Exceções de CPU
Conteúdo Traduzido: Esta é uma tradução comunitária do post CPU Exceptions. Pode estar incompleta, desatualizada ou conter erros. Por favor, reporte qualquer problema!
Traduzido por @richarddalves.
Exceções de CPU ocorrem em várias situações errôneas, por exemplo, ao acessar um endereço de memória inválido ou ao dividir por zero. Para reagir a elas, precisamos configurar uma tabela de descritores de interrupção que fornece funções manipuladoras. Ao final desta postagem, nosso kernel será capaz de capturar exceções de breakpoint e retomar a execução normal posteriormente.
Este blog é desenvolvido abertamente no GitHub. Se você tiver algum problema ou dúvida, abra um issue lá. Você também pode deixar comentários na parte inferior. O código-fonte completo desta publicação pode ser encontrado na branch post-05.
Tabela de Conteúdos
🔗Visão Geral
Uma exceção sinaliza que algo está errado com a instrução atual. Por exemplo, a CPU emite uma exceção se a instrução atual tenta dividir por 0. Quando uma exceção ocorre, a CPU interrompe seu trabalho atual e imediatamente chama uma função manipuladora de exceção específica, dependendo do tipo de exceção.
No x86, existem cerca de 20 tipos diferentes de exceções de CPU. As mais importantes são:
- Page Fault: Um page fault ocorre em acessos ilegais à memória. Por exemplo, se a instrução atual tenta ler de uma página não mapeada ou tenta escrever em uma página somente leitura.
- Invalid Opcode: Esta exceção ocorre quando a instrução atual é inválida, por exemplo, quando tentamos usar novas instruções SSE em uma CPU antiga que não as suporta.
- General Protection Fault: Esta é a exceção com a gama mais ampla de causas. Ela ocorre em vários tipos de violações de acesso, como tentar executar uma instrução privilegiada em código de nível de usuário ou escrever em campos reservados de registradores de configuração.
- Double Fault: Quando uma exceção ocorre, a CPU tenta chamar a função manipuladora correspondente. Se outra exceção ocorre enquanto chama o manipulador de exceção, a CPU levanta uma exceção de double fault. Esta exceção também ocorre quando não há função manipuladora registrada para uma exceção.
- Triple Fault: Se uma exceção ocorre enquanto a CPU tenta chamar a função manipuladora de double fault, ela emite um triple fault fatal. Não podemos capturar ou manipular um triple fault. A maioria dos processadores reage redefinindo-se e reinicializando o sistema operacional.
Para a lista completa de exceções, consulte a wiki do OSDev.
🔗A Tabela de Descritores de Interrupção
Para capturar e manipular exceções, precisamos configurar uma chamada Tabela de Descritores de Interrupção (IDT - Interrupt Descriptor Table). Nesta tabela, podemos especificar uma função manipuladora para cada exceção de CPU. O hardware usa esta tabela diretamente, então precisamos seguir um formato predefinido. Cada entrada deve ter a seguinte estrutura de 16 bytes:
| Tipo | Nome | Descrição |
|---|---|---|
| u16 | Function Pointer [0:15] | Os bits inferiores do ponteiro para a função manipuladora. |
| u16 | GDT selector | Seletor de um segmento de código na tabela de descritores globais. |
| u16 | Options | (veja abaixo) |
| u16 | Function Pointer [16:31] | Os bits do meio do ponteiro para a função manipuladora. |
| u32 | Function Pointer [32:63] | Os bits restantes do ponteiro para a função manipuladora. |
| u32 | Reserved |
O campo options tem o seguinte formato:
| Bits | Nome | Descrição |
|---|---|---|
| 0-2 | Interrupt Stack Table Index | 0: Não troca stacks, 1-7: Troca para a n-ésima stack na Interrupt Stack Table quando este manipulador é chamado. |
| 3-7 | Reserved | |
| 8 | 0: Interrupt Gate, 1: Trap Gate | Se este bit é 0, as interrupções são desativadas quando este manipulador é chamado. |
| 9-11 | must be one | |
| 12 | must be zero | |
| 13‑14 | Descriptor Privilege Level (DPL) | O nível mínimo de privilégio necessário para chamar este manipulador. |
| 15 | Present |
Cada exceção tem um índice predefinido na IDT. Por exemplo, a exceção invalid opcode tem índice de tabela 6 e a exceção page fault tem índice de tabela 14. Assim, o hardware pode automaticamente carregar a entrada IDT correspondente para cada exceção. A Tabela de Exceções na wiki do OSDev mostra os índices IDT de todas as exceções na coluna “Vector nr.”.
