Аллокация в Куче
Переведенное содержание: Это перевод сообщества поста Heap Allocation. Он может быть неполным, устаревшим или содержать ошибки. Пожалуйста, сообщайте о любых проблемах!
Перевод сделан @TakiMoysha.
В этой статье мы добавим поддержку аллокаций памяти в куче для нашего ядра. Сначала мы рассмотрим как работает динамическая память и покажем как механизм проверки заимствований (borrow checker) предотвращает распространённые ошибки при работе с выделением памяти. Затем напишем базовый интерфейс аллокаций на Rust, создадим область памяти на куче и настроим крейт-аллокатор. К концу публикации все типы аллокаций и коллекций из встроенного крейта alloc станут доступны нашему ядру.
Этот блог открыто разрабатывается на GitHub. Если у вас есть какие-либо проблемы или вопросы, пожалуйста, создайте issue. Вы также можете оставлять комментарии внизу страницы. Полный исходный код для этого поста можно найти в ветке post-10.
Содержание
🔗Локальные и статические переменные
Сечас мы используем два типа переменных в ядре: локальные и static переменные. Локальные храняться в стеке вызовов и действительны только до возврата окружающей функции. Статические переменные храняться по фиксированному адресу памяти и живут в течение всего жизненного цикла программы.
🔗Локальные переменные
Локальные переменные хранятся в стеке вызовов - стековой структуре данных с поддержкой операции push и pop. При каждом входе в функцию компилятор помещает параметры, адрес возврата и локальные переменные вызванной функции на стеке:

Приведенный выше пример показывает стек вызовов после того, как функция outer вызвала inne. Мы видим, что стек вызовов в первую очередь содержит локальные переменные outer. При вызове inner на стек помещаются параметр 1 и адрес возврата для функции. Затем управление передается inner, которая помечает свои локальные переменные.
После того как функция inner возвращает управление, её часть стека вызовов снова удаляется, и остаются только локальные переменные outer:

Мы видим, что локальные переменные inner живут только до возврата из функции. Компилятор Rust обеспечивает соблюдение этих жизненных циклов и выдает ошибку при попытке использовать значение слишком долго, например, когда мы пытаемся вернуть ссылку на локальную переменную:
fn inner(i: usize) -> &'static u32 {
let z = [1, 2, 3];
&z[i]
}
Хотя возврат ссылки в данном примере бессмыслен, есть случаи, когда нам нужно, чтобы переменная жила дольше функции. Мы уже видели подобный случай в нашем ядре при попытке загрузить таблицу дескрипторов прерываний и были вынуждены использовать static переменную для продления жизненного цикла.
🔗Статические переменные
Статические переменные хранятся в фиксированном месте памяти, отделенном от стека. Это место назначается во время компиляции линковщиком и зашифровано в исполняемом файле. Статики живут во время всего выполнения программы, поэтому имеют жизненный цикл 'static и могут всегда ссылаться из локальных переменных:
![Тот же пример outer/inner, но inner имеет static Z: [u32; 3] = [1,2,3]; и возвращает ссылку &Z[i]](https://os.phil-opp.com/ru/heap-allocation/call-stack-static.svg)
Когда функция inner возвращается в приведённом выше примере, её часть стека вызовов уничтожается. Статические переменные живут в отдельном диапазоне памяти, который никогда не уничтожается, поэтому ссылка &Z[1] остаётся валидной даже после возврата.
Помимо жизненного цикла 'static, статические переменные также обладают полезным свойством: их адрес известен на этапе компиляции, поэтому для доступа к ним не требуется ни одна из ссылок. Мы использовали это свойство для нашего макроса println: используя статический Writer внутри, нам не нужна ссылка &mut Writer для вызова макроса, что очень полезно в обработчиках исключений, где мы не имеем доступа к каким-либо дополнительным переменным.
Однако это свойство статических переменных несёт в себе критический недостаток: по умолчанию они доступны только для чтения. Rust принуждает к этому, так как иначе может появиться гонка данных. Например, если два потока хотят изменить статическую переменную одновременно. Единственный способ изменить статическую переменную - обернуть ее в Mutex, который гарантирует, что в любой момент времени существует только одна &mut-ссылка. Мы уже использовали Mutex для нашего статического буфера VGA Writer.
🔗Динамическая память
Локальные и статические переменные уже очень мощны вместе и обеспечивают большинство use cases (использований). Однако мы увидели, что у обоих есть свои ограничения:
- Локальные переменные живут только до конца окружающей функции или блока. Это происходит потому, что они находятся на стеке вызовов и уничтожаются после возврата окружающей функции.
- Статические переменные живут в течение всего времени выполнения программы, поэтому нет способа освободить и повторно использовать их память, когда она больше не нужна. Также у них размытые семантики владения, и они доступны из всех функций, поэтому их нужно защищать с помощью
Mutex, если есть нужда в их изменении.
