Introdução à Paginação
Conteúdo Traduzido: Esta é uma tradução comunitária do post Introduction to Paging. Pode estar incompleta, desatualizada ou conter erros. Por favor, reporte qualquer problema!
Traduzido por @richarddalves.
Esta postagem introduz paginação, um esquema de gerenciamento de memória muito comum que também usaremos para nosso sistema operacional. Ela explica por que o isolamento de memória é necessário, como segmentação funciona, o que é memória virtual, e como paginação resolve problemas de fragmentação de memória. Também explora o layout de tabelas de página multinível na arquitetura x86_64.
Este blog é desenvolvido abertamente no GitHub. Se você tiver algum problema ou dúvida, abra um issue lá. Você também pode deixar comentários na parte inferior. O código-fonte completo desta publicação pode ser encontrado na branch post-08.
Tabela de Conteúdos
🔗Proteção de Memória
Uma tarefa principal de um sistema operacional é isolar programas uns dos outros. Seu navegador web não deveria ser capaz de interferir com seu editor de texto, por exemplo. Para alcançar este objetivo, sistemas operacionais utilizam funcionalidade de hardware para garantir que áreas de memória de um processo não sejam acessíveis por outros processos. Existem diferentes abordagens dependendo do hardware e da implementação do SO.
Como exemplo, alguns processadores ARM Cortex-M (usados para sistemas embarcados) têm uma Memory Protection Unit (MPU), que permite definir um pequeno número (por exemplo, 8) de regiões de memória com diferentes permissões de acesso (por exemplo, sem acesso, somente leitura, leitura-escrita). Em cada acesso à memória, a MPU garante que o endereço está em uma região com permissões de acesso corretas e lança uma exceção caso contrário. Ao mudar as regiões e permissões de acesso em cada troca de processo, o sistema operacional pode garantir que cada processo acesse apenas sua própria memória e assim isole processos uns dos outros.
No x86, o hardware suporta duas abordagens diferentes para proteção de memória: segmentação e paginação.
🔗Segmentação
Segmentação já foi introduzida em 1978, originalmente para aumentar a quantidade de memória endereçável. A situação naquela época era que CPUs usavam apenas endereços de 16 bits, o que limitava a quantidade de memória endereçável a 64 KiB. Para tornar mais que esses 64 KiB acessíveis, registradores de segmento adicionais foram introduzidos, cada um contendo um endereço de deslocamento. A CPU automaticamente adicionava este deslocamento em cada acesso à memória, então até 1 MiB de memória era acessível.
O registrador de segmento é escolhido automaticamente pela CPU dependendo do tipo de acesso à memória: Para buscar instruções, o segmento de código CS é usado, e para operações de pilha (push/pop), o segmento de pilha SS é usado. Outras instruções usam o segmento de dados DS ou o segmento extra ES. Posteriormente, dois registradores de segmento adicionais, FS e GS, foram adicionados, que podem ser usados livremente.
Na primeira versão de segmentação, os registradores de segmento continham diretamente o deslocamento e nenhum controle de acesso era realizado. Isso mudou posteriormente com a introdução do modo protegido. Quando a CPU executa neste modo, os descritores de segmento contêm um índice em uma tabela de descritores local ou global, que contém – além de um endereço de deslocamento – o tamanho do segmento e permissões de acesso. Ao carregar tabelas de descritores globais/locais separadas para cada processo, que confinam acessos à memória às próprias áreas de memória do processo, o SO pode isolar processos uns dos outros.
Ao modificar os endereços de memória antes do acesso real, segmentação já empregava uma técnica que agora é usada em quase todo lugar: memória virtual.
🔗Memória Virtual
A ideia por trás da memória virtual é abstrair os endereços de memória do dispositivo de armazenamento físico subjacente. Em vez de acessar diretamente o dispositivo de armazenamento, um passo de tradução é realizado primeiro. Para segmentação, o passo de tradução é adicionar o endereço de deslocamento do segmento ativo. Imagine um programa acessando o endereço de memória 0x1234000 em um segmento com deslocamento de 0x1111000: O endereço que é realmente acessado é 0x2345000.