Quando uma exceção ocorre, a CPU aproximadamente faz o seguinte:
- Empurra alguns registradores na pilha, incluindo o ponteiro de instrução e o registrador RFLAGS. (Usaremos esses valores mais tarde nesta postagem.)
- Lê a entrada correspondente da Tabela de Descritores de Interrupção (IDT). Por exemplo, a CPU lê a 14ª entrada quando ocorre um page fault.
- Verifica se a entrada está presente e, se não estiver, levanta um double fault.
- Desativa interrupções de hardware se a entrada é um interrupt gate (bit 40 não está definido).
- Carrega o seletor GDT especificado no CS (segmento de código).
- Pula para a função manipuladora especificada.
Não se preocupe com os passos 4 e 5 por enquanto; aprenderemos sobre a tabela de descritores globais e interrupções de hardware em postagens futuras.
🔗Um Tipo IDT
Em vez de criar nosso próprio tipo IDT, usaremos a struct InterruptDescriptorTable da crate x86_64, que se parece com isto:
#[repr(C)]
pub struct InterruptDescriptorTable {
pub divide_by_zero: Entry<HandlerFunc>,
pub debug: Entry<HandlerFunc>,
pub non_maskable_interrupt: Entry<HandlerFunc>,
pub breakpoint: Entry<HandlerFunc>,
pub overflow: Entry<HandlerFunc>,
pub bound_range_exceeded: Entry<HandlerFunc>,
pub invalid_opcode: Entry<HandlerFunc>,
pub device_not_available: Entry<HandlerFunc>,
pub double_fault: Entry<HandlerFuncWithErrCode>,
pub invalid_tss: Entry<HandlerFuncWithErrCode>,
pub segment_not_present: Entry<HandlerFuncWithErrCode>,
pub stack_segment_fault: Entry<HandlerFuncWithErrCode>,
pub general_protection_fault: Entry<HandlerFuncWithErrCode>,
pub page_fault: Entry<PageFaultHandlerFunc>,
pub x87_floating_point: Entry<HandlerFunc>,
pub alignment_check: Entry<HandlerFuncWithErrCode>,
pub machine_check: Entry<HandlerFunc>,
pub simd_floating_point: Entry<HandlerFunc>,
pub virtualization: Entry<HandlerFunc>,
pub security_exception: Entry<HandlerFuncWithErrCode>,
// alguns campos omitidos
}
Os campos têm o tipo idt::Entry<F>, que é uma struct que representa os campos de uma entrada IDT (veja a tabela acima). O parâmetro de tipo F define o tipo de função manipuladora esperado. Vemos que algumas entradas requerem uma HandlerFunc e algumas entradas requerem uma HandlerFuncWithErrCode. O page fault tem até seu próprio tipo especial: PageFaultHandlerFunc.
Vamos olhar primeiro para o tipo HandlerFunc:
type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
É um type alias para um tipo extern "x86-interrupt" fn. A palavra-chave extern define uma função com uma convenção de chamada estrangeira e é frequentemente usada para se comunicar com código C (extern "C" fn). Mas o que é a convenção de chamada x86-interrupt?
🔗A Convenção de Chamada de Interrupção
Exceções são bastante similares a chamadas de função: A CPU pula para a primeira instrução da função chamada e a executa. Depois, a CPU pula para o endereço de retorno e continua a execução da função pai.
No entanto, há uma diferença importante entre exceções e chamadas de função: Uma chamada de função é invocada voluntariamente por uma instrução call inserida pelo compilador, enquanto uma exceção pode ocorrer em qualquer instrução. Para entender as consequências desta diferença, precisamos examinar as chamadas de função em mais detalhes.
Convenções de chamada especificam os detalhes de uma chamada de função. Por exemplo, elas especificam onde os parâmetros da função são colocados (por exemplo, em registradores ou na pilha) e como os resultados são retornados. No x86_64 Linux, as seguintes regras se aplicam para funções C (especificadas no System V ABI):
- os primeiros seis argumentos inteiros são passados nos registradores
rdi,rsi,rdx,rcx,r8,r9 - argumentos adicionais são passados na pilha
- resultados são retornados em
raxerdx
Note que Rust não segue a ABI do C (na verdade, nem existe uma ABI Rust ainda), então essas regras se aplicam apenas a funções declaradas como extern "C" fn.
