaklaşım Rust’a, potansiyel olarak büyük performans kayıplarıyla sonuçlanacak kapsamlı değişiklikler gerektirirdi. Bunun nedeni, bir tür runtime’ın tüm struct alanlarının tipini takip etmesi ve her taşıma işleminde bir işaretçi güncellemesinin gerekli olup olmadığını kontrol etmesi gerekecek olmasıdır.
-
Kendine referans yerine bir ofset sakla: İşaretçileri güncelleme gereksiniminden kaçınmak için, derleyici kendine referansları bunun yerine struct’ın başlangıcından ofsetler olarak saklamayı deneyebilirdi. Örneğin, yukarıdaki
WaitingOnWriteStatestruct’ınınelementalanı, 8 değerine sahip birelement_offsetalanı biçiminde saklanabilirdi; çünkü referansın işaret ettiği dizi elemanı struct’ın başlangıcından 8 bayt sonra başlar. Struct taşındığında ofset aynı kaldığından, hiçbir alan güncellemesi gerekmez.Bu yaklaşımın sorunu, derleyicinin tüm kendine referansları tespit etmesini gerektirmesidir. Bu, bir referansın değeri kullanıcı girdisine bağlı olabileceği için derleme zamanında mümkün değildir, bu yüzden referansları analiz etmek ve durum struct’larını doğru oluşturmak için yine bir runtime sistemine ihtiyaç duyardık. Bu yalnızca runtime maliyetleriyle sonuçlanmakla kalmaz, aynı zamanda belirli derleyici optimizasyonlarını da önler; böylece yine büyük performans kayıplarına neden olur.
-
Struct’ı taşımayı yasakla: Yukarıda gördüğümüz gibi, sarkan işaretçi yalnızca struct’ı bellekte taşıdığımızda meydana gelir. Kendine referans veren struct’larda taşıma işlemlerini tamamen yasaklayarak, sorundan da kaçınılabilir. Bu yaklaşımın büyük avantajı, ek runtime maliyetleri olmadan tip sistemi seviyesinde uygulanabilmesidir. Dezavantajı, olası kendine referans veren struct’larda taşıma işlemleriyle baş etme yükünü programcıya yüklemesidir.
Rust, abstraksiyonların ek runtime maliyetleri getirmemesi gerektiği anlamına gelen sıfır maliyetli soyutlamalar (zero cost abstractions) ilkesi nedeniyle üçüncü çözümü seçti. pinning API’si bu amaçla RFC 2349’da önerildi. Aşağıda, bu API’ye kısa bir genel bakış sunacak ve async/await ve future’larla nasıl çalıştığını açıklayacağız.
🔗Heap Değerleri
İlk gözlem, heap’te ayrılmış değerlerin çoğu zaman zaten sabit bir bellek adresine sahip olmasıdır. allocate çağrısı kullanılarak oluşturulur ve ardından Box<T> gibi bir işaretçi tipi tarafından referans verilirler. İşaretçi tipini taşımak mümkünken, işaretçinin işaret ettiği heap değeri, tekrar bir deallocate çağrısıyla serbest bırakılana kadar aynı bellek adresinde kalır.
Heap ayırma kullanarak, kendine referans veren bir struct oluşturmaya çalışabiliriz:
fn main() {
let mut heap_value = Box::new(SelfReferential {
self_ptr: 0 as *const _,
});
let ptr = &*heap_value as *const SelfReferential;
heap_value.self_ptr = ptr;
println!("heap value at: {:p}", heap_value);
println!("internal reference: {:p}", heap_value.self_ptr);
}
struct SelfReferential {
self_ptr: *const Self,
}Tek bir işaretçi alanı içeren SelfReferential adında basit bir struct oluşturuyoruz. Önce, bu struct’ı null bir işaretçiyle başlatıyoruz ve ardından Box::new kullanarak onu heap’te ayırıyoruz. Sonra, heap’te ayrılmış struct’ın bellek adresini belirliyoruz ve onu bir ptr değişkeninde saklıyoruz. Son olarak, ptr değişkenini self_ptr alanına atayarak struct’ı kendine referans veren hale getiriyoruz.
Bu kodu playground’da çalıştırdığımızda, heap değerinin adresi ile iç işaretçisinin eşit olduğunu görüyoruz; bu da self_ptr alanının geçerli bir kendine referans olduğu anlamına gelir. heap_value değişkeni yalnızca bir işaretçi olduğundan, onu taşımak (örneğin bir fonksiyona geçirerek) struct’ın kendisinin adresini değiştirmez, bu yüzden işaretçi taşınsa bile self_ptr geçerli kalır.
Ancak, bu örneği bozmanın hâlâ bir yolu var: Bir Box<T>’nin dışına taşıyabilir veya içeriğini değiştirebiliriz:
let stack_value = mem::replace(&mut *heap_value, SelfReferential {
self_ptr: 0 as *const _,
});
println!("value at: {:p}", &stack_value);
println!("internal reference: {:p}", stack_value.self_ptr);Burada, heap’te ayrılmış değeri yeni bir struct örneğiyle değiştirmek için mem::replace fonksiyonunu kullanıyoruz. Bu, orijinal heap_value’yu stack’e taşımamıza olanak tanır; struct’ın self_ptr alanı ise artık hâlâ eski heap adresine işaret eden sarkan bir işaretçidir. Örneği playground’da çalıştırmayı denediğinizde, yazdırılan “value at:” ve “internal reference:” satırlarının gerçekten farklı işaretçiler gösterdiğini görürsünüz. Yani bir değeri heap’te ayırmak, kendine referansları güvenli kılmak için yeterli değildir.
Yukarıdaki bozulmaya izin veren temel sorun, Box<T>’nin heap’te ayrılmış değere bir &mut T referansı almamıza izin vermesidir. Bu &mut referansı, heap’te ayrılmış değeri geçersiz kılmak için mem::replace veya mem::swap gibi metotları kullanmayı mümkün kılar. Bu sorunu çözmek için, kendine referans veren struct’lara &mut referansların oluşturulmasını önlemeliyiz.
🔗Pin<Box<T>> ve Unpin
Pinning API’si, &mut T sorununa Pin sarmalayıcı tipi ve Unpin işaretçi (marker) trait’i biçiminde bir çözüm sağlar. Bu tiplerin arkasındaki fikir, Pin’in sarmalanan değere &mut referanslar almak için kullanılabilecek tüm metotlarını (örneğin get_mut veya deref_mut) Unpin trait’ine bağlamaktır. Unpin trait’i bir otomatik trait (auto trait)’tir; açıkça vazgeçenler hariç tüm tipler için otomatik olarak uygulanır. Kendine referans veren struct’ları Unpin’den vazgeçirerek, onlar için bir Pin<Box<T>> tipinden bir &mut T almanın (güvenli) bir yolu olmaz. Sonuç olarak, iç kendine referanslarının geçerli kalacağı garanti edilir.
Bir örnek olarak, yukarıdaki SelfReferential tipini Unpin’den vazgeçecek şekilde güncelleyelim:
use core::marker::PhantomPinned;
struct SelfReferential {
self_ptr: *const Self,
_pin: PhantomPinned,
}PhantomPinned tipinde ikinci bir _pin alanı ekleyerek vazgeçiyoruz. Bu tip, tek amacı Unpin trait’ini uygula_ma_mak olan sıfır boyutlu bir işaretçi tipidir. Otomatik trait’lerin çalışma şekli nedeniyle, Unpin olmayan tek bir alan, tüm struct’ı Unpin’den vazgeçirmeye yeter.
İkinci adım, örnekteki Box<SelfReferential> tipini bir Pin<Box<SelfReferential>> tipine değiştirmektir. Bunu yapmanın en kolay yolu, heap’te ayrılmış değeri oluşturmak için Box::new yerine Box::pin fonksiyonunu kullanmaktır:
let mut heap_value = Box::pin(SelfReferential {
self_ptr: 0 as *const _,
_pin: PhantomPinned,
});Box::new’i Box::pin’e değiştirmeye ek olarak, struct başlatıcısına yeni _pin alanını da eklememiz gerekir. PhantomPinned sıfır boyutlu bir tip olduğundan, onu başlatmak için yalnızca tip adına ihtiyacımız var.
Düzenlenmiş örneğimizi şimdi çalıştırmayı denediğimizde, artık çalışmadığını görüyoruz:
error[E0594]: cannot assign to data in dereference of `Pin<Box<SelfReferential>>`
--> src/main.rs:10:5
|
10 | heap_value.self_ptr = ptr;
| ^^^^^^^^^^^^^^^^^^^^^^^^^ cannot assign
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
error[E0596]: cannot borrow data in dereference of `Pin<Box<SelfReferential>>` as mutable
--> src/main.rs:16:36
|
16 | let stack_value = mem::replace(&mut *heap_value, SelfReferential {
| ^^^^^^^^^^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`Her iki hata da, Pin<Box<SelfReferential>> tipinin artık DerefMut trait’ini uygulamaması nedeniyle oluşur. Bu tam olarak istediğimiz şeydir, çünkü DerefMut trait’i, önlemek istediğimiz bir &mut referansı döndürürdü. Bu yalnızca hem Unpin’den vazgeçtiğimiz hem de Box::new’i Box::pin’e değiştirdiğimiz için olur.
Şimdi sorun, derleyicinin yalnızca 16. satırda tipi taşımayı önlemekle kalmayıp, 10. satırda self_ptr alanını başlatmayı da yasaklamasıdır. Bu, derleyicinin &mut referansların geçerli ve geçersiz kullanımları arasında ayrım yapamaması nedeniyle olur. Başlatmayı tekrar çalışır hale getirmek için, unsafe get_unchecked_mut metodunu kullanmamız gerekir:
// güvenli, çünkü bir alanı değiştirmek tüm struct'ı taşımaz
unsafe {
let mut_ref = Pin::as_mut(&mut heap_value);
Pin::get_unchecked_mut(mut_ref).self_ptr = ptr;
}get_unchecked_mut fonksiyonu, bir Pin<Box<T>> yerine bir Pin<&mut T> üzerinde çalışır, bu yüzden değeri dönüştürmek için Pin::as_mut kullanmalıyız. Sonra, get_unchecked_mut tarafından döndürülen &mut referansını kullanarak self_ptr alanını ayarlayabiliriz.
Artık kalan tek hata, mem::replace’teki istenen hatadır. Hatırlayın, bu işlem heap’te ayrılmış değeri stack’e taşımayı dener; bu da self_ptr alanında saklanan kendine referansı bozardı. Unpin’den vazgeçerek ve Pin<Box<T>> kullanarak, bu işlemi derleme zamanında önleyebilir ve böylece kendine referans veren struct’larla güvenli bir şekilde çalışabiliriz. Gördüğümüz gibi, derleyici kendine referans oluşturmanın güvenli olduğunu (henüz) kanıtlayamıyor, bu yüzden bir unsafe blok kullanmamız ve doğruluğu kendimiz doğrulamamız gerekir.
