Pruebas
Contenido Traducido: Esta es una traducción comunitaria del post Testing. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
Esta publicación explora las pruebas unitarias e integración en ejecutables no_std. Utilizaremos el soporte de Rust para marcos de prueba personalizados para ejecutar funciones de prueba dentro de nuestro núcleo. Para reportar los resultados fuera de QEMU, utilizaremos diferentes características de QEMU y la herramienta bootimage.
Este blog se desarrolla de manera abierta en GitHub. Si tienes algún problema o pregunta, por favor abre un problema allí. También puedes dejar comentarios en la parte inferior. El código fuente completo de esta publicación se puede encontrar en la rama post-04.
Tabla de Contenidos
🔗Requisitos
Esta publicación reemplaza las publicaciones (Pruebas Unitarias) y (Pruebas de Integración) (ahora obsoletas). Se asume que has seguido la publicación (Un Núcleo Rust Mínimo) después del 2019-04-27. Principalmente, requiere que tengas un archivo .cargo/config.toml que establezca un objetivo predeterminado y defina un ejecutable de runner.
🔗Pruebas en Rust
Rust tiene un marco de prueba incorporado que es capaz de ejecutar pruebas unitarias sin la necesidad de configurar nada. Solo crea una función que verifique algunos resultados mediante afirmaciones y añade el atributo #[test] al encabezado de la función. Luego, cargo test encontrará y ejecutará automáticamente todas las funciones de prueba de tu crate.
Desafortunadamente, es un poco más complicado para aplicaciones no_std como nuestro núcleo. El problema es que el marco de prueba de Rust utiliza implícitamente la biblioteca incorporada test, que depende de la biblioteca estándar. Esto significa que no podemos usar el marco de prueba predeterminado para nuestro núcleo #[no_std].
Podemos ver esto cuando intentamos ejecutar cargo test en nuestro proyecto:
> cargo test
Compiling blog_os v0.1.0 (/…/blog_os)
error[E0463]: can't find crate for `test`
Dado que el crate test depende de la biblioteca estándar, no está disponible para nuestro objetivo de metal desnudo. Si bien portar el crate test a un contexto #[no_std] es posible, es altamente inestable y requiere algunos hacks, como redefinir el macro panic.
🔗Marcos de Prueba Personalizados
Afortunadamente, Rust soporta reemplazar el marco de prueba predeterminado a través de la característica inestable custom_test_frameworks. Esta característica no requiere bibliotecas externas y, por lo tanto, también funciona en entornos #[no_std]. Funciona recopilando todas las funciones anotadas con un atributo #[test_case] y luego invocando una función runner especificada por el usuario con la lista de pruebas como argumento. Así, proporciona a la implementación un control máximo sobre el proceso de prueba.
La desventaja en comparación con el marco de prueba predeterminado es que muchas características avanzadas, como las pruebas should_panic, no están disponibles. En su lugar, depende de la implementación proporcionar tales características sí es necesario. Esto es ideal para nosotros ya que tenemos un entorno de ejecución muy especial en el que las implementaciones predeterminadas de tales características avanzadas probablemente no funcionarían de todos modos. Por ejemplo, el atributo #[should_panic] depende de desenrollar la pila para capturar los pánicos, lo cual hemos deshabilitado para nuestro núcleo.
Para implementar un marco de prueba personalizado para nuestro núcleo, añadimos lo siguiente a nuestro main.rs:
// en src/main.rs
#![feature(custom_test_frameworks)]
#![test_runner(crate::test_runner)]
#[cfg(test)]
pub fn test_runner(tests: &[&dyn Fn()]) {
println!("Ejecutando {} pruebas", tests.len());
for test in tests {
test();
}
}
Nuestro runner solo imprime un breve mensaje de depuración y luego llama a cada función de prueba en la lista. El tipo de argumento &[&dyn Fn()] es un slice de referencias de trait object del trait Fn(). Es básicamente una lista de referencias a tipos que pueden ser llamados como una función. Dado que la función es inútil para ejecuciones que no son de prueba, usamos el atributo #[cfg(test)] para incluirlo solo para pruebas.
Cuando ejecutamos cargo test ahora, vemos que ahora tiene éxito (si no lo tiene, consulta la nota a continuación). Sin embargo, todavía vemos nuestro “¡Hola Mundo!” en lugar del mensaje de nuestro test_runner. La razón es que nuestra función _start todavía se utiliza como punto de entrada. La característica de marcos de prueba personalizados genera una función main que llama a test_runner, pero esta función se ignora porque usamos el atributo #[no_main] y proporcionamos nuestra propia entrada.
Nota: Actualmente hay un error en cargo que conduce a errores de “elemento lang duplicado” en cargo test en algunos casos. Ocurre cuando has establecido panic = "abort" para un perfil en tu Cargo.toml. Intenta eliminarlo, luego cargo test debería funcionar. Alternativamente, si eso no funciona, añade panic-abort-tests = true a la sección [unstable] de tu archivo .cargo/config.toml. Consulta el problema de cargo para más información sobre esto.
Para solucionarlo, primero necesitamos cambiar el nombre de la función generada a algo diferente de main mediante el atributo reexport_test_harness_main. Luego podemos llamar a la función renombrada desde nuestra función _start:
// en src/main.rs
#![reexport_test_harness_main = "test_main"]
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("¡Hola Mundo{}!", "!");
#[cfg(test)]
test_main();
loop {}
}
Establecemos el nombre de la función de entrada del marco de prueba en test_main y la llamamos desde nuestro punto de entrada _start. Usamos compilación condicional para añadir la llamada a test_main solo en contextos de prueba porque la función no se genera en una ejecución normal.