Другое ограничение локальных и статических переменных это их фиксированный размер. То есть они не могут хранить коллекции, которые динамически растут при добавлении новых элементов. (Есть предложение по внедрению unsized rvalues, что позволило бы использовать локальные переменные с изменяемым размером, однако это работает только в определенных случаях.)
Чтобы обойти эти недостатки, языки программирования часто поддерживают третий регион памяти для хранения переменных в куче. Куча поддерживает динамически аллоцировать память во время выполнения программы через функции allocate и deallocate. Это работает следующим образом: allocate возвращает свободный чанк памяти определенного размера, который может быть использован для размещения переменной. Эта переменная живет пока не будет вызвана функция deallocate с указателем на эту переменную.
Рассмотрим пример:
![Внутренняя функция вызывает allocate(size_of([u32; 3])), записывает z.write([1,2,3]); и возвращает (z as *mut u32).offset(i). Внешняя функция, получив значение y, выполняет deallocate(y, size_of(u32)).](https://os.phil-opp.com/ru/heap-allocation/call-stack-heap.svg)
Здесь внутренняя функция использует память heap вместо статических переменных для хранения z. Сначала она выделяет блок памяти необходимого размера, который возвращает сырой указатель (*mut u32). Затем с помощью метода ptr::write записывает в него массив [1, 2, 3]. На последнем этапе использует функцию offset для вычисления указателя на i-й элемент и возвращает его. (Обратите внимание: в этом примере функции мы упростили код, опустив некоторые обязательные приведения типов и блоки unsafe.)
Выделенная память существует до тех пор, пока её явно не освободят путём вызова deallocate. Поэтому возвращённый указатель остаётся валидным даже после того, как функция inner завершила выполнение и её часть стека была уничтожена. Преимущество использования heap-памяти по сравнению со статической в том, что после освобождения эта память может быть переиспользована - мы делаем это через вызов deallocate внутри функции outer. После этого вызова ситуация выглядит следующим образом:
![Стек вызовов содержит локальные переменные функции outer, heap-память хранит элементы z[0] и z[2], но уже не z[1].](https://os.phil-opp.com/ru/heap-allocation/call-stack-heap-freed.svg)
Мы видим, что слот z[1] снова свободен и может быть переиспользован при следующем вызове allocate. Однако также видно, что элементы z[0] и z[2] никогда не освобождены, так как мы их никогда не передали в функцию deallocate. Такой тип ошибки называется memory leak (утечка памяти) и часто приводит к чрезмерному потреблению памяти программами (представьте себе, что будет, если вызывать функцию inner многократно внутри цикла). Это может показаться неприятным, но существуют гораздо более опасные типы ошибок, возникающие при динамическом выделении.
🔗Типичные ошибки
Помимо утечек памяти, которые неприятны, но не делают программу уязвимой для атакующих, существует два типа ошибок с более серьезными последствиями:
- когда мы случайно продолжаем использовать переменную после вызова
deallocateвозникает use-after-free уязвимость. Такие ошибки приводят к неопределенному поведению и часто используются атакующими для выполнения произвольного кода. - когда мы случайно освобождаем переменную дважды, возникает уязвимость double-free. Это может привести к освобождению другого выделенного блока памяти, который был размещён в том же месте после первого вызова
deallocate. Таким образом, это снова может привести к уязвимости use-after-free.
Эти типы уязвимостей хорошо известны, поэтому можно было бы ожидать, что люди научились их избегать. Однако нет, подобные уязвимости регулярно обнаруживаются. Например, в 2019 году была найдена уязвимость use-after-free в Linux, позволяющая выполнять произвольный код. Поиск по запросу use-after-free linux {текущий год} наверняка всегда даст результаты. Это показывает, что даже лучшие программисты не всегда способны корректно управлять динамической памятью в сложных проектах.
Чтобы избежать этих проблем, многие языки, такие как Java или Python, управляют динамической памятью автоматически с помощью техники, называемой garbage collection или сборщик мусора. Идея заключается в том, что программист никогда не вызывает deallocate вручную. Вместо этого программа регулярно приостанавливается и сканируется на предмет неиспользуемых переменных heap, которые затем автоматически освобождаются. Таким образом, вышеописанные уязвимости могут никогда не возникнуть. Недостатком являются накладные расходы от регулярного сканирования и паузы во время рабты.
Rust подходит к решению этой проблемы иначе: он использует концепцию, называемую ownership (владение), которая позволяет проверять корректность операций с динамической памятью на этапе компиляции. Таким образом, для предотвращения указанных уязвимостей не требуется сборщик мусора, а значит и нету штрафов к производительности. Другим преимуществом этого подхода является то, что программист может точно настраивать поведение для данамической памяти, как в C или C++.