🔗Stack Pinning ve Pin<&mut T>
Önceki bölümde, heap’te ayrılmış, kendine referans veren bir değeri güvenli bir şekilde oluşturmak için Pin<Box<T>>’yi nasıl kullanacağımızı öğrendik. Bu yaklaşım iyi çalışsa ve (unsafe yapım dışında) nispeten güvenli olsa da, gereken heap ayırma bir performans maliyetiyle gelir. Rust mümkün olduğunca sıfır maliyetli soyutlamalar sağlamaya çalıştığından, pinning API’si stack’te ayrılmış değerlere işaret eden Pin<&mut T> örnekleri oluşturmaya da olanak tanır.
Sarmalanan değerin sahipliğine sahip olan Pin<Box<T>> örneklerinin aksine, Pin<&mut T> örnekleri sarmalanan değeri yalnızca geçici olarak ödünç alır. Bu, programcının ek garantileri kendisinin sağlamasını gerektirdiği için işleri daha karmaşık hale getirir. En önemlisi, bir Pin<&mut T>, referans verilen T’nin tüm yaşam süresi boyunca pin’lenmiş kalmalıdır; ki bu, stack tabanlı değişkenler için doğrulanması zor olabilir. Buna yardımcı olmak için, pin-utils gibi crate’ler vardır, ancak gerçekten ne yaptığınızı bilmiyorsanız stack’e pin’lemeyi yine de tavsiye etmem.
Daha fazla okuma için, pin modülünün ve Pin::new_unchecked metodunun belgelerine göz atın.
🔗Pinning ve Future’lar
Bu yazıda zaten gördüğümüz gibi, Future::poll metodu pinning’i bir Pin<&mut Self> parametresi biçiminde kullanır:
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>Bu metodun normal &mut self yerine self: Pin<&mut Self> almasının nedeni, async/await’ten oluşturulan future örneklerinin, yukarıda gördüğümüz gibi, çoğu zaman kendine referans vermesidir. Self’i Pin’e sararak ve derleyicinin async/await’ten üretilen kendine referans veren future’lar için Unpin’den vazgeçmesine izin vererek, future’ların poll çağrıları arasında bellekte taşınmayacağı garanti edilir. Bu, tüm iç referansların hâlâ geçerli olmasını sağlar.
İlk poll çağrısından önce future’ları taşımanın sorun olmadığını belirtmekte fayda var. Bu, future’ların tembel olması ve ilk kez poll edilene kadar hiçbir şey yapmaması gerçeğinin bir sonucudur. Üretilen durum makinelerinin start durumu bu yüzden yalnızca fonksiyon argümanlarını içerir, hiçbir iç referans içermez. poll’u çağırmak için, çağıranın önce future’ı Pin’e sarması gerekir; bu da future’ın artık bellekte taşınamayacağını sağlar. Stack pinning’i doğru yapmak daha zor olduğundan, bunun için her zaman Box::pin’i Pin::as_mut ile birlikte kullanmanızı tavsiye ederim.
Stack pinning kullanarak bir future kombinatör fonksiyonunu kendiniz güvenli bir şekilde nasıl uygulayacağınızı anlamak istiyorsanız, futures crate’inin map kombinatör metodunun nispeten kısa kaynağına ve pin belgelerinin projeksiyonlar ve yapısal pinning bölümüne bir göz atın.
🔗Executor’lar ve Waker’lar
Async/await kullanarak, future’larla tamamen asenkron bir şekilde ergonomik olarak çalışmak mümkündür. Ancak, yukarıda öğrendiğimiz gibi, future’lar poll edilene kadar hiçbir şey yapmaz. Bu, bir noktada onlar üzerinde poll çağırmamız gerektiği anlamına gelir; aksi takdirde asenkron kod asla yürütülmez.
Tek bir future ile, her future’ı bir döngü kullanarak yukarıda açıklandığı gibi her zaman elle bekleyebiliriz. Ancak, bu yaklaşım çok verimsizdir ve çok sayıda future oluşturan programlar için pratik değildir. Bu soruna en yaygın çözüm, sistemdeki tüm future’ları bitene kadar poll etmekten sorumlu global bir executor tanımlamaktır.
🔗Executor’lar
Bir executor’ın amacı, future’ları bağımsız görevler olarak, tipik olarak bir tür spawn metodu aracılığıyla başlatmaya (spawn) olanak tanımaktır. Executor daha sonra tüm future’ları tamamlanana kadar poll etmekten sorumludur. Tüm future’ları merkezi bir yerde yönetmenin büyük avantajı, executor’ın bir future Poll::Pending döndürdüğünde farklı bir future’a geçebilmesidir. Böylece, asenkron işlemler paralel olarak çalıştırılır ve CPU meşgul tutulur.
Birçok executor uygulaması, birden çok CPU çekirdeğine sahip sistemlerden de yararlanabilir. Yeterli iş mevcutsa tüm çekirdekleri kullanabilen bir thread havuzu (thread pool) oluşturur ve çekirdekler arasında yükü dengelemek için iş çalma (work stealing) gibi teknikler kullanırlar. Düşük gecikme ve bellek yükü için optimize eden, gömülü sistemler için özel executor uygulamaları da vardır.
Future’ları tekrar tekrar poll etmenin yükünden kaçınmak için, executor’lar tipik olarak Rust’ın future’ları tarafından desteklenen waker API’sinden yararlanır.
🔗Waker’lar
Waker API’sinin arkasındaki fikir, her poll çağrısına, Context tipine sarmalanmış özel bir Waker tipinin geçirilmesidir. Bu Waker tipi executor tarafından oluşturulur ve asenkron görev tarafından (kısmi) tamamlanmasını bildirmek için kullanılabilir. Sonuç olarak, executor’ın daha önce Poll::Pending döndüren bir future üzerinde, karşılık gelen waker tarafından bilgilendirilene kadar poll çağırması gerekmez.
Bu en iyi küçük bir örnekle açıklanır:
async fn write_file() {
async_write_file("foo.txt", "Hello").await;
}Bu fonksiyon, “Hello” dizesini asenkron olarak bir foo.txt dosyasına yazar. Sabit disk yazmaları biraz zaman aldığından, bu future üzerindeki ilk poll çağrısı muhtemelen Poll::Pending döndürecektir. Ancak, sabit disk sürücüsü poll çağrısına geçirilen Waker’ı dahili olarak saklayacak ve dosya diske yazıldığında executor’ı bilgilendirmek için onu kullanacaktır. Bu sayede, executor waker bildirimini almadan önce future’ı tekrar poll etmeye çalışarak zaman kaybetmek zorunda kalmaz.
Waker tipinin nasıl çalıştığını, bu yazının uygulama bölümünde waker desteğiyle kendi executor’ımızı oluşturduğumuzda ayrıntılı olarak göreceğiz.
🔗İşbirlikçi Çoklu Görev mi?
Bu yazının başında, kesintili ve işbirlikçi çoklu görevden bahsettik. Kesintili çoklu görev, çalışan görevler arasında zorla geçiş yapmak için işletim sistemine güvenirken, işbirlikçi çoklu görev, görevlerin düzenli olarak bir yield işlemi aracılığıyla CPU kontrolünü gönüllü olarak bırakmasını gerektirir. İşbirlikçi yaklaşımın büyük avantajı, görevlerin durumlarını kendilerinin kaydedebilmesidir; bu da daha verimli bağlam değiştirmelerle sonuçlanır ve görevler arasında aynı çağrı stack’ini paylaşmayı mümkün kılar.
Hemen belli olmayabilir, ancak future’lar ve async/await, işbirlikçi çoklu görev örüntüsünün bir uygulamasıdır:
- Executor’a eklenen her future temelde işbirlikçi bir görevdir.
- Açık bir yield işlemi kullanmak yerine, future’lar
Poll::Pending(veya sonundaPoll::Ready) döndürerek CPU çekirdeğinin kontrolünü bırakır.- Future’ları CPU’yu bırakmaya zorlayan hiçbir şey yoktur. İsterlerse, örneğin bir döngüde sonsuza dek dönerek,
poll’dan asla geri dönmeyebilirler. - Her future, executor’daki diğer future’ların yürütülmesini bloklayabileceği için, onların kötü niyetli olmadığına güvenmemiz gerekir.
- Future’ları CPU’yu bırakmaya zorlayan hiçbir şey yoktur. İsterlerse, örneğin bir döngüde sonsuza dek dönerek,
- Future’lar, bir sonraki
pollçağrısında yürütmeye devam etmek için ihtiyaç duydukları tüm durumu dahili olarak saklar. Async/await ile, derleyici gereken tüm değişkenleri otomatik olarak tespit eder ve onları üretilen durum makinesinin içinde saklar.- Yalnızca devam için gereken minimum durum kaydedilir.
pollmetodu döndüğünde çağrı stack’ini bıraktığından, aynı stack diğer future’ları poll etmek için kullanılabilir.
Future’ların ve async/await’in işbirlikçi çoklu görev örüntüsüne mükemmel uyduğunu görüyoruz; yalnızca biraz farklı terminoloji kullanırlar. Bu yüzden aşağıda, “görev” ve “future” terimlerini birbirinin yerine kullanacağız.
🔗Uygulama
Artık future’lara ve async/await’e dayalı işbirlikçi çoklu görevin Rust’ta nasıl çalıştığını anladığımıza göre, kernel’imize onun için destek ekleme zamanı geldi. Future trait’i core kütüphanesinin bir parçası olduğundan ve async/await dilin kendisinin bir özelliği olduğundan, onu #![no_std] kernel’imizde kullanmak için yapmamız gereken özel bir şey yok. Tek gereksinim, en az 2020-03-25 tarihli Rust nightly’sini kullanmamızdır; çünkü async/await öncesinde no_std uyumlu değildi.
Yeterince güncel bir nightly ile, main.rs’imizde async/await kullanmaya başlayabiliriz:
// src/main.rs içinde
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}async_number fonksiyonu bir async fn’dir, bu yüzden derleyici onu Future’u uygulayan bir durum makinesine dönüştürür. Fonksiyon yalnızca 42 döndürdüğünden, elde edilen future ilk poll çağrısında doğrudan Poll::Ready(42) döndürecektir. async_number gibi, example_task fonksiyonu da bir async fn’dir. async_number tarafından döndürülen sayıyı bekler ve ardından onu println makrosunu kullanarak yazdırır.
example_task tarafından döndürülen future’ı çalıştırmak için, Poll::Ready döndürerek tamamlanmasını bildirene kadar onun üzerinde poll çağırmamız gerekir. Bunu yapmak için, basit bir executor tipi oluşturmamız gerekir.
