Un Kernel Mínimo en Rust
Contenido Traducido: Esta es una traducción comunitaria del post A Minimal Rust Kernel. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
En esta publicación, crearemos un kernel mínimo de 64 bits en Rust para la arquitectura x86. Partiremos del un binario Rust autónomo de la publicación anterior para crear una imagen de disco arrancable que imprima algo en la pantalla.
Este blog se desarrolla abiertamente en GitHub. Si tienes problemas o preguntas, por favor abre un issue ahí. También puedes dejar comentarios al final. El código fuente completo para esta publicación se encuentra en la rama post-02.
Tabla de Contenidos
🔗El Proceso de Arranque
Cuando enciendes una computadora, comienza a ejecutar código de firmware almacenado en la ROM de la placa madre. Este código realiza una prueba automática de encendido, detecta la memoria RAM disponible y preinicializa la CPU y el hardware. Después, busca un disco arrancable y comienza a cargar el kernel del sistema operativo.
En x86, existen dos estándares de firmware: el “Sistema Básico de Entrada/Salida” (BIOS) y la más reciente “Interfaz de Firmware Extensible Unificada” (UEFI). El estándar BIOS es antiguo y está desactualizado, pero es simple y está bien soportado en cualquier máquina x86 desde los años 80. UEFI, en contraste, es más moderno y tiene muchas más funciones, pero es más complejo de configurar (al menos en mi opinión).
Actualmente, solo proporcionamos soporte para BIOS, pero también planeamos agregar soporte para UEFI. Si te gustaría ayudarnos con esto, revisa el issue en Github.
🔗Arranque con BIOS
Casi todos los sistemas x86 tienen soporte para arranque con BIOS, incluyendo máquinas más recientes basadas en UEFI que usan un BIOS emulado. Esto es excelente, porque puedes usar la misma lógica de arranque en todas las máquinas del último siglo. Sin embargo, esta amplia compatibilidad también es la mayor desventaja del arranque con BIOS, ya que significa que la CPU se coloca en un modo de compatibilidad de 16 bits llamado modo real antes de arrancar, para que los bootloaders arcaicos de los años 80 sigan funcionando.
Pero comencemos desde el principio:
Cuando enciendes una computadora, carga el BIOS desde una memoria flash especial ubicada en la placa madre. El BIOS ejecuta rutinas de autoprueba e inicialización del hardware, y luego busca discos arrancables. Si encuentra uno, transfiere el control a su bootloader (cargador de arranque), que es una porción de código ejecutable de 512 bytes almacenada al inicio del disco. La mayoría de los bootloaders son más grandes que 512 bytes, por lo que suelen dividirse en una pequeña primera etapa, que cabe en esos 512 bytes, y una segunda etapa que se carga posteriormente.
El bootloader debe determinar la ubicación de la imagen del kernel en el disco y cargarla en la memoria. Tambien necesita cambiar la CPU del modo real de 16 bits primero al modo protegido de 32 bits, y luego al modo largo de 64 bits, donde están disponibles los registros de 64 bits y toda la memoria principal. Su tercera tarea es consultar cierta información (como un mapa de memoria) desde el BIOS y pasársela al kernel del sistema operativo.
Escribir un bootloader es un poco tedioso, ya que requiere lenguaje ensamblador y muchos pasos poco claros como “escribir este valor mágico en este registro del procesador”. Por ello, no cubrimos la creación de bootloaders en este artículo y en su lugar proporcionamos una herramienta llamada bootimage que automatiza el proceso de creación de un bootloader.
Si te interesa construir tu propio bootloader: ¡Estén atentos! Un conjunto de artículos sobre este tema está en camino.
🔗El Estándar Multiboot
Para evitar que cada sistema operativo implemente su propio bootloader, que sea compatible solo con un único sistema, la Free Software Foundation creó en 1995 un estándar abierto de bootloaders llamado Multiboot. El estándar define una interfaz entre el bootloader y el sistema operativo, de modo que cualquier bootloader compatible con Multiboot pueda cargar cualquier sistema operativo compatible con Multiboot. La implementación de referencia es GNU GRUB, que es el bootloader más popular para sistemas Linux.
