الأخطاء المزدوجة
المحتوى المترجم: هذه ترجمة مجتمعية لمقالة Double Faults. قد تكون غير مكتملة أو قديمة أو تحتوي على أخطاء. يرجى الإبلاغ عن أي مشاكل!
ترجمة بواسطة @mindfreq.
يستكشف هذا المقال double fault exception بالتفصيل، التي تحدث عندما تفشل وحدة المعالجة المركزية في استدعاء exception handler. بمعالجة هذه exception، نتجنب triple faults القاتلة التي تسبب إعادة ضبط النظام. لمنع الأخطاء الثلاثية (triple faults) في جميع الحالات، نُعدّ أيضًا Interrupt Stack Table لالتقاط double faults على kernel stack منفصل.
هذا المدونة مطوّرة بشكل مفتوح على GitHub. إذا كان لديك أي مشاكل أو أسئلة، يرجى فتح issue هناك. يمكنك أيضًا ترك تعليقات في الأسفل. يمكن العثور على الكود المصدري الكامل لهذا المقال في فرع post-06.
جدول المحتويات
🔗ما هو الـ Double Fault؟
بشكل مبسط، الـ double fault هو استثناء خاص تحدث عندما تفشل وحدة المعالجة المركزية في استدعاء exception handler. على سبيل المثال، تحدث عندما يُثار page fault لكن لا يوجد page fault handler مسجل في Interrupt Descriptor Table (IDT). لذلك هي مشابهة نوعًا ما لـ catch-all blocks في لغات البرمجة مع exceptions، مثل catch(...) في C++ أو catch(Exception e) في Java أو C#.
تتصرف double fault مثل exception عادية. لها vector number 8 ويمكننا تحديد دالة معالجة عادية لها في IDT. من المهم جدًا توفير double fault handler، لأن إذا كانت double fault غير مُعالجة، تحدث triple fault قاتلة. لا يمكن التقاط triple faults، و تتفاعل معظم الأجهزة بإعادة ضبط النظام.
🔗إثارة Double Fault
لنثير double fault بإثارة exception لم نحدد لها دالة معالجة:
// in src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// trigger a page fault
unsafe {
*(0xdeadbeef as *mut u8) = 42;
};
// as before
#[cfg(test)]
test_main();
println!("It did not crash!");
loop {}
}
نستخدم unsafe للكتابة إلى العنوان غير الصالح 0xdeadbeef. العنوان الافتراضي غير مُعيّن إلى عنوان فيزيائي في page tables، لذلك تحدث page fault. لم نسجل page fault handler في IDT، لذلك تحدث double fault.
عندما نشغّل نواتنا الآن، نرى أنها تدخل في boot loop غير محدود. سبب boot loop هو ما يلي:
- يحاول وحدة المعالجة المركزية الكتابة إلى
0xdeadbeef، الذي يسبب page fault. - تنظر وحدة المعالجة المركزية إلى المدخل (entry) المقابل في IDT ويرى أنه لا توجد دالة معالجة محددة. لذلك، لا يمكنها استدعاء معالج page fault وتُثار double fault.
- ينظر وحدة المعالجة مركزية إلى IDT entry لـ double fault handler، لكن هذا entry لا يحدد دالة معالجة أيضًا. لذلك، تُثار triple fault.
- الـ triple fault خطأ قاتل. يتفاعل QEMU مثل معظم الأجهزة الحقيقية ويصدر إعادة ضبط النظام.
لمنع هذه triple fault، نحتاج إلى توفير دالة معالجة لـ page faults أو double fault handler. نريد تجنب triple faults في جميع الحالات، لذلك لنبدأ بـ double fault handler يُستدعى لجميع أنواع exceptions غير المُعالجة.
🔗معالج Double Fault
double fault هي exception عادية مع error code، لذلك يمكننا تحديد دالة معالجة مشابهة لـ breakpoint handler:
// in src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
idt.double_fault.set_handler_fn(double_fault_handler); // new
idt
};
}
// new
extern "x86-interrupt" fn double_fault_handler(
stack_frame: InterruptStackFrame, _error_code: u64) -> !