🔗Task
Executor uygulamasına başlamadan önce, bir Task tipine sahip yeni bir task modülü oluşturuyoruz:
// src/lib.rs içinde
pub mod task;// src/task/mod.rs içinde
use core::{future::Future, pin::Pin};
use alloc::boxed::Box;
pub struct Task {
future: Pin<Box<dyn Future<Output = ()>>>,
}Task struct’ı, çıktı olarak boş tip ()’a sahip, pin’lenmiş, heap’te ayrılmış ve dinamik olarak yönlendirilen (dynamically dispatched) bir future etrafında bir newtype sarmalayıcısıdır. Onu ayrıntılı olarak inceleyelim:
- Bir görevle ilişkili future’ın
()döndürmesini gerektiririz. Bu, görevlerin herhangi bir sonuç döndürmediği, yalnızca yan etkileri için yürütüldüğü anlamına gelir. Örneğin, yukarıda tanımladığımızexample_taskfonksiyonunun dönüş değeri yoktur, ancak bir yan etki olarak ekrana bir şeyler yazdırır. dynanahtar kelimesi,Box’ta bir trait nesnesi (trait object) sakladığımızı gösterir. Bu, future üzerindeki metotların dinamik olarak yönlendirildiği ve böyleceTasktipinde farklı future tiplerinin saklanmasına olanak tanındığı anlamına gelir. Bu önemlidir, çünkü herasync fn’in kendi tipi vardır ve birden çok farklı görev oluşturabilmek istiyoruz.- Pinning hakkındaki bölümde öğrendiğimiz gibi,
Pin<Box>tipi, bir değeri heap’e yerleştirerek ve ona&mutreferansların oluşturulmasını önleyerek, değerin bellekte taşınamamasını sağlar. Bu önemlidir, çünkü async/await tarafından üretilen future’lar kendine referans verebilir, yani future taşındığında geçersiz kılınacak, kendilerine işaretçiler içerebilir.
Future’lardan yeni Task struct’ları oluşturmaya olanak tanımak için, bir new fonksiyonu oluşturuyoruz:
// src/task/mod.rs içinde
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
future: Box::pin(future),
}
}
}Fonksiyon, çıktı tipi () olan keyfi bir future alır ve onu Box::pin fonksiyonu aracılığıyla bellekte pin’ler. Sonra box’lanmış future’ı Task struct’ına sarmalar ve onu döndürür. 'static yaşam süresi burada gereklidir, çünkü döndürülen Task keyfi bir süre var olabilir, bu yüzden future’ın da o süre boyunca geçerli olması gerekir.
Ayrıca, executor’ın saklanan future’ı poll etmesine olanak tanımak için bir poll metodu ekliyoruz:
// src/task/mod.rs içinde
use core::task::{Context, Poll};
impl Task {
fn poll(&mut self, context: &mut Context) -> Poll<()> {
self.future.as_mut().poll(context)
}
}Future trait’inin poll metodu bir Pin<&mut T> tipi üzerinde çağrılmayı beklediğinden, önce Pin<Box<T>> tipindeki self.future alanını dönüştürmek için Pin::as_mut metodunu kullanıyoruz. Sonra, dönüştürülen self.future alanı üzerinde poll çağırıyor ve sonucu döndürüyoruz. Task::poll metodu yalnızca birazdan oluşturacağımız executor tarafından çağrılmalı olduğundan, fonksiyonu task modülüne özel tutuyoruz.
🔗Basit Executor
Executor’lar oldukça karmaşık olabileceğinden, daha sonra daha özellikli bir executor uygulamadan önce kasıtlı olarak çok temel bir executor oluşturarak başlıyoruz. Bunun için, önce yeni bir task::simple_executor alt modülü oluşturuyoruz:
// src/task/mod.rs içinde
pub mod simple_executor;// src/task/simple_executor.rs içinde
use super::Task;
use alloc::collections::VecDeque;
pub struct SimpleExecutor {
task_queue: VecDeque<Task>,
}
impl SimpleExecutor {
pub fn new() -> SimpleExecutor {
SimpleExecutor {
task_queue: VecDeque::new(),
}
}
pub fn spawn(&mut self, task: Task) {
self.task_queue.push_back(task)
}
}Struct, VecDeque tipinde tek bir task_queue alanı içerir; bu da temelde her iki uçtan push ve pop işlemlerine olanak tanıyan bir vektördür. Bu tipi kullanmanın arkasındaki fikir, spawn metodu aracılığıyla yeni görevleri sona eklememiz ve yürütme için bir sonraki görevi baştan pop’lamamızdır. Bu sayede, basit bir FIFO kuyruğu (“ilk giren, ilk çıkar”) elde ederiz.
🔗Sahte Waker
poll metodunu çağırmak için, bir Waker tipini sarmalayan bir Context tipi oluşturmamız gerekir. Basit başlamak için, önce hiçbir şey yapmayan sahte bir waker oluşturacağız. Bunun için, farklı Waker metotlarının uygulamasını tanımlayan bir RawWaker örneği oluşturuyor ve ardından onu bir Waker’a dönüştürmek için Waker::from_raw fonksiyonunu kullanıyoruz:
// src/task/simple_executor.rs içinde
use core::task::{Waker, RawWaker};
fn dummy_raw_waker() -> RawWaker {
todo!();
}
fn dummy_waker() -> Waker {
unsafe { Waker::from_raw(dummy_raw_waker()) }
}from_raw fonksiyonu unsafe’tir, çünkü programcı RawWaker’ın belgelenmiş gereksinimlerine uymazsa tanımsız davranış meydana gelebilir. dummy_raw_waker fonksiyonunun uygulamasına bakmadan önce, önce RawWaker tipinin nasıl çalıştığını anlamaya çalışıyoruz.
🔗RawWaker
RawWaker tipi, programcının RawWaker klonlandığında, uyandırıldığında veya drop edildiğinde çağrılması gereken fonksiyonları belirten bir sanal metot tablosu (virtual method table) (vtable) açıkça tanımlamasını gerektirir. Bu vtable’ın düzeni RawWakerVTable tipi tarafından tanımlanır. Her fonksiyon, bir değere tipi silinmiş (type-erased) bir işaretçi olan bir *const () argümanı alır. Düzgün bir referans yerine bir *const () işaretçisi kullanmanın nedeni, RawWaker tipinin generic olmaması ama yine de keyfi tipleri desteklemesi gerektiğidir. İşaretçi, yalnızca bir RawWaker’ı başlatan RawWaker::new’in data argümanına konularak sağlanır. Waker daha sonra vtable fonksiyonlarını data ile çağırmak için bu RawWaker’ı kullanır.
Tipik olarak, RawWaker, Box veya Arc tipine sarmalanmış, heap’te ayrılmış bir struct için oluşturulur. Bu tür tipler için, Box<T>’yi bir *const T işaretçisine dönüştürmek için Box::into_raw gibi metotlar kullanılabilir. Bu işaretçi daha sonra anonim bir *const () işaretçisine dönüştürülebilir ve RawWaker::new’e geçirilebilir. Her vtable fonksiyonu argüman olarak aynı *const ()’i aldığından, fonksiyonlar işaretçiyi üzerinde işlem yapmak için güvenli bir şekilde tekrar bir Box<T>’ye veya bir &T’ye dönüştürebilir. Tahmin edebileceğiniz gibi, bu süreç son derece tehlikelidir ve hatalarda kolayca tanımsız davranışa yol açabilir. Bu nedenle, gerekli olmadıkça bir RawWaker’ı elle oluşturmak tavsiye edilmez.
🔗Sahte Bir RawWaker
Bir RawWaker’ı elle oluşturmak tavsiye edilmese de, şu anda hiçbir şey yapmayan sahte bir Waker oluşturmanın başka bir yolu yoktur. Neyse ki, hiçbir şey yapmak istememiz dummy_raw_waker fonksiyonunu uygulamayı nispeten güvenli kılar:
// src/task/simple_executor.rs içinde
use core::task::RawWakerVTable;
fn dummy_raw_waker() -> RawWaker {
fn no_op(_: *const ()) {}
fn clone(_: *const ()) -> RawWaker {
dummy_raw_waker()
}
let vtable = &RawWakerVTable::new(clone, no_op, no_op, no_op);
RawWaker::new(0 as *const (), vtable)
}İlk olarak, no_op ve clone adında iki iç fonksiyon tanımlıyoruz. no_op fonksiyonu bir *const () işaretçisi alır ve hiçbir şey yapmaz. clone fonksiyonu da bir *const () işaretçisi alır ve dummy_raw_waker’ı tekrar çağırarak yeni bir RawWaker döndürür. Bu iki fonksiyonu minimal bir RawWakerVTable oluşturmak için kullanıyoruz: clone fonksiyonu klonlama işlemleri için, no_op fonksiyonu ise diğer tüm işlemler için kullanılır. RawWaker hiçbir şey yapmadığından, clone’dan onu klonlamak yerine yeni bir RawWaker döndürmemizin önemi yoktur.
vtable’ı oluşturduktan sonra, RawWaker’ı oluşturmak için RawWaker::new fonksiyonunu kullanıyoruz. Geçirilen *const () önemli değildir, çünkü vtable fonksiyonlarının hiçbiri onu kullanmaz. Bu nedenle, yalnızca null bir işaretçi geçiriyoruz.
🔗Bir run Metodu
Artık bir Waker örneği oluşturmanın bir yolu olduğuna göre, onu executor’ımızda bir run metodu uygulamak için kullanabiliriz. En basit run metodu, sıraya alınmış tüm görevleri hepsi bitene kadar bir döngüde tekrar tekrar poll etmektir. Bu, Waker tipinin bildirimlerinden yararlanmadığı için çok verimli değildir, ancak işleri çalışır hale getirmenin kolay bir yoludur:
// src/task/simple_executor.rs içinde
use core::task::{Context, Poll};
impl SimpleExecutor {
pub fn run(&mut self) {
while let Some(mut task) = self.task_queue.pop_front() {
let waker = dummy_waker();
let mut context = Context::from_waker(&waker);
match task.poll(&mut context) {
Poll::Ready(()) => {} // görev bitti
Poll::Pending => self.task_queue.push_back(task),
}
}
}
}Fonksiyon, task_queue’daki tüm görevleri ele almak için bir while let döngüsü kullanır. Her görev için, önce dummy_waker fonksiyonumuzun döndürdüğü bir Waker örneğini sarmalayarak bir Context tipi oluşturur. Sonra bu context ile Task::poll metodunu çağırır. poll metodu Poll::Ready döndürürse, görev bitmiştir ve bir sonraki görevle devam edebiliriz. Görev hâlâ Poll::Pending ise, onu kuyruğun sonuna tekrar ekliyoruz; böylece sonraki bir döngü yinelemesinde tekrar poll edilecek.