Para hacer un kernel compatible con Multiboot, solo necesitas insertar un llamado encabezado Multiboot al inicio del archivo del kernel. Esto hace que arrancar un sistema operativo desde GRUB sea muy sencillo. Sin embargo, GRUB y el estándar Multiboot también tienen algunos problemas:
- Solo soportan el modo protegido de 32 bits. Esto significa que aún tienes que configurar la CPU para cambiar al modo largo de 64 bits.
- Están diseñados para simplificar el cargador de arranque en lugar del kernel. Por ejemplo, el kernel necesita vincularse con un tamaño de página predeterminado ajustado, porque GRUB no puede encontrar el encabezado Multiboot de otro modo. Otro ejemplo es que la información de arranque, que se pasa al kernel, contiene muchas estructuras dependientes de la arquitectura en lugar de proporcionar abstracciones limpias.
- Tanto GRUB como el estándar Multiboot están escasamente documentados.
- GRUB necesita instalarse en el sistema host para crear una imagen de disco arrancable a partir del archivo del kernel. Esto dificulta el desarrollo en Windows o Mac.
Debido a estas desventajas, decidimos no usar GRUB ni el estándar Multiboot. Sin embargo, planeamos agregar soporte para Multiboot a nuestra herramienta bootimage, para que sea posible cargar tu kernel en un sistema GRUB también. Si te interesa escribir un kernel compatible con Multiboot, revisa la primera edición de esta serie de blogs.
🔗UEFI
(Por el momento no proporcionamos soporte para UEFI, ¡pero nos encantaría hacerlo! Si deseas ayudar, por favor háznoslo saber en el issue de Github.)
🔗Un Kernel Mínimo
Ahora que tenemos una idea general de cómo arranca una computadora, es momento de crear nuestro propio kernel mínimo. Nuestro objetivo es crear una imagen de disco que, al arrancar, imprima “Hello World!” en la pantalla. Para esto, extendemos el un binario Rust autónomo del artículo anterior.
Como recordarás, construimos el binario independiente mediante cargo, pero dependiendo del sistema operativo, necesitábamos diferentes nombres de punto de entrada y banderas de compilación. Esto se debe a que cargo construye por defecto para el sistema anfitrión, es decir, el sistema en el que estás ejecutando el comando. Esto no es lo que queremos para nuestro kernel, ya que un kernel que funcione encima, por ejemplo, de Windows, no tiene mucho sentido. En su lugar, queremos compilar para un sistema destino claramente definido.
🔗Instalación de Rust Nightly
Rust tiene tres canales de lanzamiento: stable, beta y nightly. El libro de Rust explica muy bien la diferencia entre estos canales, así que tómate un momento para revisarlo. Para construir un sistema operativo, necesitaremos algunas características experimentales que solo están disponibles en el canal nightly, por lo que debemos instalar una versión nightly de Rust.
Para administrar instalaciones de Rust, recomiendo ampliamente rustup. Este permite instalar compiladores nightly, beta y estable lado a lado, y facilita mantenerlos actualizados. Con rustup, puedes usar un compilador nightly en el directorio actual ejecutando rustup override set nightly. Alternativamente, puedes agregar un archivo llamado rust-toolchain con el contenido nightly en el directorio raíz del proyecto. Puedes verificar que tienes una versión nightly instalada ejecutando rustc --version: el número de versión debería contener -nightly al final.
El compilador nightly nos permite activar varias características experimentales utilizando las llamadas banderas de características al inicio de nuestro archivo. Por ejemplo, podríamos habilitar el macro experimental asm! para ensamblador en línea agregando #![feature(asm)] en la parte superior de nuestro archivo main.rs. Ten en cuenta que estas características experimentales son completamente inestables, lo que significa que futuras versiones de Rust podrían cambiarlas o eliminarlas sin previo aviso. Por esta razón, solo las utilizaremos si son absolutamente necesarias.
