Double Faults
Conteúdo Traduzido: Esta é uma tradução comunitária do post Double Faults. Pode estar incompleta, desatualizada ou conter erros. Por favor, reporte qualquer problema!
Traduzido por @richarddalves.
Esta postagem explora a exceção de double fault em detalhes, que ocorre quando a CPU falha ao invocar um manipulador de exceção. Ao manipular esta exceção, evitamos triple faults fatais que causam uma redefinição do sistema. Para prevenir triple faults em todos os casos, também configuramos uma Interrupt Stack Table para capturar double faults em uma pilha de kernel separada.
Este blog é desenvolvido abertamente no GitHub. Se você tiver algum problema ou dúvida, abra um issue lá. Você também pode deixar comentários na parte inferior. O código-fonte completo desta publicação pode ser encontrado na branch post-06.
Tabela de Conteúdos
🔗O Que é um Double Fault?
Em termos simplificados, um double fault é uma exceção especial que ocorre quando a CPU falha ao invocar um manipulador de exceção. Por exemplo, ele ocorre quando um page fault é disparado mas não há manipulador de page fault registrado na Tabela de Descritores de Interrupção (IDT). Então é meio similar aos blocos catch-all em linguagens de programação com exceções, por exemplo, catch(...) em C++ ou catch(Exception e) em Java ou C#.
Um double fault se comporta como uma exceção normal. Ele tem o número de vetor 8 e podemos definir uma função manipuladora normal para ele na IDT. É realmente importante fornecer um manipulador de double fault, porque se um double fault não é manipulado, ocorre um triple fault fatal. Triple faults não podem ser capturados, e a maioria do hardware reage com uma redefinição do sistema.
🔗Disparando um Double Fault
Vamos provocar um double fault disparando uma exceção para a qual não definimos uma função manipuladora:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Olá Mundo{}", "!");
blog_os::init();
// dispara um page fault
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// como antes
#[cfg(test)]
test_main();
println!("Não crashou!");
loop {}
}
Usamos unsafe para escrever no endereço inválido 0xdeadbeef. O endereço virtual não está mapeado para um endereço físico nas tabelas de página, então ocorre um page fault. Não registramos um manipulador de page fault em nossa IDT, então ocorre um double fault.
Quando iniciamos nosso kernel agora, vemos que ele entra em um loop de boot infinito. A razão para o loop de boot é a seguinte:
- A CPU tenta escrever em
0xdeadbeef, o que causa um page fault. - A CPU olha para a entrada correspondente na IDT e vê que nenhuma função manipuladora está especificada. Assim, ela não pode chamar o manipulador de page fault e ocorre um double fault.
- A CPU olha para a entrada IDT do manipulador de double fault, mas esta entrada também não especifica uma função manipuladora. Assim, ocorre um triple fault.
- Um triple fault é fatal. QEMU reage a ele como a maioria do hardware real e emite uma redefinição do sistema.
Então, para prevenir este triple fault, precisamos fornecer uma função manipuladora para page faults ou um manipulador de double fault. Queremos evitar triple faults em todos os casos, então vamos começar com um manipulador de double fault que é invocado para todos os tipos de exceção não manipulados.
🔗Um Manipulador de Double Fault
Um double fault é uma exceção normal com um código de erro, então podemos especificar uma função manipuladora similar ao nosso manipulador de breakpoint:
// em src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // novo
idt
};
}
// novo
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEÇÃO: DOUBLE FAULT\n{:#?}", stack_frame);
}
Nosso manipulador imprime uma mensagem de erro curta e despeja o exception stack frame. O código de erro do manipulador de double fault é sempre zero, então não há razão para imprimi-lo. Uma diferença para o manipulador de breakpoint é que o manipulador de double fault é divergente. A razão é que a arquitetura x86_64 não permite retornar de uma exceção de double fault.