🔗Denemek
SimpleExecutor tipimizle, artık main.rs’imizde example_task fonksiyonunun döndürdüğü görevi çalıştırmayı deneyebiliriz:
// src/main.rs içinde
use blog_os::task::{Task, simple_executor::SimpleExecutor};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] `init_heap` dahil başlatma rutinleri
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.run();
// […] test_main, "it did not crash" mesajı, hlt_loop
}
// Aşağıda yukarı kaydırmak zorunda kalmamanız için example_task fonksiyonu yeniden
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}Onu çalıştırdığımızda, beklenen “async number: 42” mesajının ekrana yazdırıldığını görüyoruz:
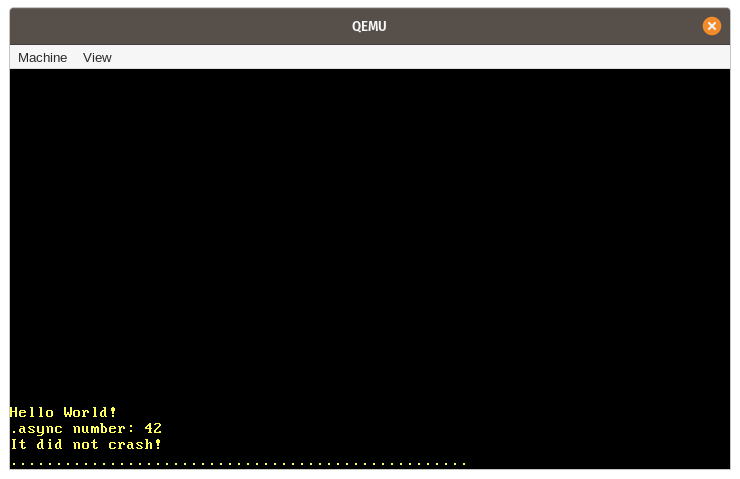
Bu örnekte gerçekleşen çeşitli adımları özetleyelim:
- İlk olarak, boş bir
task_queueileSimpleExecutortipimizin yeni bir örneği oluşturulur. - Sonra, bir future döndüren asenkron
example_taskfonksiyonunu çağırıyoruz. Bu future’ı, onu heap’e taşıyan ve pin’leyenTasktipine sarmalıyor ve ardındanspawnmetodu aracılığıyla görevi executor’ıntask_queue’suna ekliyoruz. - Ardından, kuyruktaki tek görevin yürütülmesini başlatmak için
runmetodunu çağırıyoruz. Bu şunları içerir:- Görevi
task_queue’nun başından pop’lamak. - Görev için bir
RawWakeroluşturmak, onu birWakerörneğine dönüştürmek ve ardından ondan birContextörneği oluşturmak. - Az önce oluşturduğumuz
Context’i kullanarak görevin future’ı üzerindepollmetodunu çağırmak. example_taskhiçbir şey beklemediğinden, ilkpollçağrısında doğrudan sonuna kadar çalışabilir. “async number: 42” satırının yazdırıldığı yer burasıdır.example_taskdoğrudanPoll::Readydöndürdüğünden, görev kuyruğuna tekrar eklenmez.
- Görevi
task_queueboşaldıktan sonrarunmetodu döner.kernel_mainfonksiyonumuzun yürütülmesi devam eder ve “It did not crash!” mesajı yazdırılır.
🔗Asenkron Klavye Girişi
Basit executor’ımız Waker bildirimlerinden yararlanmaz ve yalnızca tüm görevleri bitene kadar döngüye alır. Bu, example_task’ımız ilk poll çağrısında doğrudan sona kadar çalışabildiği için örneğimiz açısından bir sorun değildi. Düzgün bir Waker uygulamasının performans avantajlarını görmek için, önce gerçekten asenkron olan, yani ilk poll çağrısında muhtemelen Poll::Pending döndürecek bir görev oluşturmamız gerekir.
Sistemimizde bunun için kullanabileceğimiz bir tür asenkronluk zaten var: donanım interrupt’ları. Interrupt’lar yazısında öğrendiğimiz gibi, donanım interrupt’ları, bazı harici cihazlar tarafından belirlenen keyfi zaman noktalarında meydana gelebilir. Örneğin, bir donanım timer’ı, önceden tanımlanmış bir süre geçtikten sonra CPU’ya bir interrupt gönderir. CPU bir interrupt aldığında, kontrolü hemen interrupt descriptor table’da (IDT) tanımlanan karşılık gelen handler fonksiyonuna aktarır.
Aşağıda, klavye interrupt’ına dayalı asenkron bir görev oluşturacağız. Klavye interrupt’ı bunun için iyi bir aday, çünkü hem belirsiz (non-deterministic) hem de gecikmeye kritiktir. Belirsiz, bir sonraki tuş basışının ne zaman gerçekleşeceğini tahmin etmenin bir yolu olmadığı anlamına gelir, çünkü tamamen kullanıcıya bağlıdır. Gecikmeye kritik, klavye girdisini zamanında ele almak istediğimiz anlamına gelir; aksi takdirde kullanıcı bir gecikme hisseder. Böyle bir görevi verimli bir şekilde desteklemek için, executor’ın Waker bildirimlerine düzgün desteğe sahip olması olmazsa olmaz olacaktır.
🔗Scancode Kuyruğu
Şu anda, klavye girdisini doğrudan interrupt handler’da ele alıyoruz. Bu uzun vadede iyi bir fikir değil, çünkü interrupt handler’lar önemli işleri kesebilecekleri için mümkün olduğunca kısa kalmalıdır. Bunun yerine, interrupt handler’lar yalnızca gereken minimum miktarda işi yapmalı (örneğin klavye scancode’unu okumak) ve işin geri kalanını (örneğin scancode’u yorumlamak) bir arka plan görevine bırakmalıdır.
İşi bir arka plan görevine devretmek için yaygın bir örüntü, bir tür kuyruk oluşturmaktır. Interrupt handler iş birimlerini kuyruğa push’lar ve arka plan görevi kuyruktaki işi ele alır. Klavye interrupt’ımıza uygulandığında, bu, interrupt handler’ın yalnızca klavyeden scancode’u okuduğu, onu kuyruğa push’ladığı ve ardından döndüğü anlamına gelir. Klavye görevi kuyruğun diğer ucunda oturur ve ona push’lanan her scancode’u yorumlar ve ele alır:

O kuyruğun basit bir uygulaması, mutex korumalı bir VecDeque olabilir. Ancak, interrupt handler’larda mutex kullanmak iyi bir fikir değildir, çünkü kolayca deadlock’lara yol açabilir. Örneğin, klavye görevi kuyruğu kilitlediği sırada kullanıcı bir tuşa bastığında, interrupt handler kilidi tekrar almaya çalışır ve süresiz olarak asılı kalır. Bu yaklaşımın bir başka sorunu, VecDeque’nun dolduğunda yeni bir heap ayırma yaparak kapasitesini otomatik olarak artırmasıdır. Bu da yine deadlock’lara yol açabilir, çünkü allocator’ımız da dahili olarak bir mutex kullanır. Diğer sorunlar, heap ayırmalarının başarısız olabilmesi veya heap parçalandığında önemli miktarda zaman alabilmesidir.
Bu sorunları önlemek için, push işlemi için mutex veya ayırma gerektirmeyen bir kuyruk uygulamasına ihtiyacımız var. Bu tür kuyruklar, eleman push’lamak ve pop’lamak için kilitsiz (lock-free) atomik işlemler kullanılarak uygulanabilir. Bu sayede, yalnızca bir &self referansı gerektiren ve böylece bir mutex olmadan kullanılabilen push ve pop işlemleri oluşturmak mümkündür. push’ta ayırmalardan kaçınmak için, kuyruk önceden ayrılmış sabit boyutlu bir arabellekle desteklenebilir. Bu, kuyruğu sınırlı (bounded) kılarken (yani maksimum bir uzunluğu olur), pratikte kuyruk uzunluğu için makul üst sınırlar tanımlamak çoğu zaman mümkündür, bu yüzden bu büyük bir sorun değildir.
🔗crossbeam Crate’i
Böyle bir kuyruğu doğru ve verimli bir şekilde uygulamak çok zordur, bu yüzden mevcut, iyi test edilmiş uygulamalara bağlı kalmanızı tavsiye ederim. Eşzamanlı programlama için çeşitli mutex’siz tipler uygulayan popüler bir Rust projesi crossbeam’dir. Bu durumda tam olarak ihtiyacımız olan şey olan ArrayQueue adında bir tip sağlar. Ve şanslıyız: tip, ayırma desteğine sahip no_std crate’leriyle tamamen uyumludur.
Tipi kullanmak için, crossbeam-queue crate’ine bir bağımlılık eklememiz gerekir:
# Cargo.toml içinde
[dependencies.crossbeam-queue]
version = "0.3.11"
default-features = false
features = ["alloc"]Varsayılan olarak, crate standart kütüphaneye bağımlıdır. Onu no_std uyumlu kılmak için, varsayılan özelliklerini devre dışı bırakmamız ve bunun yerine alloc özelliğini etkinleştirmemiz gerekir. (crossbeam-queue crate’ini yeniden dışa aktaran ana crossbeam crate’ine de bir bağımlılık ekleyebileceğimizi unutmayın, ancak bu daha fazla sayıda bağımlılık ve daha uzun derleme süreleriyle sonuçlanırdı.)
🔗Kuyruk Uygulaması
ArrayQueue tipini kullanarak, artık yeni bir task::keyboard modülünde global bir scancode kuyruğu oluşturabiliriz:
// src/task/mod.rs içinde
pub mod keyboard;// src/task/keyboard.rs içinde
use conquer_once::spin::OnceCell;
use crossbeam_queue::ArrayQueue;
static SCANCODE_QUEUE: OnceCell<ArrayQueue<u8>> = OnceCell::uninit();ArrayQueue::new bir heap ayırma yaptığından ve bu derleme zamanında (henüz) mümkün olmadığından, statik değişkeni doğrudan başlatamayız. Bunun yerine, conquer_once crate’inin OnceCell tipini kullanıyoruz; bu, statik değerlerin güvenli bir kerelik başlatılmasını yapmayı mümkün kılar. Crate’i dahil etmek için, onu Cargo.toml’umuzda bir bağımlılık olarak eklememiz gerekir:
# Cargo.toml içinde
[dependencies.conquer-once]
version = "0.2.0"
default-features = falseOnceCell ilkeli yerine, burada lazy_static makrosunu da kullanabilirdik. Ancak, OnceCell tipinin, başlatmanın interrupt handler’da gerçekleşmemesini sağlayabilme ve böylece interrupt handler’ın bir heap ayırma yapmasını önleme avantajı vardır.