🔗Аллокации в Rust
Вместо того чтобы заставлять программиста вручную вызывать allocate и deallocate, стандартная библиотека Rust предоставляет абстрактные типы, которые вызывают эти функции неявно. Самый важный из них - Box, являющийся абстракцией для значения, размещенного на куче (heap). Он предоставляет конструктор Box::new, который принимает значение, вызывает allocate с размером этого значения и затем перемещает его в новый слот в памяти кучи. Чтобы освободить память кучи, тип Box реализует трейт Drop trait для вызова deallocate при выходе за пределы области видимости:
{
let z = Box::new([1,2,3]);
[…]
} // z выходит из области видимости и `deallocate` вызывается
Этот паттерн имеет странное название resource acquisition is initialization (или сокращенно RAII). Он появился в C++, где используется для реализации аналогичного абстрактного типа под названием std::unique_ptr.
Одного лишь такого типа недостаточно для предотвращения всех ошибок use-after-free, поскольку программисты все еще могут удерживать ссылки после того, как Box выйдет из области видимости и соответствующий слот памяти в куче будет освобожден:
let x = {
let z = Box::new([1,2,3]);
&z[1]
}; // z выходит из области видимости и `deallocate` вызывается
println!("{}", x);
Здесь на сцену выходит система владения (ownership) Rust. Она присваивает каждой ссылке абстрактный lifetime, который представляет собой область видимости, в которой ссылка действительна. В приведенном выше примере ссылка x берется из массива z, поэтому она становится недействительной после того, как z выйдет из области видимости. Если вы запустите приведенный выше пример в песочнице, вы увидите, что компилятор Rust генерирует ошибку:
error[E0597]: `z[_]` does not live long enough
--> src/main.rs:4:9
|
2 | let x = {
| - borrow later stored here
3 | let z = Box::new([1,2,3]);
| - binding `z` declared here
4 | &z[1]
| ^^^^^ borrowed value does not live long enough
5 | }; // z выходит из области видимости и `deallocate` вызывается
| - `z[_]` dropped here while still borrowed
Терминология в начале может быть немного запутывающей. Взятие ссылки на значение называется заимствованием (borrowing) этого значения, так как это похоже на заимствование в реальной жизни: вы получаете временный доступ к объекту, но должны его вернуть позже и не можете уничтожить его. Проверяя, что все заимствования завершаются до уничтожения объекта, компилятор Rust гарантирует, что ситуация use-after-free никогда не произойдет.
Система владения Rust заходит еще дальше: она предотвращает не только ошибки use-after-free, но и обеспечивает полную memory safety (как это делают языки с сборкой мусора, например Java или Python). Кроме того, она гарантирует thread safety и поэтому даже безопаснее этих языков при работе с многопоточным кодом. И самое главное: все эти проверки происходят на этапе компиляции, поэтому отсутствуют накладные расходы во время исполнения программы по сравнению со встроенной обработкой памяти в C.
🔗Сценарии использования
Теперь мы знаем основы динамической аллокации памяти в Rust, но когда именно нам ее использовать? Мы уже довольно далеко продвинулись с нашим ядром без динамической аллокации, так почему же нам она сейчас нужна?
Для начала - динамическая аллокация всегда несет небольшую накладную нагрузку на производительность, поскольку для каждой аллокации необходимо найти свободный слот в куче. По этой причине локальные переменные обычно предпочтительнее, особенно в коде ядра, чувствительном к производительности. Однако существуют случаи, когда динамическая аллокация является лучшим выбором.
В качестве базового правила динамическая память требуется для переменных с динамическим временем жизни или переменным размером. Самый важный тип с динамическим временем жизни это Rc, который считает количество ссылок на свое обертываемое значение и освобождает его после того, как все ссылки вышли из области видимости. Примерами типов с переменным размером являются Vec, String и другие collection types, которые динамически растут при добавлении новых элементов. Эти типы работают путем выделения большего объема памяти, когда они заполняются, копирования всех элементов в новую область и затем освобождения старой памяти.
Для нашего ядра нам будут в основном нужны типы коллекций, например, для хранения списка активных задач при реализации многозадачности в будущих постах.
🔗Интерфейс Аллокатора
Первым шагом в реализации кучевого (heap) аллокатора является добавление зависимости от встроенного крейта alloc. Подобно крейту core, он представляет собой подмножество стандартной библиотеки, которое дополнительно содержит типы для работы с памятью и коллекциями. Для добавления зависимости на alloc, мы вносим следующее изменение в наш файл lib.rs:
// src/lib.rs
extern crate alloc;
В отличие от обычных зависимостей, нам не нужно изменять файл Cargo.toml. Причиной тому является то, что крейт alloc поставляется вместе с компилятором Rust как часть стандартной библиотеки, поэтому компилятор уже знает о существовании этого крейта. Добавив эту директиву extern crate, мы указываем компилятору попытаться включить его в сборку (исторически все зависимости требовали директивы extern crate, которая теперь является опциональной).
Поскольку мы компилируем для кастомного целевого устройства, мы не можем использовать предварительно скомпилированную версию alloc, поставляемую с установкой Rust. Вместо этого нам нужно сообщить Cargo пересобрать этот крейт из исходного кода. Мы можем сделать это, добавив его в массив unstable.build-std в нашем файле .cargo/config.toml:
# .cargo/config.toml
[unstable]
build-std = ["core", "compiler_builtins", "alloc"]
Теперь компилятор пересоберет и включит крейт alloc в наше ядро.
