Excepciones de CPU
Contenido Traducido: Esta es una traducción comunitaria del post CPU Exceptions. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
Las excepciones de CPU ocurren en diversas situaciones erróneas, por ejemplo, al acceder a una dirección de memoria inválida o al dividir por cero. Para reaccionar ante ellas, tenemos que configurar una tabla de descriptores de interrupción (IDT, por sus siglas en inglés) que proporcione funciones manejadoras. Al final de esta publicación, nuestro núcleo será capaz de capturar excepciones de punto de interrupción y reanudar la ejecución normal después.
Este blog se desarrolla abiertamente en GitHub. Si tiene algún problema o pregunta, por favor abra un problema allí. También puede dejar comentarios al final. El código fuente completo de esta publicación se puede encontrar en la rama post-05.
Tabla de Contenidos
🔗Descripción general
Una excepción indica que algo está mal con la instrucción actual. Por ejemplo, la CPU emite una excepción si la instrucción actual intenta dividir por 0. Cuando se produce una excepción, la CPU interrumpe su trabajo actual y llama inmediatamente a una función manejadora de excepciones específica, dependiendo del tipo de excepción.
En x86, hay alrededor de 20 tipos diferentes de excepciones de CPU. Las más importantes son:
- Fallo de página: Un fallo de página ocurre en accesos a memoria ilegales. Por ejemplo, si la instrucción actual intenta leer de una página no mapeada o intenta escribir en una página de solo lectura.
- Código de operación inválido: Esta excepción ocurre cuando la instrucción actual es inválida, por ejemplo, cuando intentamos usar nuevas instrucciones SSE en una CPU antigua que no las soporta.
- Fallo de protección general: Esta es la excepción con el rango más amplio de causas. Ocurre en varios tipos de violaciones de acceso, como intentar ejecutar una instrucción privilegiada en código de nivel de usuario o escribir en campos reservados en registros de configuración.
- Doble fallo: Cuando ocurre una excepción, la CPU intenta llamar a la función manejadora correspondiente. Si ocurre otra excepción mientras se llama a la función manejadora de excepciones, la CPU genera una excepción de doble fallo. Esta excepción también ocurre cuando no hay una función manejadora registrada para una excepción.
- Triple fallo: Si ocurre una excepción mientras la CPU intenta llamar a la función manejadora de doble fallo, emite un triple fallo fatal. No podemos capturar o manejar un triple fallo. La mayoría de los procesadores reaccionan reiniciándose y reiniciando el sistema operativo.
Para ver la lista completa de excepciones, consulte la wiki de OSDev.
🔗La tabla de descriptores de interrupción
Para poder capturar y manejar excepciones, tenemos que configurar una llamada tabla de descriptores de interrupción (IDT). En esta tabla, podemos especificar una función manejadora para cada excepción de CPU. El hardware utiliza esta tabla directamente, por lo que necesitamos seguir un formato predefinido. Cada entrada debe tener la siguiente estructura de 16 bytes:
| Tipo | Nombre | Descripción |
|---|---|---|
| u16 | Puntero a función [0:15] | Los bits más bajos del puntero a la función manejadora. |
| u16 | Selector GDT | Selector de un segmento de código en la tabla de descriptores global. |
| u16 | Opciones | (ver abajo) |
| u16 | Puntero a función [16:31] | Los bits del medio del puntero a la función manejadora. |
| u32 | Puntero a función [32:63] | Los bits restantes del puntero a la función manejadora. |
| u32 | Reservado |
El campo de opciones tiene el siguiente formato:
| Bits | Nombre | Descripción |
|---|---|---|
| 0-2 | Índice de tabla de pila de interrupción | 0: No cambiar pilas, 1-7: Cambiar a la n-ésima pila en la Tabla de Pila de Interrupción cuando se llama a este manejador. |
| 3-7 | Reservado | |
| 8 | 0: Puerta de interrupción, 1: Puerta de trampa | Si este bit es 0, las interrupciones están deshabilitadas cuando se llama a este manejador. |
| 9-11 | debe ser uno | |
| 12 | debe ser cero | |
| 13‑14 | Nivel de privilegio del descriptor (DPL) | El nivel mínimo de privilegio requerido para llamar a este manejador. |
| 15 | Presente |
Cada excepción tiene un índice de IDT predefinido. Por ejemplo, la excepción de código de operación inválido tiene índice de tabla 6 y la excepción de fallo de página tiene índice de tabla 14. Así, el hardware puede cargar automáticamente la entrada de IDT correspondiente para cada excepción. La Tabla de Excepciones en la wiki de OSDev muestra los índices de IDT de todas las excepciones en la columna “Vector nr.”.