Cuando ejecutamos cargo test ahora, vemos el mensaje “Ejecutando 0 pruebas” en la pantalla. Ahora estamos listos para crear nuestra primera función de prueba:
// en src/main.rs
#[test_case]
fn trivial_assertion() {
print!("aserción trivial... ");
assert_eq!(1, 1);
println!("[ok]");
}
Cuando ejecutamos cargo test ahora, vemos la siguiente salida:
![QEMU imprimiendo “¡Hola Mundo!”, “Ejecutando 1 pruebas” y “aserción trivial… [ok]”](https://os.phil-opp.com/es/testing/qemu-test-runner-output.png)
El slice tests pasado a nuestra función test_runner ahora contiene una referencia a la función trivial_assertion. A partir de la salida aserción trivial... [ok] en la pantalla, vemos que la prueba fue llamada y que tuvo éxito.
Después de ejecutar las pruebas, nuestro test_runner regresa a la función test_main, que a su vez regresa a nuestra función de entrada _start. Al final de _start, entramos en un bucle infinito porque la función de entrada no puede retornar. Este es un problema, porque queremos que cargo test salga después de ejecutar todas las pruebas.
🔗Salida de QEMU
En este momento, tenemos un bucle infinito al final de nuestra función _start y necesitamos cerrar QEMU manualmente en cada ejecución de cargo test. Esto es desafortunado porque también queremos ejecutar cargo test en scripts sin interacción del usuario. La solución limpia a esto sería implementar una forma adecuada de apagar nuestro OS. Desafortunadamente, esto es relativamente complejo porque requiere implementar soporte para el estándar de gestión de energía APM o ACPI.
Afortunadamente, hay una salida: QEMU soporta un dispositivo especial isa-debug-exit, que proporciona una forma fácil de salir de QEMU desde el sistema invitado. Para habilitarlo, necesitamos pasar un argumento -device a QEMU. Podemos hacerlo añadiendo una clave de configuración package.metadata.bootimage.test-args en nuestro Cargo.toml:
# en Cargo.toml
[package.metadata.bootimage]
test-args = ["-device", "isa-debug-exit,iobase=0xf4,iosize=0x04"]
La aplicación bootimage runner agrega los test-args al comando predeterminado de QEMU para todos los ejecutables de prueba. Para un cargo run normal, los argumentos se ignoran.
Junto con el nombre del dispositivo (isa-debug-exit), pasamos los dos parámetros iobase y iosize que especifican el puerto de E/S a través del cual se puede alcanzar el dispositivo desde nuestro núcleo.
🔗Puertos de E/S
Hay dos enfoques diferentes para comunicar entre la CPU y el hardware periférico en x86, E/S mapeada en memoria y E/S mapeada en puerto. Ya hemos utilizado E/S mapeada en memoria para acceder al buffer de texto VGA a través de la dirección de memoria 0xb8000. Esta dirección no está mapeada a RAM, sino a alguna memoria en el dispositivo VGA.
En contraste, la E/S mapeada en puerto utiliza un bus de E/S separado para la comunicación. Cada periférico conectado tiene uno o más números de puerto. Para comunicarse con dicho puerto de E/S, existen instrucciones especiales de la CPU llamadas in y out, que toman un número de puerto y un byte de datos (también hay variaciones de estos comandos que permiten enviar un u16 o u32).
El dispositivo isa-debug-exit utiliza E/S mapeada en puerto. El parámetro iobase especifica en qué dirección de puerto debe residir el dispositivo (0xf4 es un puerto generalmente no utilizado en el bus de E/S de x86) y el iosize especifica el tamaño de puerto (0x04 significa cuatro bytes).
🔗Usando el Dispositivo de Salida
La funcionalidad del dispositivo isa-debug-exit es muy simple. Cuando se escribe un valor en el puerto de E/S especificado por iobase, provoca que QEMU salga con un código de salida (valor << 1) | 1. Por lo tanto, cuando escribimos 0 en el puerto, QEMU saldrá con un código de salida (0 << 1) | 1 = 1, y cuando escribimos 1 en el puerto, saldrá con un código de salida (1 << 1) | 1 = 3.
En lugar de invocar manualmente las instrucciones de ensamblaje in y out, utilizamos las abstracciones provistas por la crate x86_64. Para añadir una dependencia en esa crate, la añadimos a la sección de dependencies en nuestro Cargo.toml:
# en Cargo.toml
[dependencies]
x86_64 = "0.14.2"
Ahora podemos usar el tipo Port proporcionado por la crate para crear una función exit_qemu:
// en src/main.rs
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
#[repr(u32)]
pub enum QemuExitCode {
Success = 0x10,
Failed = 0x11,
}
pub fn exit_qemu(exit_code: QemuExitCode) {
use x86_64::instructions::port::Port;
unsafe {
let mut port = Port::new(0xf4);
port.write(exit_code as u32);
}
}
La función crea un nuevo Port en 0xf4, que es el iobase del dispositivo isa-debug-exit. Luego escribe el código de salida pasado al puerto. Usamos u32 porque especificamos el iosize del dispositivo isa-debug-exit como 4 bytes. Ambas operaciones son inseguras porque escribir en un puerto de E/S puede resultar en un comportamiento arbitrario.
Para especificar el código de salida, creamos un enum QemuExitCode. La idea es salir con el código de salida de éxito si todas las pruebas tuvieron éxito y con el código de salida de fallo de otro modo. El enum está marcado como #[repr(u32)] para representar cada variante como un entero u32. Usamos el código de salida 0x10 para éxito y 0x11 para fallo. Los códigos de salida reales no importan mucho, siempre y cuando no choquen con los códigos de salida predeterminados de QEMU. Por ejemplo, usar el código de salida 0 para éxito no es una buena idea porque se convierte en (0 << 1) | 1 = 1 después de la transformación, que es el código de salida predeterminado cuando QEMU falla al ejecutarse. Así que no podríamos diferenciar un error de QEMU de una ejecución de prueba exitosa.