Para diferenciar os dois tipos de endereço, endereços antes da tradução são chamados virtuais, e endereços após a tradução são chamados físicos. Uma diferença importante entre esses dois tipos de endereços é que endereços físicos são únicos e sempre se referem à mesma localização de memória distinta. Endereços virtuais, por outro lado, dependem da função de tradução. É inteiramente possível que dois endereços virtuais diferentes se refiram ao mesmo endereço físico. Além disso, endereços virtuais idênticos podem se referir a endereços físicos diferentes quando usam funções de tradução diferentes.
Um exemplo onde esta propriedade é útil é executar o mesmo programa duas vezes em paralelo:

Aqui o mesmo programa executa duas vezes, mas com funções de tradução diferentes. A primeira instância tem um deslocamento de segmento de 100, então seus endereços virtuais 0–150 são traduzidos para os endereços físicos 100–250. A segunda instância tem um deslocamento de 300, que traduz seus endereços virtuais 0–150 para endereços físicos 300–450. Isso permite que ambos os programas executem o mesmo código e usem os mesmos endereços virtuais sem interferir uns com os outros.
Outra vantagem é que programas agora podem ser colocados em localizações arbitrárias de memória física, mesmo se usarem endereços virtuais completamente diferentes. Assim, o SO pode utilizar a quantidade total de memória disponível sem precisar recompilar programas.
🔗Fragmentação
A diferenciação entre endereços virtuais e físicos torna a segmentação realmente poderosa. No entanto, ela tem o problema de fragmentação. Como exemplo, imagine que queremos executar uma terceira cópia do programa que vimos acima:

Não há forma de mapear a terceira instância do programa para memória virtual sem sobreposição, mesmo que haja mais que memória livre suficiente disponível. O problema é que precisamos de memória contínua e não podemos usar os pequenos pedaços livres.
Uma forma de combater esta fragmentação é pausar a execução, mover as partes usadas da memória mais próximas, atualizar a tradução, e então retomar a execução:

Agora há espaço contínuo suficiente para iniciar a terceira instância do nosso programa.
A desvantagem deste processo de desfragmentação é que ele precisa copiar grandes quantidades de memória, o que diminui o desempenho. Também precisa ser feito regularmente antes que a memória se torne muito fragmentada. Isso torna o desempenho imprevisível já que programas são pausados em momentos aleatórios e podem se tornar não responsivos.
O problema de fragmentação é uma das razões pelas quais segmentação não é mais usada pela maioria dos sistemas. Na verdade, segmentação nem é mais suportada no modo de 64 bits no x86. Em vez disso, paginação é usada, que evita completamente o problema de fragmentação.
🔗Paginação
A ideia é dividir tanto o espaço de memória virtual quanto o físico em pequenos blocos de tamanho fixo. Os blocos do espaço de memória virtual são chamados páginas, e os blocos do espaço de endereço físico são chamados frames. Cada página pode ser individualmente mapeada para um frame, o que torna possível dividir regiões de memória maiores em frames físicos não contínuos.
A vantagem disso se torna visível se recapitularmos o exemplo do espaço de memória fragmentado, mas usando paginação em vez de segmentação desta vez:

Neste exemplo, temos um tamanho de página de 50 bytes, o que significa que cada uma de nossas regiões de memória é dividida em três páginas. Cada página é mapeada para um frame individualmente, então uma região de memória virtual contínua pode ser mapeada para frames físicos não contínuos. Isso nos permite iniciar a terceira instância do programa sem realizar nenhuma desfragmentação antes.
🔗Fragmentação Escondida
Comparado à segmentação, paginação usa muitas regiões de memória pequenas de tamanho fixo em vez de algumas regiões grandes de tamanho variável. Como cada frame tem o mesmo tamanho, não há frames que são muito pequenos para serem usados, então nenhuma fragmentação ocorre.
Ou parece que nenhuma fragmentação ocorre. Ainda há algum tipo escondido de fragmentação, a chamada fragmentação interna. Fragmentação interna ocorre porque nem toda região de memória é um múltiplo exato do tamanho da página. Imagine um programa de tamanho 101 no exemplo acima: Ele ainda precisaria de três páginas de tamanho 50, então ocuparia 49 bytes a mais que o necessário. Para diferenciar os dois tipos de fragmentação, o tipo de fragmentação que acontece ao usar segmentação é chamado fragmentação externa.