Quando iniciamos nosso kernel agora, devemos ver que o manipulador de double fault é invocado:
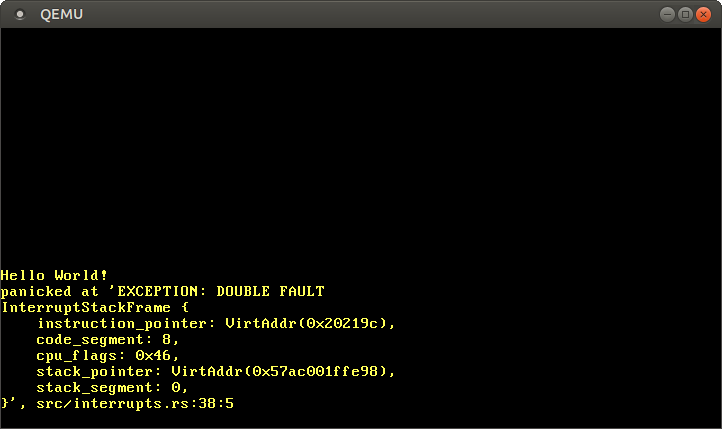
Funcionou! Aqui está o que aconteceu desta vez:
- A CPU tenta escrever em
0xdeadbeef, o que causa um page fault. - Como antes, a CPU olha para a entrada correspondente na IDT e vê que nenhuma função manipuladora está definida. Assim, ocorre um double fault.
- A CPU pula para o manipulador de double fault – agora presente.
O triple fault (e o loop de boot) não ocorre mais, já que a CPU agora pode chamar o manipulador de double fault.
Isso foi bem direto! Então por que precisamos de uma postagem inteira para este tópico? Bem, agora somos capazes de capturar a maioria dos double faults, mas há alguns casos onde nossa abordagem atual não é suficiente.
🔗Causas de Double Faults
Antes de olharmos para os casos especiais, precisamos conhecer as causas exatas de double faults. Acima, usamos uma definição bem vaga:
Um double fault é uma exceção especial que ocorre quando a CPU falha ao invocar um manipulador de exceção.
O que “falha ao invocar” significa exatamente? O manipulador não está presente? O manipulador está trocado para fora? E o que acontece se um manipulador causa exceções ele mesmo?
Por exemplo, o que acontece se:
- uma exceção de breakpoint ocorre, mas a função manipuladora correspondente está trocada para fora?
- um page fault ocorre, mas o manipulador de page fault está trocado para fora?
- um manipulador de divide-by-zero causa uma exceção de breakpoint, mas o manipulador de breakpoint está trocado para fora?
- nosso kernel estoura sua pilha e a guard page é atingida?
Felizmente, o manual AMD64 (PDF) tem uma definição exata (na Seção 8.2.9). De acordo com ele, uma “exceção de double fault pode ocorrer quando uma segunda exceção ocorre durante a manipulação de um manipulador de exceção anterior (primeira)”. O “pode” é importante: Apenas combinações muito específicas de exceções levam a um double fault. Essas combinações são:
Então, por exemplo, uma falha de divide-by-zero seguida de um page fault está ok (o manipulador de page fault é invocado), mas uma falha de divide-by-zero seguida de um general-protection fault leva a um double fault.
Com a ajuda desta tabela, podemos responder às primeiras três das questões acima:
- Se uma exceção de breakpoint ocorre e a função manipuladora correspondente está trocada para fora, ocorre um page fault e o manipulador de page fault é invocado.
- Se um page fault ocorre e o manipulador de page fault está trocado para fora, ocorre um double fault e o manipulador de double fault é invocado.
- Se um manipulador de divide-by-zero causa uma exceção de breakpoint, a CPU tenta invocar o manipulador de breakpoint. Se o manipulador de breakpoint está trocado para fora, ocorre um page fault e o manipulador de page fault é invocado.
De fato, até o caso de uma exceção sem função manipuladora na IDT segue este esquema: Quando a exceção ocorre, a CPU tenta ler a entrada IDT correspondente. Como a entrada é 0, que não é uma entrada IDT válida, ocorre um general protection fault. Não definimos uma função manipuladora para o general protection fault também, então outro general protection fault ocorre. De acordo com a tabela, isso leva a um double fault.
🔗Kernel Stack Overflow
Vamos olhar para a quarta questão:
O que acontece se nosso kernel estoura sua pilha e a guard page é atingida?
