Excepciones de Doble Fallo
Contenido Traducido: Esta es una traducción comunitaria del post Double Faults. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
Esta publicación explora en detalle la excepción de doble fallo, que ocurre cuando la CPU no logra invocar un controlador de excepciones. Al manejar esta excepción, evitamos fallos triples fatales que causan un reinicio del sistema. Para prevenir fallos triples en todos los casos, también configuramos una Tabla de Pila de Interrupciones (IST) para capturar dobles fallos en una pila de núcleo separada.
Este blog se desarrolla abiertamente en GitHub. Si tienes problemas o preguntas, abre un issue allí. También puedes dejar comentarios al final. El código fuente completo de esta publicación se puede encontrar en la rama post-06.
Tabla de Contenidos
🔗¿Qué es un Doble Fallo?
En términos simplificados, un doble fallo es una excepción especial que ocurre cuando la CPU no logra invocar un controlador de excepciones. Por ejemplo, ocurre cuando se activa un fallo de página pero no hay un controlador de fallo de página registrado en la Tabla de Descriptores de Interrupciones (IDT). Así que es un poco similar a los bloques de captura de “cosecha todo” en lenguajes de programación con excepciones, por ejemplo, catch(...) en C++ o catch(Exception e) en Java o C#.
Un doble fallo se comporta como una excepción normal. Tiene el número de vector 8 y podemos definir una función controladora normal para él en la IDT. Es realmente importante proporcionar un controlador de doble fallo, porque si un doble fallo no se maneja, ocurre un fallo triple fatal. Los fallos triples no se pueden capturar, y la mayoría del hardware reacciona con un reinicio del sistema.
🔗Provocando un Doble Fallo
Provocamos un doble fallo al activar una excepción para la cual no hemos definido una función controladora:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// provocar un fallo de página
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// como antes
#[cfg(test)]
test_main();
println!("¡No se colapsó!");
loop {}
}
Usamos unsafe para escribir en la dirección inválida 0xdeadbeef. La dirección virtual no está mapeada a una dirección física en las tablas de páginas, por lo que ocurre un fallo de página. No hemos registrado un controlador de fallo de página en nuestra IDT, así que ocurre un doble fallo.
Cuando iniciamos nuestro núcleo ahora, vemos que entra en un bucle de arranque interminable. La razón del bucle de arranque es la siguiente:
- La CPU intenta escribir en
0xdeadbeef, lo que causa un fallo de página. - La CPU consulta la entrada correspondiente en la IDT y ve que no se especifica ninguna función controladora. Por lo tanto, no puede llamar al controlador de fallo de página y ocurre un doble fallo.
- La CPU consulta la entrada de la IDT del controlador de doble fallo, pero esta entrada tampoco especifica una función controladora. Por lo tanto, ocurre un fallo triple.
- Un fallo triple es fatal. QEMU reacciona a esto como la mayoría del hardware real y emite un reinicio del sistema.
Por lo tanto, para prevenir este fallo triple, necesitamos proporcionar una función controladora para los fallos de página o un controlador de doble fallo. Queremos evitar los fallos triples en todos los casos, así que empecemos con un controlador de doble fallo que se invoca para todos los tipos de excepciones no manejadas.
🔗Un Controlador de Doble Fallo
Un doble fallo es una excepción normal con un código de error, por lo que podemos especificar una función controladora similar a nuestra función controladora de punto de interrupción:
// en src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // nuevo
idt
};
}
// nuevo
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPCIÓN: DOBLE FALLO\n{:#?}", stack_frame);
}
Nuestro controlador imprime un corto mensaje de error y volcado del marco de pila de excepciones. El código de error del controlador de doble fallo siempre es cero, así que no hay razón para imprimirlo. Una diferencia con el controlador de punto de interrupción es que el controlador de doble fallo es divergente. La razón es que la arquitectura x86_64 no permite devolver de una excepción de doble fallo.