Fragmentação interna é infeliz mas frequentemente melhor que a fragmentação externa que ocorre com segmentação. Ela ainda desperdiça memória, mas não requer desfragmentação e torna a quantidade de fragmentação previsível (em média metade de uma página por região de memória).
🔗Tabelas de Página
Vimos que cada uma das potencialmente milhões de páginas é individualmente mapeada para um frame. Esta informação de mapeamento precisa ser armazenada em algum lugar. Segmentação usa um registrador seletor de segmento individual para cada região de memória ativa, o que não é possível para paginação já que há muito mais páginas que registradores. Em vez disso, paginação usa uma estrutura de tabela chamada tabela de página para armazenar a informação de mapeamento.
Para nosso exemplo acima, as tabelas de página pareceriam com isto:

Vemos que cada instância de programa tem sua própria tabela de página. Um ponteiro para a tabela atualmente ativa é armazenado em um registrador especial da CPU. No x86, este registrador é chamado CR3. É trabalho do sistema operacional carregar este registrador com o ponteiro para a tabela de página correta antes de executar cada instância de programa.
Em cada acesso à memória, a CPU lê o ponteiro da tabela do registrador e procura o frame mapeado para a página acessada na tabela. Isso é inteiramente feito em hardware e completamente invisível para o programa em execução. Para acelerar o processo de tradução, muitas arquiteturas de CPU têm um cache especial que lembra os resultados das últimas traduções.
Dependendo da arquitetura, entradas da tabela de página também podem armazenar atributos como permissões de acesso em um campo de flags. No exemplo acima, a flag “r/w” torna a página tanto legível quanto gravável.
🔗Tabelas de Página Multinível
As tabelas de página simples que acabamos de ver têm um problema em espaços de endereço maiores: elas desperdiçam memória. Por exemplo, imagine um programa que usa as quatro páginas virtuais 0, 1_000_000, 1_000_050, e 1_000_100 (usamos _ como separador de milhares):

Ele precisa apenas de 4 frames físicos, mas a tabela de página tem mais de um milhão de entradas. Não podemos omitir as entradas vazias porque então a CPU não seria mais capaz de pular diretamente para a entrada correta no processo de tradução (por exemplo, não é mais garantido que a quarta página use a quarta entrada).
Para reduzir a memória desperdiçada, podemos usar uma tabela de página de dois níveis. A ideia é que usamos tabelas de página diferentes para regiões de endereço diferentes. Uma tabela adicional chamada tabela de página de nível 2 contém o mapeamento entre regiões de endereço e tabelas de página (nível 1).
Isso é melhor explicado por um exemplo. Vamos definir que cada tabela de página de nível 1 é responsável por uma região de tamanho 10_000. Então as seguintes tabelas existiriam para o exemplo de mapeamento acima:

A página 0 cai na primeira região de 10_000 bytes, então usa a primeira entrada da tabela de página de nível 2. Esta entrada aponta para a tabela de página de nível 1 T1, que especifica que a página 0 aponta para o frame 0.
As páginas 1_000_000, 1_000_050, e 1_000_100 todas caem na 100ª região de 10_000 bytes, então usam a 100ª entrada da tabela de página de nível 2. Esta entrada aponta para uma tabela de página de nível 1 diferente T2, que mapeia as três páginas para frames 100, 150, e 200. Note que o endereço da página em tabelas de nível 1 não inclui o deslocamento da região. Por exemplo, a entrada para a página 1_000_050 é apenas 50.
Ainda temos 100 entradas vazias na tabela de nível 2, mas muito menos que o milhão de entradas vazias antes. A razão para essas economias é que não precisamos criar tabelas de página de nível 1 para as regiões de memória não mapeadas entre 10_000 e 1_000_000.
O princípio de tabelas de página de dois níveis pode ser estendido para três, quatro, ou mais níveis. Então o registrador de tabela de página aponta para a tabela de nível mais alto, que aponta para a tabela de próximo nível mais baixo, que aponta para o próximo nível mais baixo, e assim por diante. A tabela de página de nível 1 então aponta para o frame mapeado. O princípio em geral é chamado de tabela de página multinível ou hierárquica.
