Введение в пагинацию
Переведенное содержание: Это перевод сообщества поста Introduction to Paging. Он может быть неполным, устаревшим или содержать ошибки. Пожалуйста, сообщайте о любых проблемах!
Перевод сделан @TakiMoysha.
Этот пост посвящен пагинации, очень распространенной схеме управления памяти, которую и мы будем использовать в нашей операционной системе. Далее изложенно, зачем нужна изоляция памяти, как работает сегментация, что такое виртуальная память и как страничная организация памяти решает проблемы фрагментации памяти. Кроме того, рассмотрим структуру многоуровневых таблиц страниц в архитектуре x86_64.
Этот блог открыто разрабатывается на GitHub. Если у вас есть какие-либо проблемы или вопросы, пожалуйста, создайте issue. Вы также можете оставлять комментарии внизу страницы. Полный исходный код для этого поста можно найти в ветке post-08.
Содержание
🔗Защита Памяти
Одной из основных задач операционной системы является изоляция программ друг от друга. Например, ваш веб-браузер не должен иметь возможности влиять на работу текстового редактора. Для достижения этой цели операционные системы используют аппаратные средства, чтобы изолировать область памяти одного процесса от других. Существуют различные подходы в зависимости от аппаратного обеспечения и реализации ОС.
Например, некоторые процессоры ARM Cortex-M (используемые в эмбедед-системах) имеют блок защиты памяти (MPU), который позволяет определить небольшое количество (например, 8) областей памяти с различными правами доступа (например, без доступа, только для чтения, для чтения и записи). При каждом доступе к памяти MPU проверяет, находится ли адрес в области с правильными правами доступа, и в противном случае генерирует исключение. Изменяя области и права доступа при каждом переключении между процессами, операционная система может гарантировать, что каждый процесс обращается только к своей собственной памяти, и таким образом изолирует процессы друг от друга.
В x86 есть аппарантная поддерживает двух разных подходов к защите памяти: сегментация и пагинация
🔗Сегментация
Сегментация была представлена ещё в 1978 году, изначально с целью увеличения объёма адресуемой памяти. В то время процессоры использовали только 16-разрядные адреса, что ограничивало объём адресуемой памяти в 64 КБ. Чтобы обеспечить доступ к памяти, превышающему эти 64 КБ, были введены дополнительные сегментные регистры, каждый из которых содержал адрес смещения. Процессор автоматически добавлял это смещение при каждом обращении к памяти, благодаря чему становилось доступно до 1 МБ памяти.
Регистр сегмента выбирается процессором автоматически в зависимости от типа доступа к памяти: для выборки инструкций используется сегмент кода CS, а для операций со стеком (push/pop) — сегмент стека SS. Остальные инструкции используют сегмент данных DS или дополнительный сегмент ES. Позже были добавлены два дополнительных сегментных регистра, FS и GS, которые можно использовать по своему усмотрению.
В первой версии сегментации сегментные регистры непосредственно содержали смещение, и контроль доступа не осуществлялся. Это было изменено позже с введением защищенного режима. Когда процессор работает в этом режиме, сегментные дескрипторы содержат индекс в локальную или глобальную таблицу дескрипторов, которая содержит - помимо адреса смещения - размер сегмента и права доступа. Загружая отдельные глобальные/локальные таблицы дескрипторов для каждого процесса, которые ограничивают доступ к памяти собственными областями памяти процесса, ОС может изолировать процессы друг от друга.
Изменяя адрес памяти перед фактическим доступом, сегментация уже применяет технику, которую сегодня применяется практически повсеместно: виртуальная память.
🔗Виртуальная Память
Суть виртуальной памяти заключается в абстрагировании адресов памяти от базового физического устройства хранения. Вместо прямого обращения к устройству хранения сначала выполняется трансляция (или преобразование) адреса. Для сегментации, этап трансляции залючается в добавлении смещения адреса нативного сегмента. Представьте себе программу, обращающуюся к адресу памяти 0x1234000 в сегменте со смещением 0x1111000: адрес, к которому на самом деле обращаются будет 0x2345000.