Uma guard page é uma página de memória especial na parte inferior de uma pilha que torna possível detectar estouros de pilha. A página não está mapeada para nenhum frame físico, então acessá-la causa um page fault em vez de silenciosamente corromper outra memória. O bootloader configura uma guard page para nossa pilha de kernel, então um stack overflow causa um page fault.
Quando um page fault ocorre, a CPU olha para o manipulador de page fault na IDT e tenta empurrar o interrupt stack frame na pilha. No entanto, o ponteiro de pilha atual ainda aponta para a guard page não presente. Assim, ocorre um segundo page fault, que causa um double fault (de acordo com a tabela acima).
Então a CPU tenta chamar o manipulador de double fault agora. No entanto, em um double fault, a CPU tenta empurrar o exception stack frame também. O ponteiro de pilha ainda aponta para a guard page, então ocorre um terceiro page fault, que causa um triple fault e uma reinicialização do sistema. Então nosso manipulador de double fault atual não pode evitar um triple fault neste caso.
Vamos tentar nós mesmos! Podemos facilmente provocar um kernel stack overflow chamando uma função que recursa infinitamente:
// em src/main.rs
#[unsafe(no_mangle)] // não altere (mangle) o nome desta função
pub extern "C" fn _start() -> ! {
println!("Olá Mundo{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // para cada recursão, o endereço de retorno é empurrado
}
// dispara um stack overflow
stack_overflow();
[…] // test_main(), println(…), e loop {}
}
Quando tentamos este código no QEMU, vemos que o sistema entra em um bootloop novamente.
Então como podemos evitar este problema? Não podemos omitir o empurrar do exception stack frame, já que a própria CPU faz isso. Então precisamos garantir de alguma forma que a pilha esteja sempre válida quando uma exceção de double fault ocorre. Felizmente, a arquitetura x86_64 tem uma solução para este problema.
🔗Trocando Pilhas
A arquitetura x86_64 é capaz de trocar para uma pilha predefinida e conhecida como boa quando uma exceção ocorre. Esta troca acontece em nível de hardware, então pode ser realizada antes que a CPU empurre o exception stack frame.
O mecanismo de troca é implementado como uma Interrupt Stack Table (IST). A IST é uma tabela de 7 ponteiros para pilhas conhecidas como boas. Em pseudocódigo similar a Rust:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}
Para cada manipulador de exceção, podemos escolher uma pilha da IST através do campo stack_pointers na entrada IDT correspondente. Por exemplo, nosso manipulador de double fault poderia usar a primeira pilha na IST. Então a CPU automaticamente troca para esta pilha sempre que ocorre um double fault. Esta troca aconteceria antes de qualquer coisa ser empurrada, prevenindo o triple fault.
🔗A IST e TSS
A Interrupt Stack Table (IST) é parte de uma antiga estrutura legada chamada Task State Segment (TSS). A TSS costumava armazenar várias informações (por exemplo, estado de registradores do processador) sobre uma tarefa no modo de 32 bits e era, por exemplo, usada para troca de contexto de hardware. No entanto, a troca de contexto de hardware não é mais suportada no modo de 64 bits e o formato da TSS mudou completamente.
No x86_64, a TSS não armazena mais nenhuma informação específica de tarefa. Em vez disso, ela armazena duas tabelas de pilha (a IST é uma delas). O único campo comum entre a TSS de 32 bits e 64 bits é o ponteiro para o bitmap de permissões de porta I/O.
A TSS de 64 bits tem o seguinte formato:
| Campo | Tipo |
|---|---|
| (reservado) | u32 |
| Privilege Stack Table | [u64; 3] |
| (reservado) | u64 |
| Interrupt Stack Table | [u64; 7] |
| (reservado) | u64 |
| (reservado) | u16 |
| I/O Map Base Address | u16 |
A Privilege Stack Table é usada pela CPU quando o nível de privilégio muda. Por exemplo, se uma exceção ocorre enquanto a CPU está em modo usuário (nível de privilégio 3), a CPU normalmente troca para o modo kernel (nível de privilégio 0) antes de invocar o manipulador de exceção. Nesse caso, a CPU trocaria para a 0ª pilha na Privilege Stack Table (já que 0 é o nível de privilégio alvo). Ainda não temos nenhum programa em modo usuário, então ignoraremos esta tabela por enquanto.