Agora que sabemos como paginação e tabelas de página multinível funcionam, podemos olhar como paginação é implementada na arquitetura x86_64 (assumimos no seguinte que a CPU executa no modo de 64 bits).
🔗Paginação no x86_64
A arquitetura x86_64 usa uma tabela de página de 4 níveis e um tamanho de página de 4 KiB. Cada tabela de página, independente do nível, tem um tamanho fixo de 512 entradas. Cada entrada tem um tamanho de 8 bytes, então cada tabela tem 512 * 8 B = 4 KiB de tamanho e assim cabe exatamente em uma página.
O índice da tabela de página para cada nível é derivado diretamente do endereço virtual:

Vemos que cada índice de tabela consiste de 9 bits, o que faz sentido porque cada tabela tem 2^9 = 512 entradas. Os 12 bits mais baixos são o deslocamento na página de 4 KiB (2^12 bytes = 4 KiB). Os bits 48 a 64 são descartados, o que significa que x86_64 não é realmente 64 bits já que suporta apenas endereços de 48 bits.
Mesmo que os bits 48 a 64 sejam descartados, eles não podem ser definidos para valores arbitrários. Em vez disso, todos os bits nesta faixa devem ser cópias do bit 47 para manter endereços únicos e permitir extensões futuras como a tabela de página de 5 níveis. Isso é chamado extensão de sinal porque é muito similar à extensão de sinal em complemento de dois. Quando um endereço não é corretamente estendido com sinal, a CPU lança uma exceção.
Vale notar que as CPUs Intel “Ice Lake” recentes opcionalmente suportam tabelas de página de 5 níveis para estender endereços virtuais de 48 bits para 57 bits. Dado que otimizar nosso kernel para uma CPU específica não faz sentido neste estágio, trabalharemos apenas com tabelas de página padrão de 4 níveis nesta postagem.
🔗Exemplo de Tradução
Vamos passar por um exemplo para entender como o processo de tradução funciona em detalhes:

O endereço físico da tabela de página de nível 4 atualmente ativa, que é a raiz da tabela de página de 4 níveis, é armazenado no registrador CR3. Cada entrada da tabela de página então aponta para o frame físico da tabela de próximo nível. A entrada da tabela de nível 1 então aponta para o frame mapeado. Note que todos os endereços nas tabelas de página são físicos em vez de virtuais, porque caso contrário a CPU precisaria traduzi-los também (o que poderia causar uma recursão sem fim).
A hierarquia de tabela de página acima mapeia duas páginas (em azul). Dos índices da tabela de página, podemos deduzir que os endereços virtuais dessas duas páginas são 0x803FE7F000 e 0x803FE00000. Vamos ver o que acontece quando o programa tenta ler do endereço 0x803FE7F5CE. Primeiro, convertemos o endereço para binário e determinamos os índices da tabela de página e o deslocamento de página para o endereço:

Com esses índices, agora podemos percorrer a hierarquia da tabela de página para determinar o frame mapeado para o endereço:
- Começamos lendo o endereço da tabela de nível 4 do registrador
CR3. - O índice de nível 4 é 1, então olhamos para a entrada com índice 1 daquela tabela, que nos diz que a tabela de nível 3 está armazenada no endereço 16 KiB.
- Carregamos a tabela de nível 3 daquele endereço e olhamos para a entrada com índice 0, que nos aponta para a tabela de nível 2 em 24 KiB.
- O índice de nível 2 é 511, então olhamos para a última entrada daquela página para descobrir o endereço da tabela de nível 1.
- Através da entrada com índice 127 da tabela de nível 1, finalmente descobrimos que a página está mapeada para o frame 12 KiB, ou 0x3000 em hexadecimal.
- O passo final é adicionar o deslocamento de página ao endereço do frame para obter o endereço físico 0x3000 + 0x5ce = 0x35ce.

As permissões para a página na tabela de nível 1 são r, o que significa somente leitura. O hardware reforça essas permissões e lançaria uma exceção se tentássemos escrever naquela página. Permissões em páginas de nível mais alto restringem as permissões possíveis em níveis mais baixos, então se definirmos a entrada de nível 3 como somente leitura, nenhuma página que use esta entrada pode ser gravável, mesmo se níveis mais baixos especificarem permissões de leitura/escrita.