🔗Especificación del Objetivo
Cargo soporta diferentes sistemas destino mediante el parámetro --target. El destino se describe mediante un tripleta de destino, que especifica la arquitectura de la CPU, el proveedor, el sistema operativo y el ABI. Por ejemplo, el tripleta de destino x86_64-unknown-linux-gnu describe un sistema con una CPU x86_64, sin un proveedor claro, y un sistema operativo Linux con el ABI GNU. Rust soporta muchas tripleta de destino diferentes, incluyendo arm-linux-androideabi para Android o wasm32-unknown-unknown para WebAssembly.
Para nuestro sistema destino, sin embargo, requerimos algunos parámetros de configuración especiales (por ejemplo, sin un sistema operativo subyacente), por lo que ninguno de los tripletas de destino existentes encaja. Afortunadamente, Rust nos permite definir nuestros propios objetivos mediante un archivo JSON. Por ejemplo, un archivo JSON que describe el objetivo x86_64-unknown-linux-gnu se ve así:
{
"llvm-target": "x86_64-unknown-linux-gnu",
"data-layout": "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128",
"arch": "x86_64",
"target-endian": "little",
"target-pointer-width": 64,
"target-c-int-width": 32,
"os": "linux",
"executables": true,
"linker-flavor": "gcc",
"pre-link-args": ["-m64"],
"morestack": false
}
La mayoría de los campos son requeridos por LLVM para generar código para esa plataforma. Por ejemplo, el campo data-layout define el tamaño de varios tipos de enteros, números de punto flotante y punteros. Luego, hay campos que Rust utiliza para la compilación condicional, como target-pointer-width. El tercer tipo de campo define cómo debe construirse el crate. Por ejemplo, el campo pre-link-args especifica argumentos que se pasan al linker.
Nuestro kernel también tiene como objetivo los sistemas x86_64, por lo que nuestra especificación de objetivo será muy similar a la anterior. Comencemos creando un archivo llamado x86_64-blog_os.json (puedes elegir el nombre que prefieras) con el siguiente contenido común:
{
"llvm-target": "x86_64-unknown-none",
"data-layout": "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128",
"arch": "x86_64",
"target-endian": "little",
"target-pointer-width": 64,
"target-c-int-width": 32,
"os": "none",
"executables": true
}
Ten en cuenta que cambiamos el sistema operativo en el campo llvm-target y en el campo os a none, porque nuestro kernel se ejecutará directamente sobre hardware sin un sistema operativo subyacente.
Agregamos las siguientes entradas relacionadas con la construcción:
"linker-flavor": "ld.lld",
"linker": "rust-lld",
En lugar de usar el enlazador predeterminado de la plataforma (que podría no soportar objetivos de Linux), utilizamos el enlazador multiplataforma LLD que se incluye con Rust para enlazar nuestro kernel.
"panic-strategy": "abort",
Esta configuración especifica que el objetivo no soporta stack unwinding en caso de un pánico, por lo que el programa debería abortar directamente. Esto tiene el mismo efecto que la opción panic = "abort" en nuestro archivo Cargo.toml, por lo que podemos eliminarla de ahí. (Ten en cuenta que, a diferencia de la opción en Cargo.toml, esta opción del destino también se aplica cuando recompilamos la biblioteca core más adelante en este artículo. Por lo tanto, incluso si prefieres mantener la opción en Cargo.toml, asegúrate de incluir esta opción.)
"disable-redzone": true,
Estamos escribiendo un kernel, por lo que en algún momento necesitaremos manejar interrupciones. Para hacerlo de manera segura, debemos deshabilitar una optimización del puntero de pila llamada “red zone”, ya que de lo contrario podría causar corrupción en la pila. Para más información, consulta nuestro artículo sobre [cómo deshabilitar la red zone].
"features": "-mmx,-sse,+soft-float",
El campo features habilita o deshabilita características del destinos. Deshabilitamos las características mmx y sse anteponiéndoles un signo menos y habilitamos la característica soft-float anteponiéndole un signo más. Ten en cuenta que no debe haber espacios entre las diferentes banderas, ya que de lo contrario LLVM no podrá interpretar correctamente la cadena de características.