🔗Criando uma TSS
Vamos criar uma nova TSS que contém uma pilha de double fault separada em sua interrupt stack table. Para isso, precisamos de uma struct TSS. Felizmente, a crate x86_64 já contém uma struct TaskStateSegment que podemos usar.
Criamos a TSS em um novo módulo gdt (o nome fará sentido mais tarde):
// em src/lib.rs
pub mod gdt;
// em src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(&raw const STACK);
let stack_end = stack_start + STACK_SIZE;
stack_end
};
tss
};
}
Usamos lazy_static porque o avaliador const de Rust ainda não é poderoso o suficiente para fazer esta inicialização em tempo de compilação. Definimos que a 0ª entrada IST é a pilha de double fault (qualquer outro índice IST funcionaria também). Então escrevemos o endereço superior de uma pilha de double fault na 0ª entrada. Escrevemos o endereço superior porque pilhas no x86 crescem para baixo, isto é, de endereços altos para endereços baixos.
Ainda não implementamos gerenciamento de memória, então não temos uma forma apropriada de alocar uma nova pilha. Em vez disso, usamos um array static mut como armazenamento de pilha por enquanto. É importante que seja uma static mut e não uma static imutável, porque caso contrário o bootloader a mapearia para uma página somente leitura. Substituiremos isto por uma alocação de pilha apropriada em uma postagem posterior.
Note que esta pilha de double fault não tem guard page que proteja contra stack overflow. Isso significa que não devemos fazer nada intensivo em pilha em nosso manipulador de double fault porque um stack overflow poderia corromper a memória abaixo da pilha.
🔗Carregando a TSS
Agora que criamos uma nova TSS, precisamos de uma forma de dizer à CPU que ela deve usá-la. Infelizmente, isto é um pouco trabalhoso, já que a TSS usa o sistema de segmentação (por razões históricas). Em vez de carregar a tabela diretamente, precisamos adicionar um novo descritor de segmento à Tabela de Descritores Globais (GDT). Então podemos carregar nossa TSS invocando a instrução ltr com o respectivo índice GDT. (Esta é a razão pela qual nomeamos nosso módulo gdt.)
🔗A Tabela de Descritores Globais
A Tabela de Descritores Globais (GDT - Global Descriptor Table) é uma relíquia que foi usada para segmentação de memória antes de paginação se tornar o padrão de fato. No entanto, ela ainda é necessária no modo de 64 bits para várias coisas, como configuração de modo kernel/usuário ou carregamento de TSS.
A GDT é uma estrutura que contém os segmentos do programa. Ela foi usada em arquiteturas mais antigas para isolar programas uns dos outros antes de paginação se tornar o padrão. Para mais informações sobre segmentação, confira o capítulo de mesmo nome do livro gratuito “Three Easy Pieces”. Embora a segmentação não seja mais suportada no modo de 64 bits, a GDT ainda existe. Ela é usada principalmente para duas coisas: Trocar entre espaço de kernel e espaço de usuário, e carregar uma estrutura TSS.
🔗Criando uma GDT
Vamos criar uma GDT estática que inclui um segmento para nossa TSS estática:
// em src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.add_entry(Descriptor::kernel_code_segment());
gdt.add_entry(Descriptor::tss_segment(&TSS));
gdt
};
}
Como antes, usamos lazy_static novamente. Criamos uma nova GDT com um segmento de código e um segmento TSS.
🔗Carregando a GDT
Para carregar nossa GDT, criamos uma nova função gdt::init que chamamos de nossa função init:
// em src/gdt.rs
pub fn init() {
GDT.load();
}
// em src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}
Agora nossa GDT está carregada (já que a função _start chama init), mas ainda vemos o loop de boot no stack overflow.