Ahora podemos actualizar nuestro test_runner para salir de QEMU después de que se hayan ejecutado todas las pruebas:
// en src/main.rs
fn test_runner(tests: &[&dyn Fn()]) {
println!("Ejecutando {} pruebas", tests.len());
for test in tests {
test();
}
/// nuevo
exit_qemu(QemuExitCode::Success);
}
Cuando ejecutamos cargo test ahora, vemos que QEMU se cierra inmediatamente después de ejecutar las pruebas. El problema es que cargo test interpreta la prueba como fallida aunque pasamos nuestro código de salida de éxito:
> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.03s
Running target/x86_64-blog_os/debug/deps/blog_os-5804fc7d2dd4c9be
Building bootloader
Compiling bootloader v0.5.3 (/home/philipp/Documents/bootloader)
Finished release [optimized + debuginfo] target(s) in 1.07s
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
deps/bootimage-blog_os-5804fc7d2dd4c9be.bin -device isa-debug-exit,iobase=0xf4,
iosize=0x04`
error: test failed, to rerun pass '--bin blog_os'
El problema es que cargo test considera todos los códigos de error que no sean 0 como fallidos.
🔗Código de salida de éxito
Para solucionar esto, bootimage proporciona una clave de configuración test-success-exit-code que mapea un código de salida especificado al código de salida 0:
# en Cargo.toml
[package.metadata.bootimage]
test-args = […]
test-success-exit-code = 33 # (0x10 << 1) | 1
Con esta configuración, bootimage mapea nuestro código de salida de éxito al código de salida 0, de modo que cargo test reconozca correctamente el caso de éxito y no cuente la prueba como fallida.
Nuestro runner de pruebas ahora cierra automáticamente QEMU y reporta correctamente los resultados de las pruebas. Aún vemos que la ventana de QEMU permanece abierta por un breve período de tiempo, pero no es suficiente para leer los resultados. Sería agradable si pudiéramos imprimir los resultados de las pruebas en la consola en su lugar, para que podamos seguir viéndolos después de que QEMU salga.
🔗Imprimiendo en la Consola
Para ver la salida de las pruebas en la consola, necesitamos enviar los datos desde nuestro núcleo al sistema host de alguna manera. Hay varias formas de lograr esto, por ejemplo, enviando los datos a través de una interfaz de red TCP. Sin embargo, configurar una pila de red es una tarea bastante compleja, por lo que elegiremos una solución más simple.
🔗Puerto Serial
Una forma simple de enviar los datos es usar el puerto serial, un estándar de interfaz antiguo que ya no se encuentra en computadoras modernas. Es fácil de programar y QEMU puede redirigir los bytes enviados a través del serial a la salida estándar del host o a un archivo.
Los chips que implementan una interfaz serial se llaman UARTs. Hay muchos modelos de UART en x86, pero afortunadamente las únicas diferencias entre ellos son algunas características avanzadas que no necesitamos. Los UART comunes hoy en día son todos compatibles con el UART 16550, así que utilizaremos ese modelo para nuestro framework de pruebas.
Usaremos la crate uart_16550 para inicializar el UART y enviar datos a través del puerto serial. Para añadirlo como dependencia, actualizamos nuestro Cargo.toml y main.rs:
# en Cargo.toml
[dependencies]
uart_16550 = "0.2.0"
La crate uart_16550 contiene una estructura SerialPort que representa los registros del UART, pero aún necesitamos construir una instancia de ella nosotros mismos. Para eso, creamos un nuevo módulo serial con el siguiente contenido:
// en src/main.rs
mod serial;
// en src/serial.rs
use uart_16550::SerialPort;
use spin::Mutex;
use lazy_static::lazy_static;
lazy_static! {
pub static ref SERIAL1: Mutex<SerialPort> = {
let mut serial_port = unsafe { SerialPort::new(0x3F8) };
serial_port.init();
Mutex::new(serial_port)
};
}
Al igual que con el buffer de texto VGA, usamos lazy_static y un spinlock para crear una instancia static de escritor. Usando lazy_static podemos asegurarnos de que el método init se llame exactamente una vez en su primer uso.
Al igual que el dispositivo isa-debug-exit, el UART se programa usando E/S de puerto. Dado que el UART es más complejo, utiliza varios puertos de E/S para programar diferentes registros del dispositivo. La función insegura SerialPort::new espera la dirección del primer puerto de E/S del UART como argumento, desde la cual puede calcular las direcciones de todos los puertos necesarios. Estamos pasando la dirección de puerto 0x3F8, que es el número de puerto estándar para la primera interfaz serial.
Para hacer que el puerto serial sea fácilmente utilizable, añadimos los macros serial_print! y serial_println!:
// en src/serial.rs
#[doc(hidden)]
pub fn _print(args: ::core::fmt::Arguments) {
use core::fmt::Write;
SERIAL1.lock().write_fmt(args).expect("Error al imprimir en serial");
}
/// Imprime en el host a través de la interfaz serial.
#[macro_export]
macro_rules! serial_print {
($($arg:tt)*) => {
$crate::serial::_print(format_args!($($arg)*));
};
}
/// Imprime en el host a través de la interfaz serial, añadiendo una nueva línea.
#[macro_export]
macro_rules! serial_println {
() => ($crate::serial_print!("\n"));
($fmt:expr) => ($crate::serial_print!(concat!($fmt, "\n")));
($fmt:expr, $($arg:tt)*) => ($crate::serial_print!(
concat!($fmt, "\n"), $($arg)*));
}
La implementación es muy similar a la implementación de nuestros macros print y println. Dado que el tipo SerialPort ya implementa el trait fmt::Write, no necesitamos proporcionar nuestra propia implementación.
Ahora podemos imprimir en la interfaz serial en lugar de en el buffer de texto VGA en nuestro código de prueba:
// en src/main.rs
#[cfg(test)]
fn test_runner(tests: &[&dyn Fn()]) {
serial_println!("Ejecutando {} pruebas", tests.len());
[…]
}
#[test_case]
fn trivial_assertion() {
serial_print!("aserción trivial... ");
assert_eq!(1, 1);
serial_println!("[ok]");
}
Ten en cuenta que el macro serial_println vive directamente en el espacio de nombres raíz porque usamos el atributo #[macro_export], por lo que importarlo a través de use crate::serial::serial_println no funcionará.