Чтобы различать эти два типа адресов, адреса до преобразования называются виртуальными, а адреса после преобразования физическими. Одно из важных отличий между этими двумя типами адресов в том, что физические адреса являются уникальными и всегда ссылаются на одно и то же конкретное место в памяти. Виртуальные адреса, с другой стороны, зависят от функции преобразования. Вполне возможно, что два разных виртуальных адреса ссылаются на один и тот же физический адрес. Кроме того, одинаковые виртуальные адреса могут ссылаться на разные физические адреса, если для них используются разные функции преобразования.
Примером, в котором это свойство оказывается полезным, является параллельное выполнение одной и той же программы дважды:

Здесь одна и та же программа запускается дважды, но с разными функциями преобразования. Первый экземпляр запущен со смещением сегмента 100, так что его виртуальные адреса 0-150 транслируются в физичесие адреса 100-250. Второй экземпляр со смещением 300, что приводит к преобразованию его виртуальных адресов 0–150 в физические адреса 300–450. Это позволяет обеим программам выполнять один и тот же код и использовать одни и те же виртуальные адреса, не мешая друг другу.
Еще одним преимуществом является то, что программы теперь можно размещать в произвольных областях физических памяти, даже если они используют совершенно разные виртуальные адреса. Таким образом, ОС может использовать весь объем доступной памяти без необходимости перекомпиляции программ.
🔗Фрагментация
Разделение между виртуальными и физическими адресами делает сегментацию по настоящему мощным инструментом. Тем не менее, у нее есть проблема фрагментации. Допустим, мы хотим запустить третью копию программы, которую видели выше:

Не существует способа отобразить третий экземпляр программы в виртуальную память без перекрытия, даже если свободно больше чем требуется памяти. Проблема в том, что нам нужна непрерывния память, и мы не можем использовать небольшие свободные фрагменты.
Один из способов борьбы с этой фрагментацией - приостановить выполнение, сблизить используемые части памяти, обновить преобразованные адреса, а затем возобновить выполнение:

Теперь у нас достаточно непрерывного пространства чтобы запустить третий экземпляр нашей программны.
Недостатком процесса дефрагментации является то, что он требует копирования больших объемов памяти, что снижает производительность. Кроме того, его необходимо выполнять регулярно до того, как память станет слишком фрагментированной. Это делает производительность непредсказуемой, поскольку программы приостанавливаются в случайное время и могут стать неотзывчивыми.
Проблема фрагментации является одной из причин, по которой сегментация перестала использоваться большинством систем. Фактически, сегментация даже не поддерживается в режиме 64-бит на x86. Вместо этого используется пагинация (или постраничная адресация), которая полностью обходит проблему фрагментации.
🔗Пагинация
Идея заключается в том, чтобы разделить как виртуальное, так и физическое пространство памяти на небольшие блоки фиксированного размера. Блоки виртуального пространства памяти называются страницами, а блоки физического адресного пространства - фреймами (frames). Каждая страница может быть индивидуально сопоставлена с фреймом, что позволяет распределять большие области памяти по несплошным физическим фреймам.
Преимуществом этого становится очевидным, если мы вернемся к примеру с фрагментированным пространством памяти, но на этот раз вместо сегментации используем страничную организацию:

В этом примере размер страницы равен 50 байтам, что значит, что каждая область памяти разделена на три страницы. Каждая страница сопоставлена со своим фреймом, что позволяет сопоставить сплошную область виртуальной памяти с несплошными физическими фреймами. Благодаря этому мы можем запустить третий экземпляр программы без предварительной дефрагментации.
🔗Скрытая Фрагментация
По сравнению с сегментацией, страничная организация памяти использует множество небольших областей памяти фиксированного размера вместо нескольких больших областей переменного размера. Поскольку все фрагменты имеют одинаковый размер, нет фрагментов, которые были бы слишком малы для использования, поэтому фрагментация не возникает.
Или это только кажется, что фрагментации не возникает. У нас все еще некоторая фрагментация, называемый внутренней фрагментацией. Внутренняя фрагментация возникает из-за того, что не каждый участок памяти является точным кратным размера страницы. Представьте себе программу размером 101 байт из приведенного выше примера: ей по-прежнему потребуется три страницы размером 50 байт, поэтому она займет на 49 байт больше, чем необходимо. Чтобы различать эти два типа фрагментации, тип фрагментации, возникающий при использовании сегментации, называется внешней фрагментацией.