Причина, по которой крейт alloc отключен по умолчанию в том, что для крейтах с атрибутом #[no_std] есть дополнительные требования. Когда мы попытаемся скомпилировать наш проект сейчас, увидим эти требования в виде ошибок:
error: no global memory allocator found but one is required; link to std or add
#[global_allocator] to a static item that implements the GlobalAlloc trait.
Ошибка возникает потому, что крейт alloc требует наличия heap-аллокатора - объекта, предоставляющего функции allocate и deallocate. В Rust heap-аллокатор описываются трейтом GlobalAlloc, который упомянут в сообщении об ошибке. Чтобы задать аллокатор на куче для крейта, атрибут #[global_allocator] должен быть применен к переменной static, реализующей трейт GlobalAlloc.
🔗Трейт GlobalAlloc
Трейт GlobalAlloc определяет функции, которые должен предоставлять heap-аллокатор. Этот трейт особенный тем, что программисты почти никогда не используют его напрямую. Вместо этого компилятор автоматически вставляет соответствующие вызовы методов трейта при использовании типов для работы с памятью и коллекциями из alloc.
Так как нам придется реализовать этот трейт для всех наших типов аллокаторов, стоит внимательно изучить его декларацию:
pub unsafe trait GlobalAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
unsafe fn realloc(
&self,
ptr: *mut u8,
layout: Layout,
new_size: usize
) -> *mut u8 { ... }
}
Он определяет два обязательных метода alloc и dealloc, которые соответствуют функциям allocate и deallocate, что мы использовали в наших примерах:
- Метод
allocпринимает аргумент типаLayout, который описывает желаемый размер и выравнивание (alignment), которыми должна обладать выделенная память. Он возвращает сырой указатель на первый байт выделенного блока памяти. Вместо явного значения ошибки методallocвозвращает нулевой указатель для сигнализации об ошибке выделения. Это немного неидиоматично, но имеет преимущество: облегчается создание обертки над существующими системными аллокаторами, так как они используют ту же конвенцию. - Метод
deallocявляется аналогом и отвечает за освобождение блока памяти обратно. Он принимает два аргумента: указатель, возвращенныйalloc, иLayout, использованный при выделении.
Трейт дополнительно определяет два метода alloc_zeroed и realloc с реализацией по умолчанию:
- Метод
alloc_zeroedэквивалентен вызовуalloc, за которым следует установка выделенного блока памяти в ноль, что точно делает предоставленная реализация по умолчанию. Реализация аллокатора может переопределить дефолтный более эффективной кастомной версией, если это возможно. - Метод
reallocпозволяет увеличить или уменьшить размер выделения. Реализация по умолчанию выделяет новый блок памяти с желаемым размером и копирует туда все содержимое из предыдущего выделения. Снова, реализация аллокатора может предоставить более эффективную версию этого метода, например, путем изменения размера выделение на месте (in-place), если это возможно.
🔗Ненадежность (Unsafety)
Стоит отметить одно: и сам трейт, и все его методы объявлены как unsafe:
- Причина объявления трейта как
unsafeв том, что программист должен гарантировать корректность реализации трейта для типа аллокатора. Например, методallocникогда не должен возвращать блок памяти, который уже используется где-то еще, так как это приведет к неопределенному поведению. - Аналогично, методы объявляются
unsafe, потому что вызывающая сторона должна обеспечить соблюдение различных инвариантов при их использовании. Например, переданный в методallocобъектLayoutдолжен указывать ненулевой размер. На практике это не так важно, поскольку эти методы обычно вызываются напрямую компилятором, который гарантирует выполнение требований.
🔗DummyAllocator
Теперь, когда мы знаем, что тип аллокатора должен предоставлять, можно создать простой тестовый аллокатор. Для этого создадим новый модуль allocator:
// src/lib.rs
pub mod allocator;
Наш тестовый аллокатор выполняет абсолютно минимум для реализации трейта и всегда возвращает ошибку при вызове alloc. Он выглядит следующим образом:
// src/allocator.rs
use alloc::alloc::{GlobalAlloc, Layout};
use core::ptr::null_mut;
pub struct Dummy;
unsafe impl GlobalAlloc for Dummy {
unsafe fn alloc(&self, _layout: Layout) -> *mut u8 {
null_mut()
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
panic!("dealloc should be never called")
}
}
Структура не требует каких-либо полей, поэтому мы создаем её как тип нулевого размера (zero-sized type). Как упоминалось выше, метод alloc всегда возвращает нулевой указатель, что соответствует ошибке выделения. Поскольку аллокатор никогда не возвращает память, вызов метода dealloc никогда не должен происходить. По этой причине мы просто вызываем panic! в методе dealloc. Методы alloc_zeroed и realloc имеют реализации по умолчанию, поэтому нам не нужно предоставлять свои версии для них.
Теперь у нас есть простой аллокатор, но мы всё ещё должны сообщить компилятору Rust использовать именно его. Здесь на сцену выходит атрибут #[global_allocator].