🔗Argumentos de QEMU
Para ver la salida serial de QEMU, necesitamos usar el argumento -serial para redirigir la salida a stdout:
# en Cargo.toml
[package.metadata.bootimage]
test-args = [
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio"
]
Cuando ejecutamos cargo test ahora, vemos la salida de las pruebas directamente en la consola:
> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
Building bootloader
Finished release [optimized + debuginfo] target(s) in 0.02s
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
Ejecutando 1 pruebas
aserción trivial... [ok]
Sin embargo, cuando una prueba falla, todavía vemos la salida dentro de QEMU porque nuestro manejador de pánicos todavía usa println. Para simular esto, podemos cambiar la afirmación en nuestra prueba de trivial_assertion a assert_eq!(0, 1):
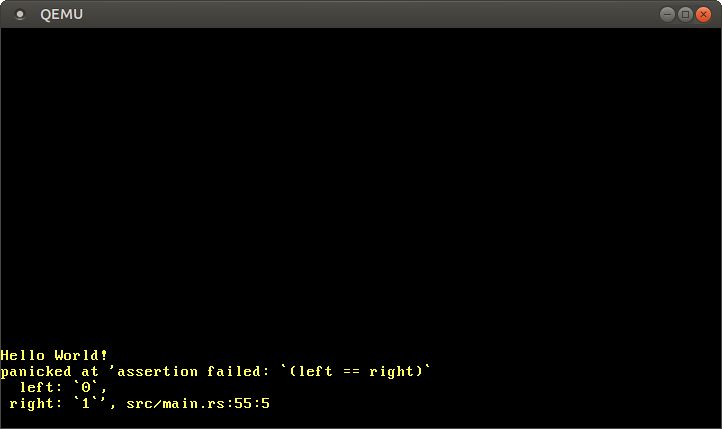
Vemos que el mensaje de pánico todavía se imprime en el buffer de VGA, mientras que la otra salida de prueba se imprime en el puerto serial. El mensaje de pánico es bastante útil, así que sería útil verlo también en la consola.
🔗Imprimir un Mensaje de Error en el Pánico
Para salir de QEMU con un mensaje de error en un pánico, podemos usar compilación condicional para usar un manejador de pánicos diferente en modo de prueba:
// en src/main.rs
// nuestro manejador de pánico existente
#[cfg(not(test))] // nuevo atributo
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
println!("{}", info);
loop {}
}
// nuestro manejador de pánico en modo de prueba
#[cfg(test)]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
serial_println!("[fallido]\n");
serial_println!("Error: {}\n", info);
exit_qemu(QemuExitCode::Failed);
loop {}
}
Para nuestro manejador de pánico en las pruebas, usamos serial_println en lugar de println y luego salimos de QEMU con un código de salida de error. Ten en cuenta que aún necesitamos un bucle infinito después de la llamada a exit_qemu porque el compilador no sabe que el dispositivo isa-debug-exit provoca una salida del programa.
Ahora QEMU también saldrá para pruebas fallidas e imprimirá un mensaje de error útil en la consola:
> cargo test
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running target/x86_64-blog_os/debug/deps/blog_os-7b7c37b4ad62551a
Building bootloader
Finished release [optimized + debuginfo] target(s) in 0.02s
Running: `qemu-system-x86_64 -drive format=raw,file=/…/target/x86_64-blog_os/debug/
deps/bootimage-blog_os-7b7c37b4ad62551a.bin -device
isa-debug-exit,iobase=0xf4,iosize=0x04 -serial stdio`
Ejecutando 1 pruebas
aserción trivial... [fallido]
Error: panicked at 'assertion failed: `(left == right)`
left: `0`,
right: `1`', src/main.rs:65:5
Dado que ahora vemos toda la salida de prueba en la consola, ya no necesitamos la ventana de QEMU que aparece por un corto período de tiempo. Así que podemos ocultarla completamente.
🔗Ocultando QEMU
Dado que reportamos todos los resultados de las pruebas utilizando el dispositivo isa-debug-exit y el puerto serial, ya no necesitamos la ventana de QEMU. Podemos ocultarla pasando el argumento -display none a QEMU:
# en Cargo.toml
[package.metadata.bootimage]
test-args = [
"-device", "isa-debug-exit,iobase=0xf4,iosize=0x04", "-serial", "stdio",
"-display", "none"
]
Ahora QEMU se ejecuta completamente en segundo plano y no se abre ninguna ventana. Esto no solo es menos molesto, sino que también permite que nuestro framework de pruebas se ejecute en entornos sin una interfaz gráfica, como servicios CI o conexiones SSH.
🔗Timeouts
Dado que cargo test espera hasta que el runner de pruebas salga, una prueba que nunca retorna puede bloquear el runner de pruebas para siempre. Eso es desafortunado, pero no es un gran problema en la práctica, ya que generalmente es fácil evitar bucles infinitos. En nuestro caso, sin embargo, pueden ocurrir bucles infinitos en varias situaciones:
- El cargador de arranque no logra cargar nuestro núcleo, lo que provoca que el sistema reinicie indefinidamente.
- El firmware BIOS/UEFI no logra cargar el cargador de arranque, lo que provoca el mismo reinicio infinito.
- La CPU entra en una instrucción
loop {}al final de algunas de nuestras funciones, por ejemplo, porque el dispositivo de salida QEMU no funciona correctamente. - El hardware provoca un reinicio del sistema, por ejemplo, cuando una excepción de CPU no es capturada (explicado en una publicación futura).