🔗Os Passos Finais
O problema é que os segmentos GDT ainda não estão ativos porque os registradores de segmento e TSS ainda contêm os valores da GDT antiga. Também precisamos modificar a entrada IDT de double fault para que ela use a nova pilha.
Em resumo, precisamos fazer o seguinte:
- Recarregar registrador de segmento de código: Mudamos nossa GDT, então devemos recarregar
cs, o registrador de segmento de código. Isso é necessário já que o antigo seletor de segmento poderia agora apontar para um descritor GDT diferente (por exemplo, um descritor TSS). - Carregar a TSS: Carregamos uma GDT que contém um seletor TSS, mas ainda precisamos dizer à CPU que ela deve usar essa TSS.
- Atualizar a entrada IDT: Assim que nossa TSS é carregada, a CPU tem acesso a uma interrupt stack table (IST) válida. Então podemos dizer à CPU que ela deve usar nossa nova pilha de double fault modificando nossa entrada IDT de double fault.
Para os dois primeiros passos, precisamos de acesso às variáveis code_selector e tss_selector em nossa função gdt::init. Podemos conseguir isso tornando-as parte da static através de uma nova struct Selectors:
// em src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}
Agora podemos usar os seletores para recarregar o registrador cs e carregar nossa TSS:
// em src/gdt.rs
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}
Recarregamos o registrador de segmento de código usando CS::set_reg e carregamos a TSS usando load_tss. As funções são marcadas como unsafe, então precisamos de um bloco unsafe para invocá-las. A razão é que pode ser possível quebrar a segurança de memória carregando seletores inválidos.
Agora que carregamos uma TSS e interrupt stack table válidas, podemos definir o índice de pilha para nosso manipulador de double fault na IDT:
// em src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // novo
}
idt
};
}
O método set_stack_index é unsafe porque o chamador deve garantir que o índice usado é válido e não está já usado para outra exceção.
É isso! Agora a CPU deve trocar para a pilha de double fault sempre que ocorre um double fault. Assim, somos capazes de capturar todos os double faults, incluindo kernel stack overflows:
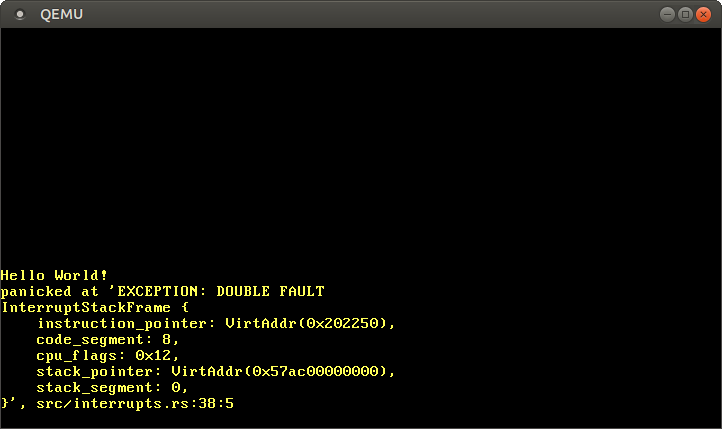
De agora em diante, nunca devemos ver um triple fault novamente! Para garantir que não quebramos acidentalmente o acima, devemos adicionar um teste para isso.
🔗Um Teste de Stack Overflow
Para testar nosso novo módulo gdt e garantir que o manipulador de double fault é corretamente chamado em um stack overflow, podemos adicionar um teste de integração. A ideia é provocar um double fault na função de teste e verificar que o manipulador de double fault é chamado.
Vamos começar com um esqueleto mínimo:
// em tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
Como nosso teste panic_handler, o teste executará sem um test harness. A razão é que não podemos continuar a execução após um double fault, então mais de um teste não faz sentido. Para desativar o test harness para o teste, adicionamos o seguinte ao nosso Cargo.toml:
# em Cargo.toml
[[test]]
name = "stack_overflow"
harness = false
Agora cargo test --test stack_overflow deve compilar com sucesso. O teste falha, é claro, já que a macro unimplemented entra em panic.