Внутренняя фрагментация - это неприятная вещь, но зачастую она лучше, чем внешняя фрагментация, возникающая при сегментации. Она все равно приводит к потере памяти, но не требует дефрагментации и делает объем фрагментации предсказуемым (в среднем половина страницы на выбеленный блок памяти).
🔗Таблицы Страниц
Мы видели, что каждая из потенциально миллионов страниц индивидуально сопоставляется с одним фреймом. Эта информация о сопоставлении должна где-то храниться. При сегментации для каждой активной области памяти используется отдельный регистр выбора сегмента, что невозможно при страничной организации памяти, т.к. страниц гораздо больше, чем регистров. Вместо этого при страничной организации памяти для хранения информации о сопоставлении используется табличная структура, называемая таблицей страниц.
Для приведенного выше примера таблицы страниц будут выглядеть следующим образом:

Мы видим, что каждый экземпляр программы имеет свою собственную таблицу страниц. Указатель на текущую активную таблицу хранится в специальном регистре процессора. В архитектуре x86 этот регистр называется CR3. Задача операционной системы состоит в том, чтобы перед запуском каждого экземпляра программы загрузить в этот регистр указатель на нужную таблицу страниц.
При каждом обращении к памяти процессор считывает указатель таблицы из регистра и ищет в таблице сопоставленный блок для обращаемой страницы. Этот процесс полностью выполняется аппаратно и остается незаметным для выполняемой программы. Для ускорения процесса преобразования во многих архитектурах CPU предусмотрен специальный кэш, в котором сохраняются результаты последних преобразований.
В зависимости от архитектуры записи в таблице страниц могут также хранить такие атрибуты, как права доступа, в поле флагов. В приведенном выше примере флаг «r/w» делает страницу доступной как для чтения, так и для записи.
🔗Многоуровневые Таблицы Страниц
Простые таблицы страниц, которые мы только что рассмотрели имеют проблему с большим адресным пространством: они растрачивают память. Например: представьте программу, которая использует четыре виртуальные страницы 0, 1_000_000, 1_000_050 и 1_000_100 (мы используем _ в качестве разделителя тысяч):

Для этого требуется всего 4 физических фрейма, но таблица страниц содержит более миллиона записей. Мы не можем опустить пустые записи, потому что тогда ЦП больше не сможет переходить напрямую к нужной записи в процессе преобразования (например, больше не будет гарантии, что четвертая страница использует четвертую запись).
Чтобы уменьшить объем растрачиваемой памяти, мы можем использовать двухуровневую таблицу страниц. Идея в том, что мы используем разные таблицы страниц для разных областей адресов. Дополнительная таблица, называемая таблицей страниц уровня 2, содержит отображение между диапазонами адресов и таблицами страниц (уровня 1).
Лучше всего это объяснить на примере. Давайте определим, что каждая таблица страниц уровня 1 отвечает за область размером 10_000. Тогда для приведенного выше примера отображения будут существовать следующие таблицы:

Страница 0 попадает в первый диапазов байтов 10_000, поэтому для нее используется первая запись таблицы страниц второго уровня. Эта запись указывает на таблицу страниц первого уровня Т1, в которой указано, что страница 0 указывает на фрейм 0.
Страницы 1_000_000, 1_000_050 и 1_000_100 все попадают в 100-ю область по 10_000 байт, поэтому они используют 100-ю запись таблицы страниц уровня 2. Эта запись указывает на другую таблицу страниц уровня 1 T2, которая сопоставляет три страницы фреймам 100, 150 и 200. Обратите внимание, что адрес страницы в таблицах уровня 1 не включает смещение области. Например, запись для страницы 1_000_050 это просто 50.
У нас все еще есть 100 пустых записей в таблице 2-го уровня, но их гораздо меньше, чем миллион пустых записей ранее. Причина этой экономии в том, что нам не нужно создавать таблицы страниц 1-го уровня для несопоставленных областей памяти между 10_000 и 1_000_000.
Принцип двухуровневых таблиц страниц можно расширить до трех, четырёх или более уровней. Тогда регистр таблицы страниц указывает на таблицу самого высокого уровня, которая указывает на таблицу следующего более низкого уровня, которая указывает на следующий более низкий уровень и так далее. Затем таблица страниц уровня 1 указывает на отображённый фрейм. Этот принцип в целом называется многоуровневой или иерархической таблицей страниц.