Cuando ocurre una excepción, la CPU realiza aproximadamente lo siguiente:
- Empuja algunos registros en la pila, incluyendo el puntero de instrucción y el registro RFLAGS. (Usaremos estos valores más adelante en esta publicación.)
- Lee la entrada correspondiente de la tabla de descriptores de interrupción (IDT). Por ejemplo, la CPU lee la 14ª entrada cuando ocurre un fallo de página.
- Verifica si la entrada está presente y, si no, genera un doble fallo.
- Deshabilita las interrupciones de hardware si la entrada es una puerta de interrupción (bit 40 no establecido).
- Carga el selector GDT especificado en el CS (segmento de código).
- Salta a la función manejadora especificada.
No se preocupe por los pasos 4 y 5 por ahora; aprenderemos sobre la tabla de descriptores global y las interrupciones de hardware en publicaciones futuras.
🔗Un tipo de IDT
En lugar de crear nuestro propio tipo de IDT, utilizaremos la estructura InterruptDescriptorTable del crate x86_64, que luce así:
#[repr(C)]
pub struct InterruptDescriptorTable {
pub divide_by_zero: Entry<HandlerFunc>,
pub debug: Entry<HandlerFunc>,
pub non_maskable_interrupt: Entry<HandlerFunc>,
pub breakpoint: Entry<HandlerFunc>,
pub overflow: Entry<HandlerFunc>,
pub bound_range_exceeded: Entry<HandlerFunc>,
pub invalid_opcode: Entry<HandlerFunc>,
pub device_not_available: Entry<HandlerFunc>,
pub double_fault: Entry<HandlerFuncWithErrCode>,
pub invalid_tss: Entry<HandlerFuncWithErrCode>,
pub segment_not_present: Entry<HandlerFuncWithErrCode>,
pub stack_segment_fault: Entry<HandlerFuncWithErrCode>,
pub general_protection_fault: Entry<HandlerFuncWithErrCode>,
pub page_fault: Entry<PageFaultHandlerFunc>,
pub x87_floating_point: Entry<HandlerFunc>,
pub alignment_check: Entry<HandlerFuncWithErrCode>,
pub machine_check: Entry<HandlerFunc>,
pub simd_floating_point: Entry<HandlerFunc>,
pub virtualization: Entry<HandlerFunc>,
pub security_exception: Entry<HandlerFuncWithErrCode>,
// algunos campos omitidos
}
Los campos tienen el tipo idt::Entry<F>, que es una estructura que representa los campos de una entrada de IDT (ver tabla anterior). El parámetro de tipo F define el tipo esperado de la función manejadora. Vemos que algunas entradas requieren un HandlerFunc y algunas entradas requieren un HandlerFuncWithErrCode. El fallo de página incluso tiene su propio tipo especial: PageFaultHandlerFunc.
Veamos primero el tipo HandlerFunc:
type HandlerFunc = extern "x86-interrupt" fn(_: InterruptStackFrame);
Es un alias de tipo para un tipo de extern "x86-interrupt" fn. La palabra clave extern define una función con una convención de llamada foránea y se utiliza a menudo para comunicarse con código C (extern "C" fn). Pero, ¿cuál es la convención de llamada x86-interrupt?