Cuando iniciamos nuestro núcleo ahora, deberíamos ver que se invoca el controlador de doble fallo:
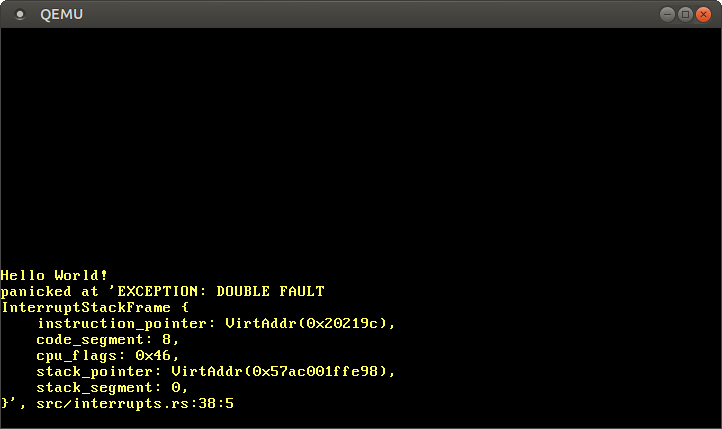
¡Funcionó! Aquí está lo que sucedió esta vez:
- La CPU intenta escribir en
0xdeadbeef, lo que causa un fallo de página. - Como antes, la CPU consulta la entrada correspondiente en la IDT y ve que no se define ninguna función controladora. Así que ocurre un doble fallo.
- La CPU salta al – ahora presente – controlador de doble fallo.
El fallo triple (y el bucle de arranque) ya no ocurre, ya que la CPU ahora puede llamar al controlador de doble fallo.
¡Eso fue bastante directo! Entonces, ¿por qué necesitamos una publicación completa sobre este tema? Bueno, ahora podemos capturar la mayoría de los dobles fallos, pero hay algunos casos en los que nuestro enfoque actual no es suficiente.
🔗Causas de Doble Fallos
Antes de mirar los casos especiales, necesitamos conocer las causas exactas de los dobles fallos. Arriba, usamos una definición bastante vaga:
Un doble fallo es una excepción especial que ocurre cuando la CPU no logra invocar un controlador de excepciones.
¿Qué significa exactamente “no logra invocar”? ¿No está presente el controlador? ¿El controlador está intercambiado? ¿Y qué sucede si un controlador causa excepciones a su vez?
Por ejemplo, ¿qué ocurre si:
- ocurre una excepción de punto de interrupción, pero la función controladora correspondiente está intercambiada?
- ocurre un fallo de página, pero el controlador de fallo de página está intercambiado?
- un controlador de división por cero causa una excepción de punto de interrupción, pero el controlador de punto de interrupción está intercambiado?
- nuestro núcleo desborda su pila y se activa la página de guardia?
Afortunadamente, el manual de AMD64 (PDF) tiene una definición exacta (en la Sección 8.2.9). Según él, una “excepción de doble fallo puede ocurrir cuando una segunda excepción ocurre durante el manejo de un controlador de excepción previo (primera)”. El “puede” es importante: Solo combinaciones muy específicas de excepciones conducen a un doble fallo. Estas combinaciones son:
Así que, por ejemplo, un fallo de división por cero seguido de un fallo de página está bien (se invoca el controlador de fallo de página), pero un fallo de división por cero seguido de un fallo de protección general conduce a un doble fallo.
Con la ayuda de esta tabla, podemos responder las tres primeras preguntas anteriores:
- Si ocurre una excepción de punto de interrupción y la función controladora correspondiente está intercambiada, ocurre un fallo de página y se invoca el controlador de fallo de página.
- Si ocurre un fallo de página y el controlador de fallo de página está intercambiado, ocurre un doble fallo y se invoca el controlador de doble fallo.
- Si un controlador de división por cero causa una excepción de punto de interrupción, la CPU intenta invocar el controlador de punto de interrupción. Si el controlador de punto de interrupción está intercambiado, ocurre un fallo de página y se invoca el controlador de fallo de página.
De hecho, incluso el caso de una excepción sin una función controladora en la IDT sigue este esquema: Cuando ocurre la excepción, la CPU intenta leer la entrada correspondiente de la IDT. Dado que la entrada es 0, que no es una entrada válida de la IDT, ocurre un fallo de protección general. No definimos una función controladora para el fallo de protección general tampoco, así que ocurre otro fallo de protección general. Según la tabla, esto conduce a un doble fallo.
🔗Desbordamiento de Pila del Núcleo
Veamos la cuarta pregunta:
¿Qué ocurre si nuestro núcleo desborda su pila y se activa la página de guardia?