🔗Registradores Preservados e Scratch
A convenção de chamada divide os registradores em duas partes: registradores preservados e scratch.
Os valores dos registradores preservados devem permanecer inalterados entre chamadas de função. Portanto, uma função chamada (a “callee”) só tem permissão para sobrescrever esses registradores se restaurar seus valores originais antes de retornar. Portanto, esses registradores são chamados de “callee-saved”. Um padrão comum é salvar esses registradores na pilha no início da função e restaurá-los logo antes de retornar.
Em contraste, uma função chamada tem permissão para sobrescrever registradores scratch sem restrições. Se o chamador quiser preservar o valor de um registrador scratch entre uma chamada de função, ele precisa fazer backup e restaurá-lo antes da chamada de função (por exemplo, empurrando-o para a pilha). Portanto, os registradores scratch são caller-saved.
No x86_64, a convenção de chamada C especifica os seguintes registradores preservados e scratch:
| registradores preservados | registradores scratch |
|---|---|
rbp, rbx, rsp, r12, r13, r14, r15 | rax, rcx, rdx, rsi, rdi, r8, r9, r10, r11 |
| callee-saved | caller-saved |
O compilador conhece essas regras, então gera o código de acordo. Por exemplo, a maioria das funções começa com um push rbp, que faz backup de rbp na pilha (porque é um registrador callee-saved).
🔗Preservando Todos os Registradores
Em contraste com chamadas de função, exceções podem ocorrer em qualquer instrução. Na maioria dos casos, não sabemos nem em tempo de compilação se o código gerado causará uma exceção. Por exemplo, o compilador não pode saber se uma instrução causa um stack overflow ou um page fault.
Como não sabemos quando uma exceção ocorre, não podemos fazer backup de nenhum registrador antes. Isso significa que não podemos usar uma convenção de chamada que depende de registradores caller-saved para manipuladores de exceção. Em vez disso, precisamos de uma convenção de chamada que preserva todos os registradores. A convenção de chamada x86-interrupt é tal convenção de chamada, então garante que todos os valores de registrador são restaurados para seus valores originais no retorno da função.
Note que isso não significa que todos os registradores são salvos na pilha na entrada da função. Em vez disso, o compilador apenas faz backup dos registradores que são sobrescritos pela função. Desta forma, código muito eficiente pode ser gerado para funções curtas que usam apenas alguns registradores.
🔗O Stack Frame de Interrupção
Em uma chamada de função normal (usando a instrução call), a CPU empurra o endereço de retorno antes de pular para a função alvo. No retorno da função (usando a instrução ret), a CPU retira este endereço de retorno e pula para ele. Então o stack frame de uma chamada de função normal se parece com isto:

Para manipuladores de exceção e interrupção, no entanto, empurrar um endereço de retorno não seria suficiente, já que manipuladores de interrupção frequentemente executam em um contexto diferente (ponteiro de pilha, flags da CPU, etc.). Em vez disso, a CPU executa os seguintes passos quando uma interrupção ocorre:
- Salvando o antigo ponteiro de pilha: A CPU lê os valores dos registradores ponteiro de pilha (
rsp) e segmento de pilha (ss) e os lembra em um buffer interno. - Alinhando o ponteiro de pilha: Uma interrupção pode ocorrer em qualquer instrução, então o ponteiro de pilha pode ter qualquer valor também. No entanto, algumas instruções de CPU (por exemplo, algumas instruções SSE) requerem que o ponteiro de pilha esteja alinhado em um limite de 16 bytes, então a CPU realiza tal alinhamento logo após a interrupção.
- Trocando pilhas (em alguns casos): Uma troca de pilha ocorre quando o nível de privilégio da CPU muda, por exemplo, quando uma exceção de CPU ocorre em um programa em modo usuário. Também é possível configurar trocas de pilha para interrupções específicas usando a chamada Interrupt Stack Table (descrita na próxima postagem).
- Empurrando o antigo ponteiro de pilha: A CPU empurra os valores
rspessdo passo 0 para a pilha. Isso torna possível restaurar o ponteiro de pilha original ao retornar de um manipulador de interrupção. - Empurrando e atualizando o registrador
RFLAGS: O registradorRFLAGScontém vários bits de controle e status. Na entrada de interrupção, a CPU muda alguns bits e empurra o valor antigo. - Empurrando o ponteiro de instrução: Antes de pular para a função manipuladora de interrupção, a CPU empurra o ponteiro de instrução (
rip) e o segmento de código (cs). Isso é comparável ao push de endereço de retorno de uma chamada de função normal. - Empurrando um código de erro (para algumas exceções): Para algumas exceções específicas, como page faults, a CPU empurra um código de erro, que descreve a causa da exceção.