🔗La convención de llamada de interrupción
Las excepciones son bastante similares a las llamadas a funciones: la CPU salta a la primera instrucción de la función llamada y la ejecuta. Después, la CPU salta a la dirección de retorno y continúa la ejecución de la función madre.
Sin embargo, hay una gran diferencia entre excepciones y llamadas a funciones: una llamada a función es invocada voluntariamente por una instrucción call insertada por el compilador, mientras que una excepción puede ocurrir en cualquier instrucción. Para entender las consecuencias de esta diferencia, necesitamos examinar las llamadas a funciones en más detalle.
Convenciones de llamada especifican los detalles de una llamada a función. Por ejemplo, especifican dónde se colocan los parámetros de la función (por ejemplo, en registros o en la pila) y cómo se devuelven los resultados. En x86_64 Linux, se aplican las siguientes reglas para funciones C (especificadas en el ABI de System V):
- los primeros seis argumentos enteros se pasan en los registros
rdi,rsi,rdx,rcx,r8,r9 - argumentos adicionales se pasan en la pila
- los resultados se devuelven en
raxyrdx
Tenga en cuenta que Rust no sigue el ABI de C (de hecho, ni siquiera hay un ABI de Rust todavía), por lo que estas reglas solo se aplican a funciones declaradas como extern "C" fn.
🔗Registros preservados y de uso
La convención de llamada divide los registros en dos partes: registros preservados y registros de uso.
Los valores de los registros preservados deben permanecer sin cambios a través de llamadas a funciones. Por lo tanto, una función llamada (la “llamada”) solo puede sobrescribir estos registros si restaura sus valores originales antes de retornar. Por ello, estos registros se llaman “guardados por el llamado”. Un patrón común es guardar estos registros en la pila al inicio de la función y restaurarlos justo antes de retornar.
En contraste, una función llamada puede sobrescribir registros de uso sin restricciones. Si el llamador quiere preservar el valor de un registro de uso a través de una llamada a función, necesita respaldarlo y restaurarlo antes de la llamada a la función (por ejemplo, empujándolo a la pila). Así, los registros de uso son guardados por el llamador.
En x86_64, la convención de llamada C especifica los siguientes registros preservados y de uso:
| registros preservados | registros de uso |
|---|---|
rbp, rbx, rsp, r12, r13, r14, r15 | rax, rcx, rdx, rsi, rdi, r8, r9, r10, r11 |
| guardados por el llamado | guardados por el llamador |
El compilador conoce estas reglas, por lo que genera el código en consecuencia. Por ejemplo, la mayoría de las funciones comienzan con un push rbp, que respalda rbp en la pila (porque es un registro guardado por el llamado).
🔗Preservando todos los registros
A diferencia de las llamadas a funciones, las excepciones pueden ocurrir en cualquier instrucción. En la mayoría de los casos, ni siquiera sabemos en tiempo de compilación si el código generado causará una excepción. Por ejemplo, el compilador no puede saber si una instrucción provoca un desbordamiento de pila o un fallo de página.
Dado que no sabemos cuándo ocurrirá una excepción, no podemos respaldar ningún registro antes. Esto significa que no podemos usar una convención de llamada que dependa de registros guardados por el llamador para los manejadores de excepciones. En su lugar, necesitamos una convención de llamada que preserve todos los registros. La convención de llamada x86-interrupt es una de esas convenciones, por lo que garantiza que todos los valores de los registros se restauren a sus valores originales al retornar de la función.
Tenga en cuenta que esto no significa que todos los registros se guarden en la pila al ingresar la función. En su lugar, el compilador solo respalda los registros que son sobrescritos por la función. De esta manera, se puede generar un código muy eficiente para funciones cortas que solo utilizan unos pocos registros.