Una página de guardia es una página de memoria especial en la parte inferior de una pila que permite detectar desbordamientos de pila. La página no está mapeada a ningún marco físico, por lo que acceder a ella provoca un fallo de página en lugar de corromper silenciosamente otra memoria. El cargador de arranque establece una página de guardia para nuestra pila de núcleo, así que un desbordamiento de pila provoca un fallo de página.
Cuando ocurre un fallo de página, la CPU busca el controlador de fallo de página en la IDT e intenta empujar el marco de pila de interrupción en la pila. Sin embargo, el puntero de pila actual aún apunta a la página de guardia no presente. Por lo tanto, ocurre un segundo fallo de página, que causa un doble fallo (según la tabla anterior).
Así que la CPU intenta llamar al controlador de doble fallo ahora. Sin embargo, en un doble fallo, la CPU también intenta empujar el marco de pila de excepción. El puntero de pila aún apunta a la página de guardia, por lo que ocurre un tercer fallo de página, que causa un fallo triple y un reinicio del sistema. Así que nuestro actual controlador de doble fallo no puede evitar un fallo triple en este caso.
¡Probémoslo nosotros mismos! Podemos provocar fácilmente un desbordamiento de pila del núcleo llamando a una función que recursivamente se llame a sí misma sin fin:
// en src/main.rs
#[no_mangle] // no mangles el nombre de esta función
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // por cada recursión, se empuja la dirección de retorno
}
// provocar un desbordamiento de pila
stack_overflow();
[…] // test_main(), println(…), y loop {}
}
Cuando intentamos este código en QEMU, vemos que el sistema entra en un bucle de arranque nuevamente.
Entonces, ¿cómo podemos evitar este problema? No podemos omitir el empuje del marco de pila de excepción, ya que la CPU lo hace ella misma. Así que necesitamos asegurarnos de alguna manera de que la pila sea siempre válida cuando ocurra una excepción de doble fallo. Afortunadamente, la arquitectura x86_64 tiene una solución a este problema.
🔗Cambio de Pilas
La arquitectura x86_64 es capaz de cambiar a una pila conocida y predefinida cuando ocurre una excepción. Este cambio se realiza a nivel de hardware, así que se puede hacer antes de que la CPU empuje el marco de pila de excepción.
El mecanismo de cambio se implementa como una Tabla de Pila de Interrupciones (IST). La IST es una tabla de 7 punteros a pilas conocidas y válidas. En pseudocódigo estilo Rust:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}
Para cada controlador de excepciones, podemos elegir una pila de la IST a través del campo stack_pointers en la entrada correspondiente de la IDT. Por ejemplo, nuestro controlador de doble fallo podría usar la primera pila en la IST. Entonces, la CPU cambia automáticamente a esta pila cada vez que ocurre un doble fallo. Este cambio ocurriría antes de que se empuje cualquier cosa, previniendo el fallo triple.
🔗La IST y TSS
La Tabla de Pila de Interrupciones (IST) es parte de una estructura antigua llamada Segmento de Estado de Tarea (TSS). La TSS solía contener varias piezas de información (por ejemplo, el estado de registro del procesador) sobre una tarea en modo de 32 bits y se usaba, por ejemplo, para cambio de contexto de hardware. Sin embargo, el cambio de contexto de hardware ya no se admite en modo de 64 bits y el formato de la TSS ha cambiado completamente.
En x86_64, la TSS ya no contiene ninguna información específica de tarea. En su lugar, contiene dos tablas de pilas (la IST es una de ellas). El único campo común entre la TSS de 32 bits y 64 bits es el puntero al bitmap de permisos de puertos de E/S.
La TSS de 64 bits tiene el siguiente formato:
| Campo | Tipo |
|---|---|
| (reservado) | u32 |
| Tabla de Pilas de Privilegio | [u64; 3] |
| (reservado) | u64 |
| Tabla de Pila de Interrupciones | [u64; 7] |
| (reservado) | u64 |
| (reservado) | u16 |
| Dirección Base del Mapa de E/S | u16 |
La Tabla de Pilas de Privilegio es usada por la CPU cuando cambia el nivel de privilegio. Por ejemplo, si ocurre una excepción mientras la CPU está en modo usuario (nivel de privilegio 3), la CPU normalmente cambia a modo núcleo (nivel de privilegio 0) antes de invocar el controlador de excepciones. En ese caso, la CPU cambiaría a la 0ª pila en la Tabla de Pilas de Privilegio (ya que 0 es el nivel de privilegio de destino). Aún no tenemos programas en modo usuario, así que ignoraremos esta tabla por ahora.