Las características mmx y sse determinan el soporte para instrucciones Single Instruction Multiple Data (SIMD), que a menudo pueden acelerar significativamente los programas. Sin embargo, el uso de los registros SIMD en kernels de sistemas operativos genera problemas de rendimiento. Esto se debe a que el kernel necesita restaurar todos los registros a su estado original antes de continuar un programa interrumpido. Esto implica que el kernel debe guardar el estado completo de SIMD en la memoria principal en cada llamada al sistema o interrupción de hardware. Dado que el estado SIMD es muy grande (512–1600 bytes) y las interrupciones pueden ocurrir con mucha frecuencia, estas operaciones adicionales de guardar/restaurar afectan considerablemente el rendimiento. Para evitar esto, deshabilitamos SIMD para nuestro kernel (pero no para las aplicaciones que se ejecutan encima).
Un problema al deshabilitar SIMD es que las operaciones de punto flotante en x86_64 requieren registros SIMD por defecto. Para resolver este problema, agregamos la característica soft-float, que emula todas las operaciones de punto flotante mediante funciones de software basadas en enteros normales.
Para más información, consulta nuestro artículo sobre cómo deshabilitar SIMD.
🔗Juntándolo Todo
Nuestro archivo de especificación de objetivo ahora se ve así:
{
"llvm-target": "x86_64-unknown-none",
"data-layout": "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128",
"arch": "x86_64",
"target-endian": "little",
"target-pointer-width": 64,
"target-c-int-width": 32,
"os": "none",
"executables": true,
"linker-flavor": "ld.lld",
"linker": "rust-lld",
"panic-strategy": "abort",
"disable-redzone": true,
"features": "-mmx,-sse,+soft-float"
}
🔗Construyendo nuestro Kernel
Compilar para nuestro nuevo objetivo usará convenciones de Linux, ya que la opción de enlazador ld.lld instruye a LLVM a compilar con la bandera -flavor gnu (para más opciones del enlazador, consulta la documentación de rustc). Esto significa que necesitamos un punto de entrada llamado _start, como se describió en el artículo anterior:
// src/main.rs
#![no_std] // no enlazar con la biblioteca estándar de Rust
#![no_main] // deshabilitar todos los puntos de entrada a nivel de Rust
use core::panic::PanicInfo;
/// Esta función se llama cuando ocurre un pánico.
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
loop {}
}
#[unsafe(no_mangle)] // no modificar el nombre de esta función
pub extern "C" fn _start() -> ! {
// esta función es el punto de entrada, ya que el enlazador busca una función
// llamada `_start` por defecto
loop {}
}
Ten en cuenta que el punto de entrada debe llamarse _start sin importar el sistema operativo anfitrión.
Ahora podemos construir el kernel para nuestro nuevo objetivo pasando el nombre del archivo JSON como --target:
> cargo build --target x86_64-blog_os.json
error: `.json` target specs require -Zjson-target-spec
¡Falla! El error nos indica que las especificaciones de objetivo JSON personalizadas son una característica inestable que requiere habilitación explícita. Esto se debe a que el formato de los archivos JSON de objetivo aún no se considera estable, por lo que podrían ocurrir cambios en futuras versiones de Rust. Consulta el issue de seguimiento para especificaciones de objetivo JSON personalizadas para más información.
🔗La Opción json-target-spec
Para habilitar el soporte para especificaciones de objetivo JSON personalizadas, necesitamos crear un archivo de configuración local de cargo en .cargo/config.toml (la carpeta .cargo debería estar junto a tu carpeta src) con el siguiente contenido:
# en .cargo/config.toml
[unstable]
json-target-spec = true
Esto habilita la característica inestable json-target-spec, permitiéndonos usar archivos JSON de objetivo personalizados.
Con esta configuración en su lugar, intentemos construir nuevamente:
> cargo build --target x86_64-blog_os.json
error[E0463]: can't find crate for `core`
¡Ahora vemos un error diferente! El error nos indica que el compilador de Rust ya no encuentra la biblioteca core. Esta biblioteca contiene tipos básicos de Rust como Result, Option e iteradores, y se vincula implícitamente a todos los crates con no_std.