🔗Атрибут #[global_allocator]
Атрибут #[global_allocator] сообщает компилятору Rust, какой экземпляр аллокатора следует использовать в качестве глобального кучевого аллокатора. Этот атрибут применим только к переменной static, реализующей трейт GlobalAlloc. Давайте зарегистрируем экземпляр нашего аллокатора Dummy как глобальный:
// src/allocator.rs
#[global_allocator]
static ALLOCATOR: Dummy = Dummy;
Поскольку аллокатор Dummy является типом нулевого размера, нам не нужно указывать какие-либо поля в выражении инициализации.
С этим статическим объектом ошибки компиляции должны исчезнуть. Теперь мы можем использовать типы для работы с памятью и коллекциями из alloc. Например, мы можем использовать Box для выделения значения в куче:
// src/main.rs
extern crate alloc;
use alloc::boxed::Box;
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] печать "Hello World!", вызов `init`, создание `mapper` и `frame_allocator`
let x = Box::new(41);
// […] вызов `test_main` в тестовом режиме
println!("It did not crash!");
blog_os::hlt_loop();
}
Обратите внимание, что нам также необходимо указать директиву extern crate alloc в файле main.rs, потому что это части lib.rs и main.rs рассматриваются как отдельные крейты (crate). Однако создавать дополнительный статический объект #[global_allocator] не нужно, так как глобальный аллокатор применяется ко всем крейтам в проекте. Более того, указание дополнительного аллокатора в другом крейте привело бы к ошибке.
При запуске вышеуказанного кода мы увидим возникновение паники:
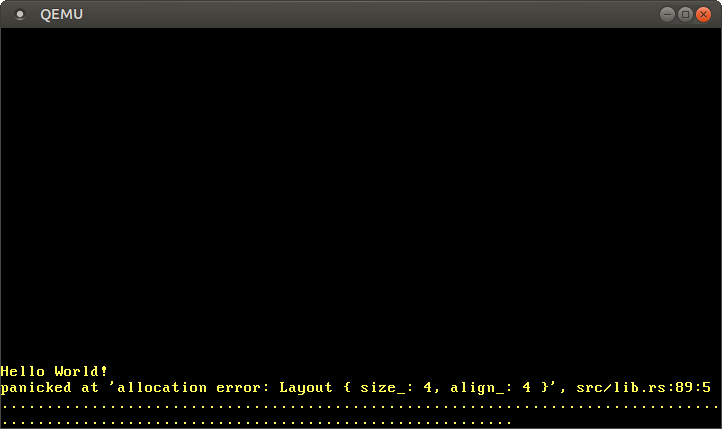
Паника возникает потому, что функция Box::new неявно вызывает функцию alloc глобального аллокатора. Наш тестовый аллокатор всегда возвращает нулевой указатель, поэтому каждое выделение памяти завершается ошибкой. Чтобы исправить это, нам нужно создать аллокатор, который действительно возвращает доступную память.
🔗Создание Кучи для Ядра
Прежде чем мы сможем создать настоящий аллокатор, сначала нужно создать область кучи в памяти, из которой он сможет аллоцировать память. Для этого необходимо определить виртуальный диапазон памяти для области кучи и затем маппнуть его на физические страницы (фреймы). См. пост Введение в пагинацию для общего обзора виртуальной памяти и таблиц страниц.
Первым шагом является определение виртуального диапазона памяти для кучи. Мы можем выбрать любой диапазон виртуальных адресов, который нам нравится, при условии, что он не занят другой областью памяти. Давайте определим его как память, начинающуюся по адресу 0x_4444_4444_0000, чтобы в дальнейшем легко идентифицировать указатели на кучу:
// src/allocator.rs
pub const HEAP_START: usize = 0x_4444_4444_0000;
pub const HEAP_SIZE: usize = 100 * 1024; // 100 KiB
Размер кучи пока установлен на 100 KiB. Если в будущем потребуется больше пространства, мы можем просто увеличить этот размер.
Если бы мы попытались использовать эту область кучи прямо сейчас, то получили бы “отказ страницы” (page fault), так как виртуальная область памяти ещё не маппнута на физическую. Для решения этой проблемы создадим функцию init_heap, которая маппнит страницы кучи с использованием Mapper API, представленного в посте “Реализация пагинации”:
// src/allocator.rs
use x86_64::{
structures::paging::{
mapper::MapToError, FrameAllocator, Mapper, Page, PageTableFlags, Size4KiB,
},
VirtAddr,
};
pub fn init_heap(
mapper: &mut impl Mapper<Size4KiB>,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) -> Result<(), MapToError<Size4KiB>> {
let page_range = {
let heap_start = VirtAddr::new(HEAP_START as u64);
let heap_end = heap_start + HEAP_SIZE - 1u64;
let heap_start_page = Page::containing_address(heap_start);
let heap_end_page = Page::containing_address(heap_end);
Page::range_inclusive(heap_start_page, heap_end_page)
};
for page in page_range {
let frame = frame_allocator
.allocate_frame()
.ok_or(MapToError::FrameAllocationFailed)?;
let flags = PageTableFlags::PRESENT | PageTableFlags::WRITABLE;
unsafe {
mapper.map_to(page, frame, flags, frame_allocator)?.flush()
};
}
Ok(())
}
Функция принимает мутабельные ссылки на экземпляр Mapper и FrameAllocator, оба ограниченные страницами размером в 4 KiB с использованием параметра общего типа Size4KiB. Функции возвращают Result с типом () для успешной операции и MapToError метода Mapper::map_to для ошибки. Повторное использование типа ошибок здесь имеет смысл, поскольку метод map_to является основным источником ошибок в этой функции.