🔗Creando una TSS
Creemos una nueva TSS que contenga una pila de doble fallo separada en su tabla de pila de interrupciones. Para ello, necesitamos una estructura TSS. Afortunadamente, la crate x86_64 ya contiene una struct TaskStateSegment que podemos usar.
Creamos la TSS en un nuevo módulo gdt (el nombre tendrá sentido más adelante):
// en src/lib.rs
pub mod gdt;
// en src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(unsafe { &STACK });
let stack_end = stack_start + STACK_SIZE;
stack_end
};
tss
};
}
Usamos lazy_static porque el evaluador de const de Rust aún no es lo suficientemente potente como para hacer esta inicialización en tiempo de compilación. Definimos que la entrada 0 de la IST es la pila de doble fallo (cualquier otro índice de IST también funcionaría). Luego, escribimos la dirección superior de una pila de doble fallo en la entrada 0. Escribimos la dirección superior porque las pilas en x86 crecen hacia abajo, es decir, de direcciones altas a bajas.
No hemos implementado la gestión de memoria aún, así que no tenemos una forma adecuada de asignar una nueva pila. En su lugar, usamos un array static mut como almacenamiento de pila por ahora. El unsafe es requerido porque el compilador no puede garantizar la ausencia de condiciones de carrera cuando se accede a estáticos mutables. Es importante que sea un static mut y no un static inmutable, porque de lo contrario el cargador de arranque lo mapeará a una página de solo lectura. Reemplazaremos esto con una asignación de pila adecuada en una publicación posterior, entonces el unsafe ya no será necesario en este lugar.
Ten en cuenta que esta pila de doble fallo no tiene página de guardia que proteja contra el desbordamiento de pila. Esto significa que no deberíamos hacer nada intensivo en pila en nuestro controlador de doble fallo porque un desbordamiento de pila podría corromper la memoria debajo de la pila.
🔗Cargando la TSS
Ahora que hemos creado una nueva TSS, necesitamos una forma de decirle a la CPU que debe usarla. Desafortunadamente, esto es un poco engorroso ya que la TSS utiliza el sistema de segmentación (por razones históricas). En lugar de cargar la tabla directamente, necesitamos agregar un nuevo descriptor de segmento a la Tabla Global de Descriptores (GDT). Luego podemos cargar nuestra TSS invocando la instrucción ltr con el índice correspondiente de la GDT. (Esta es la razón por la que llamamos a nuestro módulo gdt).
🔗La Tabla Global de Descriptores
La Tabla Global de Descriptores (GDT) es un reliquia que se usaba para segmentación de memoria antes de que la paginación se convirtiera en el estándar de facto. Sin embargo, todavía se necesita en modo de 64 bits para varias cosas, como la configuración del modo núcleo/usuario o la carga de la TSS.
La GDT es una estructura que contiene los segmentos del programa. Se usaba en arquitecturas más antiguas para aislar programas unos de otros antes de que la paginación se convirtiera en el estándar. Para más información sobre segmentación, consulta el capítulo del mismo nombre en el libro gratuito “Three Easy Pieces”. Mientras que la segmentación ya no se admite en modo de 64 bits, la GDT sigue existiendo. Se utiliza principalmente para dos cosas: cambiar entre espacio de núcleo y espacio de usuario, y cargar una estructura TSS.
🔗Creando una GDT
Creemos una GDT estática que incluya un segmento para nuestra TSS estática:
// en src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.add_entry(Descriptor::kernel_code_segment());
gdt.add_entry(Descriptor::tss_segment(&TSS));
gdt
};
}
Como antes, usamos lazy_static de nuevo. Creamos una nueva GDT con un segmento de código y un segmento de TSS.