É importante notar que mesmo que este exemplo usasse apenas uma única instância de cada tabela, tipicamente há múltiplas instâncias de cada nível em cada espaço de endereço. No máximo, há:
- uma tabela de nível 4,
- 512 tabelas de nível 3 (porque a tabela de nível 4 tem 512 entradas),
- 512 * 512 tabelas de nível 2 (porque cada uma das 512 tabelas de nível 3 tem 512 entradas), e
- 512 * 512 * 512 tabelas de nível 1 (512 entradas para cada tabela de nível 2).
🔗Formato da Tabela de Página
Tabelas de página na arquitetura x86_64 são basicamente um array de 512 entradas. Na sintaxe Rust:
#[repr(align(4096))]
pub struct PageTable {
entries: [PageTableEntry; 512],
}
Como indicado pelo atributo repr, tabelas de página precisam ser alinhadas por página, isto é, alinhadas em um limite de 4 KiB. Este requisito garante que uma tabela de página sempre preenche uma página completa e permite uma otimização que torna as entradas muito compactas.
Cada entrada tem 8 bytes (64 bits) de tamanho e tem o seguinte formato:
| Bit(s) | Nome | Significado |
|---|---|---|
| 0 | present | a página está atualmente na memória |
| 1 | writable | é permitido escrever nesta página |
| 2 | user accessible | se não definido, apenas código em modo kernel pode acessar esta página |
| 3 | write-through caching | escritas vão diretamente para a memória |
| 4 | disable cache | nenhum cache é usado para esta página |
| 5 | accessed | a CPU define este bit quando esta página é usada |
| 6 | dirty | a CPU define este bit quando uma escrita nesta página ocorre |
| 7 | huge page/null | deve ser 0 em P1 e P4, cria uma página de 1 GiB em P3, cria uma página de 2 MiB em P2 |
| 8 | global | página não é removida dos caches em troca de espaço de endereço (bit PGE do registrador CR4 deve estar definido) |
| 9-11 | available | pode ser usado livremente pelo SO |
| 12-51 | physical address | o endereço físico de 52 bits alinhado por página do frame ou da próxima tabela de página |
| 52-62 | available | pode ser usado livremente pelo SO |
| 63 | no execute | proíbe executar código nesta página (o bit NXE no registrador EFER deve estar definido) |
Vemos que apenas os bits 12–51 são usados para armazenar o endereço físico do frame. Os bits restantes são usados como flags ou podem ser usados livremente pelo sistema operacional. Isso é possível porque sempre apontamos para um endereço alinhado em 4096 bytes, seja para uma tabela de página alinhada por página ou para o início de um frame mapeado. Isso significa que os bits 0–11 são sempre zero, então não há razão para armazenar esses bits porque o hardware pode simplesmente defini-los para zero antes de usar o endereço. O mesmo é verdade para os bits 52–63, porque a arquitetura x86_64 suporta apenas endereços físicos de 52 bits (similar a como suporta apenas endereços virtuais de 48 bits).