Теперь, когда мы знаем, как работают страничная организация памяти и многоуровневые таблицы страниц, мы можем рассмотреть, как страничная организация памяти реализована в архитектуре x86_64 (далее мы предполагаем, что процессор работает в 64-битном режиме).
🔗Пагинация на x86_64
В x86_64 используется 4-уровневая таблица страниц с размером страницы 4 КБ. Каждая таблица страниц, независимо от уровня, имеет фиксированный размер в 512 записей. Каждая запись имеет размер 8 байт, поэтому каждая таблица имеет размер 512 * 8 Б = 4 КБ и, таким образом, точно помещается в одну страницу.
Индекс таблицы страниц для каждого уровня выводится непосредственно из виртуального адреса:

Мы видим, что каждый индекс таблицы состоит из 9 битов, что логично, поскольку каждая таблица имеет 2^9 = 512 записей. Младшие 12 битов представляют собой смещение в странице размером 4 КБ (2^12 байт = 4 КБ). Биты с 48 по 64 игнорируются, что означает, что x86_64 на самом деле не является 64-разрядной архитектурой, поскольку поддерживает только 48-разрядные адреса.
Несмотря на то, что биты с 48 по 64 игнорируются, их нельзя устанавливать в произвольные значения. Вместо этого все биты в этом диапазоне должны быть копиями бита 47, чтобы сохранить уникальность адресов и обеспечить возможность будущих расширений, таких как 5-уровневая таблица страниц. Это называется расширением знака, поскольку очень похоже на расширение знака в дополнении до двух. Если адрес не был правильно расширен по знаку, процессор генерирует исключение.
Стоит отметить, что новейшие процессоры Intel серии «Ice Lake» опционально поддерживают 5-уровневые таблицы страниц для расширения виртуальных адресов с 48 до 57 бит. Учитывая, что на данном этапе оптимизация нашего ядра под конкретный процессор не имеет смысла, в этой статье мы будем работать только со стандартными 4-уровневыми таблицами страниц.
🔗Пример Трансляции
Давайте рассмотрим пример, чтобы подробно понять, как работает процесс трансляции или отображения:

Физический адрес текущей активной таблицы страниц 4-го уровня, являющейся корнем 4-уровневой таблицы страниц, хранится в регистре CR3. Затем каждая запись таблицы страниц указывает на физический фрейм таблицы следующего уровня. Запись таблицы 1-го уровня указывает на отображенный фрейм. Обратите внимание, что все адреса в таблицах страниц являются физическими, а не виртуальными, поскольку в противном случае ЦП пришлось бы преобразовывать и эти адреса (что могло бы привести к бесконечной рекурсии).
На приведенной выше иерархии таблиц страниц отображены две страницы (выделены синим цветом). По индексам таблицы страниц можно определить, что виртуальные адреса этих двух страниц равны 0x803FE7F000 и 0x803FE00000. Давайте посмотрим, что произойдет, когда программа попытается прочитать данные по адресу 0x803FE7F5CE. Сначала преобразуем адрес в двоичный формат и определим индексы таблицы страниц и смещение страницы для этого адреса:

Используя эти индексы, мы теперь можем пройти по иерархии таблиц страниц, чтобы определить сопоставленный фрейм для данного адреса:
- Для начала мы считываем адрес таблицы 4-го уровня из регистра
CR3. - Индекс 4-го уровня равен 1, поэтому мы обращаемся к записи с индексом 1 в этой таблице, которая указывает, что таблица 3-го уровня хранится по адресу 16 КБ.
- Мы загружаем таблицу уровня 3 с этого адреса и смотрим запись с индексом 0, которая указывает нам на таблицу уровня 2 по адресу 24 КБ.
- Индекс уровня 2 равен 511, поэтому мы смотрим последнюю запись этой страницы, чтобы узнать адрес таблицы уровня 1.
- Через запись с индексом 127 в таблице уровня 1 мы наконец выясняем, что страница сопоставлена с фреймом 12 КБ, или 0x3000 в шестнадцатеричном формате.
- Последний шаг — сложить смещение страницы с адресом фрейма, чтобы получить физический адрес 0x3000 + 0x5ce = 0x35ce.