El problema es que la biblioteca core se distribuye junto con el compilador de Rust como una biblioteca precompilada. Por lo tanto, solo es válida para tripletas de anfitrión soportados (por ejemplo, x86_64-unknown-linux-gnu), pero no para nuestro objetivo personalizado. Si queremos compilar código para otros objetivos, necesitamos recompilar core para esos objetivos primero.
🔗La Opción build-std
Aquí es donde entra en juego la característica build-std de cargo. Esta permite recompilar core y otras bibliotecas estándar bajo demanda, en lugar de usar las versiones precompiladas que vienen con la instalación de Rust. Esta característica es muy nueva y aún no está terminada, por lo que está marcada como “inestable” y solo está disponible en los compiladores de Rust nightly.
Para usar esta característica, necesitamos añadir lo siguiente a nuestro archivo de configuración de cargo en .cargo/config.toml:
# en .cargo/config.toml
[unstable]
json-target-spec = true
build-std = ["core", "compiler_builtins"]
Esto le indica a cargo que debe recompilar las bibliotecas core y compiler_builtins. Esta última es necesaria porque es una dependencia de core. Para poder recompilar estas bibliotecas, cargo necesita acceso al código fuente de Rust, el cual podemos instalar ejecutando rustup component add rust-src.
Nota: La clave de configuración unstable.build-std requiere al menos la versión de Rust nightly del 15 de julio de 2020.
Después de configurar la clave unstable.build-std e instalar el componente rust-src, podemos ejecutar nuevamente nuestro comando de construcción:
> cargo build --target x86_64-blog_os.json
Compiling core v0.0.0 (/…/rust/src/libcore)
Compiling rustc-std-workspace-core v1.99.0 (/…/rust/src/tools/rustc-std-workspace-core)
Compiling compiler_builtins v0.1.32
Compiling blog_os v0.1.0 (/…/blog_os)
Finished dev [unoptimized + debuginfo] target(s) in 0.29 secs
Vemos que cargo build ahora recompila las bibliotecas core, rustc-std-workspace-core (una dependencia de compiler_builtins) y compiler_builtins para nuestro objetivo personalizado.
🔗Intrínsecos Relacionados con la Memoria
El compilador de Rust asume que un cierto conjunto de funciones integradas está disponible para todos los sistemas. La mayoría de estas funciones son proporcionadas por el crate compiler_builtins, que acabamos de recompilar. Sin embargo, hay algunas funciones relacionadas con la memoria en ese crate que no están habilitadas por defecto, ya que normalmente son proporcionadas por la biblioteca C del sistema. Estas funciones incluyen memset, que establece todos los bytes de un bloque de memoria a un valor dado, memcpy, que copia un bloque de memoria a otro, y memcmp, que compara dos bloques de memoria. Aunque no necesitamos estas funciones para compilar nuestro kernel en este momento, serán necesarias tan pronto como agreguemos más código (por ejemplo, al copiar estructuras).
Dado que no podemos vincularnos a la biblioteca C del sistema operativo, necesitamos una forma alternativa de proporcionar estas funciones al compilador. Una posible solución podría ser implementar nuestras propias funciones memset, memcpy, etc., y aplicarles el atributo #[unsafe(no_mangle)] (para evitar el renombramiento automático durante la compilación). Sin embargo, esto es peligroso, ya que el más mínimo error en la implementación de estas funciones podría conducir a un comportamiento indefinido. Por ejemplo, implementar memcpy con un bucle for podría resultar en una recursión infinita, ya que los bucles for llaman implícitamente al método del trait IntoIterator::into_iter, que podría invocar nuevamente a memcpy. Por lo tanto, es una buena idea reutilizar implementaciones existentes y bien probadas.