Vamos olhar mais de perto as flags disponíveis:
- A flag
presentdiferencia páginas mapeadas de não mapeadas. Ela pode ser usada para temporariamente trocar páginas para o disco quando a memória principal fica cheia. Quando a página é acessada subsequentemente, uma exceção especial chamada page fault ocorre, à qual o sistema operacional pode reagir recarregando a página faltante do disco e então continuando o programa. - As flags
writableeno executecontrolam se o conteúdo da página é gravável ou contém instruções executáveis, respectivamente. - As flags
accessededirtysão automaticamente definidas pela CPU quando uma leitura ou escrita na página ocorre. Esta informação pode ser aproveitada pelo sistema operacional, por exemplo, para decidir quais páginas trocar ou se o conteúdo da página foi modificado desde o último salvamento no disco. - As flags
write-through cachingedisable cachepermitem o controle de caches para cada página individualmente. - A flag
user accessibletorna uma página disponível para código em espaço de usuário, caso contrário, é acessível apenas quando a CPU está em modo kernel. Este recurso pode ser usado para tornar chamadas de sistema mais rápidas mantendo o kernel mapeado enquanto um programa em espaço de usuário está executando. No entanto, a vulnerabilidade Spectre pode permitir que programas em espaço de usuário leiam essas páginas de qualquer forma. - A flag
globalsinaliza ao hardware que uma página está disponível em todos os espaços de endereço e assim não precisa ser removida do cache de tradução (veja a seção sobre o TLB abaixo) em trocas de espaço de endereço. Esta flag é comumente usada junto com uma flaguser accessibledesmarcada para mapear o código do kernel para todos os espaços de endereço. - A flag
huge pagepermite a criação de páginas de tamanhos maiores permitindo que as entradas das tabelas de página de nível 2 ou nível 3 apontem diretamente para um frame mapeado. Com este bit definido, o tamanho da página aumenta por fator 512 para 2 MiB = 512 * 4 KiB para entradas de nível 2 ou até 1 GiB = 512 * 2 MiB para entradas de nível 3. A vantagem de usar páginas maiores é que menos linhas do cache de tradução e menos tabelas de página são necessárias.
A crate x86_64 fornece tipos para tabelas de página e suas entradas, então não precisamos criar essas estruturas nós mesmos.
🔗O Translation Lookaside Buffer
Uma tabela de página de 4 níveis torna a tradução de endereços virtuais cara porque cada tradução requer quatro acessos à memória. Para melhorar o desempenho, a arquitetura x86_64 armazena em cache as últimas traduções no chamado translation lookaside buffer (TLB). Isso permite pular a tradução quando ela ainda está em cache.
Ao contrário dos outros caches da CPU, o TLB não é totalmente transparente e não atualiza ou remove traduções quando o conteúdo das tabelas de página muda. Isso significa que o kernel deve atualizar manualmente o TLB sempre que modifica uma tabela de página. Para fazer isso, há uma instrução especial da CPU chamada invlpg (“invalidate page”) que remove a tradução para a página especificada do TLB, para que seja carregada novamente da tabela de página no próximo acesso. O TLB também pode ser completamente esvaziado recarregando o registrador CR3, que simula uma troca de espaço de endereço. A crate x86_64 fornece funções Rust para ambas as variantes no módulo tlb.
É importante lembrar de esvaziar o TLB em cada modificação de tabela de página porque caso contrário a CPU pode continuar usando a tradução antiga, o que pode levar a bugs não-determinísticos que são muito difíceis de depurar.
🔗Implementação
Uma coisa que ainda não mencionamos: Nosso kernel já executa em paginação. O bootloader que adicionamos na postagem “Um Kernel Rust Mínimo” já configurou uma hierarquia de paginação de 4 níveis que mapeia cada página do nosso kernel para um frame físico. O bootloader faz isso porque paginação é obrigatória no modo de 64 bits no x86_64.
Isso significa que cada endereço de memória que usamos em nosso kernel era um endereço virtual. Acessar o buffer VGA no endereço 0xb8000 só funcionou porque o bootloader fez identity mapping daquela página de memória, o que significa que ele mapeou a página virtual 0xb8000 para o frame físico 0xb8000.
Paginação já torna nosso kernel relativamente seguro, já que cada acesso à memória que está fora dos limites causa uma exceção de page fault em vez de escrever em memória física aleatória. O bootloader até define as permissões de acesso corretas para cada página, o que significa que apenas as páginas contendo código são executáveis e apenas páginas de dados são graváveis.