Права доступа к странице в таблице уровня 1 имеют значение r, что означает «только для чтения». Аппаратное обеспечение обеспечивает соблюдение этих прав и вызовет исключение, если мы попытаемся записать данные на эту страницу. Права доступа на страницах более высоких уровней ограничивают возможные права доступа на более низких уровнях, поэтому, если мы установим для записи уровня 3 значение «только для чтения», ни одна из страниц, использующих эту запись, не сможет быть доступна для записи, даже если на более низких уровнях указаны права чтения/записи.
Важно отметить, что, хотя в этом примере использовался только один экземпляр каждой таблицы, обычно в каждом адресном пространстве имеется несколько экземпляров каждого уровня. Максимально может быть:
- одна таблица 4-го уровня,
- 512 таблиц 3-го уровня (поскольку таблица 4-го уровня содержит 512 записей),
- 512 * 512 таблиц уровня 2 (поскольку каждая из 512 таблиц уровня 3 имеет 512 записей) и
- 512 * 512 * 512 таблиц уровня 1 (512 записей для каждой таблицы уровня 2).
🔗Формат Таблицы Страниц
Таблицы страниц в архитетуру x86_64 представляют собой массив из 512 записей. В синтаксисе Rust:
#[repr(align(4096))]
pub struct PageTable {
entries: [PageTableEntry; 512],
}Как указывает атрибут repr, таблицы страниц должны быть выровнены по страницам, т.е. выровнены по границе 4 КБ. Это требование гарантирует, что таблица страниц всегда заполняет целую страницу, и позволяет оптимизировать записи, делая их очень компактными.
Каждая запись имеет размер 8 байт (64 бита) и следующий формат:
| Бит(ы) | Название | Значение |
|---|---|---|
| 0 | present | страница в данный момент находится в памяти |
| 1 | writable | на эту страницу разрешена запись |
| 2 | user accessible | если не установлено, доступ к этой странице имеет только код в режиме ядра (kernel mode) |
| 3 | write-through caching | записи поступают напрямую в память |
| 4 | disable cache | для этой страницы кэш не используется |
| 5 | accessed | ЦП устанавливает этот бит, когда эта страница используется |
| 6 | dirty | ЦП устанавливает этот бит, когда происходит запись на эту страницу |
| 7 | huge page/null | должен быть равен 0 в P1 и P4, создает страницу размером 1 ГБ в P3, создает страницу размером 2 МБ в P2 |
| 8 | global | страница не очищается из кэшей при переключении адресного пространства (бит PGE регистра CR4 должен быть установлен) |
| 9-11 | available | может свободно использоваться ОС |
| 12-51 | physical address | выровненный по странице 52-битный физический адрес фрейма или следующей таблицы страниц |
| 52-62 | available | может свободно использоваться ОС |
| 63 | no execute | запрещает выполнение кода на этой странице (бит NXE в регистре EFER должен быть установлен) |
Мы видим, что для хранения физического адреса фрейма используются только биты 12–51. Остальные биты служат в качестве флагов или могут свободно использоваться операционной системой. Это возможно благодаря тому, что мы всегда указываем на адрес, выровненный по границе 4096 байт, будь то таблица страниц, выровненная по странице, или начало отображенного фрейма. Это означает, что биты 0–11 всегда равны нулю, поэтому нет причин хранить эти биты, поскольку аппаратное обеспечение может просто обнулить их перед использованием адреса. То же самое верно для битов 52–63, поскольку архитектура x86_64 поддерживает только 52-битные физические адреса (аналогично тому, как она поддерживает только 48-битные виртуальные адреса).