Afortunadamente, el crate compiler_builtins ya contiene implementaciones para todas las funciones necesarias, pero están deshabilitadas por defecto para evitar conflictos con las implementaciones de la biblioteca C. Podemos habilitarlas configurando la bandera build-std-features de cargo como ["compiler-builtins-mem"]. Al igual que la bandera build-std, esta bandera puede pasarse como un flag -Z en la línea de comandos o configurarse en la tabla unstable en el archivo .cargo/config.toml. Dado que siempre queremos compilar con esta bandera, la opción de archivo de configuración tiene más sentido para nosotros:
# en .cargo/config.toml
[unstable]
json-target-spec = true
build-std-features = ["compiler-builtins-mem"]
build-std = ["core", "compiler_builtins"]
(El soporte para la característica compiler-builtins-mem fue añadido muy recientemente, por lo que necesitas al menos Rust nightly 2020-09-30 para usarla).
Detrás de escena, esta bandera habilita la característica mem del crate compiler_builtins. El efecto de esto es que el atributo #[unsafe(no_mangle)] se aplica a las implementaciones de memcpy, etc. del crate, lo que las hace disponibles para el enlazador.
Con este cambio, nuestro kernel tiene implementaciones válidas para todas las funciones requeridas por el compilador, por lo que continuará compilándose incluso si nuestro código se vuelve más complejo.
🔗Configurar un Objetivo Predeterminado
Para evitar pasar el parámetro --target en cada invocación de cargo build, podemos sobrescribir el objetivo predeterminado. Para hacer esto, añadimos lo siguiente a nuestro archivo de configuración de cargo en .cargo/config.toml:
# en .cargo/config.toml
[build]
target = "x86_64-blog_os.json"
Esto le indica a cargo que use nuestro objetivo x86_64-blog_os.json cuando no se pase explícitamente el argumento --target. Esto significa que ahora podemos construir nuestro kernel con un simple cargo build. Para más información sobre las opciones de configuración de cargo, consulta la documentación oficial.
Ahora podemos construir nuestro kernel para un objetivo bare metal con un simple cargo build. Sin embargo, nuestro punto de entrada _start, que será llamado por el cargador de arranque, aún está vacío. Es momento de mostrar algo en la pantalla desde ese punto.
🔗Imprimiendo en Pantalla
La forma más sencilla de imprimir texto en la pantalla en esta etapa es usando el búfer de texto VGA. Es un área de memoria especial mapeada al hardware VGA que contiene el contenido mostrado en pantalla. Normalmente consta de 25 líneas, cada una con 80 celdas de caracteres. Cada celda de carácter muestra un carácter ASCII con algunos colores de primer plano y fondo. La salida en pantalla se ve así:

Discutiremos el diseño exacto del búfer VGA en el próximo artículo, donde escribiremos un primer controlador pequeño para él. Para imprimir “Hello World!”, solo necesitamos saber que el búfer está ubicado en la dirección 0xb8000 y que cada celda de carácter consta de un byte ASCII y un byte de color.
La implementación se ve así:
static HELLO: &[u8] = b"Hello World!";
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
let vga_buffer = 0xb8000 as *mut u8;
for (i, &byte) in HELLO.iter().enumerate() {
unsafe {
*vga_buffer.offset(i as isize * 2) = byte;
*vga_buffer.offset(i as isize * 2 + 1) = 0xb;
}
}
loop {}
}
Primero, convertimos el entero 0xb8000 en un raw pointer. Luego, iteramos sobre los bytes de la [cadena de bytes estática] HELLO. Usamos el método enumerate para obtener adicionalmente una variable de conteo i. En el cuerpo del bucle for, utilizamos el método offset para escribir el byte de la cadena y el byte de color correspondiente (0xb representa un cian claro).
Ten en cuenta que hay un bloque unsafe alrededor de todas las escrituras de memoria. Esto se debe a que el compilador de Rust no puede probar que los punteros crudos que creamos son válidos. Podrían apuntar a cualquier lugar y causar corrupción de datos. Al poner estas operaciones en un bloque unsafe, básicamente le decimos al compilador que estamos absolutamente seguros de que las operaciones son válidas. Sin embargo, un bloque unsafe no desactiva las verificaciones de seguridad de Rust; simplemente permite realizar cinco operaciones adicionales.