{
panic!("EXCEPTION: DOUBLE FAULT\n{:#?}", stack_frame);
}
المعالج يطبع رسالة خطأ قصيرة ويدرج interrupt stack frame. error code لـ double fault handler دائمًا صفر، لذلك لا يوجد سبب لطباعته. فرق واحد مقارنة بـ breakpoint handler هو أن double fault handler diverging. السبب هو أن معمارية x86_64 لا تسمح بالعودة من double fault exception.
عندما نشغّل نواتنا الآن، يجب أن نرى أن double fault handler يُستدعى:
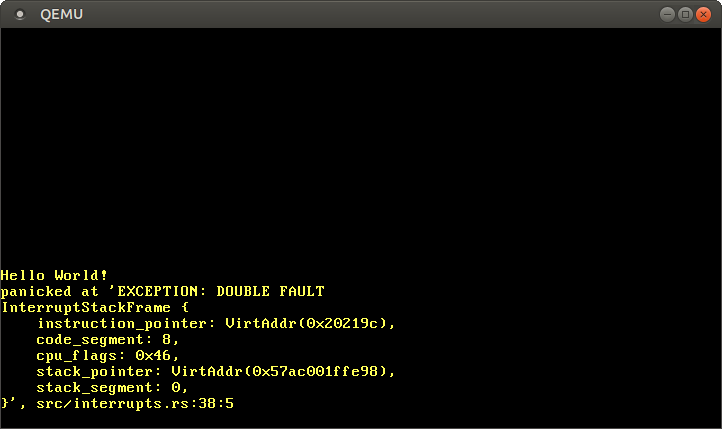
لقد نجح! إليك ما حدث هذه المرة:
- يحاول وحدة المعالجة المركزية الكتابة إلى
0xdeadbeef، الذي يسبب page fault. - مثل قبل، تنظر وحدة المعالجة المركزية إلى المدخل (entry) المقابل في IDT ويرى أنه لا توجد دالة معالجة محددة. لذلك، تُثار double fault.
- يقفز وحدة المعالجة مركزية إلى double fault handler – الموجودة الآن.
لم تعد triple fault (و boot-loop) تحدث، لأن وحدة المعالجة المركزية يمكنها الآن استدعاء double fault handler.
كان ذلك مباشرًا! فلماذا نحتاج إلى مقال كامل لهذا الموضوع؟ حسنًا، نحن الآن قادرون على التقاط معظم double faults، لكن هناك بعض الحالات لا يكفي فيها نهجنا الحالي.
🔗أسباب الـ Double Fault
قبل أن ننظر في الحالات الخاصة، نحتاج إلى معرفة الأسباب الدقيقة لـ double faults. أعلاه، استخدمنا تعريفًا غامضًا بعض الشيء:
الـ double fault هو استثناء خاص تحدث عندما تفشل وحدة المعالجة المركزية في استدعاء exception handler.
ماذا تعني “fails to invoke” بالضبط؟ المعالج غير موجود؟ المعالج مُزال من الذاكرة؟ وماذا يحدث إذا تسبب معالج في exceptions بنفسه؟
على سبيل المثال، ماذا يحدث إذا:
- تُثار breakpoint exception، لكن دالة المعالجة المقابلة مُزالة من الذاكرة؟
- تُثار page fault، لكن page fault handler مُزال من الذاكرة؟
- تسبب divide-by-zero handler في breakpoint exception، لكن breakpoint handler مُزال من الذاكرة؟
- تتخطى نواتنا stack وتُضرب guard page؟
لحسن الحظ، يحتوي كتيب AMD64 (PDF) على تعريف دقيق (في القسم 8.2.9). وفقًا له، “double fault exception يمكن أن تحدث عندما تحدث exception ثانية أثناء معالجة prior (first) exception handler”. “can” مهمة: فقط مجموعات محددة جدًا من exceptions تؤدي إلى double fault. هذه المجموعات هي:
على سبيل المثال، divide-by-zero fault يتبعه page fault لا بأس به (يُستدعى page fault handler)، لكن divide-by zero fault يتبعه general-protection fault يؤدي إلى double fault.
بمساعدة هذا الجدول، يمكننا الإجابة على أول ثلاث أسئلة أعلاه:
- إذا تُثير breakpoint exception ودالة المعالجة المقابلة مُزالة من الذاكرة، تُثار page fault ويُستدعى page fault handler.
- إذا تُثير page fault و page fault handler مُزال من الذاكرة، تُثار double fault ويُستدعى double fault handler.