🔗El marco de pila de interrupción
En una llamada a función normal (usando la instrucción call), la CPU empuja la dirección de retorno antes de saltar a la función objetivo. Al retornar de la función (usando la instrucción ret), la CPU extrae esta dirección de retorno y salta a ella. Por lo tanto, el marco de pila de una llamada a función normal se ve así:

Sin embargo, para los manejadores de excepciones e interrupciones, empujar una dirección de retorno no sería suficiente, ya que los manejadores de interrupción a menudo se ejecutan en un contexto diferente (puntero de pila, flags de CPU, etc.). En cambio, la CPU realiza los siguientes pasos cuando ocurre una interrupción:
- Guardando el antiguo puntero de pila: La CPU lee los valores del puntero de pila (
rsp) y del registro del segmento de pila (ss) y los recuerda en un búfer interno. - Alineando el puntero de pila: Una interrupción puede ocurrir en cualquier instrucción, por lo que el puntero de pila también puede tener cualquier valor. Sin embargo, algunas instrucciones de CPU (por ejemplo, algunas instrucciones SSE) requieren que el puntero de pila esté alineado en un límite de 16 bytes, por lo que la CPU realiza tal alineación inmediatamente después de la interrupción.
- Cambiando de pilas (en algunos casos): Se produce un cambio de pila cuando cambia el nivel de privilegio de la CPU, por ejemplo, cuando ocurre una excepción de CPU en un programa en modo usuario. También es posible configurar los cambios de pila para interrupciones específicas utilizando la llamada Tabla de Pila de Interrupción (descrita en la próxima publicación).
- Empujando el antiguo puntero de pila: La CPU empuja los valores
rspyssdel paso 0 a la pila. Esto hace posible restaurar el puntero de pila original al retornar de un manejador de interrupción. - Empujando y actualizando el registro
RFLAGS: El registroRFLAGScontiene varios bits de control y estado. Al entrar en la interrupción, la CPU cambia algunos bits y empuja el antiguo valor. - Empujando el puntero de instrucción: Antes de saltar a la función manejadora de la interrupción, la CPU empuja el puntero de instrucción (
rip) y el segmento de código (cs). Esto es comparable al empuje de la dirección de retorno de una llamada a función normal. - Empujando un código de error (para algunas excepciones): Para algunas excepciones específicas, como los fallos de página, la CPU empuja un código de error, que describe la causa de la excepción.
- Invocando el manejador de interrupción: La CPU lee la dirección y el descriptor de segmento de la función manejadora de interrupción del campo correspondiente en la IDT. Luego, invoca este manejador cargando los valores en los registros
ripycs.
Así, el marco de pila de interrupción se ve así:

En el crate x86_64, el marco de pila de interrupción está representado por la estructura InterruptStackFrame. Se pasa a los manejadores de interrupción como &mut y se puede utilizar para recuperar información adicional sobre la causa de la excepción. La estructura no contiene un campo de código de error, ya que solo algunas pocas excepciones empujan un código de error. Estas excepciones utilizan el tipo de función separado HandlerFuncWithErrCode, que tiene un argumento adicional error_code.
🔗Detrás de las escenas
La convención de llamada x86-interrupt es una potente abstracción que oculta casi todos los detalles desordenados del proceso de manejo de excepciones. Sin embargo, a veces es útil saber lo que sucede tras el telón. Aquí hay un breve resumen de las cosas que la convención de llamada x86-interrupt maneja:
- Recuperando los argumentos: La mayoría de las convenciones de llamada esperan que los argumentos se pasen en registros. Esto no es posible para los manejadores de excepciones, ya que no debemos sobrescribir los valores de ningún registro antes de respaldarlos en la pila. En cambio, la convención de llamada
x86-interruptes consciente de que los argumentos ya están en la pila en un desplazamiento específico. - Retornando usando
iretq: Dado que el marco de pila de interrupción difiere completamente de los marcos de pila de llamadas a funciones normales, no podemos retornar de las funciones manejadoras a través de la instrucciónretnormal. Así que en su lugar, se debe usar la instruccióniretq. - Manejando el código de error: El código de error, que se empuja para algunas excepciones, hace que las cosas sean mucho más complejas. Cambia la alineación de la pila (vea el siguiente punto) y debe ser extraído de la pila antes de retornar. La convención de llamada
x86-interruptmaneja toda esa complejidad. Sin embargo, no sabe qué función manejadora se utiliza para qué excepción, por lo que necesita deducir esa información del número de argumentos de función. Esto significa que el programador sigue siendo responsable de utilizar el tipo de función correcto para cada excepción. Afortunadamente, el tipoInterruptDescriptorTabledefinido por el cratex86_64asegura que se utilicen los tipos de función correctos. - Alineando la pila: Algunas instrucciones (especialmente las instrucciones SSE) requieren que la pila esté alineada a 16 bytes. La CPU asegura esta alineación cada vez que ocurre una excepción, pero para algunas excepciones, puede destruirla de nuevo más tarde cuando empuja un código de error. La convención de llamada
x86-interruptse encarga de esto al realinear la pila en este caso.