Dado que los bucles infinitos pueden ocurrir en tantas situaciones, la herramienta bootimage establece un tiempo de espera de 5 minutos para cada ejecutable de prueba de manera predeterminada. Si la prueba no termina dentro de este tiempo, se marca como fallida y se imprime un error de “Tiempo de espera”. Esta función asegura que las pruebas que están atrapadas en un bucle infinito no bloqueen cargo test para siempre.
Puedes intentarlo tú mismo añadiendo una instrucción loop {} en la prueba trivial_assertion. Cuando ejecutes cargo test, verás que la prueba se marca como expirado después de 5 minutos. La duración del tiempo de espera es configurable a través de una clave test-timeout en el Cargo.toml:
# en Cargo.toml
[package.metadata.bootimage]
test-timeout = 300 # (en segundos)
Si no quieres esperar 5 minutos para que la prueba trivial_assertion expire, puedes reducir temporalmente el valor anterior.
🔗Insertar Impresión Automáticamente
Nuestra prueba trivial_assertion actualmente necesita imprimir su propia información de estado usando serial_print!/serial_println!:
#[test_case]
fn trivial_assertion() {
serial_print!("aserción trivial... ");
assert_eq!(1, 1);
serial_println!("[ok]");
}
Añadir manualmente estas declaraciones de impresión para cada prueba que escribimos es engorroso, así que actualicemos nuestro test_runner para imprimir estos mensajes automáticamente. Para hacer eso, necesitamos crear un nuevo trait Testable:
// en src/main.rs
pub trait Testable {
fn run(&self) -> ();
}
El truco ahora es implementar este trait para todos los tipos T que implementan el trait [Fn()]:
// en src/main.rs
impl<T> Testable for T
where
T: Fn(),
{
fn run(&self) {
serial_print!("{}...\t", core::any::type_name::<T>());
self();
serial_println!("[ok]");
}
}
Implementamos la función run imprimiendo primero el nombre de la función utilizando la función any::type_name . Esta función se implementa directamente en el compilador y devuelve una descripción de cadena de cada tipo. Para las funciones, el tipo es su nombre, así que esto es exactamente lo que queremos en este caso. El carácter \t es el carácter de tabulación, que añade algo de alineación a los mensajes [ok].
Después de imprimir el nombre de la función, invocamos la función de prueba a través de self(). Esto solo funciona porque requerimos que self implemente el trait Fn(). Después de que la función de prueba retorna, imprimimos [ok] para indicar que la función no provocó un pánico.
El último paso es actualizar nuestro test_runner para usar el nuevo trait Testable:
// en src/main.rs
#[cfg(test)]
pub fn test_runner(tests: &[&dyn Testable]) { // nuevo
serial_println!("Ejecutando {} pruebas", tests.len());
for test in tests {
test.run(); // nuevo
}
exit_qemu(QemuExitCode::Success);
}
Los únicos dos cambios son el tipo del argumento tests de &[&dyn Fn()] a &[&dyn Testable] y el hecho de que ahora llamamos a test.run() en lugar de test().
Ahora podemos eliminar las declaraciones de impresión de nuestra prueba trivial_assertion ya que ahora se imprimen automáticamente:
// en src/main.rs
#[test_case]
fn trivial_assertion() {
assert_eq!(1, 1);
}
La salida de cargo test ahora se ve así:
Ejecutando 1 pruebas
blog_os::trivial_assertion... [ok]
El nombre de la función ahora incluye la ruta completa a la función, que es útil cuando las funciones de prueba en diferentes módulos tienen el mismo nombre. De lo contrario, la salida se ve igual que antes, pero ya no necesitamos agregar declaraciones de impresión a nuestras pruebas manualmente.
🔗Pruebas del Buffer VGA
Ahora que tenemos un marco de pruebas funcional, podemos crear algunas pruebas para nuestra implementación del buffer VGA. Primero, creamos una prueba muy simple para verificar que println funciona sin provocar un pánico:
// en src/vga_buffer.rs
#[test_case]
fn test_println_simple() {
println!("salida de test_println_simple");
}
La prueba simplemente imprime algo en el buffer VGA. Si termina sin provocar un pánico, significa que la invocación de println tampoco provocó un pánico.
Para asegurarnos de que no se produzca un pánico incluso si se imprimen muchas líneas y las líneas se desplazan de la pantalla, podemos crear otra prueba:
// en src/vga_buffer.rs
#[test_case]
fn test_println_many() {
for _ in 0..200 {
println!("salida de test_println_many");
}
}
También podemos crear una función de prueba para verificar que las líneas impresas realmente aparecen en la pantalla:
// en src/vga_buffer.rs
#[test_case]
fn test_println_output() {
let s = "Alguna cadena de prueba que cabe en una única línea";
println!("{}", s);
for (i, c) in s.chars().enumerate() {
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
}
La función define una cadena de prueba, la imprime usando println, y luego itera sobre los caracteres de pantalla del estático WRITER, que representa el buffer de texto VGA. Dado que println imprime en la última línea de pantalla y luego inmediatamente agrega una nueva línea, la cadena debería aparecer en la línea BUFFER_HEIGHT - 2.
Usando enumerate, contamos el número de iteraciones en la variable i, que luego utilizamos para cargar el carácter de pantalla correspondiente a c. Al comparar el ascii_character del carácter de pantalla con c, nos aseguramos de que cada carácter de la cadena realmente aparece en el buffer de texto VGA.
Como puedes imaginar, podríamos crear muchas más funciones de prueba. Por ejemplo, una función que teste que no se produzca un pánico al imprimir líneas muy largas y que se envuelvan correctamente, o una función que pruebe que se manejan correctamente nuevas líneas, caracteres no imprimibles y caracteres no unicode.
Para el resto de esta publicación, sin embargo, explicaremos cómo crear pruebas de integración para probar la interacción de diferentes componentes juntos.
🔗Pruebas de Integración
La convención para las pruebas de integración en Rust es ponerlas en un directorio tests en la raíz del proyecto (es decir, junto al directorio src). Tanto el marco de prueba predeterminado como los marcos de prueba personalizados recogerán y ejecutarán automáticamente todas las pruebas en ese directorio.