Quiero enfatizar que esta no es la forma en que queremos hacer las cosas en Rust. Es muy fácil cometer errores al trabajar con punteros crudos dentro de bloques unsafe. Por ejemplo, podríamos escribir más allá del final del búfer si no somos cuidadosos.
Por lo tanto, queremos minimizar el uso de unsafe tanto como sea posible. Rust nos permite lograr esto creando abstracciones seguras. Por ejemplo, podríamos crear un tipo de búfer VGA que encapsule toda la inseguridad y garantice que sea imposible hacer algo incorrecto desde el exterior. De esta manera, solo necesitaríamos cantidades mínimas de código unsafe y podríamos estar seguros de no violar la seguridad de la memoria. Crearemos una abstracción segura para el búfer VGA en el próximo artículo.
🔗Ejecutando Nuestro Kernel
Ahora que tenemos un ejecutable que realiza algo perceptible, es momento de ejecutarlo. Primero, necesitamos convertir nuestro kernel compilado en una imagen de disco arrancable vinculándolo con un cargador de arranque. Luego, podemos ejecutar la imagen de disco en la máquina virtual QEMU o iniciarla en hardware real usando una memoria USB.
🔗Creando una Bootimage
Para convertir nuestro kernel compilado en una imagen de disco arrancable, debemos vincularlo con un cargador de arranque. Como aprendimos en la sección sobre el proceso de arranque, el cargador de arranque es responsable de inicializar la CPU y cargar nuestro kernel.
En lugar de escribir nuestro propio cargador de arranque, lo cual es un proyecto en sí mismo, usamos el crate bootloader. Este crate implementa un cargador de arranque básico para BIOS sin dependencias en C, solo Rust y ensamblador en línea. Para usarlo y arrancar nuestro kernel, necesitamos agregarlo como dependencia:
# en Cargo.toml
[dependencies]
bootloader = "0.9"
Nota: Este artículo solo es compatible con bootloader v0.9. Las versiones más recientes usan un sistema de construcción diferente y generarán errores de compilación al seguir este artículo.
Agregar el bootloader como dependencia no es suficiente para crear una imagen de disco arrancable. El problema es que necesitamos vincular nuestro kernel con el bootloader después de la compilación, pero cargo no tiene soporte para scripts post-compilación.
Para resolver este problema, creamos una herramienta llamada bootimage que primero compila el kernel y el bootloader, y luego los vincula para crear una imagen de disco arrancable. Para instalar esta herramienta, dirígete a tu directorio de inicio (o cualquier directorio fuera de tu proyecto de cargo) y ejecuta el siguiente comando en tu terminal:
cargo install bootimage
Para ejecutar bootimage y compilar el bootloader, necesitas tener instalado el componente llvm-tools-preview de rustup. Puedes hacerlo ejecutando el comando correspondiente.
Después de instalar bootimage y agregar el componente llvm-tools-preview, puedes crear una imagen de disco arrancable regresando al directorio de tu proyecto de cargo y ejecutando:
> cargo bootimage
Vemos que la herramienta recompila nuestro kernel usando cargo build, por lo que automáticamente aplicará cualquier cambio que realices. Después, compila el bootloader, lo cual puede tardar un poco. Como ocurre con todas las dependencias de los crates, solo se compila una vez y luego se almacena en caché, por lo que las compilaciones posteriores serán mucho más rápidas. Finalmente, bootimage combina el bootloader y tu kernel en una imagen de disco arrancable.
Después de ejecutar el comando, deberías ver una imagen de disco arrancable llamada bootimage-blog_os.bin en tu directorio target/x86_64-blog_os/debug. Puedes arrancarla en una máquina virtual o copiarla a una unidad USB para arrancarla en hardware real. (Ten en cuenta que esta no es una imagen de CD, que tiene un formato diferente, por lo que grabarla en un CD no funcionará).
🔗¿Cómo funciona?