Si está interesado en más detalles, también tenemos una serie de publicaciones que explican el manejo de excepciones utilizando funciones desnudas vinculadas al final de esta publicación.
🔗Implementación
Ahora que hemos entendido la teoría, es hora de manejar las excepciones de CPU en nuestro núcleo. Comenzaremos creando un nuevo módulo de interrupciones en src/interrupts.rs, que primero crea una función init_idt que crea una nueva InterruptDescriptorTable:
// en src/lib.rs
pub mod interrupts;
// en src/interrupts.rs
use x86_64::structures::idt::InterruptDescriptorTable;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
}
Ahora podemos agregar funciones manejadoras. Comenzamos agregando un manejador para la excepción de punto de interrupción. La excepción de punto de interrupción es la excepción perfecta para probar el manejo de excepciones. Su único propósito es pausar temporalmente un programa cuando se ejecuta la instrucción de punto de interrupción int3.
La excepción de punto de interrupción se utiliza comúnmente en depuradores: cuando el usuario establece un punto de interrupción, el depurador sobrescribe la instrucción correspondiente con la instrucción int3 para que la CPU lance la excepción de punto de interrupción al llegar a esa línea. Cuando el usuario quiere continuar el programa, el depurador reemplaza la instrucción int3 con la instrucción original nuevamente y continúa el programa. Para más detalles, vea la serie “Cómo funcionan los depuradores”.
Para nuestro caso de uso, no necesitamos sobrescribir instrucciones. En su lugar, solo queremos imprimir un mensaje cuando la instrucción de punto de interrupción se ejecute y luego continuar el programa. Así que creemos una simple función breakpoint_handler y la agreguemos a nuestra IDT:
// en src/interrupts.rs
use x86_64::structures::idt::{InterruptDescriptorTable, InterruptStackFrame};
use crate::println;
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
}
extern "x86-interrupt" fn breakpoint_handler(
stack_frame: InterruptStackFrame)
{
println!("EXCEPCIÓN: PUNTO DE INTERRUPCIÓN\n{:#?}", stack_frame);
}
Nuestro manejador simplemente muestra un mensaje y imprime en formato bonito el marco de pila de interrupción.
Cuando intentamos compilarlo, ocurre el siguiente error:
error[E0658]: la ABI de x86-interrupt es experimental y está sujeta a cambios (ver issue #40180)
--> src/main.rs:53:1
|
53 | / extern "x86-interrupt" fn breakpoint_handler(stack_frame: InterruptStackFrame) {
54 | | println!("EXCEPCIÓN: PUNTO DE INTERRUPCIÓN\n{:#?}", stack_frame);
55 | | }
| |_^
|
= ayuda: añade #![feature(abi_x86_interrupt)] a los atributos del crate para habilitarlo
Este error ocurre porque la convención de llamada x86-interrupt sigue siendo inestable. Para utilizarla de todos modos, tenemos que habilitarla explícitamente añadiendo #![feature(abi_x86_interrupt)] en la parte superior de nuestro lib.rs.