Реализацию можно разбить на две части:
-
Создание диапазона страниц: Чтобы создать диапазон страниц, которые мы хотим маппнуть, преобразуем указатель
HEAP_STARTв типVirtAddr. Затем вычисляем конечный адрес кучи, прибавив к немуHEAP_SIZE. Нам нужен инклюзивный предел (адрес последнего байта кучи), поэтому мы вычитаем 1. Далее преобразуем адреса в типыPageс помощью функцииcontaining_address. Наконец, создаём диапазон страниц из начальной и конечной страниц с помощью функцииPage::range_inclusive. -
Маппнинг страниц: Второй шаг заключается в маппнинге всех страниц созданного диапазона. Для этого мы проходим по этим страницам через цикл
for. Для каждой страницы делаем следующее:-
Мы аллоцируем физический фрейм, к которому должна быть замаплена страница через метод
FrameAllocator::allocate_frame. Этот метод возвращаетNone, если доступных фреймов нету. В этом случае мы преобразуем результат в ошибкуMapToError::FrameAllocationFailedчерез методOption::ok_or, а затем используем оператор “вопрос” для раннего возврата ошибки. -
Мы устанавливаем для страницы необходимые флаги
PRESENTиWRITABLE. При наличии этих флагов разрешены как чтение, так и запись, что вполне уместно для куче. -
Для создания маппинга в таблице активных страниц мы используем метод
Mapper::map_to. Этот метод может завершиться с ошибкой, поэтому мы снова используем оператор “вопрос”, чтобы передать ошибку вызывающему коду. В случае успешного выполнения метод возвращает экземплярMapperFlush, который мы можем использовать для обновления буфера ассоциативной трансляции с помощью методаflush.
-
Финальным шагом является вызов этой функции из нашего kernel_main:
// src/main.rs
fn kernel_main(boot_info: &'static BootInfo) -> ! {
use blog_os::allocator; // новый импорт
use blog_os::memory::{self, BootInfoFrameAllocator};
println!("Hello World{}", "!");
blog_os::init();
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let mut mapper = unsafe { memory::init(phys_mem_offset) };
let mut frame_allocator = unsafe {
BootInfoFrameAllocator::init(&boot_info.memory_map)
};
// новый вызов
allocator::init_heap(&mut mapper, &mut frame_allocator)
.expect("heap initialization failed");
let x = Box::new(41);
// […] вызов `test_main` в тестовом режиме
println!("It did not crash!");
blog_os::hlt_loop();
}
Здесь показана функция полностью для контекста. Единственные новые строки - это импорт blog_os::allocator и вызов функции allocator::init_heap. В случае, если функция init_heap возвращает ошибку, мы вызываем панику через метод Result::expect, так как в данный момент у нас нет осмысленного способа обработать эту ошибку.
Теперь у нас есть маппнутая область памяти кучи, готовая к использованию. Вызов Box::new всё ещё использует наш старый аллокатор Dummy, поэтому при запуске вы по-прежнему увидите ошибку “недостаточно памяти”. Давайте исправим это, используя настоящий аллокатор.
🔗Использование крейта для аллокатора
Поскольку реализация собственного аллокатора несколько сложна, начнём с использования внешнего крейта для аллокаторов. В следующем посте мы изучим, как реализовать свой собственный аллокатор.
Простым крейтом для приложений no_std является linked_list_allocator. Его название происходит из того факта, что он использует структуру данных связного списка для отслеживания освобождённых областей памяти. Более подробное объяснение этого подхода смотрите в следующем посте.
Для использования крейта сначала нужно добавить зависимость от него в наш файл Cargo.toml:
# Cargo.toml
[dependencies]
linked_list_allocator = "0.9.0"
Затем мы можем заменить наш тестовый аллокатор на тот, который предоставляется крейтом:
// src/allocator.rs
use linked_list_allocator::LockedHeap;
#[global_allocator]
static ALLOCATOR: LockedHeap = LockedHeap::empty();
Структура называется LockedHeap, потому что она использует тип spinning_top::Spinlock для синхронизации. Это необходимо, поскольку несколько потоков могут одновременно получать доступ к статической переменной ALLOCATOR. Как всегда, при использовании спинлока или мьютекса нужно быть осторожным и избегать случайных взаимоблокировок (deadlocks). Это означает, что мы не должны выполнять операции аллокации в обработчиках прерываний, так как они могут выполняться в любой момент и могут прервать текущую операцию аллокации.