La herramienta bootimage realiza los siguientes pasos detrás de escena:
- Compila nuestro kernel en un archivo ELF.
- Compila la dependencia del bootloader como un ejecutable independiente.
- Vincula los bytes del archivo ELF del kernel con el bootloader.
Al arrancar, el bootloader lee y analiza el archivo ELF anexado. Luego, mapea los segmentos del programa a direcciones virtuales en las tablas de páginas, inicializa a cero la sección .bss y configura una pila. Finalmente, lee la dirección del punto de entrada (nuestra función _start) y salta a ella.
🔗Arrancando en QEMU
Ahora podemos arrancar la imagen de disco en una máquina virtual. Para arrancarla en QEMU, ejecuta el comando correspondiente.
> qemu-system-x86_64 -drive format=raw,file=target/x86_64-blog_os/debug/bootimage-blog_os.bin
Esto abre una ventana separada que debería verse similar a esto:
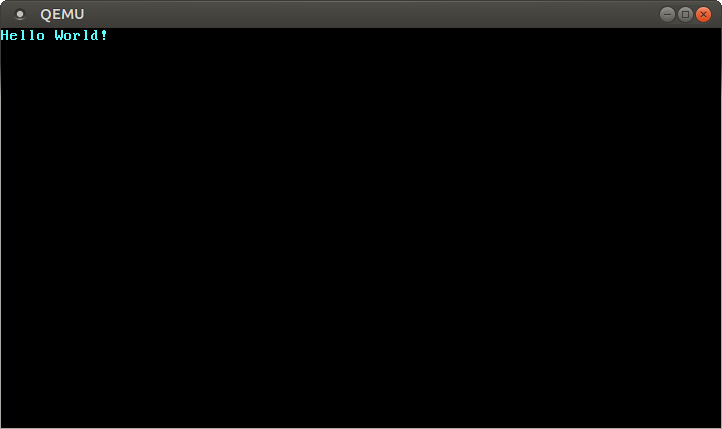
Vemos que nuestro “Hello World!” es visible en la pantalla.
🔗Máquina Real
También es posible escribir la imagen a una memoria USB y arrancarla en una máquina real, pero ten mucho cuidado al elegir el nombre correcto del dispositivo, porque todo en ese dispositivo será sobrescrito:
> dd if=target/x86_64-blog_os/debug/bootimage-blog_os.bin of=/dev/sdX && sync
Donde sdX es el nombre del dispositivo de tu memoria USB.
Después de escribir la imagen en la memoria USB, puedes ejecutarla en hardware real iniciando desde ella. Probablemente necesitarás usar un menú de arranque especial o cambiar el orden de arranque en la configuración del BIOS para iniciar desde la memoria USB. Ten en cuenta que actualmente no funciona para máquinas UEFI, ya que el crate bootloader aún no tiene soporte para UEFI.
🔗Usando cargo run
Para facilitar la ejecución de nuestro kernel en QEMU, podemos configurar la clave de configuración runner para cargo:
# en .cargo/config.toml
[target.'cfg(target_os = "none")']
runner = "bootimage runner"
La tabla target.'cfg(target_os = "none")' se aplica a todos los objetivos cuyo campo "os" en el archivo de configuración del objetivo esté configurado como "none". Esto incluye nuestro objetivo x86_64-blog_os.json. La clave runner especifica el comando que debe ejecutarse para cargo run. El comando se ejecuta después de una compilación exitosa, con la ruta del ejecutable pasada como el primer argumento. Consulta la documentación de cargo para más detalles.
El comando bootimage runner está específicamente diseñado para ser utilizado como un ejecutable runner. Vincula el ejecutable dado con la dependencia del bootloader del proyecto y luego lanza QEMU. Consulta el README de bootimage para más detalles y posibles opciones de configuración.
Ahora podemos usar cargo run para compilar nuestro kernel e iniciarlo en QEMU.
🔗¿Qué sigue?
En el próximo artículo, exploraremos el búfer de texto VGA con más detalle y escribiremos una interfaz segura para él. También añadiremos soporte para el macro println.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.