- إذا تسبب divide-by-zero handler في breakpoint exception، يحاول وحدة المعالجة المركزية استدعاء breakpoint handler. إذا كان breakpoint handler مُزالًا من الذاكرة، تُثار page fault ويُستدعى page fault handler.
في الواقع، حتى حالة exception بدون دالة معالجة في IDT تتبع هذا المخطط: عندما تحدث exception، يحاول وحدة المعالجة المركزية قراءة IDT entry المقابل. بما أن entry هو 0، الذي ليس IDT entry صالحًا، تُثار general protection fault. لم نحدد دالة معالجة لـ general protection fault أيضًا، لذلك تُثار general protection fault أخرى. وفقًا للجدول، يؤدي هذا إلى double fault.
🔗تجاوز سعة Stack النواة
لننظر في السؤال الرابع:
ماذا يحدث إذا تتخطى نواتنا stack وتُضرب guard page؟
guard page هي صفحة ذاكرة خاصة في أسفل stack تجعل من الممكن اكتشاف stack overflows. الصفحة غير مُعيّنة إلى أي frame فيزيائي، لذلك الوصول إليها يسبب page fault بدلاً من تلف ذاكرة أخرى بصمت. يُعدّ bootloader guard page لـ kernel stack، لذلك stack overflow يسبب page fault.
عندما تحدث page fault، ينظر وحدة المعالجة مركزية إلى page fault handler في IDT ويحاول دفع interrupt stack frame onto stack. ومع ذلك، مؤشر Stack الحالي لا يزال يشير إلى guard page الغير موجودة. لذلك، تحدث page fault ثانية، التي تسبب double fault (وفقاً للجدول أعلاه).
لذلك يحاول وحدة المعالجة مركزية استدعاء double fault handler الآن. ومع ذلك، عند double fault، يحاول وحدة المعالجة مركزية دفع exception stack frame أيضًا. مؤشر Stack لا يزال يشير إلى guard page، لذلك تحدث third page fault، التي تسبب triple fault وإعادة إقلاع النظام. لذلك double fault handler الحالي لا يمكنه تجنب triple fault في هذه الحالة.
لنجرّبه بأنفسنا! يمكننا بسهولة إثارة kernel stack overflow باستدعاء دالة تعيد نفسها بلا نهاية:
// in src/main.rs
#[unsafe(no_mangle)] // don't mangle the name of this function
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
}
// trigger a stack overflow
stack_overflow();
[…] // test_main(), println(…), and loop {}
}
عندما نجرب هذا الكود في QEMU، نرى أن النظام يدخل bootloop مرة أخرى.
فكيف نتجنب هذه المشكلة؟ لا يمكننا تجاهل دفع exception stack frame، لأن وحدة المعالجة المركزية نفسها تفعل ذلك. لذلك نحتاج إلى ضمان أن stack صالح دائمًا عندما تحدث double fault exception. لحسن الحظ، معمارية x86_64 لها حل لهذه المشكلة.
🔗تبديل الـ Stacks
معمارية x86_64 قادرة على التبديل إلى stack محدد مسبقًا معروف الجودة عندما تحدث exception. يحدث هذا التبديل على مستوى الجهاز، لذلك يمكن تنفيذه قبل أن يدفع وحدة المعالجة مركزية exception stack frame.
آلية التبديل منفذة كـ Interrupt Stack Table (IST). IST هو جدول من 7 مؤشرات إلى stacks معروفة الجودة. في pseudocode شبيه بـ Rust:
struct InterruptStackTable {
stack_pointers: [Option<StackPointer>; 7],
}
لكل exception handler، يمكننا اختيار stack من IST عبر حقل stack_pointers في IDT entry المقابل. على سبيل المثال، يمكن لـ double fault handler استخدام أول stack في IST. ثم ينتقل وحدة المعالجة المركزية تلقائيًا إلى هذا stack whenever تحدث double fault. هذا التبديل سيحدث قبل أي شيء يُدفع، مانعًا triple fault.
🔗IST و TSS
Interrupt Stack Table (IST) هو جزء من هيكل قديم يسمى Task State Segment (TSS). كان TSS يحمل various pieces of information (مثل حالة سجل المعالج) عن مهمة في وضع 32-bit وكان، على سبيل المثال، يُستخدم لـ hardware context switching. ومع ذلك، لم يعد hardware context switching مدعومًا في وضع 64-bit و تغير تنسيق TSS completely.