🔗Cargando la IDT
Para que la CPU utilice nuestra nueva tabla de descriptores de interrupción, necesitamos cargarla usando la instrucción lidt. La estructura InterruptDescriptorTable del crate x86_64 proporciona un método load para eso. Intentemos usarlo:
// en src/interrupts.rs
pub fn init_idt() {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.load();
}
Cuando intentamos compilarlo ahora, ocurre el siguiente error:
error: `idt` no vive lo suficiente
--> src/interrupts/mod.rs:43:5
|
43 | idt.load();
| ^^^ no vive lo suficiente
44 | }
| - el valor prestado solo es válido hasta aquí
|
= nota: el valor prestado debe ser válido durante la vida estática...
Así que el método load espera un &'static self, es decir, una referencia válida para la duración completa del programa. La razón es que la CPU accederá a esta tabla en cada interrupción hasta que se cargue una IDT diferente. Por lo tanto, usar una vida más corta que 'static podría llevar a errores de uso después de liberar.
De hecho, esto es exactamente lo que sucede aquí. Nuestra idt se crea en la pila, por lo que solo es válida dentro de la función init. Después, la memoria de la pila se reutiliza para otras funciones, por lo que la CPU podría interpretar una memoria aleatoria de la pila como IDT. Afortunadamente, el método load de InterruptDescriptorTable codifica este requisito de vida en su definición de función, para que el compilador de Rust pueda prevenir este posible error en tiempo de compilación.
Para solucionar este problema, necesitamos almacenar nuestra idt en un lugar donde tenga una vida 'static. Para lograr esto, podríamos asignar nuestra IDT en el montón usando Box y luego convertirla en una referencia 'static, pero estamos escribiendo un núcleo de sistema operativo y, por lo tanto, no tenemos un montón (todavía).
Como alternativa, podríamos intentar almacenar la IDT como una static:
static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
Sin embargo, hay un problema: las estáticas son inmutables, por lo que no podemos modificar la entrada de punto de interrupción desde nuestra función init. Podríamos resolver este problema utilizando un static mut:
static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new();
pub fn init_idt() {
unsafe {
IDT.breakpoint.set_handler_fn(breakpoint_handler);
IDT.load();
}
}
Esta variante se compila sin errores, pero está lejos de ser idiomática. Las variables static mut son muy propensas a condiciones de carrera, por lo que necesitamos un bloque unsafe en cada acceso.
🔗Las estáticas perezosas al rescate
Afortunadamente, existe el macro lazy_static. En lugar de evaluar una static en tiempo de compilación, el macro realiza la inicialización de cuando la static es referenciada por primera vez. Por lo tanto, podemos hacer casi todo en el bloque de inicialización e incluso ser capaces de leer valores en tiempo de ejecución.
Ya importamos el crate lazy_static cuando creamos una abstracción para el búfer de texto VGA. Así que podemos utilizar directamente el macro lazy_static! para crear nuestra IDT estática:
// en src/interrupts.rs
use lazy_static::lazy_static;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt
};
}
pub fn init_idt() {
IDT.load();
}
Tenga en cuenta cómo esta solución no requiere bloques unsafe. El macro lazy_static! utiliza unsafe detrás de escena, pero está abstraído en una interfaz segura.
🔗Ejecutándolo
El último paso para hacer que las excepciones funcionen en nuestro núcleo es llamar a la función init_idt desde nuestro main.rs. En lugar de llamarla directamente, introducimos una función de inicialización general en nuestro lib.rs:
// en src/lib.rs
pub fn init() {
interrupts::init_idt();
}
Con esta función, ahora tenemos un lugar central para las rutinas de inicialización que se pueden compartir entre las diferentes funciones _start en nuestro main.rs, lib.rs y pruebas de integración.