- Invocando o manipulador de interrupção: A CPU lê o endereço e o descritor de segmento da função manipuladora de interrupção do campo correspondente na IDT. Ela então invoca este manipulador carregando os valores nos registradores
ripecs.
Então o interrupt stack frame se parece com isto:

Na crate x86_64, o interrupt stack frame é representado pela struct InterruptStackFrame. Ela é passada para manipuladores de interrupção como &mut e pode ser usada para recuperar informações adicionais sobre a causa da exceção. A struct não contém campo de código de erro, já que apenas algumas exceções empurram um código de erro. Essas exceções usam o tipo de função HandlerFuncWithErrCode separado, que tem um argumento adicional error_code.
🔗Por Trás das Cortinas
A convenção de chamada x86-interrupt é uma abstração poderosa que esconde quase todos os detalhes confusos do processo de manipulação de exceção. No entanto, às vezes é útil saber o que está acontecendo por trás das cortinas. Aqui está uma breve visão geral das coisas das quais a convenção de chamada x86-interrupt cuida:
- Recuperando os argumentos: A maioria das convenções de chamada espera que os argumentos sejam passados em registradores. Isso não é possível para manipuladores de exceção, já que não devemos sobrescrever nenhum valor de registrador antes de fazer backup deles na pilha. Em vez disso, a convenção de chamada
x86-interruptestá ciente de que os argumentos já estão na pilha em um deslocamento específico. - Retornando usando
iretq: Como o interrupt stack frame difere completamente dos stack frames de chamadas de função normais, não podemos retornar de funções manipuladoras através da instruçãoretnormal. Então, em vez disso, a instruçãoiretqdeve ser usada. - Manipulando o código de erro: O código de erro, que é empurrado para algumas exceções, torna as coisas muito mais complexas. Ele muda o alinhamento da pilha (veja o próximo ponto) e precisa ser retirado da pilha antes de retornar. A convenção de chamada
x86-interruptmanipula toda essa complexidade. No entanto, ela não sabe qual função manipuladora é usada para qual exceção, então precisa deduzir essa informação do número de argumentos da função. Isso significa que o programador ainda é responsável por usar o tipo de função correto para cada exceção. Felizmente, o tipoInterruptDescriptorTabledefinido pela cratex86_64garante que os tipos de função corretos são usados. - Alinhando a pilha: Algumas instruções (especialmente instruções SSE) requerem um alinhamento de pilha de 16 bytes. A CPU garante esse alinhamento sempre que uma exceção ocorre, mas para algumas exceções ela o destrói novamente mais tarde quando empurra um código de erro. A convenção de chamada
x86-interruptcuida disso realinhando a pilha neste caso.
Se você estiver interessado em mais detalhes, também temos uma série de postagens que explica a manipulação de exceção usando funções nuas vinculadas no final desta postagem.
🔗Implementação
Agora que entendemos a teoria, é hora de manipular exceções de CPU em nosso kernel. Começaremos criando um novo módulo interrupts em src/interrupts.rs, que primeiro cria uma função init_idt que cria uma nova InterruptDescriptorTable:
// em src/lib.rs
pub mod interrupts;
// em src/interrupts.rs
use x86_64::structures::idt::InterruptDescriptorTable;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
}
Agora podemos adicionar funções manipuladoras. Começamos adicionando um manipulador para a exceção de breakpoint. A exceção de breakpoint é a exceção perfeita para testar a manipulação de exceção. Seu único propósito é pausar temporariamente um programa quando a instrução de breakpoint int3 é executada.
A exceção de breakpoint é comumente usada em debuggers: Quando o usuário define um breakpoint, o debugger sobrescreve a instrução correspondente com a instrução int3 para que a CPU lance a exceção de breakpoint quando atinge aquela linha. Quando o usuário quer continuar o programa, o debugger substitui a instrução int3 pela instrução original novamente e continua o programa. Para mais detalhes, veja a série “How debuggers work”.