🔗Page Faults
Vamos tentar causar um page fault acessando alguma memória fora do nosso kernel. Primeiro, criamos um manipulador de page fault e o registramos em nossa IDT, para que vejamos uma exceção de page fault em vez de um double fault genérico:
// em src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
[…]
idt.page_fault.set_handler_fn(page_fault_handler); // novo
idt
};
}
use x86_64::structures::idt::PageFaultErrorCode;
use crate::hlt_loop;
extern "x86-interrupt" fn page_fault_handler(
stack_frame: InterruptStackFrame,
error_code: PageFaultErrorCode,
) {
use x86_64::registers::control::Cr2;
println!("EXCEÇÃO: PAGE FAULT");
println!("Endereço Acessado: {:?}", Cr2::read());
println!("Código de Erro: {:?}", error_code);
println!("{:#?}", stack_frame);
hlt_loop();
}
O registrador CR2 é automaticamente definido pela CPU em um page fault e contém o endereço virtual acessado que causou o page fault. Usamos a função Cr2::read da crate x86_64 para lê-lo e imprimi-lo. O tipo PageFaultErrorCode fornece mais informações sobre o tipo de acesso à memória que causou o page fault, por exemplo, se foi causado por uma operação de leitura ou escrita. Por esta razão, também o imprimimos. Não podemos continuar a execução sem resolver o page fault, então entramos em um hlt_loop no final.
Agora podemos tentar acessar alguma memória fora do nosso kernel:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Olá Mundo{}", "!");
blog_os::init();
// novo
let ptr = 0xdeadbeaf as *mut u8;
unsafe { *ptr = 42; }
// como antes
#[cfg(test)]
test_main();
println!("Não crashou!");
blog_os::hlt_loop();
}
Quando o executamos, vemos que nosso manipulador de page fault é chamado:
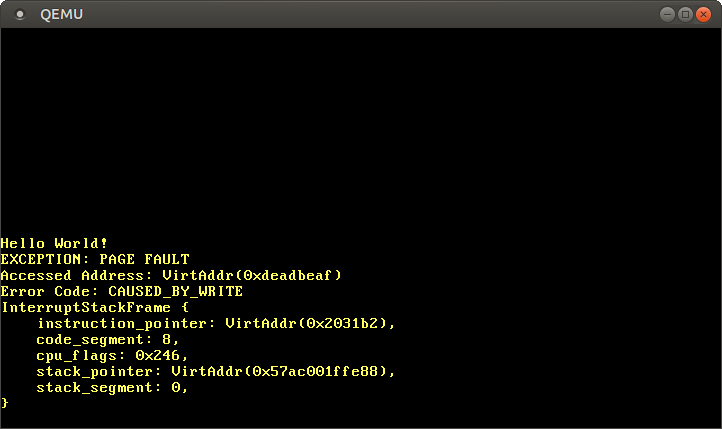
O registrador CR2 de fato contém 0xdeadbeaf, o endereço que tentamos acessar. O código de erro nos diz através do CAUSED_BY_WRITE que a falha ocorreu ao tentar realizar uma operação de escrita. Ele nos diz ainda mais através dos bits que não estão definidos. Por exemplo, o fato de que a flag PROTECTION_VIOLATION não está definida significa que o page fault ocorreu porque a página alvo não estava presente.
Vemos que o ponteiro de instrução atual é 0x2031b2, então sabemos que este endereço aponta para uma página de código. Páginas de código são mapeadas como somente leitura pelo bootloader, então ler deste endereço funciona mas escrever causa um page fault. Você pode tentar isso mudando o ponteiro 0xdeadbeaf para 0x2031b2:
// Note: O endereço real pode ser diferente para você. Use o endereço que
// seu manipulador de page fault reporta.
let ptr = 0x2031b2 as *mut u8;
// lê de uma página de código
unsafe { let x = *ptr; }
println!("leitura funcionou");
// escreve em uma página de código
unsafe { *ptr = 42; }
println!("escrita funcionou");
Ao comentar a última linha, vemos que o acesso de leitura funciona, mas o acesso de escrita causa um page fault:
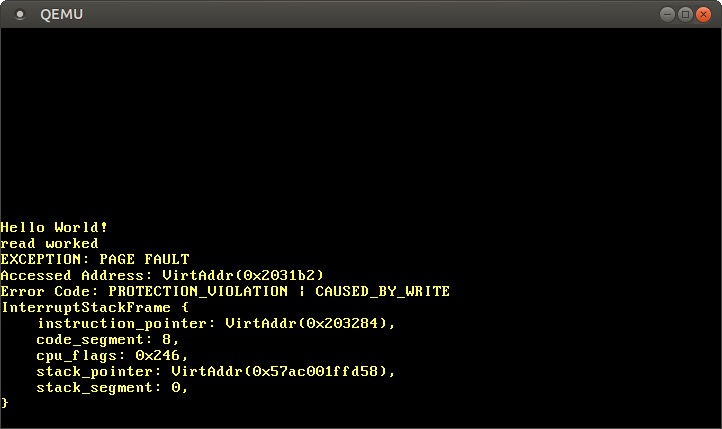
Vemos que a mensagem “leitura funcionou” é impressa, o que indica que a operação de leitura não causou nenhum erro. No entanto, em vez da mensagem “escrita funcionou”, ocorre um page fault. Desta vez a flag PROTECTION_VIOLATION está definida além da flag CAUSED_BY_WRITE, o que indica que a página estava presente, mas a operação não era permitida nela. Neste caso, escritas na página não são permitidas já que páginas de código são mapeadas como somente leitura.