🔗Kuyruğu Doldurmak
Scancode kuyruğunu doldurmak için, interrupt handler’dan çağıracağımız yeni bir add_scancode fonksiyonu oluşturuyoruz:
// src/task/keyboard.rs içinde
use crate::println;
/// Klavye interrupt handler'ı tarafından çağrılır
///
/// Bloklamamalı veya ayırma yapmamalıdır.
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}Başlatılmış kuyruğa bir referans almak için OnceCell::try_get’i kullanıyoruz. Kuyruk henüz başlatılmamışsa, klavye scancode’unu yok sayıyor ve bir uyarı yazdırıyoruz. Kuyruğu bu fonksiyonda başlatmaya çalışmamamız önemlidir, çünkü heap ayırmaları yapmaması gereken interrupt handler tarafından çağrılacaktır. Bu fonksiyon main.rs’imizden çağrılabilir olmaması gerektiğinden, onu yalnızca lib.rs’imize kullanılabilir kılmak için pub(crate) görünürlüğünü kullanıyoruz.
ArrayQueue::push metodunun yalnızca bir &self referansı gerektirmesi, metodu statik kuyrukta çağırmayı çok basit kılar. ArrayQueue tipi gereken tüm senkronizasyonu kendisi yapar, bu yüzden burada bir mutex sarmalayıcısına ihtiyacımız yok. Kuyruğun dolu olması durumunda, bir uyarı da yazdırıyoruz.
add_scancode fonksiyonunu klavye interrupt’larında çağırmak için, interrupts modülündeki keyboard_interrupt_handler fonksiyonumuzu güncelliyoruz:
// src/interrupts.rs içinde
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame
) {
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
crate::task::keyboard::add_scancode(scancode); // yeni
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}Tüm klavye işleme kodunu bu fonksiyondan kaldırdık ve bunun yerine add_scancode fonksiyonuna bir çağrı ekledik. Fonksiyonun geri kalanı öncekiyle aynı kalır.
Beklendiği gibi, projemizi şimdi cargo run kullanarak çalıştırdığımızda tuş basışları artık ekrana yazdırılmıyor. Bunun yerine, her tuş vuruşunda scancode kuyruğunun başlatılmadığı uyarısını görüyoruz.
🔗Scancode Stream’i
SCANCODE_QUEUE’yu başlatmak ve scancode’ları kuyruktan asenkron bir şekilde okumak için, yeni bir ScancodeStream tipi oluşturuyoruz:
// src/task/keyboard.rs içinde
pub struct ScancodeStream {
_private: (),
}
impl ScancodeStream {
pub fn new() -> Self {
SCANCODE_QUEUE.try_init_once(|| ArrayQueue::new(100))
.expect("ScancodeStream::new should only be called once");
ScancodeStream { _private: () }
}
}_private alanının amacı, struct’ın modülün dışından yapımını önlemektir. Bu, new fonksiyonunu tipi yapılandırmanın tek yolu yapar. Fonksiyonda, önce SCANCODE_QUEUE static’ini başlatmaya çalışıyoruz. Yalnızca tek bir ScancodeStream örneğinin oluşturulabilmesini sağlamak için, zaten başlatılmışsa panic yapıyoruz.
Scancode’ları asenkron görevlere kullanılabilir kılmak için, sonraki adım, kuyruktaki bir sonraki scancode’u pop’lamayı deneyen poll benzeri bir metot uygulamaktır. Bu, tipimiz için Future trait’ini uygulamamız gerektiği gibi görünse de, burada tam olarak uymuyor. Sorun, Future trait’inin yalnızca tek bir asenkron değer üzerinde soyutlama yapması ve poll metodunun Poll::Ready döndürdükten sonra tekrar çağrılmamasını beklemesidir. Ancak scancode kuyruğumuz birden çok asenkron değer içerir, bu yüzden onu poll etmeye devam etmek sorun değildir.
🔗Stream Trait’i
Birden çok asenkron değer veren tipler yaygın olduğundan, futures crate’i bu tür tipler için yararlı bir soyutlama sağlar: Stream trait’i. Trait şöyle tanımlanır:
pub trait Stream {
type Item;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Option<Self::Item>>;
}Bu tanım, aşağıdaki farklarla, Future trait’ine oldukça benzer:
- İlişkili tip
OutputyerineItemolarak adlandırılır. Poll<Self::Item>döndüren birpollmetodu yerine,Streamtrait’iPoll<Option<Self::Item>>döndüren birpoll_nextmetodu tanımlar (ekOption’a dikkat edin).
Anlamsal bir fark da vardır: poll_next, stream’in bittiğini bildirmek için Poll::Ready(None) döndürene kadar tekrar tekrar çağrılabilir. Bu açıdan, metot, son değerden sonra da None döndüren Iterator::next metoduna benzer.
🔗Stream’i Uygulamak
SCANCODE_QUEUE’nun değerlerini asenkron bir şekilde sağlamak için ScancodeStream’imiz için Stream trait’ini uygulayalım. Bunun için, önce Stream tipini içeren futures-util crate’ine bir bağımlılık eklememiz gerekir:
# Cargo.toml içinde
[dependencies.futures-util]
version = "0.3.4"
default-features = false
features = ["alloc"]Crate’i no_std uyumlu kılmak için varsayılan özellikleri devre dışı bırakıyor ve ayırma tabanlı tiplerini kullanılabilir kılmak için alloc özelliğini etkinleştiriyoruz (buna daha sonra ihtiyacımız olacak). (futures-util crate’ini yeniden dışa aktaran ana futures crate’ine de bir bağımlılık ekleyebileceğimizi unutmayın, ancak bu daha fazla sayıda bağımlılık ve daha uzun derleme süreleriyle sonuçlanırdı.)
Artık Stream trait’ini içe aktarabilir ve uygulayabiliriz:
// src/task/keyboard.rs içinde
use core::{pin::Pin, task::{Poll, Context}};
use futures_util::stream::Stream;
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE.try_get().expect("not initialized");
match queue.pop() {
Some(scancode) => Poll::Ready(Some(scancode)),
None => Poll::Pending,
}
}
}Önce, başlatılmış scancode kuyruğuna bir referans almak için OnceCell::try_get metodunu kullanıyoruz. Kuyruğu new fonksiyonunda başlattığımız için bu asla başarısız olmamalı, bu yüzden başlatılmamışsa panic yapmak için güvenle expect metodunu kullanabiliriz. Sonra, kuyruktan bir sonraki elemanı almayı denemek için ArrayQueue::pop metodunu kullanıyoruz. Başarılı olursa, scancode’u Poll::Ready(Some(…))’da sarmalanmış olarak döndürüyoruz. Başarısız olursa, bu kuyruğun boş olduğu anlamına gelir. Bu durumda, Poll::Pending döndürüyoruz.
🔗Waker Desteği
Futures::poll metodu gibi, Stream::poll_next metodu da, Poll::Pending döndürüldükten sonra asenkron görevin hazır hale geldiğinde executor’ı bilgilendirmesini gerektirir. Bu sayede, executor’ın bilgilendirilene kadar aynı görevi tekrar poll etmesine gerek kalmaz; bu da bekleyen görevlerin performans yükünü büyük ölçüde azaltır.
Bu bildirimi göndermek için, görev geçirilen Context referansından Waker’ı çıkarmalı ve onu bir yerde saklamalıdır. Görev hazır hale geldiğinde, executor’a görevin tekrar poll edilmesi gerektiğini bildirmek için saklanan Waker üzerinde wake metodunu çağırmalıdır.
🔗AtomicWaker
ScancodeStream’imiz için Waker bildirimini uygulamak için, Waker’ı poll çağrıları arasında saklayabileceğimiz bir yere ihtiyacımız var. Onu ScancodeStream’in kendisinde bir alan olarak saklayamayız, çünkü add_scancode fonksiyonundan erişilebilir olması gerekir. Buna çözüm, futures-util crate’inin sağladığı AtomicWaker tipinde bir statik değişken kullanmaktır. ArrayQueue tipi gibi, bu tip de atomik komutlara dayanır ve güvenli bir şekilde bir static’te saklanabilir ve eşzamanlı olarak değiştirilebilir.
AtomicWaker tipini kullanarak statik bir WAKER tanımlayalım:
// src/task/keyboard.rs içinde
use futures_util::task::AtomicWaker;
static WAKER: AtomicWaker = AtomicWaker::new();Fikir, poll_next uygulamasının mevcut waker’ı bu statiğe saklaması ve add_scancode fonksiyonunun kuyruğa yeni bir scancode eklendiğinde onun üzerinde wake fonksiyonunu çağırmasıdır.
🔗Bir Waker Saklamak
poll/poll_next tarafından tanımlanan sözleşme, Poll::Pending döndürdüğünde görevin geçirilen Waker için bir uyandırma kaydetmesini gerektirir. poll_next uygulamamızı bu gereksinimi karşılayacak şekilde değiştirelim:
// src/task/keyboard.rs içinde
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE
.try_get()
.expect("scancode queue not initialized");
// hızlı yol (fast path)
if let Some(scancode) = queue.pop() {
return Poll::Ready(Some(scancode));
}
WAKER.register(&cx.waker());
match queue.pop() {
Some(scancode) => {
WAKER.take();
Poll::Ready(Some(scancode))
}
None => Poll::Pending,
}
}
}Önceki gibi, önce başlatılmış scancode kuyruğuna bir referans almak için OnceCell::try_get fonksiyonunu kullanıyoruz. Sonra iyimser bir şekilde kuyruktan pop etmeyi deniyor ve başarılı olduğunda Poll::Ready döndürüyoruz. Bu sayede, kuyruk boş olmadığında bir waker kaydetmenin performans yükünden kaçınabiliriz.
queue.pop()’a yapılan ilk çağrı başarılı olmazsa, kuyruk potansiyel olarak boştur. Yalnızca potansiyel olarak, çünkü interrupt handler kontrolden hemen sonra kuyruğu asenkron olarak doldurmuş olabilir. Bu race condition bir sonraki kontrol için tekrar meydana gelebileceğinden, ikinci kontrolden önce Waker’ı WAKER static’ine kaydetmemiz gerekir. Bu sayede, bir uyandırma Poll::Pending döndürmeden önce gerçekleşebilir, ancak kontrolden sonra push’lanan herhangi bir scancode için bir uyandırma alacağımız garanti edilir.
Geçirilen Context’te bulunan Waker’ı AtomicWaker::register fonksiyonu aracılığıyla kaydettikten sonra, kuyruktan ikinci kez pop etmeyi deniyoruz. Şimdi başarılı olursa, Poll::Ready döndürüyoruz. Bir waker bildirimine artık ihtiyaç olmadığı için, kaydedilen waker’ı AtomicWaker::take kullanarak tekrar kaldırıyoruz. queue.pop() ikinci kez de başarısız olursa, önceki gibi Poll::Pending döndürüyoruz, ancak bu kez kaydedilmiş bir uyandırmayla.