Para nosso caso de uso, não precisamos sobrescrever nenhuma instrução. Em vez disso, queremos apenas imprimir uma mensagem quando a instrução de breakpoint é executada e então continuar o programa. Então vamos criar uma função breakpoint_handler simples e adicioná-la à nossa IDT:
// em src/interrupts.rs
use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
use crate::println;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
}
extern "x86-interrupt" fn breakpoint_handler(
stack_frame: InterruptStackFrame)
{
println!("EXCEÇÃO: BREAKPOINT\n{:#?}", stack_frame);
}
Nosso manipulador apenas produz uma mensagem e imprime de forma bonita o interrupt stack frame.
Quando tentamos compilá-lo, o seguinte erro ocorre:
error[E0658]: x86-interrupt ABI is experimental and subject to change (see issue #40180)
--> src/main.rs:53:1
|
53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
54 | | println!("EXCEÇÃO: BREAKPOINT\n{:#?}", stack_frame);
55 | | }
| |_^
|
= help: add #![feature(abi_x86_interrupt)] to the crate attributes to enable
Este erro ocorre porque a convenção de chamada x86-interrupt ainda é instável. Para usá-la de qualquer forma, temos que habilitá-la explicitamente adicionando #![feature(abi_x86_interrupt)] no topo do nosso lib.rs.
🔗Carregando a IDT
Para que a CPU use nossa nova tabela de descritores de interrupção, precisamos carregá-la usando a instrução lidt. A struct InterruptDescriptorTable da crate x86_64 fornece um método load para isso. Vamos tentar usá-lo:
// em src/interrupts.rs
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.load();
}
Quando tentamos compilar agora, o seguinte erro ocorre:
error: `idt` does not live long enough
--> src/interrupts/mod.rs:43:5
|
43 | idt.load();
| ^^^ does not live long enough
44 | }
| - borrowed value only lives until here
|
= note: borrowed value must be valid for the static lifetime...
Então o método load espera um &'static self, isto é, uma referência válida para o tempo de execução completo do programa. A razão é que a CPU acessará esta tabela em cada interrupção até carregarmos uma IDT diferente. Então usar um tempo de vida menor que 'static poderia levar a bugs de use-after-free.
De fato, isso é exatamente o que acontece aqui. Nossa idt é criada na pilha, então ela é válida apenas dentro da função init. Depois, a memória da pilha é reutilizada para outras funções, então a CPU interpretaria memória aleatória da pilha como IDT. Felizmente, o método InterruptDescriptorTable::load codifica este requisito de tempo de vida em sua definição de função, para que o compilador Rust seja capaz de prevenir este possível bug em tempo de compilação.
Para corrigir este problema, precisamos armazenar nossa idt em um lugar onde ela tenha um tempo de vida 'static. Para conseguir isso, poderíamos alocar nossa IDT no heap usando Box e então convertê-la para uma referência 'static, mas estamos escrevendo um kernel de SO e, portanto, não temos um heap (ainda).
Como alternativa, poderíamos tentar armazenar a IDT como uma static:
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
No entanto, há um problema: Statics são imutáveis, então não podemos modificar a entrada de breakpoint da nossa função init. Poderíamos resolver este problema usando uma static mut:
static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
unsafe {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
}
Esta variante compila sem erros, mas está longe de ser idiomática. static muts são muito propensas a data races, então precisamos de um bloco unsafe em cada acesso.
🔗Lazy Statics ao Resgate
Felizmente, a macro lazy_static existe. Em vez de avaliar uma static em tempo de compilação, a macro realiza a inicialização quando a static é referenciada pela primeira vez. Assim, podemos fazer quase tudo no bloco de inicialização e somos até capazes de ler valores de tempo de execução.
Já importamos a crate lazy_static quando criamos uma abstração para o buffer de texto VGA. Então podemos usar diretamente a macro lazy_static! para criar nossa IDT estática:
// em src/interrupts.rs
use lazy_static::lazy_static;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt
};
}
pub fn init_idt() {
IDT.load();
}
Note como esta solução não requer blocos unsafe. A macro lazy_static! usa unsafe por trás dos panos, mas é abstraída em uma interface segura.
🔗Executando
O último passo para fazer exceções funcionarem em nosso kernel é chamar a função init_idt do nosso main.rs. Em vez de chamá-la diretamente, introduzimos uma função geral init em nosso lib.rs:
// em src/lib.rs
pub fn init() {
interrupts::init_idt();
}
Com esta função, agora temos um lugar central para rotinas de inicialização que podem ser compartilhadas entre as diferentes funções _start em nosso main.rs, lib.rs e testes de integração.