على x86_64، لم يعد TSS يحمل أي معلومات خاصة بالمهمة على الإطلاق. بدلاً من ذلك، يحمل جدولين من stacks (IST أحدهما). الحقل المشترك الوحيد بين TSS من 32-bit و 64-bit هو المؤشر إلى I/O port permissions bitmap.
TSS من 64-bit له التنسيق التالي:
| Field | Type |
|---|---|
| (reserved) | u32 |
| Privilege Stack Table | [u64; 3] |
| (reserved) | u64 |
| Interrupt Stack Table | [u64; 7] |
| (reserved) | u64 |
| (reserved) | u16 |
| I/O Map Base Address | u16 |
Privilege Stack Table يُستخدم من قبل وحدة المعالجة المركزية عندما يتغير مستوى الامتياز. على سبيل المثال، إذا تحدث exception بينما وحدة المعالجة المركزية في وضع المستخدم (مستوى الامتياز 3)، ينتقل عادة إلى وضع النواة (مستوى الامتياز 0) قبل استدعاء exception handler. في تلك الحالة، ينتقل وحدة المعالجة مركزية إلى stack رقم 0 في Privilege Stack Table (بما أن 0 هو مستوى الامتياز المستهدف). ليس لدينا أي برامج وضع المستخدم بعد، لذلك سنتجاهل هذا الجدول الآن.
🔗إنشاء TSS
لننشئ TSS جديد يحتوي على double fault stack منفصل في interrupt stack table. لذلك، نحتاج إلى TSS struct. لحسن الحظ، تحتوي مكتبة x86_64 بالفعل على TaskStateSegment struct يمكننا استخدامه.
ننشئ TSS في module gdt جديد (الاسم سيكون له معنى لاحقًا):
// in src/lib.rs
pub mod gdt;
// in src/gdt.rs
use x86_64::VirtAddr;
use x86_64::structures::tss::TaskStateSegment;
use lazy_static::lazy_static;
pub const DOUBLE_FAULT_IST_INDEX: u16 = 0;
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
tss.interrupt_stack_table[DOUBLE_FAULT_IST_INDEX as usize] = {
const STACK_SIZE: usize = 4096 * 5;
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(&raw const STACK);
let stack_end = stack_start + STACK_SIZE;
stack_end
};
tss
};
}
نستخدم lazy_static لأن Rust const evaluator ليس قويًا بما يكفي لفعل هذه التهيئة وقت التجميع. نحدد أن IST entry رقم 0 هو double fault stack (أي فهرس IST آخر سيعمل أيضًا). ثم نكتب عنوان أعلى double fault stack إلى entry رقم 0. نكتب العنوان الأعلى لأن stacks على x86 تنمو نحو الأسفل، أي من عناوين عالية إلى عناوين منخفضة.
لم ننفذ إدارة الذاكرة بعد، لذلك ليس لدينا طريقة مناسبة لتخصيص stack جديد. بدلاً من ذلك، نستخدم مصفوفة static mut كـ stack storage مؤقتًا. من المهم أن تكون static mut وليست static غير قابلة للتغيير، لأن bootloader سيعيّنها إلى صفحة للقراءة فقط بخلاف ذلك. سنستبدل هذا بتخصيص stack مناسب في مقال لاحق.
لاحظ أن هذا double fault stack ليس لديه guard page تحمي من stack overflow. هذا يعني أنه يجب ألا نفعل أي شيء مكثف على stack في double fault handler لأن stack overflow قد يفسد الذاكرة تحت stack.
🔗تحميل TSS
الآن بعد أن أنشأنا TSS جديد، نحتاج إلى طريقة لإخبار وحدة المعالجة المركزية أنه يجب استخدامه. لسوء الحظ، هذا مرهق بعض الشيء لأن TSS يستخدم نظام التجزئة (لأسباب تاريخية). بدلاً من تحميل الجدول مباشرة، نحتاج إلى إضافة segment descriptor جديد إلى Global Descriptor Table (GDT). ثم يمكننا تحميل TSS باستدعاء [ltr instruction] بفهرس GDT المقابل. (هذا السبب لماذا سمينا module gdt.)