Просто установки LockedHeap в качестве глобального аллокатора недостаточно. Причина в том, что мы используем конструкторную функцию empty, которая создаёт аллокатор без резервирующей памяти. Как и наш dummy-аллокатор, он всегда возвращает ошибку при вызове alloc. Для исправления этого нам нужно инициализировать аллокатор после создания кучи:
// src/allocator.rs
pub fn init_heap(
mapper: &mut impl Mapper<Size4KiB>,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) -> Result<(), MapToError<Size4KiB>> {
// […] маппнит все страницы кучи на физические фреймы
// новый код
unsafe {
ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE);
}
Ok(())
}
Мы используем метод lock на внутреннем спинлоке типа LockedHeap, чтобы получить эксклюзивную ссылку на обёрнутый экземпляр Heap, на котором затем вызываем метод init с границами кучи в качестве аргументов. Поскольку функция init уже пытается записывать в память кучи, мы должны инициализировать кучу только после маппнинга страниц кучи.
После инициализации кучи мы теперь можем использовать все типы для аллокации и коллекций из встроенного крейта alloc без ошибок:
// src/main.rs
use alloc::{boxed::Box, vec, vec::Vec, rc::Rc};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] инициализация прерываний, mapper, frame_allocator, heap
// аллоцируем число в куче
let heap_value = Box::new(41);
println!("heap_value at {:p}", heap_value);
// создаём вектор динамического размера
let mut vec = Vec::new();
for i in 0..500 {
vec.push(i);
}
println!("vec at {:p}", vec.as_slice());
// создаём вектор со счётчиком ссылок -> будет освобождён, когда счётчик достигнет 0
let reference_counted = Rc::new(vec![1, 2, 3]);
let cloned_reference = reference_counted.clone();
println!("current reference count is {}", Rc::strong_count(&cloned_reference));
core::mem::drop(reference_counted);
println!("reference count is {} now", Rc::strong_count(&cloned_reference));
// […] вызов `test_main` в тестовом контексте
println!("It did not crash!");
blog_os::hlt_loop();
}
Этот пример кода демонстрирует использование типов Box, Vec и Rc. Для типов Box и Vec мы выводим базовые указатели кучи с помощью спецификатора форматирования [{:p}]. Чтобы продемонстрировать Rc, мы создаём значение в куче со счётчиком ссылок и используем функцию Rc::strong_count для вывода текущего количества ссылок до и после освобождения экземпляра (с помощью core::mem::drop).
При запуске мы видим следующее:
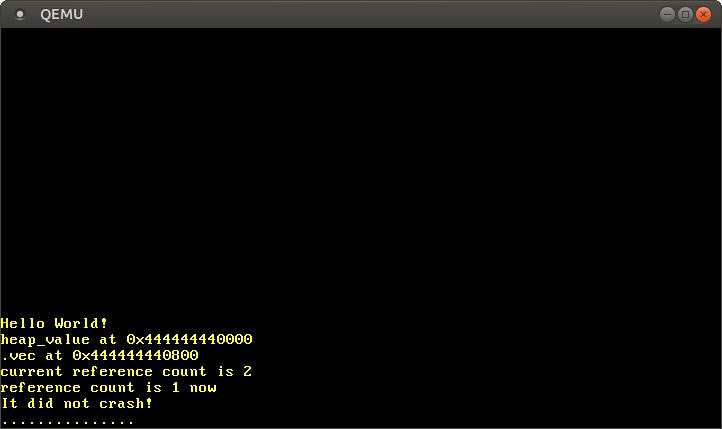
Как и ожидалось, мы видим, что значения Box и Vec находятся в куче, как это указано префиксом указателя, начинающимся с 0x_4444_4444_*. Значение со счётчиком ссылок также ведёт себя ожидаемым образом: после вызова clone счётчик равен 2, а после освобождения одного из экземпляров снова становится 1.
Причина, по которой вектор начинается со смещения 0x800, не в том, что размер упакованного значения составляет 0x800 байт, а в том, что происходят перераспределения, когда вектору необходимо увеличить свою вместимость. Например, когда вместимость вектора равна 32, и мы пытаемся добавить следующий элемент, вектор “за кулисами” выделяет новый резервный массив с вместимостью 64 и копирует туда все элементы. Затем он освобождает старое выделение.
Конечно, в крейте alloc существует множество других типов для аллокации и коллекций, которые мы теперь можем использовать в нашем ядре, включая:
- потокобезопасный указатель со счётчиком ссылок
Arc - тип владения строкой
Stringи макросformat! LinkedList- растущий кольцевой буфер
VecDeque - очередь приоритетов
BinaryHeap BTreeMapиBTreeSet
Эти типы станут очень полезными, когда мы будем реализовывать списки потоков, очереди планирования или поддержку async/await.