Давайте подробнее рассмотрим доступные флаги:
- Флаг
presentпозволяет отличать отображенные страницы от неотображенных. Его можно использовать для временного перемещения страниц на диск, когда основная память заполняется. При последующем обращении к странице возникает специальное исключение page fault, на которое операционная система может отреагировать, перезагрузив отсутствующую страницу с диска и продолжив выполнение программы. - Флаги
writableиno executeопределяют можно ли записывать содержимое страницы или содержит ли оно исполняемые инструкции соответственно. - Флаги
accessedиdirtyавтоматически устанавливаются процессором при чтении или записи в страницу. Эта информация может быть использована операционной системой, например, для определения, какие страницы следует выгрузить, или для проверки, было ли содержимое страницы изменено с момента последнего сохранения на диск. - Флаги
write-through cachingиdisable cacheпозволяют управлять кэшами для каждой страницы индивидуально. - Флаг
user accessibleделает страницу доступной для кода пользовательского пространства; в противном случае она доступна только тогда, когда процессор находится в режиме ядра. Эта функция может использоваться для ускорения системных вызовов за счет сохранения отображения ядра во время работы программы пользовательского пространства. Однако уязвимость Spectre может все же позволить программам пользовательского пространства читать эти страницы. - Флаг
globalсигнализирует аппаратному обеспечению, что страница доступна во всех адресных пространствах и, следовательно, не требует удаления из кэша преобразования (см. раздел о TLB ниже) при переключении между адресными пространствами. Этот флаг обычно используется вместе со сброшенным флагомuser accessibleдля отображения кода ядра во всех адресных пространствах. - Флаг
huge pageпозволяет создавать страницы большего размера, позволяя записям таблиц страниц уровня 2 или уровня 3 напрямую указывать на отображенный фрейм. При установке этого бита размер страницы увеличивается в 512 раз до 2 МБ = 512 * 4 КБ для записей уровня 2 или даже 1 ГБ = 512 * 2 МБ для записей уровня 3. Преимущество использования страниц большего размера заключается в том, что требуется меньше строк в кэше преобразования и меньше таблиц страниц.
Крейт x86_64 предоставляет типы для таблиц страниц и их записей, поэтому нам не нужно создавать эти структуры самостоятельно.
🔗Буфер Предварительного Просмотра Преобразований
Четырёхуровневая таблица страниц делает преобразование виртуальных адресов ресурсоёмким, поскольку каждое преобразование требует четырёх обращений к памяти. Для повышения производительности архитектура x86_64 кэширует последние несколько преобразований, в так называемом, буфере ассоциативной трансляции (TLB - translation lookaside buffer). Это позволяет пропустить преобразование, если оно ещё находится в кэше.
В отличие от других кэшей процессора, TLB не является полностью прозрачным и не обновляет или удаляет преобразования при изменении содержимого таблиц страниц. Это означает, что ядро должно вручную обновлять TLB при каждом изменении таблицы страниц. Для этого существует специальная инструкция процессора под названием invlpg (“invalidate page”), которая удаляет преобразование для указанной страницы из TLB, чтобы при следующем доступе оно было загружено заново из таблицы страниц. TLB также можно полностью очистить, перезагрузив регистр CR3, что имитирует переключение адресного пространства. Крейт x86_64 предоставляет функции Rust для обоих вариантов в модуле tlb.
Важно не забывать очищать TLB при каждом изменении таблицы страниц, поскольку в противном случае процессор может продолжать использовать старое преобразование, что может привести к непредсказуемым ошибкам, которые очень сложно устранить.
🔗Реализация
Есть одна вещь, о которой мы ещё не упоминали: наше ядро уже работает с пагинацией. Загрузчик, который мы добавили в статье “Минимально возможное ядро на Rust”, уже настроил 4-уровневую иерархию страниц, которая сопоставляет каждую страницу нашего ядра с физическим фреймом. Загрузчик делает это потому, что в 64-битном режиме на архитектуре x86_64 использование страничной организации памяти является обязательным.
Это означает, что каждый адрес памяти, который мы использовали в нашем ядре, был виртуальным адресом. Доступ к буферу VGA по адресу 0xb8000 работал только потому, что загрузчик выполнил идентичное отображение этой страницы памяти, то есть сопоставил виртуальную страницу 0xb8000 с физическим блоком 0xb8000.
Страничная организация памяти делает наше ядро уже относительно безопасным, поскольку каждый доступ к памяти за пределами допустимого диапазона вызывает ошибку страницы (page fault exception) вместо записи в произвольную физическую память. Загрузчик даже устанавливает корректные права доступа для каждой страницы, что означает, что только страницы с кодом являются исполняемыми и только страницы с данными доступными для записи.