🔗جدول واصف العام
Global Descriptor Table (GDT) هي آثار أثرية كانت تُستخدم لـ memory segmentation قبل أن يصبح paging المعيار الفعلي. ومع ذلك، لا تزال مطلوبة في وضع 64-bit لأمور مختلفة، مثل تكوين kernel/user mode أو تحميل TSS.
GDT هي بنية تحتوي على segments للبرنامج. كانت تُستخدم على معماريات أقدم لعزل البرامج عن بعضها قبل أن يصبح paging المعيار. لمزيد من المعلومات حول التجزئة، راجع الفصل ذو الاسم نفسه من كتاب [“Three Easy Pieces”] المجاني. بينما لم يعد التجزئة مدعومة في وضع 64-bit، لا يزال GDT موجودًا. يُستخدم في الغالب لشيئين: التبديل بين kernel space و user space، وتحميل هيكل TSS.
🔗إنشاء GDT
لننشئ GDT ثابت يتضمن segment لـ TSS الثابت:
// in src/gdt.rs
use x86_64::structures::gdt::{GlobalDescriptorTable, Descriptor};
lazy_static! {
static ref GDT: GlobalDescriptorTable = {
let mut gdt = GlobalDescriptorTable::new();
gdt.add_entry(Descriptor::kernel_code_segment());
gdt.add_entry(Descriptor::tss_segment(&TSS));
gdt
};
}
كما قبل، نستخدم lazy_static مرة أخرى. ننشئ GDT جديدًا مع code segment و TSS segment.
🔗تحميل GDT
لتحميل GDT، ننشئ دالة gdt::init جديدة نستدعيها من دالة init:
// in src/gdt.rs
pub fn init() {
GDT.load();
}
// in src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
}
الآن GDT مُحمّل (لأن دالة _start تستدعي init)، لكننا لا نزال نرى boot loop عند stack overflow.
🔗الخطوات النهائية
المشكلة هي أن GDT segments غير مُفعلة بعد لأن segment و TSS registers لا تزال تحتوي القيم من GDT القديم. نحتاج أيضًا إلى تعديل double fault IDT entry بحيث يستخدم stack الجديد.
بشكل ملخص، نحتاج إلى فعل ما يلي:
- إعادة تحميل سجل code segment: غيّرنا GDT، لذلك يجب إعادة تحميل
cs، سجل code segment. هذا مطلوب لأن segment selector القديم قد يشير الآن إلى GDT descriptor مختلف (مثل TSS descriptor). - تحميل TSS: حمّلنا GDT يحتوي على TSS selector، لكن لا نزال نحتاج إلى إخبار وحدة المعالجة المركزية أنه يجب استخدام ذلك TSS.
- تحديث IDT entry: بمجرد تحميل TSS، يصل وحدة المعالجة مركزية إلى interrupt stack table صالح (IST). ثم يمكننا إخبار وحدة المعالجة المركزية أنه يجب استخدام double fault stack الجديد بتعديل double fault IDT entry.
للخطوتين الأوليين، نحتاج إلى الوصول إلى متغيرات code_selector و tss_selector في دالة gdt::init. يمكننا تحقيق ذلك بجعلها جزءًا من static عبر struct Selectors جديد:
// in src/gdt.rs
use x86_64::structures::gdt::SegmentSelector;
lazy_static! {
static ref GDT: (GlobalDescriptorTable, Selectors) = {
let mut gdt = GlobalDescriptorTable::new();
let code_selector = gdt.add_entry(Descriptor::kernel_code_segment());
let tss_selector = gdt.add_entry(Descriptor::tss_segment(&TSS));
(gdt, Selectors { code_selector, tss_selector })
};
}
struct Selectors {
code_selector: SegmentSelector,
tss_selector: SegmentSelector,
}
الآن يمكننا استخدام المحددات لإعادة تحميل سجل cs وتحميل TSS:
// in src/gdt.rs
pub fn init() {
use x86_64::instructions::tables::load_tss;
use x86_64::instructions::segmentation::{CS, Segment};
GDT.0.load();
unsafe {
CS::set_reg(GDT.1.code_selector);
load_tss(GDT.1.tss_selector);
}
}
نعيد تحميل سجل code segment باستخدام CS::set_reg ونحمّل TSS باستخدام load_tss. الدوال محددة كـ unsafe، لذلك نحتاج إلى كتلة unsafe لاستدعائها. السبب هو أنه قد يكون من الممكن كسر أمان الذاكرة بتحميل محددات غير صالحة.