Todas las pruebas de integración son sus propios ejecutables y completamente separadas de nuestro main.rs. Esto significa que cada prueba necesita definir su propia función de punto de entrada. Creemos una prueba de integración de ejemplo llamada basic_boot para ver cómo funciona en detalle:
// en tests/basic_boot.rs
#![no_std]
#![no_main]
#![feature(custom_test_frameworks)]
#![test_runner(crate::test_runner)]
#![reexport_test_harness_main = "test_main"]
use core::panic::PanicInfo;
#[no_mangle] // no modificar el nombre de esta función
pub extern "C" fn _start() -> ! {
test_main();
loop {}
}
fn test_runner(tests: &[&dyn Fn()]) {
unimplemented!();
}
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
loop {}
}
Dado que las pruebas de integración son ejecutables separados, necesitamos proporcionar todos los atributos de crate nuevamente (no_std, no_main, test_runner, etc.). También necesitamos crear una nueva función de punto de entrada _start, que llama a la función de punto de entrada de prueba test_main. No necesitamos ningún atributo cfg(test) porque los ejecutables de prueba de integración nunca se construyen en modo no prueba.
Usamos el macro unimplemented que siempre provoca un pánico como un marcador de posición para la función test_runner y simplemente hacemos loop en el manejador de pánico por ahora. Idealmente, queremos implementar estas funciones exactamente como lo hicimos en nuestro main.rs utilizando el macro serial_println y la función exit_qemu. El problema es que no tenemos acceso a estas funciones ya que las pruebas se construyen completamente por separado de nuestro ejecutable main.rs.
Si ejecutas cargo test en esta etapa, te quedarás atrapado en un bucle infinito porque el manejador de pánicos se queda en un bucle indefinidamente. Necesitas usar el atajo de teclado ctrl+c para salir de QEMU.
🔗Crear una Biblioteca
Para que las funciones requeridas estén disponibles para nuestra prueba de integración, necesitamos separar una biblioteca de nuestro main.rs, que pueda ser incluida por otros crates y ejecutables de pruebas de integración. Para hacer esto, creamos un nuevo archivo src/lib.rs:
// src/lib.rs
#![no_std]
Al igual que main.rs, lib.rs es un archivo especial que es automáticamente reconocido por cargo. La biblioteca es una unidad de compilación separada, por lo que necesitamos especificar el atributo #![no_std] nuevamente.
Para que nuestra biblioteca funcione con cargo test, también necesitamos mover las funciones y atributos de prueba de main.rs a lib.rs:
// en src/lib.rs
#![cfg_attr(test, no_main)]
#![feature(custom_test_frameworks)]
#![test_runner(crate::test_runner)]
#![reexport_test_harness_main = "test_main"]
use core::panic::PanicInfo;
pub trait Testable {
fn run(&self) -> ();
}
impl<T> Testable for T
where
T: Fn(),
{
fn run(&self) {
serial_print!("{}...\t", core::any::type_name::<T>());
self();
serial_println!("[ok]");
}
}
pub fn test_runner(tests: &[&dyn Testable]) {
serial_println!("Ejecutando {} pruebas", tests.len());
for test in tests {
test.run();
}
exit_qemu(QemuExitCode::Success);
}
pub fn test_panic_handler(info: &PanicInfo) -> ! {
serial_println!("[fallido]\n");
serial_println!("Error: {}\n", info);
exit_qemu(QemuExitCode::Failed);
loop {}
}
/// Punto de entrada para `cargo test`
#[cfg(test)]
#[no_mangle]
pub extern "C" fn _start() -> ! {
test_main();
loop {}
}
#[cfg(test)]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
test_panic_handler(info)
}
Para hacer que nuestra test_runner esté disponible para los ejecutables y pruebas de integración, la hacemos pública y no le aplicamos el atributo cfg(test). También extraemos la implementación de nuestro manejador de pánicos en una función pública test_panic_handler, para que esté disponible para los ejecutables también.
Dado que nuestra lib.rs se prueba independientemente de main.rs, necesitamos añadir una función de entrada _start y un manejador de pánico cuando la biblioteca se compila en modo de prueba. Usando el atributo cfg_attr de crate, habilitamos condicionalmente el atributo no_main en este caso.
También movemos el enum QemuExitCode y la función exit_qemu y los hacemos públicos:
// en src/lib.rs
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
#[repr(u32)]
pub enum QemuExitCode {
Success = 0x10,
Failed = 0x11,
}
pub fn exit_qemu(exit_code: QemuExitCode) {
use x86_64::instructions::port::Port;
unsafe {
let mut port = Port::new(0xf4);
port.write(exit_code as u32);
}
}
Ahora los ejecutables y las pruebas de integración pueden importar estas funciones de la biblioteca y no necesitan definir sus propias implementaciones. Para también hacer que println y serial_println estén disponibles, movemos también las declaraciones de módulo:
// en src/lib.rs
pub mod serial;
pub mod vga_buffer;
Hacemos que los módulos sean públicos para que sean utilizables fuera de nuestra biblioteca. Esto también es necesario para hacer que nuestros macros println y serial_println sean utilizables ya que utilizan las funciones _print de los módulos.
Ahora podemos actualizar nuestro main.rs para usar la biblioteca:
// en src/main.rs
#![no_std]
#![no_main]
#![feature(custom_test_frameworks)]
#![test_runner(blog_os::test_runner)]
#![reexport_test_harness_main = "test_main"]
use core::panic::PanicInfo;
use blog_os::println;
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("¡Hola Mundo{}!", "!");
#[cfg(test)]
test_main();
loop {}
}
/// Esta función se llama en caso de pánico.