(Henüz) Poll::Pending döndürmeyen bir görev için bir uyandırmanın gerçekleşebileceği iki yol olduğunu unutmayın. Bir yol, uyandırma Poll::Pending döndürmeden hemen önce gerçekleştiğinde bahsedilen race condition’dır. Diğer yol, waker’ı kaydettikten sonra kuyruğun artık boş olmaması ve böylece Poll::Ready döndürülmesidir. Bu sahte (spurious) uyandırmalar önlenebilir olmadığından, executor’ın onları doğru bir şekilde ele alabilmesi gerekir.
🔗Saklanan Waker’ı Uyandırmak
Saklanan Waker’ı uyandırmak için, add_scancode fonksiyonuna bir WAKER.wake() çağrısı ekliyoruz:
// src/task/keyboard.rs içinde
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
} else {
WAKER.wake(); // yeni
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}Yaptığımız tek değişiklik, scancode kuyruğuna push başarılı olursa bir WAKER.wake() çağrısı eklemektir. WAKER static’inde bir waker kayıtlıysa, bu metot onun üzerinde aynı adlı wake metodunu çağırır; bu da executor’ı bilgilendirir. Aksi takdirde, işlem bir no-op’tur, yani hiçbir şey olmaz.
wake’i yalnızca kuyruğa push’ladıktan sonra çağırmamız önemlidir, çünkü aksi takdirde görev kuyruk hâlâ boşken çok erken uyandırılabilir. Bu, örneğin uyandırılan görevi farklı bir CPU çekirdeğinde eşzamanlı olarak başlatan çok thread’li bir executor kullanırken gerçekleşebilir. Henüz thread desteğimiz olmasa da, yakında ekleyeceğiz ve o zaman işlerin bozulmasını istemiyoruz.
🔗Klavye Görevi
Artık ScancodeStream’imiz için Stream trait’ini uyguladığımıza göre, onu asenkron bir klavye görevi oluşturmak için kullanabiliriz:
// src/task/keyboard.rs içinde
use futures_util::stream::StreamExt;
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use crate::print;
pub async fn print_keypresses() {
let mut scancodes = ScancodeStream::new();
let mut keyboard = Keyboard::new(ScancodeSet1::new(),
layouts::Us104Key, HandleControl::Ignore);
while let Some(scancode) = scancodes.next().await {
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
}
}Kod, bu yazıda değiştirmeden önce klavye interrupt handler’ımızda sahip olduğumuz koda çok benzer. Tek fark, scancode’u bir G/Ç portundan okumak yerine onu ScancodeStream’den almamızdır. Bunun için, önce yeni bir Scancode stream’i oluşturuyor ve ardından stream’deki bir sonraki elemana çözümlenen (resolve) bir Future almak için StreamExt trait’inin sağladığı next metodunu tekrar tekrar kullanıyoruz. Onun üzerinde await operatörünü kullanarak, future’ın sonucunu asenkron olarak bekliyoruz.
Stream sonunu bildirmek için None döndürene kadar döngüye almak için while let kullanıyoruz. poll_next metodumuz asla None döndürmediğinden, bu aslında sonsuz bir döngüdür, bu yüzden print_keypresses görevi asla bitmez.
print_keypresses görevini main.rs’imizde executor’ımıza ekleyerek tekrar çalışan klavye girdisi elde edelim:
// src/main.rs içinde
use blog_os::task::keyboard; // yeni
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] init_heap, test_main dahil başlatma rutinleri
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses())); // yeni
executor.run();
// […] "it did not crash" mesajı, hlt_loop
}Şimdi cargo run çalıştırdığımızda, klavye girdisinin tekrar çalıştığını görüyoruz:

Bilgisayarınızın CPU kullanımına göz kulak olursanız, QEMU sürecinin artık CPU’yu sürekli meşgul tuttuğunu görürsünüz. Bu, SimpleExecutor’ımızın görevleri bir döngüde tekrar tekrar poll etmesi nedeniyle olur. Yani klavyede herhangi bir tuşa basmasak bile, executor print_keypresses görevimiz üzerinde, görev hiçbir ilerleme kaydedemese ve her seferinde Poll::Pending döndürecek olsa bile, tekrar tekrar poll çağırır.
🔗Waker Destekli Executor
Performans sorununu düzeltmek için, Waker bildirimlerinden düzgün bir şekilde yararlanan bir executor oluşturmamız gerekir. Bu sayede, executor bir sonraki klavye interrupt’ı meydana geldiğinde bilgilendirilir, bu yüzden print_keypresses görevini tekrar tekrar poll etmeye devam etmesine gerek kalmaz.
🔗Görev Kimliği (Task Id)
Düzgün waker bildirimi desteğine sahip bir executor oluşturmanın ilk adımı, her göreve benzersiz bir kimlik (ID) vermektir. Bu gereklidir, çünkü hangi görevin uyandırılması gerektiğini belirtmenin bir yoluna ihtiyacımız var. Yeni bir TaskId sarmalayıcı tipi oluşturarak başlıyoruz:
// src/task/mod.rs içinde
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord)]
struct TaskId(u64);TaskId struct’ı, u64 etrafında basit bir sarmalayıcı tipidir. Onu yazdırılabilir, kopyalanabilir, karşılaştırılabilir ve sıralanabilir kılmak için bir dizi trait türetiyoruz. Sonuncusu önemlidir, çünkü birazdan TaskId’yi bir BTreeMap’in anahtar tipi olarak kullanmak istiyoruz.
Yeni bir benzersiz ID oluşturmak için, bir TaskId::new fonksiyonu oluşturuyoruz:
use core::sync::atomic::{AtomicU64, Ordering};
impl TaskId {
fn new() -> Self {
static NEXT_ID: AtomicU64 = AtomicU64::new(0);
TaskId(NEXT_ID.fetch_add(1, Ordering::Relaxed))
}
}Fonksiyon, her ID’nin yalnızca bir kez atanmasını sağlamak için AtomicU64 tipinde statik bir NEXT_ID değişkeni kullanır. fetch_add metodu, değeri atomik olarak artırır ve önceki değeri tek bir atomik işlemde döndürür. Bu, TaskId::new metodu paralel olarak çağrıldığında bile her ID’nin tam olarak bir kez döndürüldüğü anlamına gelir. Ordering parametresi, derleyicinin fetch_add işlemini komut akışında yeniden sıralamasına izin verilip verilmediğini tanımlar. Yalnızca ID’nin benzersiz olmasını gerektirdiğimizden, en zayıf gereksinimlere sahip Relaxed sıralaması bu durumda yeterlidir.
Artık Task tipimizi ek bir id alanıyla genişletebiliriz:
// src/task/mod.rs içinde
pub struct Task {
id: TaskId, // yeni
future: Pin<Box<dyn Future<Output = ()>>>,
}
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
id: TaskId::new(), // yeni
future: Box::pin(future),
}
}
}Yeni id alanı, bir görevi benzersiz olarak adlandırmayı mümkün kılar; ki bu, belirli bir görevi uyandırmak için gereklidir.
🔗Executor Tipi
Yeni Executor tipimizi bir task::executor modülünde oluşturuyoruz:
// src/task/mod.rs içinde
pub mod executor;// src/task/executor.rs içinde
use super::{Task, TaskId};
use alloc::{collections::BTreeMap, sync::Arc};
use core::task::Waker;
use crossbeam_queue::ArrayQueue;
pub struct Executor {
tasks: BTreeMap<TaskId, Task>,
task_queue: Arc<ArrayQueue<TaskId>>,
waker_cache: BTreeMap<TaskId, Waker>,
}
impl Executor {
pub fn new() -> Self {
Executor {
tasks: BTreeMap::new(),
task_queue: Arc::new(ArrayQueue::new(100)),
waker_cache: BTreeMap::new(),
}
}
}SimpleExecutor’ımız için yaptığımız gibi görevleri bir VecDeque’de saklamak yerine, görev ID’lerinden oluşan bir task_queue ve gerçek Task örneklerini içeren tasks adında bir BTreeMap kullanıyoruz. Map, belirli bir görevin verimli bir şekilde sürdürülmesine olanak tanımak için TaskId tarafından indekslenir.
task_queue alanı, referans sayımı (reference counting) uygulayan Arc tipine sarmalanmış, görev ID’lerinden oluşan bir ArrayQueue’dur. Referans sayımı, bir değerin sahipliğini birden çok sahip arasında paylaşmayı mümkün kılar. Değeri heap’te ayırarak ve ona yapılan aktif referansların sayısını sayarak çalışır. Aktif referansların sayısı sıfıra ulaştığında, değere artık ihtiyaç yoktur ve deallocate edilebilir.
task_queue için bu Arc<ArrayQueue> tipini kullanıyoruz, çünkü executor ile waker’lar arasında paylaşılacaktır. Fikir, waker’ların uyandırılan görevin ID’sini kuyruğa push’lamasıdır. Executor kuyruğun alıcı ucunda oturur, uyandırılan görevleri ID’lerine göre tasks map’inden alır ve ardından onları çalıştırır. SegQueue gibi sınırsız bir kuyruk yerine sabit boyutlu bir kuyruk kullanmanın nedeni, interrupt handler’ların bu kuyruğa push’ta ayırma yapmaması gerektiğidir.
task_queue ve tasks map’ine ek olarak, Executor tipinin yine bir map olan bir waker_cache alanı vardır. Bu map, oluşturulduktan sonra bir görevin Waker’ını önbelleğe alır. Bunun iki nedeni vardır: İlki, aynı görevin birden çok uyandırması için her seferinde yeni bir waker oluşturmak yerine aynı waker’ı yeniden kullanarak performansı iyileştirir. İkincisi, referans sayımlı waker’ların interrupt handler’ların içinde deallocate edilmemesini sağlar; çünkü bu deadlock’lara yol açabilir (bunun hakkında aşağıda daha fazla ayrıntı var).
Bir Executor oluşturmak için, basit bir new fonksiyonu sağlıyoruz. task_queue için 100 kapasitesini seçiyoruz; bu, öngörülebilir gelecek için fazlasıyla yeterli olmalı. Sistemimizin bir noktada 100’den fazla eşzamanlı görevi olması durumunda, bu boyutu kolayca artırabiliriz.