Ahora podemos actualizar la función _start de nuestro main.rs para llamar a init y luego activar una excepción de punto de interrupción:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("¡Hola Mundo{}", "!");
blog_os::init(); // nueva
// invocar una excepción de punto de interrupción
x86_64::instructions::interrupts::int3(); // nueva
// como antes
#[cfg(test)]
test_main();
println!("¡No se bloqueó!");
loop {}
}
Cuando lo ejecutamos en QEMU ahora (usando cargo run), vemos lo siguiente:
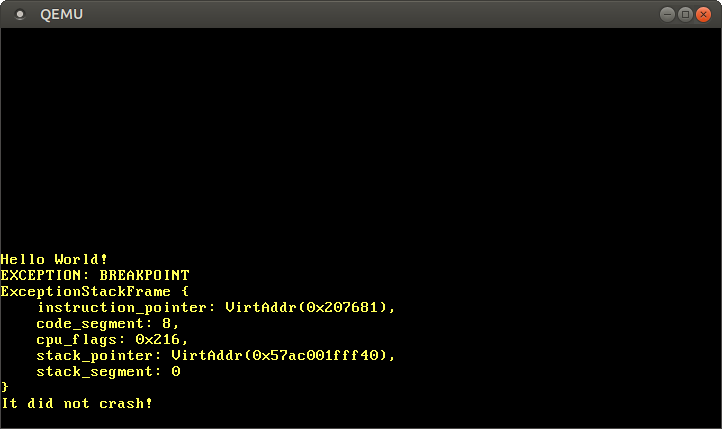
¡Funciona! La CPU invoca exitosamente nuestro manejador de punto de interrupción, que imprime el mensaje, y luego devuelve a la función _start, donde se imprime el mensaje ¡No se bloqueó!.
Vemos que el marco de pila de interrupción nos indica los punteros de instrucción y de pila en el momento en que ocurrió la excepción. Esta información es muy útil al depurar excepciones inesperadas.
🔗Agregando una prueba
Creemos una prueba que asegure que lo anterior sigue funcionando. Primero, actualizamos la función _start para que también llame a init:
// en src/lib.rs
/// Punto de entrada para `cargo test`
#[cfg(test)]
#[no_mangle]
pub extern "C" fn _start() -> ! {
init(); // nueva
test_main();
loop {}
}
Recuerde, esta función _start se utiliza al ejecutar cargo test --lib, ya que Rust prueba el lib.rs completamente de forma independiente de main.rs. Necesitamos llamar a init aquí para configurar una IDT antes de ejecutar las pruebas.
Ahora podemos crear una prueba test_breakpoint_exception:
// en src/interrupts.rs
#[test_case]
fn test_breakpoint_exception() {
// invocar una excepción de punto de interrupción
x86_64::instructions::interrupts::int3();
}
La prueba invoca la función int3 para activar una excepción de punto de interrupción. Al verificar que la ejecución continúa después, verificamos que nuestro manejador de punto de interrupción está funcionando correctamente.
Puedes probar esta nueva prueba ejecutando cargo test (todas las pruebas) o cargo test --lib (solo las pruebas de lib.rs y sus módulos). Deberías ver lo siguiente en la salida:
blog_os::interrupts::test_breakpoint_exception... [ok]
🔗¿Demasiada magia?
La convención de llamada x86-interrupt y el tipo InterruptDescriptorTable hicieron que el proceso de manejo de excepciones fuera relativamente sencillo y sin dolor. Si esto fue demasiada magia para ti y te gusta aprender todos los detalles sucios del manejo de excepciones, tenemos cubiertos: Nuestra serie “Manejo de Excepciones con Funciones Desnudas” muestra cómo manejar excepciones sin la convención de llamada x86-interrupt y también crea su propio tipo de IDT. Históricamente, estas publicaciones eran las principales publicaciones sobre manejo de excepciones antes de que existieran la convención de llamada x86-interrupt y el crate x86_64. Tenga en cuenta que estas publicaciones se basan en la primera edición de este blog y pueden estar desactualizadas.
🔗¿Qué sigue?
¡Hemos capturado con éxito nuestra primera excepción y regresamos de ella! El siguiente paso es asegurarnos de que capturamos todas las excepciones porque una excepción no capturada causa un triple fallo fatal, lo que lleva a un reinicio del sistema. La próxima publicación explica cómo podemos evitar esto al capturar correctamente dobles fallos.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.