🔗Добавим Тесты
Что бы убедится, что мы случайно не сломали наш новый код аллокатора, мы должны добавить интеграционные тесты для него. Мы начнем с создания файла tests/heap_allocation.rs с содержимым:
// tests/heap_allocation.rs
#![no_std]
#![no_main]
#![feature(custom_test_frameworks)]
#![test_runner(blog_os::test_runner)]
#![reexport_test_harness_main = "test_main"]
extern crate alloc;
use bootloader::{entry_point, BootInfo};
use core::panic::PanicInfo;
entry_point!(main);
fn main(boot_info: &'static BootInfo) -> ! {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
Мы переиспользуем test_runner и test_panic_handler функции из lib.rs. Поскольку мы хотим тестировать аллокатор, мы включим крейт alloc через extern crate alloc. Узнать больше о шаблоне (boilerplate) ознакомьтесь с постом про тестирование.
Реализация функции main выглядит следующим образом:
// tests/heap_allocation.rs
fn main(boot_info: &'static BootInfo) -> ! {
use blog_os::allocator;
use blog_os::memory::{self, BootInfoFrameAllocator};
use x86_64::VirtAddr;
blog_os::init();
let phys_mem_offset = VirtAddr::new(boot_info.physical_memory_offset);
let mut mapper = unsafe { memory::init(phys_mem_offset) };
let mut frame_allocator = unsafe {
BootInfoFrameAllocator::init(&boot_info.memory_map)
};
allocator::init_heap(&mut mapper, &mut frame_allocator)
.expect("heap initialization failed");
test_main();
loop {}
}
Она очень похожа на функцию kernel_main из файла main.rs, за исключением того, что мы не вызываем println, не включаем примеры аллокаций и безусловно вызываем test_main.
Теперь мы готовы добавить несколько тестовых случаев. Во-первых, добавим тест, который выполняет простые аллокации используя Box и проверяет выделенные значения, чтобы убедиться, что базовые аллокации работают:
// tests/heap_allocation.rs
use alloc::boxed::Box;
#[test_case]
fn simple_allocation() {
let heap_value_1 = Box::new(41);
let heap_value_2 = Box::new(13);
assert_eq!(*heap_value_1, 41);
assert_eq!(*heap_value_2, 13);
}
Наиболее важно то, что тест проверяет отсутсвие ошибок аллокации.
Далее мы итеративно создаем большой вектор, чтобы протестировать как большие аллокации, так и множественные аллокации (из-за переаллокаций).
// tests/heap_allocation.rs
use alloc::vec::Vec;
#[test_case]
fn large_vec() {
let n = 1000;
let mut vec = Vec::new();
for i in 0..n {
vec.push(i);
}
assert_eq!(vec.iter().sum::<u64>(), (n - 1) * n / 2);
}
Мы проверяем сумму, сравнивая её с формулой для суммы первых n членов арифметической прогрессии. Это даёт нам уверенность в том, что все выделенные значения корректны.
В качестве третьего теста мы создаём десять тысяч аллокаций подряд:
// tests/heap_allocation.rs
use blog_os::allocator::HEAP_SIZE;
#[test_case]
fn many_boxes() {
for i in 0..HEAP_SIZE {
let x = Box::new(i);
assert_eq!(*x, i);
}
}
Этот тест гарантирует, что аллокатор повторно использует освобождённую память для последующих аллокаций; в противном случае память закончилась бы. Это может показаться очевидным требованием для любого аллокатора, но существуют архитектуры, которые этого не делают. Например bump-аллокатор, который будет объяснен в следующем посте.
Запустим наш новый интеграционный тест:
> cargo test --test heap_allocation
[…]
Running 3 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
Все три теста успешно прошли! Вы также можете вызвать cargo test (без аргумента --test), чтобы запустить все юнит- и интеграционные тесты.
🔗Итоги
Этот пост дал введение в динамическую память и объяснил, почему и где она необходима. Мы увидели, как механизм проверки заимствований Rust предотвращает распространённые уязвимости, и изучили работу API аллокации Rust.
После создания минимальной реализации интерфейса аллокатора Rust с использованием тестового (dummy) аллокатора, мы создали правильную область памяти в куче для нашего ядра. Для этого мы определили виртуальный диапазон адресов для кучи и затем маппнули все страницы этого диапазона на физические фреймы, используя Mapper и FrameAllocator из предыдущего поста.
В завершение мы добавили зависимость от крейта linked_list_allocator, чтобы добавить настоящий аллокатор в наше ядро. С этим аллокатором нам удалось использовать типы Box, Vec и другие типы для аллокации и коллекций из крейта alloc.
🔗Что дальше?
Хотя мы уже добавили поддержку аллокации кучи в этом посте, большую часть работы мы делегировали крейту linked_list_allocator. Следующий пост подробно покажет, как реализовать аллокатор с нуля. Он представит несколько возможных архитектур аллокаторов, продемонстрирует реализацию простых версий каждой из них и объяснит их преимущества и недостатки.
Комментарии
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English and follow Rust's code of conduct. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Пожалуйста, оставляйте комментарии на английском по возможности.