🔗Implementando _start
A implementação da função _start se parece com isto:
// em tests/stack_overflow.rs
use blog_os::serial_print;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// dispara um stack overflow
stack_overflow();
panic!("Execução continuou após stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // para cada recursão, o endereço de retorno é empurrado
volatile::Volatile::new(0).read(); // previne otimizações de tail recursion
}
Chamamos nossa função gdt::init para inicializar uma nova GDT. Em vez de chamar nossa função interrupts::init_idt, chamamos uma função init_test_idt que será explicada em um momento. A razão é que queremos registrar um manipulador de double fault customizado que faz um exit_qemu(QemuExitCode::Success) em vez de entrar em panic.
A função stack_overflow é quase idêntica à função em nosso main.rs. A única diferença é que no final da função, realizamos uma leitura volátil adicional usando o tipo Volatile para prevenir uma otimização do compilador chamada tail call elimination. Entre outras coisas, esta otimização permite ao compilador transformar uma função cuja última instrução é uma chamada de função recursiva em um loop normal. Assim, nenhum stack frame adicional é criado para a chamada de função, então o uso de pilha permanece constante.
No nosso caso, no entanto, queremos que o stack overflow aconteça, então adicionamos uma instrução de leitura volátil fictícia no final da função, que o compilador não tem permissão para remover. Assim, a função não é mais tail recursive, e a transformação em um loop é prevenida. Também adicionamos o atributo allow(unconditional_recursion) para silenciar o aviso do compilador de que a função recursa infinitamente.
🔗A IDT de Teste
Como notado acima, o teste precisa de sua própria IDT com um manipulador de double fault customizado. A implementação se parece com isto:
// em tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}
A implementação é muito similar à nossa IDT normal em interrupts.rs. Como na IDT normal, definimos um índice de pilha na IST para o manipulador de double fault para trocar para uma pilha separada. A função init_test_idt carrega a IDT na CPU através do método load.
🔗O Manipulador de Double Fault
A única peça que falta é nosso manipulador de double fault. Ele se parece com isto:
// em tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
Quando o manipulador de double fault é chamado, saímos do QEMU com um código de saída de sucesso, o que marca o teste como aprovado. Como testes de integração são executáveis completamente separados, precisamos definir o atributo #![feature(abi_x86_interrupt)] novamente no topo do nosso arquivo de teste.
Agora podemos executar nosso teste através de cargo test --test stack_overflow (ou cargo test para executar todos os testes). Como esperado, vemos a saída stack_overflow... [ok] no console. Tente comentar a linha set_stack_index; isso deve fazer o teste falhar.
🔗Resumo
Nesta postagem, aprendemos o que é um double fault e sob quais condições ele ocorre. Adicionamos um manipulador de double fault básico que imprime uma mensagem de erro e adicionamos um teste de integração para ele.
Também habilitamos a troca de pilha suportada por hardware em exceções de double fault para que também funcione em stack overflow. Enquanto implementávamos isso, aprendemos sobre o segmento de estado de tarefa (TSS), a interrupt stack table (IST) contida nele, e a tabela de descritores globais (GDT), que foi usada para segmentação em arquiteturas mais antigas.
🔗O Que Vem a Seguir?
A próxima postagem explica como manipular interrupções de dispositivos externos como temporizadores, teclados ou controladores de rede. Essas interrupções de hardware são muito similares a exceções, por exemplo, elas também são despachadas através da IDT. No entanto, ao contrário de exceções, elas não surgem diretamente na CPU. Em vez disso, um controlador de interrupção agrega essas interrupções e as encaminha para a CPU dependendo de sua prioridade. Na próxima postagem, exploraremos o controlador de interrupções Intel 8259 (“PIC”) e aprenderemos como implementar suporte a teclado.
Comentários
Teve algum problema, quer deixar um feedback ou discutir mais ideias? Fique à vontade para deixar um comentário aqui! Por favor, use o inglês e siga o código de conduta do Rust. Este tópico de comentários está diretamente vinculado a uma discussão no GitHub, então você também pode comentar lá se preferir.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor, deixe seus comentários em inglês se possível.