🔗Ошибка Страницы
Попробуем вызвать ошибку страницы, обратившись к памяти за пределами нашего ядра. Сначала создадим обработчик для ошибки страницы и зарегистрируем его в нашем IDT (дескрипторная таблица прерываний), чтобы вместо общей ошибки double fault мы видели исключение, связанное с ошибкой страницы:
// src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
[…]
idt.page_fault.set_handler_fn(page_fault_handler); // новое
idt
};
}
use x86_64::structures::idt::PageFaultErrorCode;
use crate::hlt_loop;
extern "x86-interrupt" fn page_fault_handler(
stack_frame: InterruptStackFrame,
error_code: PageFaultErrorCode,
) {
use x86_64::registers::control::Cr2;
println!("EXCEPTION: PAGE FAULT");
println!("Accessed Address: {:?}", Cr2::read());
println!("Error Code: {:?}", error_code);
println!("{:#?}", stack_frame);
hlt_loop();
}Регистр CR2 автоматически устанавливается процессором при возникновении ошибки страницы и содержит виртуальный адрес, доступ к которому вызвал эту ошибку. Мы используем функцию Cr2::read из библиотеки x86_64 для чтения и вывода этого значения. Тип PageFaultErrorCode предоставляет дополнительную информацию о типе доступа к памяти, вызвавшем ошибку страницы, например, была ли она вызвана операцией чтения или записи. По этой причине мы также выводим его на экран. Мы не можем продолжить выполнение без устранения ошибки страницы, поэтому в конце входим в цикл hlt_loop.
Теперь мы можем попробовать получить доступ к памяти за пределами нашего ядра:
// src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
// новое
let ptr = 0xdeadbeaf as *mut u8;
unsafe { *ptr = 42; }
// как и раньше
#[cfg(test)]
test_main();
println!("It did not crash!");
blog_os::hlt_loop();
}При запуске мы видим, что вызывается наш обработчик ошибок страниц:
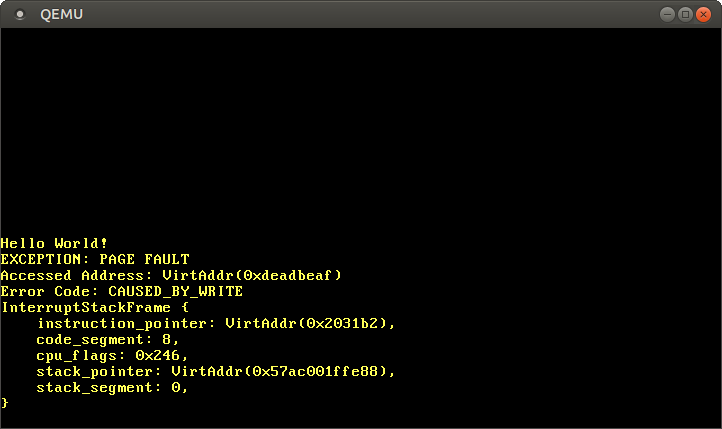
Регистр CR2 действительно содержит значение 0xdeadbeaf - адрес, к которому мы пытались получить доступ. Код ошибки сообщает нам через CAUSED_BY_WRITE, что сбой произошел при попытке выполнить операцию записи. Он сообщает нам еще больше через биты, которые не установлены. Например, тот факт, что флаг PROTECTION_VIOLATION не установлен, означает, что сбой страницы произошел из-за отсутствия целевой страницы.
Мы видим, что текущий указатель инструкции равен 0x2031b2, поэтому знаем, что этот адрес указывает на страницу кода. Страницы кода сопоставляются загрузчиком в режиме «только для чтения», поэтому чтение с этого адреса работает, а запись приводит к ошибке страницы. Вы можете проверить это, изменив значение указателя 0xdeadbeaf на 0x2031b2:
// Примечание: У вас адрес может отличаться.