#[cfg(not(test))]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
println!("{}", info);
loop {}
}
#[cfg(test)]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
La biblioteca es utilizable como si fuera una crate externa normal. Se llama blog_os, como nuestra crate. El código anterior utiliza la función test_runner de blog_os en el atributo test_runner y la función test_panic_handler de blog_os en nuestro manejador de pánicos cfg(test). También importa el macro println para hacerlo disponible en nuestras funciones _start y panic.
En este punto, cargo run y cargo test deberían funcionar nuevamente. Por supuesto, cargo test todavía se queda atrapado en un bucle infinito (puedes salir con ctrl+c). Vamos a solucionar esto usando las funciones de biblioteca requeridas en nuestra prueba de integración.
🔗Completar la Prueba de Integración
Al igual que nuestro src/main.rs, nuestro ejecutable tests/basic_boot.rs puede importar tipos de nuestra nueva biblioteca. Esto nos permite importar los componentes faltantes para completar nuestra prueba:
// en tests/basic_boot.rs
#![test_runner(blog_os::test_runner)]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
blog_os::test_panic_handler(info)
}
En lugar de reimplementar el runner de prueba, usamos la función test_runner de nuestra biblioteca cambiando el atributo #![test_runner(crate::test_runner)] a #![test_runner(blog_os::test_runner)]. Ya no necesitamos la función de sanidad test_runner de referencia en basic_boot.rs, así que podemos eliminarla. Para nuestro manejador de pánicos, llamamos a la función blog_os::test_panic_handler como hicimos en nuestro archivo main.rs.
Ahora cargo test sale normalmente nuevamente. Cuando lo ejecutas, verás que construye y ejecuta las pruebas para lib.rs, main.rs y basic_boot.rs por separado después de cada uno. Para main.rs y las pruebas de integración basic_boot, informa “Ejecutando 0 pruebas” ya que estos archivos no tienen funciones anotadas con #[test_case].
Ahora podemos añadir pruebas a nuestro basic_boot.rs. Por ejemplo, podemos probar que println funciona sin provocar un pánico, como hicimos en las pruebas del buffer VGA:
// en tests/basic_boot.rs
use blog_os::println;
#[test_case]
fn test_println() {
println!("salida de test_println");
}
Cuando ejecutamos cargo test ahora, vemos que encuentra y ejecuta la función de prueba.
La prueba podría parecer un poco inútil ahora ya que es casi idéntica a una de las pruebas del buffer VGA. Sin embargo, en el futuro, las funciones _start de nuestros main.rs y lib.rs podrían crecer y llamar a varias rutinas de inicialización antes de ejecutar la función test_main, de modo que las dos pruebas se ejecuten en entornos muy diferentes.
Al probar println en un entorno de basic_boot sin llamar a ninguna rutina de inicialización en _start, podemos asegurarnos de que println funcione justo después de arrancar. Esto es importante porque nos basamos en ello, por ejemplo, para imprimir mensajes de pánico.
🔗Pruebas Futuras
El poder de las pruebas de integración es que se tratan como ejecutables completamente separados. Esto les da el control total sobre el entorno, lo que hace posible probar que el código interactúa correctamente con la CPU o dispositivos de hardware.
Nuestra prueba basic_boot es un ejemplo muy simple de una prueba de integración. En el futuro, nuestro núcleo se volverá mucho más funcional e interactuará con el hardware de varias maneras. Al añadir pruebas de integración, podemos asegurarnos de que estas interacciones funcionen (y sigan funcionando) como se espera. Algunas ideas para posibles pruebas futuras son:
- Excepciones de CPU: Cuando el código realiza operaciones inválidas (por ejemplo, division por cero), la CPU lanza una excepción. El núcleo puede registrar funciones de manejo para tales excepciones. Una prueba de integración podría verificar que se llame al controlador de excepciones correcto cuando ocurre una excepción de CPU o que la ejecución continúe correctamente después de una excepción recuperable.
- Tablas de Páginas: Las tablas de páginas definen qué regiones de memoria son válidas y accesibles. Al modificar las tablas de páginas, es posible asignar nuevas regiones de memoria, por ejemplo, al lanzar programas. Una prueba de integración podría modificar las tablas de páginas en la función
_starty verificar que las modificaciones tengan los efectos deseados en las funciones#[test_case]. - Programas en Espacio de Usuario: Los programas en espacio de usuario son programas con acceso limitado a los recursos del sistema. Por ejemplo, no tienen acceso a las estructuras de datos del núcleo ni a la memoria de otros programas. Una prueba de integración podría lanzar programas en espacio de usuario que realicen operaciones prohibidas y verificar que el núcleo las prevenga todas.
Como puedes imaginar, son posibles muchas más pruebas. Al añadir tales pruebas, podemos asegurarnos de no romperlas accidentalmente al añadir nuevas características a nuestro núcleo o refactorizar nuestro código. Esto es especialmente importante cuando nuestro núcleo se vuelve más grande y complejo.
🔗Pruebas que Deberían Fallar
El marco de pruebas de la biblioteca estándar admite un atributo #[should_panic] que permite construir funciones de prueba que deberían fallar. Esto es útil, por ejemplo, para verificar que una función falle cuando se pasa un argumento inválido. Desafortunadamente, este atributo no está soportado en crates #[no_std] ya que requiere soporte de la biblioteca estándar.