🔗Görev Başlatmak (Spawning)
SimpleExecutor’da olduğu gibi, Executor tipimizde, verilen bir görevi tasks map’ine ekleyen ve ID’sini task_queue’ya push’layarak onu hemen uyandıran bir spawn metodu sağlıyoruz:
// src/task/executor.rs içinde
impl Executor {
pub fn spawn(&mut self, task: Task) {
let task_id = task.id;
if self.tasks.insert(task.id, task).is_some() {
panic!("task with same ID already in tasks");
}
self.task_queue.push(task_id).expect("queue full");
}
}Map’te aynı ID’ye sahip bir görev zaten varsa, [BTreeMap::insert] metodu onu döndürür. Her görevin benzersiz bir ID’si olduğundan bu asla olmamalı, bu yüzden bu durumda kodumuzda bir hata olduğunu gösterdiği için panic yapıyoruz. Benzer şekilde, yeterince büyük bir kuyruk boyutu seçersek bu asla olmaması gerektiğinden, task_queue dolu olduğunda panic yapıyoruz.
🔗Görevleri Çalıştırmak
task_queue’daki tüm görevleri yürütmek için, özel bir run_ready_tasks metodu oluşturuyoruz:
// src/task/executor.rs içinde
use core::task::{Context, Poll};
impl Executor {
fn run_ready_tasks(&mut self) {
// borrow checker hatalarından kaçınmak için `self`'i yapısöküme uğrat
let Self {
tasks,
task_queue,
waker_cache,
} = self;
while let Some(task_id) = task_queue.pop() {
let task = match tasks.get_mut(&task_id) {
Some(task) => task,
None => continue, // görev artık yok
};
let waker = waker_cache
.entry(task_id)
.or_insert_with(|| TaskWaker::new(task_id, task_queue.clone()));
let mut context = Context::from_waker(waker);
match task.poll(&mut context) {
Poll::Ready(()) => {
// görev bitti -> onu ve önbelleğe alınmış waker'ını kaldır
tasks.remove(&task_id);
waker_cache.remove(&task_id);
}
Poll::Pending => {}
}
}
}
}Bu fonksiyonun temel fikri SimpleExecutor’ımıza benzer: task_queue’daki tüm görevler üzerinde döngüye al, her görev için bir waker oluştur ve ardından onları poll et. Ancak, beklemedeki görevleri task_queue’nun sonuna tekrar eklemek yerine, uyandırılan görevleri kuyruğa geri eklemekle TaskWaker uygulamamızın ilgilenmesine izin veriyoruz. Bu waker tipinin uygulaması birazdan gösterilecek.
Bu run_ready_tasks metodunun bazı uygulama detaylarına bakalım:
-
Bazı borrow checker hatalarından kaçınmak için
self’i üç alanına bölmek üzere yapısöküm (destructuring) kullanıyoruz. Yani, uygulamamızınself.task_queue’ya bir closure’ın içinden erişmesi gerekiyor; ki bu closure şu andaself’i tamamen ödünç almaya çalışıyor. Bu, RFC 2229 uygulandığında çözülecek temel bir borrow checker sorunudur. -
Pop’lanan her görev ID’si için,
tasksmap’inden karşılık gelen göreve değiştirilebilir bir referans alıyoruz.ScancodeStreamuygulamamız, bir görevin uyutulması gerekip gerekmediğini kontrol etmeden önce waker’ları kaydettiğinden, artık var olmayan bir görev için bir uyandırmanın gerçekleşmesi olabilir. Bu durumda, uyandırmayı basitçe yok sayıyor ve kuyruktaki bir sonraki ID ile devam ediyoruz. -
Her poll’da bir waker oluşturmanın performans yükünden kaçınmak için, her görevin waker’ını oluşturulduktan sonra saklamak amacıyla
waker_cachemap’ini kullanıyoruz. Bunun için, henüz yoksa yeni bir waker oluşturmak ve ardından ona değiştirilebilir bir referans almak amacıylaBTreeMap::entrymetodunuEntry::or_insert_withile birlikte kullanıyoruz. Yeni bir waker oluşturmak için,task_queue’yu klonluyor ve onu görev ID’siyle birlikteTaskWaker::newfonksiyonuna geçiriyoruz (uygulaması aşağıda gösterilmiştir).task_queuebirArc’a sarmalandığından,cloneyalnızca değerin referans sayısını artırır, ancak yine de aynı heap’te ayrılmış kuyruğa işaret eder. Waker’ları bu şekilde yeniden kullanmanın tüm waker uygulamaları için mümkün olmadığını, ancakTaskWakertipimizin buna izin vereceğini unutmayın.
Bir görev Poll::Ready döndürdüğünde biter. Bu durumda, onu BTreeMap::remove metodunu kullanarak tasks map’inden kaldırıyoruz. Varsa, önbelleğe alınmış waker’ını da kaldırıyoruz.
🔗Waker Tasarımı
Waker’ın görevi, uyandırılan görevin ID’sini executor’ın task_queue’suna push’lamaktır. Bunu, görev ID’sini ve task_queue’ya bir referansı saklayan yeni bir TaskWaker struct’ı oluşturarak uyguluyoruz:
// src/task/executor.rs içinde
struct TaskWaker {
task_id: TaskId,
task_queue: Arc<ArrayQueue<TaskId>>,
}task_queue’nun sahipliği executor ile waker’lar arasında paylaşıldığından, paylaşılan referans sayımlı sahipliği uygulamak için Arc sarmalayıcı tipini kullanıyoruz.
Uyandırma işleminin uygulaması oldukça basittir:
// src/task/executor.rs içinde
impl TaskWaker {
fn wake_task(&self) {
self.task_queue.push(self.task_id).expect("task_queue full");
}
}task_id’yi referans verilen task_queue’ya push’luyoruz. ArrayQueue tipindeki değişiklikler yalnızca paylaşılan bir referans gerektirdiğinden, bu metodu &mut self yerine &self üzerinde uygulayabiliriz.
🔗Wake Trait’i
TaskWaker tipimizi future’ları poll etmek için kullanmak amacıyla, önce onu bir Waker örneğine dönüştürmemiz gerekir. Bu gereklidir, çünkü Future::poll metodu argüman olarak yalnızca Waker tipinden yapılandırılabilen bir Context örneği alır. Bunu RawWaker tipinin bir uygulamasını sağlayarak yapabilsek de, bunun yerine Arc tabanlı Wake trait’ini uygulamak ve ardından Waker’ı yapılandırmak için standart kütüphanenin sağladığı From uygulamalarını kullanmak hem daha basit hem de daha güvenlidir.
Trait uygulaması şöyle görünür:
// src/task/executor.rs içinde
use alloc::task::Wake;
impl Wake for TaskWaker {
fn wake(self: Arc<Self>) {
self.wake_task();
}
fn wake_by_ref(self: &Arc<Self>) {
self.wake_task();
}
}Waker’lar genellikle executor ile asenkron görevler arasında paylaşıldığından, trait metotları Self örneğinin, referans sayımlı sahipliği uygulayan Arc tipine sarmalanmasını gerektirir. Bu, onları çağırmak için TaskWaker’ımızı bir Arc’a taşımamız gerektiği anlamına gelir.
wake ve wake_by_ref metotları arasındaki fark, ikincisinin yalnızca Arc’a bir referans gerektirmesi, birincisinin ise Arc’ın sahipliğini alması ve böylece çoğu zaman referans sayısında bir artış gerektirmesidir. Tüm tipler referansla uyandırmayı desteklemez, bu yüzden wake_by_ref metodunu uygulamak isteğe bağlıdır. Ancak, gereksiz referans sayısı değişikliklerinden kaçındığı için daha iyi performansa yol açabilir. Bizim durumumuzda, her iki trait metodunu da, yalnızca paylaşılan bir &self referansı gerektiren wake_task fonksiyonumuza basitçe yönlendirebiliriz.
🔗Waker’lar Oluşturmak
Waker tipi, Wake trait’ini uygulayan tüm Arc’a sarmalanmış değerler için From dönüşümlerini desteklediğinden, artık Executor::run_ready_tasks metodumuzun gerektirdiği TaskWaker::new fonksiyonunu uygulayabiliriz:
// src/task/executor.rs içinde
impl TaskWaker {
fn new(task_id: TaskId, task_queue: Arc<ArrayQueue<TaskId>>) -> Waker {
Waker::from(Arc::new(TaskWaker {
task_id,
task_queue,
}))
}
}TaskWaker’ı geçirilen task_id ve task_queue kullanarak oluşturuyoruz. Sonra TaskWaker’ı bir Arc’a sarmalıyor ve onu bir Waker’a dönüştürmek için Waker::from uygulamasını kullanıyoruz. Bu from metodu, TaskWaker tipimiz için bir RawWakerVTable ve bir RawWaker örneği yapılandırmayla ilgilenir. Ayrıntılı olarak nasıl çalıştığıyla ilgileniyorsanız, alloc crate’indeki uygulamaya göz atın.
🔗Bir run Metodu
Waker uygulamamız yerinde olduğuna göre, artık executor’ımız için nihayet bir run metodu yapılandırabiliriz:
// src/task/executor.rs içinde
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
}
}
}Bu metot yalnızca bir döngüde run_ready_tasks fonksiyonunu çağırır. Teorik olarak tasks map’i boşaldığında fonksiyondan dönebilsek de, keyboard::print_keypresses görevimiz asla bitmediği için bu asla gerçekleşmez, bu yüzden basit bir loop yeterli olur. Fonksiyon asla geri dönmediğinden, fonksiyonu derleyiciye ıraksayan (diverging) olarak işaretlemek için ! dönüş tipini kullanıyoruz.
Artık kernel_main’imizi SimpleExecutor yerine yeni Executor’ımızı kullanacak şekilde değiştirebiliriz:
// src/main.rs içinde
use blog_os::task::executor::Executor; // yeni
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] init_heap, test_main dahil başlatma rutinleri
let mut executor = Executor::new(); // yeni
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses()));
executor.run();
}Yalnızca içe aktarmayı ve tip adını değiştirmemiz gerekiyor. run fonksiyonumuz ıraksayan olarak işaretlendiğinden, derleyici onun asla geri dönmediğini bilir, bu yüzden kernel_main fonksiyonumuzun sonunda artık bir hlt_loop çağrısına ihtiyacımız yok.
Kernel’imizi şimdi cargo run kullanarak çalıştırdığımızda, klavye girdisinin hâlâ çalıştığını görüyoruz:

Ancak, QEMU’nun CPU kullanımı hiç iyileşmedi. Bunun nedeni, hâlâ CPU’yu her zaman meşgul tutmamızdır. Görevleri artık tekrar uyandırılana kadar poll etmiyoruz, ancak task_queue’yu yine de meşgul bir döngüde kontrol ediyoruz. Bunu düzeltmek için, yapacak iş kalmadığında CPU’yu uykuya yatırmamız gerekir.
🔗Boştaysa Uyu
Temel fikir, task_queue boş olduğunda hlt komutunu yürütmektir. Bu komut, bir sonraki interrupt gelene kadar CPU’yu uykuya yatırır. CPU’nun interrupt’larda hemen tekrar aktif hale gelmesi, bir interrupt handler task_queue’ya push’ladığında hâlâ doğrudan tepki verebilmemizi sağlar.