الآن بعد أن حمّلنا TSS صالحًا و interrupt stack table، يمكننا تعيين فهرس Stack لـ double fault handler في IDT:
// in src/interrupts.rs
use crate::gdt;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault.set_handler_fn(double_fault_handler)
.set_stack_index(gdt::DOUBLE_FAULT_IST_INDEX); // new
}
idt
};
}
دالة set_stack_index غير آمنة لأن المستدعي يجب أن يضمن أن الفهرس المستخدم صالح و غير مستخدم بالفعل لـ exception أخرى.
هذا كل شيء! الآن يجب أن ينتقل وحدة المعالجة مركزية إلى double fault stack whenever تحدث double fault. لذلك، نحن قادرون على التقاط جميع double faults، بما في ذلك kernel stack overflows:
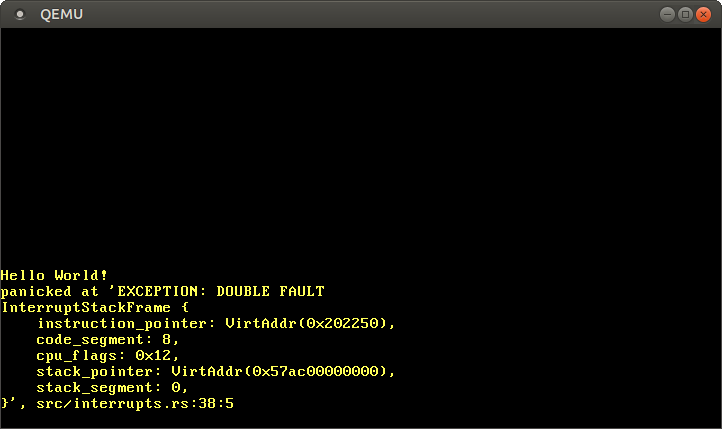
من الآن فصاعدًا، يجب ألا نرى triple fault مرة أخرى! لضمان عدم كسر ما سبق عن طريق الخطأ، يجب أن نضيف اختبارًا لذلك.
🔗اختبار تجاوز سعة Stack
لاختبار module gdt الجديد وضمان استدعاء double fault handler بشكل صحيح عند stack overflow، يمكننا إضافة integration test. الفكرة هي إثارة double fault في دالة الاختبار والتحقق من استدعاء double fault handler.
لنبدأ بـ skeleton بسيط:
// in tests/stack_overflow.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
مثل اختبار panic_handler، سيعمل الاختبار [بدون test harness]. السبب هو أننا لا نستطيع استئناف التنفيذ بعد double fault، لذلك أكثر من اختبار واحد لا معنى له. لتعطيل test harness للاختبار، نضيف ما يلي إلى Cargo.toml:
# in Cargo.toml
[[test]]
name = "stack_overflow"
harness = false
الآن cargo test --test stack_overflow يجب أن يترجم بنجاح. بالطبع، الاختبار سيفشل لأن الماكرو unimplemented يُسبب panic.
🔗تنفيذ _start
تنفيذ دالة _start يبدو كالتالي:
// in tests/stack_overflow.rs
use blog_os::serial_print;
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
serial_print!("stack_overflow::stack_overflow...\t");
blog_os::gdt::init();
init_test_idt();
// trigger a stack overflow
stack_overflow();
panic!("Execution continued after stack overflow");
}
#[allow(unconditional_recursion)]
fn stack_overflow() {
stack_overflow(); // for each recursion, the return address is pushed
volatile::Volatile::new(0).read(); // prevent tail recursion optimizations
}
نستدعي دالة gdt::init لتهيئة GDT جديد. بدلاً من استدعاء دالة interrupts::init_idt، نستدعي دالة init_test_idt التي ستُشرح بعد لحظة. السبب هو أننا نريد تسجيل double fault handler مخصص يفعل exit_qemu(QemuExitCode::Success) بدلاً من الـ panic.
دالة stack_overflow متطابقة تقريبًا مع الدالة في main.rs. الفرق الوحيد هو في نهاية الدالة، ننفذ قراءة volatile إضافية باستخدام نوع Volatile لمنع تحسين المترجم المسمى tail call elimination. من بين أمور أخرى، يسمح هذا التحسين للمترجم بتحويل دالة آخر عبارة فيها استدعاء دالة recursive إلى loop عادية. لذلك، لا يُنشأ stack frame إضافي لاستدعاء الدالة، وتبقى استخدامات Stack ثابتة.