🔗Cargando la GDT
Para cargar nuestra GDT, creamos una nueva función gdt::init que llamamos desde nuestra función init:
// en src/gdt.rs
pub fn init() {
GDT.load();
}
// en src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}
Ahora nuestra GDT está cargada (ya que la función _start llama a init), pero aún vemos el bucle de arranque en el desbordamiento de pila.
🔗Los Pasos Finales
El problema es que los segmentos de la GDT aún no están activos porque los registros de segmento y TSS aún contienen los valores de la antigua GDT. También necesitamos modificar la entrada de IDT de doble fallo para que use la nueva pila.
En resumen, necesitamos hacer lo siguiente:
- Recargar el registro de segmento de código: Hemos cambiado nuestra GDT, así que deberíamos recargar
cs, el registro del segmento de código. Esto es necesario porque el antiguo selector de segmento podría ahora apuntar a un descriptor de GDT diferente (por ejemplo, un descriptor de TSS). - Cargar la TSS: Cargamos una GDT que contiene un selector de TSS, pero aún necesitamos decirle a la CPU que debe usar esa TSS.
- Actualizar la entrada de IDT: Tan pronto como nuestra TSS esté cargada, la CPU tendrá acceso a una tabla de pila de interrupciones (IST) válida. Luego podemos decirle a la CPU que debe usar nuestra nueva pila de doble fallo modificando nuestra entrada de IDT de doble fallo.
Para los dos primeros pasos, necesitamos acceso a las variables code_selector y tss_selector en nuestra función gdt::init. Podemos lograr esto haciéndolas parte de la estática a través de una nueva estructura Selectors:
// en src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}
Ahora podemos usar los selectores para recargar el registro cs y cargar nuestra TSS:
// en src/gdt.rs
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}
Recargamos el registro de segmento de código usando CS::set_reg y cargamos la TSS usando load_tss. Las funciones están marcadas como unsafe, así que necesitamos un bloque unsafe para invocarlas. La razón es que podría ser posible romper la seguridad de la memoria al cargar selectores inválidos.
Ahora que hemos cargado una TSS válida y una tabla de pila de interrupciones, podemos establecer el índice de pila para nuestro controlador de doble fallo en la IDT:
// en src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // nuevo
}
idt
};
}
El método set_stack_index es inseguro porque el llamador debe asegurarse de que el índice utilizado es válido y no ya está usado para otra excepción.
¡Eso es todo! Ahora la CPU debería cambiar a la pila de doble fallo cada vez que ocurra un doble fallo. Así que podemos capturar todos los dobles fallos, incluidos los desbordamientos de pila del núcleo:
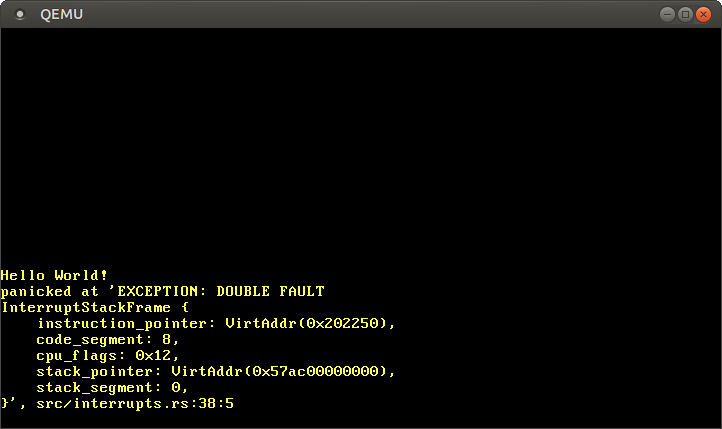
A partir de ahora, ¡no deberíamos ver un fallo triple nuevamente! Para asegurar que no rompamos accidentalmente lo anterior, deberíamos agregar una prueba para esto.
🔗Una Prueba de Desbordamiento de Pila
Para probar nuestro nuevo módulo gdt y asegurarnos de que el controlador de doble fallo se llama correctamente en un desbordamiento de pila, podemos agregar una prueba de integración. La idea es provocar un doble fallo en la función de prueba y verificar que se llama al controlador de doble fallo.