Bunu uygulamak için, executor’ımızda yeni bir sleep_if_idle metodu oluşturuyor ve onu run metodumuzdan çağırıyoruz:
// src/task/executor.rs içinde
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
self.sleep_if_idle(); // yeni
}
}
fn sleep_if_idle(&self) {
if self.task_queue.is_empty() {
x86_64::instructions::hlt();
}
}
}sleep_if_idle’ı, task_queue boşalana kadar döngüye giren run_ready_tasks’tan hemen sonra çağırdığımızdan, kuyruğu tekrar kontrol etmek gereksiz görünebilir. Ancak, run_ready_tasks döndükten hemen sonra bir donanım interrupt’ı meydana gelebilir, bu yüzden sleep_if_idle fonksiyonu çağrıldığında kuyrukta yeni bir görev olabilir. Yalnızca kuyruk hâlâ boşsa, x86_64 crate’inin sağladığı instructions::hlt sarmalayıcı fonksiyonu aracılığıyla hlt komutunu yürüterek CPU’yu uykuya yatırıyoruz.
Ne yazık ki, bu uygulamada hâlâ ince bir race condition var. Interrupt’lar asenkron olduğundan ve herhangi bir zamanda gerçekleşebileceğinden, bir interrupt’ın tam olarak is_empty kontrolü ile hlt çağrısı arasında gerçekleşmesi mümkündür:
if self.task_queue.is_empty() {
/// <--- interrupt burada gerçekleşebilir
x86_64::instructions::hlt();
}Bu interrupt task_queue’ya push’larsa, artık hazır bir görev olmasına rağmen CPU’yu uykuya yatırırız. En kötü durumda, bu, bir klavye interrupt’ının ele alınmasını bir sonraki tuş basışına veya bir sonraki timer interrupt’ına kadar geciktirebilir. Peki bunu nasıl önleriz?
Cevap, kontrolden önce CPU’da interrupt’ları devre dışı bırakmak ve onları hlt komutuyla birlikte atomik olarak tekrar etkinleştirmektir. Bu sayede, aradaki tüm interrupt’lar hlt komutundan sonraya ertelenir, böylece hiçbir uyandırma kaçırılmaz. Bu yaklaşımı uygulamak için, x86_64 crate’inin sağladığı interrupts::enable_and_hlt fonksiyonunu kullanabiliriz.
sleep_if_idle fonksiyonumuzun güncellenmiş uygulaması şöyle görünür:
// src/task/executor.rs içinde
impl Executor {
fn sleep_if_idle(&self) {
use x86_64::instructions::interrupts::{self, enable_and_hlt};
interrupts::disable();
if self.task_queue.is_empty() {
enable_and_hlt();
} else {
interrupts::enable();
}
}
}Race condition’lardan kaçınmak için, task_queue’nun boş olup olmadığını kontrol etmeden önce interrupt’ları devre dışı bırakıyoruz. Boşsa, interrupt’ları etkinleştirmek ve CPU’yu tek bir atomik işlem olarak uykuya yatırmak için enable_and_hlt fonksiyonunu kullanıyoruz. Kuyruk artık boş değilse, bu, run_ready_tasks döndükten sonra bir interrupt’ın bir görevi uyandırdığı anlamına gelir. Bu durumda, interrupt’ları tekrar etkinleştiriyor ve hlt yürütmeden doğrudan yürütmeye devam ediyoruz.
Artık executor’ımız, yapacak bir şey olmadığında CPU’yu düzgün bir şekilde uykuya yatırıyor. Kernel’imizi tekrar cargo run kullanarak çalıştırdığımızda, QEMU sürecinin çok daha düşük bir CPU kullanımına sahip olduğunu görebiliriz.
🔗Olası Genişletmeler
Executor’ımız artık görevleri verimli bir şekilde çalıştırabiliyor. Bekleyen görevleri poll etmekten kaçınmak için waker bildirimlerinden yararlanıyor ve şu anda yapacak iş olmadığında CPU’yu uykuya yatırıyor. Ancak, executor’ımız hâlâ oldukça temel ve işlevselliğini genişletmenin pek çok olası yolu var:
- Zamanlama (Scheduling):
task_queue’muz için şu anda, genellikle round robin zamanlaması olarak da adlandırılan bir ilk giren ilk çıkar (FIFO) stratejisini uygulamak içinVecDequetipini kullanıyoruz. Bu strateji tüm iş yükleri için en verimli olmayabilir. Örneğin, gecikmeye kritik görevlere veya çok fazla G/Ç yapan görevlere öncelik vermek mantıklı olabilir. Daha fazla bilgi için Operating Systems: Three Easy Pieces kitabının zamanlama bölümüne veya zamanlama hakkındaki Wikipedia makalesine bakın. - Görev Başlatma (Task Spawning):
Executor::spawnmetodumuz şu anda bir&mut selfreferansı gerektiriyor ve bu yüzdenrunmetodu çağrıldıktan sonra artık kullanılamaz. Bunu düzeltmek için, executor ile bir tür kuyruk paylaşan ve görevlerin kendi içlerinden görev oluşturmaya olanak tanıyan ek birSpawnertipi oluşturabilirdik. Kuyruk doğrudantask_queueolabilir veya executor’ın çalıştırma döngüsünde kontrol ettiği ayrı bir kuyruk olabilir. - Thread’lerden Yararlanma: Henüz thread desteğimiz yok, ancak bir sonraki yazıda ekleyeceğiz. Bu, executor’ın birden çok örneğini farklı thread’lerde başlatmayı mümkün kılacak. Bu yaklaşımın avantajı, diğer görevler eşzamanlı çalışabileceği için uzun süre çalışan görevlerin getirdiği gecikmenin azaltılabilmesidir. Bu yaklaşım ayrıca birden çok CPU çekirdeğinden yararlanmaya da olanak tanır.
- Yük Dengeleme (Load Balancing): Thread desteği eklerken, tüm CPU çekirdeklerinin kullanıldığından emin olmak için görevlerin executor’lar arasında nasıl dağıtılacağını bilmek önemli hale gelir. Bunun için yaygın bir teknik iş çalmadır (work stealing).
🔗Özet
Bu yazıya çoklu görevi tanıtarak ve çalışan görevleri düzenli olarak zorla kesen kesintili çoklu görev ile görevlerin CPU kontrolünü gönüllü olarak bırakana kadar çalışmasına izin veren işbirlikçi çoklu görev arasında ayrım yaparak başladık.
Ardından, Rust’ın async/await desteğinin işbirlikçi çoklu görevin dil seviyesinde bir uygulamasını nasıl sağladığını inceledik. Rust, uygulamasını, asenkron görevleri soyutlayan, yoklama tabanlı (polling-based) Future trait’inin üzerine kurar. Async/await kullanarak, future’larla neredeyse normal senkron kodla çalışır gibi çalışmak mümkündür. Fark, asenkron fonksiyonların yine bir Future döndürmesidir; bu da onu çalıştırmak için bir noktada bir executor’a eklenmesi gerekir.
Perde arkasında, derleyici async/await kodunu, her .await işlemi olası bir duraklama noktasına karşılık gelecek şekilde durum makinelerine dönüştürür. Program hakkındaki bilgisinden yararlanarak, derleyici her duraklama noktası için yalnızca minimum durumu kaydedebilir; bu da görev başına çok küçük bir bellek tüketimiyle sonuçlanır. Bir zorluk, üretilen durum makinelerinin, örneğin asenkron fonksiyonun yerel değişkenleri birbirine referans verdiğinde, kendine referans veren struct’lar içerebilmesidir. İşaretçi geçersizleşmesini önlemek için, Rust, future’ların ilk kez poll edildikten sonra artık bellekte taşınamamasını sağlamak amacıyla Pin tipini kullanır.
Uygulamamız için, önce Waker tipini hiç kullanmadan başlatılan tüm görevleri meşgul bir döngüde poll eden çok temel bir executor oluşturduk. Ardından, asenkron bir klavye görevi uygulayarak waker bildirimlerinin avantajını gösterdik. Görev, crossbeam crate’inin sağladığı mutex’siz ArrayQueue tipini kullanarak statik bir SCANCODE_QUEUE tanımlar. Tuş basışlarını doğrudan ele almak yerine, klavye interrupt handler’ı artık alınan tüm scancode’ları kuyruğa koyar ve ardından yeni girdinin mevcut olduğunu bildirmek için kayıtlı Waker’ı uyandırır. Alıcı uçta, kuyruktaki bir sonraki scancode’a çözümlenen bir Future sağlamak için bir ScancodeStream tipi oluşturduk. Bu, kuyruktaki scancode’ları yorumlamak ve yazdırmak için async/await kullanan asenkron bir print_keypresses görevi oluşturmayı mümkün kıldı.
Klavye görevinin waker bildirimlerinden yararlanmak için, hazır görevler için Arc ile paylaşılan bir task_queue kullanan yeni bir Executor tipi oluşturduk. Uyandırılan görevlerin ID’sini doğrudan bu task_queue’ya push’layan bir TaskWaker tipi uyguladık; bunlar daha sonra executor tarafından tekrar poll edilir. Hiçbir görev çalıştırılabilir olmadığında güç tasarrufu yapmak için, hlt komutunu kullanarak CPU’yu uykuya yatırma desteği ekledik. Son olarak, executor’ımıza yönelik bazı potansiyel genişletmeleri, örneğin çok çekirdekli desteği sağlamayı, tartıştık.
🔗Sırada Ne Var?
Async/await kullanarak, artık kernel’imizde işbirlikçi çoklu görev için temel desteğe sahibiz. İşbirlikçi çoklu görev çok verimli olsa da, tek tek görevler çok uzun süre çalışmaya devam ettiğinde ve böylece diğer görevlerin çalışmasını önlediğinde gecikme sorunlarına yol açar. Bu nedenle, kernel’imize kesintili çoklu görev için de destek eklemek mantıklıdır.
Bir sonraki yazıda, kesintili çoklu görevin en yaygın biçimi olarak thread’leri tanıtacağız. Uzun süre çalışan görevler sorununu çözmenin yanı sıra, thread’ler bizi gelecekte birden çok CPU çekirdeğinden yararlanmaya ve güvenilmeyen kullanıcı programları çalıştırmaya da hazırlayacak.
Yorumlar
Bir sorunuz mu var, geri bildirim paylaşmak veya fikirlerinizi tartışmak mı istiyorsunuz? Buraya yorum bırakmaktan çekinmeyin! Lütfen İngilizce kullanın ve Rust'ın davranış kurallarına uyun. Bu yorum dizisi doğrudan GitHub'daki bir tartışmaya bağlıdır, dolayısıyla isterseniz oraya da yorum yapabilirsiniz.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Mümkünse yorumlarınızı İngilizce bırakınız.