في حالتنا، ومع ذلك، نريد أن يحدث stack overflow، لذلك نضيف عبارة قراءة volatile وهمية في نهاية الدالة، التي لا يُسمح للمترجم بإزالتها. لذلك، لم تعد الدالة tail recursive، ويُمنع التحويل إلى loop. نضيف أيضًا السمة allow(unconditional_recursion) لكتم تحذير المترجم بأن الدالة تعيد نفسها بلا نهاية.
🔗The Test IDT
كما لوحظ أعلاه، يحتاج الاختبار إلى IDT خاص به مع double fault handler مخصص. يبدو التنفيذ كالتالي:
// in tests/stack_overflow.rs
use lazy_static::lazy_static;
use x86_64::structures::idt::InterruptDescriptorTable;
lazy_static! {
static ref TEST_IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
unsafe {
idt.double_fault
.set_handler_fn(test_double_fault_handler)
.set_stack_index(blog_os::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt
};
}
pub fn init_test_idt() {
TEST_IDT.load();
}
التنفيذ مشابه جدًا لـ IDT العادي في interrupts.rs. مثل IDT العادي، نعيّن فهرس Stack في IST لـ double fault handler للتبديل إلى stack منفصل. دالة init_test_idt تحمل IDT على وحدة المعالجة المركزية عبر دالة load.
🔗The Double Fault Handler
القطعة الوحيدة المفقودة هي double fault handler. يبدو كالتالي:
// in tests/stack_overflow.rs
use blog_os::{exit_qemu, QemuExitCode, serial_println};
use x86_64::structures::idt::InterruptStackFrame;
extern "x86-interrupt" fn test_double_fault_handler(
_stack_frame: InterruptStackFrame,
_error_code: u64,
) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
عندما يُستدعى double fault handler، نخرج من QEMU بـ exit code نجاح، الذي يحدد الاختبار على أنه ناجح. بما أن integration tests هي executables completely منفصلة، نحتاج إلى تعيين السمة #![feature(abi_x86_interrupt)] مرة أخرى في أعلى ملف الاختبار.
الآن يمكننا تشغيل اختبارنا عبر cargo test --test stack_overflow (أو cargo test لتشغيل جميع الاختبارات). كما هو متوقع، نرى إخراج stack_overflow... [ok] في console. حاول التعليق على سطر set_stack_index؛ يجب أن يسبب فشل الاختبار.
🔗Summary
في هذا المقال، تعلمنا ما هي double fault و في أي شروط تحدث. أضفنا double fault handler أساسي يطبع رسالة خطأ وأضفنا integration test لها.
فعّلنا أيضًا تبديل Stack المدعوم بالجهاز عند double fault exceptions بحيث يعمل أيضًا عند stack overflow. أثناء التنفيذ، تعلمنا عن task state segment (TSS)، و interrupt stack table (IST) المحتوى، و global descriptor table (GDT)، الذي كان يُستخدم للتجزئة على معماريات أقدم.
🔗What’s next?
المقال التالي يشرح كيفية معالجة interrupts من أجهزة خارجية مثل timers و keyboards أو network controllers. هذه hardware interrupts مشابهة جدًا لـ exceptions، على سبيل المثال، تُوزع أيضًا عبر IDT. ومع ذلك، على عكس exceptions، لا تنشأ مباشرة على وحدة المعالجة المركزية. بدلاً من ذلك، interrupt controller يجمع هذه المقاطعات ويحولها إلى وحدة المعالجة المركزية حسب أولويتها. في المقال التالي، سنستكشف Intel 8259 (“PIC”) interrupt controller ون⊊مل كيفية تنفيذ دعم لوحة المفاتيح.
التعليقات
هل لديك مشكلة، أو تريد مشاركة ملاحظات، أو مناقشة أفكار إضافية؟ لا تتردد في ترك تعليق هنا! يرجى الالتزام باللغة الإنجليزية واتباع مدونة سلوك Rust. يتم ربط هذا الخيط من التعليقات مباشرة بـ نقاش على GitHub، لذا يمكنك التعليق هناك أيضًا إذا أردت.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
يفضل كتابة التعليقات باللغة الإنجليزية إن أمكن.