Comencemos con un esqueleto mínimo:
// en tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[no_mangle]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
Al igual que nuestra prueba de panic_handler, la prueba se ejecutará sin un arnés de prueba. La razón es que no podemos continuar la ejecución después de un doble fallo, así que más de una prueba no tiene sentido. Para desactivar el arnés de prueba para la prueba, agregamos lo siguiente a nuestro Cargo.toml:
# en Cargo.toml
[[test]]
name = "stack_overflow"
harness = false
Ahora cargo test --test stack_overflow debería compilar con éxito. La prueba falla, por supuesto, ya que el macro unimplemented provoca un pánico.
🔗Implementando _start
La implementación de la función _start se ve así:
// en tests/stack_overflow.rs
use blog_os::serial_print;
#[no_mangle]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// provocar un desbordamiento de pila
stack_overflow();
panic!("La ejecución continuó después del desbordamiento de pila");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // por cada recursión, la dirección de retorno es empujada
volatile::Volatile::new(0).read(); // prevenir optimizaciones de recursión de cola
}
Llamamos a nuestra función gdt::init para inicializar una nueva GDT. En lugar de llamar a nuestra función interrupts::init_idt, llamamos a una función init_test_idt que se explicará en un momento. La función stack_overflow es casi idéntica a la función en nuestro main.rs. La única diferencia es que al final de la función, realizamos una lectura volátil adicional usando el tipo Volatile para prevenir una optimización del compilador llamada eliminación de llamadas de cola. Entre otras cosas, esta optimización permite al compilador transformar una función cuya última declaración es una llamada recursiva a una normal. Por lo tanto, no se crea un marco de pila adicional para la llamada a la función, así que el uso de la pila permanece constante.
En nuestro caso, sin embargo, queremos que el desbordamiento de pila ocurra, así que agregamos una declaración de lectura volátil ficticia al final de la función, que el compilador no puede eliminar. Por lo tanto, la función ya no es tail recursive, y se previene la transformación en un bucle. También agregamos el atributo allow(unconditional_recursion) para silenciar la advertencia del compilador de que la función recurre sin fin.
🔗La IDT de Prueba
Como se mencionó anteriormente, la prueba necesita su propia IDT con un controlador de doble fallo personalizado. La implementación se ve así:
// en tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}
La implementación es muy similar a nuestra IDT normal en interrupts.rs. Al igual que en la IDT normal, establecemos un índice de pila en la IST para el controlador de doble fallo con el fin de cambiar a una pila separada. La función init_test_idt carga la IDT en la CPU a través del método load.
🔗El Controlador de Doble Fallo
La única pieza que falta es nuestro controlador de doble fallo. Se ve así:
// en tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
Cuando se llama al controlador de doble fallo, salimos de QEMU con un código de salida de éxito, lo que marca la prueba como pasada. Dado que las pruebas de integración son ejecutables completamente separadas, necesitamos establecer el atributo #![feature(abi_x86_interrupt)] nuevamente en la parte superior de nuestro archivo de prueba.
Ahora podemos ejecutar nuestra prueba a través de cargo test --test stack_overflow (o cargo test para ejecutar todas las pruebas). Como era de esperar, vemos la salida de stack_overflow... [ok] en la consola. Intenta comentar la línea set_stack_index; debería hacer que la prueba falle.
🔗Resumen
En esta publicación, aprendimos qué es un doble fallo y bajo qué condiciones ocurre. Agregamos un controlador básico de doble fallo que imprime un mensaje de error y añadimos una prueba de integración para ello.
También habilitamos el cambio de pila soportado por hardware en excepciones de doble fallo para que también funcione en desbordamientos de pila. Mientras lo implementábamos, aprendimos sobre el segmento de estado de tarea (TSS), la tabla de pila de interrupciones (IST) que contiene, y la tabla global de descriptores (GDT), que se usaba para segmentación en arquitecturas anteriores.
🔗¿Qué sigue?
La próxima publicación explica cómo manejar interrupciones de dispositivos externos como temporizadores, teclados o controladores de red. Estas interrupciones de hardware son muy similares a las excepciones, por ejemplo, también se despachan a través de la IDT. Sin embargo, a diferencia de las excepciones, no surgen directamente en la CPU. En su lugar, un controlador de interrupciones agrega estas interrupciones y las reenvía a la CPU según su prioridad. En la próxima publicación, exploraremos el Intel 8259 (“PIC”) controlador de interrupciones y aprenderemos cómo implementar soporte para teclado.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.