🔗Acessando as Tabelas de Página
Vamos tentar dar uma olhada nas tabelas de página que definem como nosso kernel é mapeado:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
println!("Olá Mundo{}", "!");
blog_os::init();
use x86_64::registers::control::Cr3;
let (level_4_page_table, _) = Cr3::read();
println!("Tabela de página de nível 4 em: {:?}", level_4_page_table.start_address());
[…] // test_main(), println(…), e hlt_loop()
}
A função Cr3::read da crate x86_64 retorna a tabela de página de nível 4 atualmente ativa do registrador CR3. Ela retorna uma tupla de um tipo PhysFrame e um tipo Cr3Flags. Estamos interessados apenas no frame, então ignoramos o segundo elemento da tupla.
Quando o executamos, vemos a seguinte saída:
Tabela de página de nível 4 em: PhysAddr(0x1000)
Então a tabela de página de nível 4 atualmente ativa está armazenada no endereço 0x1000 na memória física, como indicado pelo tipo wrapper PhysAddr. A questão agora é: como podemos acessar esta tabela do nosso kernel?
Acessar memória física diretamente não é possível quando paginação está ativa, já que programas poderiam facilmente contornar a proteção de memória e acessar a memória de outros programas caso contrário. Então a única forma de acessar a tabela é através de alguma página virtual que está mapeada para o frame físico no endereço 0x1000. Este problema de criar mapeamentos para frames de tabela de página é um problema geral, já que o kernel precisa acessar as tabelas de página regularmente, por exemplo, ao alocar uma pilha para uma nova thread.
Soluções para este problema são explicadas em detalhes na próxima postagem.
🔗Resumo
Esta postagem introduziu duas técnicas de proteção de memória: segmentação e paginação. Enquanto a primeira usa regiões de memória de tamanho variável e sofre de fragmentação externa, a última usa páginas de tamanho fixo e permite controle muito mais refinado sobre permissões de acesso.
Paginação armazena a informação de mapeamento para páginas em tabelas de página com um ou mais níveis. A arquitetura x86_64 usa tabelas de página de 4 níveis e um tamanho de página de 4 KiB. O hardware automaticamente percorre as tabelas de página e armazena em cache as traduções resultantes no translation lookaside buffer (TLB). Este buffer não é atualizado transparentemente e precisa ser esvaziado manualmente em mudanças de tabela de página.
Aprendemos que nosso kernel já executa em cima de paginação e que acessos ilegais à memória causam exceções de page fault. Tentamos acessar as tabelas de página atualmente ativas, mas não conseguimos fazê-lo porque o registrador CR3 armazena um endereço físico que não podemos acessar diretamente do nosso kernel.
🔗O Que Vem a Seguir?
A próxima postagem explica como implementar suporte para paginação em nosso kernel. Ela apresenta diferentes formas de acessar memória física do nosso kernel, o que torna possível acessar as tabelas de página nas quais nosso kernel executa. Neste ponto, seremos capazes de implementar funções para traduzir endereços virtuais para físicos e para criar novos mapeamentos nas tabelas de página.
Comentários
Teve algum problema, quer deixar um feedback ou discutir mais ideias? Fique à vontade para deixar um comentário aqui! Por favor, use o inglês e siga o código de conduta do Rust. Este tópico de comentários está diretamente vinculado a uma discussão no GitHub, então você também pode comentar lá se preferir.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor, deixe seus comentários em inglês se possível.