Si bien no podemos usar el atributo #[should_panic] en nuestro núcleo, podemos obtener un comportamiento similar creando una prueba de integración que salga con un código de error de éxito desde el manejador de pánicos. Comencemos a crear tal prueba con el nombre should_panic:
// en tests/should_panic.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
use blog_os::{QemuExitCode, exit_qemu, serial_println};
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
Esta prueba aún está incompleta ya que no define una función _start ni ninguno de los atributos del marco de prueba personalizados que faltan. Añadamos las partes que faltan:
// en tests/should_panic.rs
#![feature(custom_test_frameworks)]
#![test_runner(test_runner)]
#![reexport_test_harness_main = "test_main"]
#[no_mangle]
pub extern "C" fn _start() -> ! {
test_main();
loop {}
}
pub fn test_runner(tests: &[&dyn Fn()]) {
serial_println!("Ejecutando {} pruebas", tests.len());
for test in tests {
test();
serial_println!("[la prueba no falló]");
exit_qemu(QemuExitCode::Failed);
}
exit_qemu(QemuExitCode::Success);
}
En lugar de reutilizar el test_runner de lib.rs, la prueba define su propia función test_runner que sale con un código de error de fallo cuando una prueba retorna sin provocar un pánico (queremos que nuestras pruebas fallen). Si no se define ninguna función de prueba, el runner sale con un código de éxito. Dado que el runner siempre sale después de ejecutar una sola prueba, no tiene sentido definir más de una función #[test_case].
Ahora podemos crear una prueba que debería fallar:
// en tests/should_panic.rs
use blog_os::serial_print;
#[test_case]
fn should_fail() {
serial_print!("should_panic::should_fail...\t");
assert_eq!(0, 1);
}
La prueba utiliza assert_eq para afirmar que 0 y 1 son iguales. Por supuesto, esto falla, por lo que nuestra prueba provoca un pánico como se deseaba. Ten en cuenta que necesitamos imprimir manualmente el nombre de la función usando serial_print! aquí porque no usamos el trait Testable.
Cuando ejecutamos la prueba a través de cargo test --test should_panic vemos que es exitosa porque la prueba se produjo como se esperaba. Cuando comentamos la afirmación y ejecutamos la prueba nuevamente, vemos que, de hecho, falla con el mensaje “la prueba no falló”.
Una gran desventaja de este enfoque es que solo funciona para una única función de prueba. Con múltiples funciones #[test_case], solo se ejecuta la primera función porque la ejecución no puede continuar después de que se ha llamado al manejador de pánicos. Actualmente no sé una buena manera de resolver este problema, ¡así que házmelo saber si tienes una idea!
🔗Pruebas Sin Harness
Para las pruebas de integración que solo tienen una única función de prueba (como nuestra prueba should_panic), el runner de prueba no es realmente necesario. Para casos como este, podemos deshabilitar completamente el runner de pruebas y ejecutar nuestra prueba directamente en la función _start.
La clave para esto es deshabilitar la bandera harness para la prueba en el Cargo.toml, que define si se usa un runner de prueba para una prueba de integración. Cuando está configurada como false, se desactivan tanto el marco de prueba predeterminado como la característica de marcos de prueba personalizados, por lo que la prueba se trata como un ejecutable normal.
Deshabilitemos la bandera harness para nuestra prueba should_panic:
# en Cargo.toml
[[test]]
name = "should_panic"
harness = false
Ahora simplificamos enormemente nuestra prueba should_panic al eliminar el código relacionado con el test_runner. El resultado se ve así:
// en tests/should_panic.rs
#![no_std]
#![no_main]
use core::panic::PanicInfo;
use blog_os::{exit_qemu, serial_print, serial_println, QemuExitCode};
#[no_mangle]
pub extern "C" fn _start() -> ! {
should_fail();
serial_println!("[la prueba no falló]");
exit_qemu(QemuExitCode::Failed);
loop{}
}
fn should_fail() {
serial_print!("should_panic::should_fail...\t");
assert_eq!(0, 1);
}
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
serial_println!("[ok]");
exit_qemu(QemuExitCode::Success);
loop {}
}
Ahora llamamos a la función should_fail directamente desde nuestra función _start y salimos con un código de error de fallo si retorna. Cuando ejecutamos cargo test --test should_panic ahora, vemos que la prueba se comporta exactamente como antes.
Además de crear pruebas should_panic, deshabilitar el atributo harness también puede ser útil para pruebas de integración complejas, por ejemplo, cuando las funciones de prueba individuales tienen efectos secundarios y necesitan ejecutarse en un orden específico.
🔗Resumen
Las pruebas son una técnica muy útil para asegurarse de que ciertos componentes tengan el comportamiento deseado. Aunque no pueden mostrar la ausencia de errores, siguen siendo una herramienta útil para encontrarlos y especialmente para evitar regresiones.
Esta publicación explicó cómo configurar un marco de pruebas para nuestro núcleo Rust. Utilizamos la característica de marcos de prueba personalizados de Rust para implementar el soporte para un simple atributo #[test_case] en nuestro entorno de metal desnudo. Usando el dispositivo isa-debug-exit de QEMU, nuestro runner de pruebas puede salir de QEMU después de ejecutar las pruebas y reportar el estado de las pruebas. Para imprimir mensajes de error en la consola en lugar de en el buffer de VGA, creamos un controlador básico para el puerto serial.
Después de crear algunas pruebas para nuestro macro println, exploramos las pruebas de integración en la segunda mitad de la publicación. Aprendimos que viven en el directorio tests y se tratan como ejecutables completamente separados. Para dar acceso a la función exit_qemu y al macro serial_println, movimos la mayor parte de nuestro código a una biblioteca que pueden importar todos los ejecutables y pruebas de integración. Dado que las pruebas de integración se ejecutan en su propio entorno separado, permiten probar interacciones con el hardware o crear pruebas que deberían provocar pánicos.
Ahora tenemos un marco de pruebas que se ejecuta en un entorno realista dentro de QEMU. Al crear más pruebas en publicaciones futuras, podemos mantener nuestro núcleo manejable a medida que se vuelva más complejo.
🔗¿Qué sigue?
En la próxima publicación, exploraremos excepciones de CPU. Estas excepciones son lanzadas por la CPU cuando ocurre algo ilegal, como una división por cero o un acceso a una página de memoria no mapeada (una llamada “falta de página”). Poder capturar y examinar estas excepciones es muy importante para depurar futuros errores. El manejo de excepciones también es muy similar al manejo de interrupciones de hardware, que es necesario para el soporte del teclado.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.