Agora podemos atualizar a função _start do nosso main.rs para chamar init e então disparar uma exceção de breakpoint:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Olá Mundo{}", "!");
blog_os::init(); // novo
// invoca uma exceção de breakpoint
x86_64::instructions::interrupts::int3(); // novo
// como antes
#[cfg(test)]
test_main();
println!("Não crashou!");
loop {}
}
Quando executamos agora no QEMU (usando cargo run), vemos o seguinte:
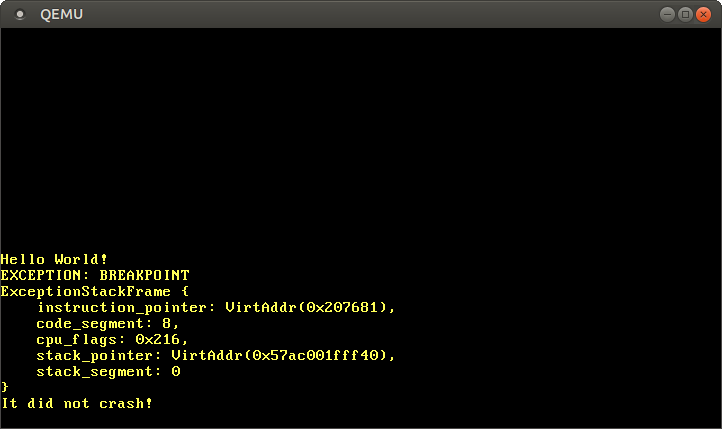
Funciona! A CPU invoca com sucesso nosso manipulador de breakpoint, que imprime a mensagem, e então retorna de volta para a função _start, onde a mensagem Não crashou! é impressa.
Vemos que o interrupt stack frame nos diz os ponteiros de instrução e pilha no momento em que a exceção ocorreu. Esta informação é muito útil ao depurar exceções inesperadas.
🔗Adicionando um Teste
Vamos criar um teste que garante que o acima continue funcionando. Primeiro, atualizamos a função _start para também chamar init:
// em src/lib.rs
/// Ponto de entrada para `cargo test`
#[cfg(test)]
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
init(); // novo
test_main();
loop {}
}
Lembre-se, esta função _start é usada quando executamos cargo test --lib, já que Rust testa o lib.rs completamente independente do main.rs. Precisamos chamar init aqui para configurar uma IDT antes de executar os testes.
Agora podemos criar um teste test_breakpoint_exception:
// em src/interrupts.rs
#[test_case]
fn test_breakpoint_exception() {
// invoca uma exceção de breakpoint
x86_64::instructions::interrupts::int3();
}
O teste invoca a função int3 para disparar uma exceção de breakpoint. Ao verificar que a execução continua depois, verificamos que nosso manipulador de breakpoint está funcionando corretamente.
Você pode tentar este novo teste executando cargo test (todos os testes) ou cargo test --lib (apenas testes de lib.rs e seus módulos). Você deve ver o seguinte na saída:
blog_os::interrupts::test_breakpoint_exception... [ok]
🔗Muita Mágica?
A convenção de chamada x86-interrupt e o tipo InterruptDescriptorTable tornaram o processo de manipulação de exceção relativamente simples e indolor. Se isso foi muita mágica para você e você gostaria de aprender todos os detalhes sórdidos da manipulação de exceção, nós temos você coberto: Nossa série “Manipulando Exceções com Funções Nuas” mostra como manipular exceções sem a convenção de chamada x86-interrupt e também cria seu próprio tipo IDT. Historicamente, essas postagens eram as principais postagens de manipulação de exceção antes que a convenção de chamada x86-interrupt e a crate x86_64 existissem. Note que essas postagens são baseadas na primeira edição deste blog e podem estar desatualizadas.
🔗O Que Vem a Seguir?
Capturamos com sucesso nossa primeira exceção e retornamos dela! O próximo passo é garantir que capturemos todas as exceções porque uma exceção não capturada causa um triple fault fatal, que leva a uma redefinição do sistema. A próxima postagem explica como podemos evitar isso capturando corretamente double faults.
Comentários
Teve algum problema, quer deixar um feedback ou discutir mais ideias? Fique à vontade para deixar um comentário aqui! Por favor, use o inglês e siga o código de conduta do Rust. Este tópico de comentários está diretamente vinculado a uma discussão no GitHub, então você também pode comentar lá se preferir.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor, deixe seus comentários em inglês se possível.