// Используйте адрес, который сообщает ваша процедура обработки ошибок страницы
let ptr = 0x2031b2 as *mut u8;
// чтение из страницы кодов
unsafe { let x = *ptr; }
println!("read worked");
// запись в страницу кодов
unsafe { *ptr = 42; }
println!("write worked");Закомментировав последнюю строку, мы видим, что чтение работает, но запись вызывает ошибку страницы:
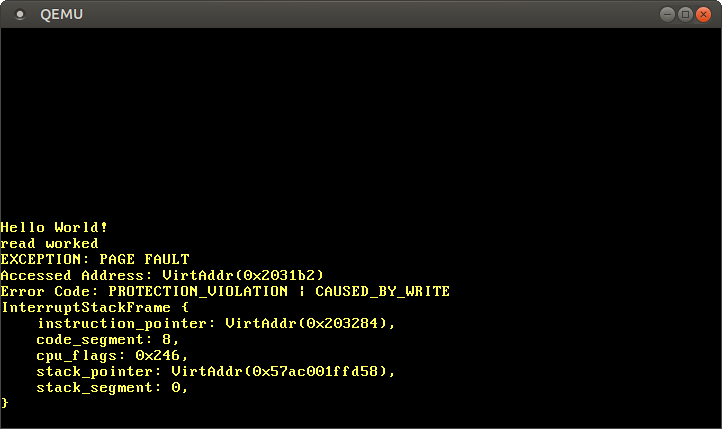
Мы видим, что выводится сообщение “read worked”, что указывает на то, что операция чтения не вызвала никаких ошибок. Однако вместо сообщения “write worked” возникает ошибка страницы. На этот раз флаг PROTECTION_VIOLATION установлен в дополнение к флагу CAUSED_BY_WRITE, что указывает на то, что страница присутствовала, но операция с ней была запрещена. В данном случае запись на страницу запрещена, поскольку страницы кодов отображаются как доступные только для чтения.
🔗Доступ к Таблицам Страниц
Давайте попробуем взглянуть на таблицы страниц, которые определяют, как организовано адресование в нашем ядре:
// src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Hello World{}", "!");
blog_os::init();
use x86_64::registers::control::Cr3;
let (level_4_page_table, _) = Cr3::read();
println!("Level 4 page table at: {:?}", level_4_page_table.start_address());
[…] // test_main(), println(…), and hlt_loop()
}Функция Cr3::read архитектуры x86_64 возвращает текущую активную таблицу страниц 4-го уровня из регистра CR3. Она возвращает кортеж, состоящий из элементов типов PhysFrame и Cr3Flags. Нас интересует только фрейм, поэтому мы игнорируем второй элемент кортежа.
При запуске мы видим следующий вывод:
Level 4 page table at: PhysAddr(0x1000)Итак, текущая активная таблица страниц 4-го уровня хранится по адресу 0x1000 в физической памяти, как указывает тип-обёртка PhysAddr. Теперь возникает вопрос: как мы можем получить доступ к этой таблице из нашего ядра?
Прямой доступ к физической памяти невозможен при включенной страничной организации памяти, поскольку в противном случае программы могли бы легко обойти механизмы защиты памяти и получить доступ к памяти других программ. Поэтому единственный способ доступа к таблице через виртуальную страницу, отображенную на физический фрейм по адресу 0x1000. Проблема создания отображений для фреймов таблицы страниц общая, поскольку ядру необходимо регулярно обращаться к таблицам страниц, например, при выделении стека для нового потока.
Решения этой проблемы подробно описаны в следующем посте.
🔗Итог
В этой статье были представлены два метода защиты памяти: сегментация и страничная организация. В то время как первый метод использует области памяти переменного размера и страдает от внешней фрагментации, второй использует страницы фиксированного размера и обеспечивает гораздо более тонкое управление правами доступа.
Страничная организация хранит информацию о сопоставлении страниц в таблицах страниц, имеющих один или несколько уровней. Архитектура x86_64 использует 4-уровневые таблицы страниц и размер страницы 4 КБ. Аппаратура автоматически просматривает таблицы страниц и кэширует полученные преобразования в буфере ассоциативной трансляции (TLB). Этот буфер обновляется неявно и требует ручной очисти при изменениях в таблицах страниц.
Мы узнали, что наше ядро уже работает на основе страничной организации памяти и что нелегальные обращения к памяти вызывают ошибку страницы (page fault). Мы пытались получить доступ к текущим активным таблицам страниц, но не смогли этого сделать, поскольку регистр CR3 хранит физический адрес, к которому мы не можем получить прямой доступ из нашего ядра.
🔗Что далее?
В следующей статье объясняется, как реализовать поддержку пагинации в нашем ядре. В ней представлены различные способы доступа к физической памяти из нашего ядра, что позволяет обращаться к таблицам страниц, на которых работает ядро. На данном этапе мы можем реализовать функции преобразования виртуальных адресов в физические, а также функции создания новых сопоставлений в таблицах страниц.
Комментарии
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English and follow Rust's code of conduct. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Пожалуйста, оставляйте комментарии на английском по возможности.