Introducción a la Paginación
Contenido Traducido: Esta es una traducción comunitaria del post Introduction to Paging. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
Esta publicación introduce la paginación (paging), un esquema de gestión de memoria muy común que también utilizaremos para nuestro sistema operativo. Explica por qué se necesita la aislamiento de memoria, cómo funciona la segmentación (segmentation), qué es la memoria virtual (virtual memory) y cómo la paginación soluciona los problemas de fragmentación de memoria. También explora el diseño de las tablas de páginas multinivel en la arquitectura x86_64.
Este blog se desarrolla abiertamente en GitHub. Si tienes algún problema o pregunta, por favor abre un issue allí. También puedes dejar comentarios al final. El código fuente completo de esta publicación se puede encontrar en la rama post-08.
Tabla de Contenidos
🔗Protección de Memoria
Una de las principales tareas de un sistema operativo es aislar programas entre sí. Tu navegador web no debería poder interferir con tu editor de texto, por ejemplo. Para lograr este objetivo, los sistemas operativos utilizan funcionalidades de hardware para asegurarse de que las áreas de memoria de un proceso no sean accesibles por otros procesos. Hay diferentes enfoques dependiendo del hardware y la implementación del sistema operativo.
Como ejemplo, algunos procesadores ARM Cortex-M (usados en sistemas embebidos) tienen una Unidad de Protección de Memoria (Memory Protection Unit, MPU), que permite definir un pequeño número (por ejemplo, 8) de regiones de memoria con diferentes permisos de acceso (por ejemplo, sin acceso, solo lectura, lectura-escritura). En cada acceso a la memoria, la MPU asegura que la dirección esté en una región con permisos de acceso correctos y lanza una excepción en caso contrario. Al cambiar las regiones y los permisos de acceso en cada cambio de proceso, el sistema operativo puede asegurarse de que cada proceso solo acceda a su propia memoria y, por lo tanto, aísla los procesos entre sí.
En x86, el hardware admite dos enfoques diferentes para la protección de memoria: segmentación y paginación.
🔗Segmentación
La segmentación fue introducida en 1978, originalmente para aumentar la cantidad de memoria direccionable. La situación en ese entonces era que las CPU solo usaban direcciones de 16 bits, lo que limitaba la cantidad de memoria direccionable a 64 KiB. Para hacer accesibles más de estos 64 KiB, se introdujeron registros de segmento adicionales, cada uno conteniendo una dirección de desplazamiento. La CPU sumaba automáticamente este desplazamiento en cada acceso a la memoria, de modo que hasta 1 MiB de memoria era accesible.
El registro del segmento es elegido automáticamente por la CPU dependiendo del tipo de acceso a la memoria: para obtener instrucciones, se utiliza el segmento de código CS, y para operaciones de pila (push/pop), se utiliza el segmento de pila SS. Otras instrucciones utilizan el segmento de datos DS o el segmento adicional ES. Más tarde, se añadieron dos registros de segmento adicionales, FS y GS, que pueden ser utilizados libremente.
En la primera versión de la segmentación, los registros de segmento contenían directamente el desplazamiento y no se realizaba control de acceso. Esto se cambió más tarde con la introducción del modo protegido (protected mode). Cuando la CPU funciona en este modo, los descriptores de segmento contienen un índice a una tabla de descriptores local o global, que contiene – además de una dirección de desplazamiento – el tamaño del segmento y los permisos de acceso. Al cargar tablas de descriptores globales/locales separadas para cada proceso, que confinan los accesos de memoria a las áreas de memoria del propio proceso, el sistema operativo puede aislar los procesos entre sí.
Al modificar las direcciones de memoria antes del acceso real, la segmentación ya utilizaba una técnica que ahora se usa casi en todas partes: memoria virtual (virtual memory).
🔗Memoria Virtual
La idea detrás de la memoria virtual es abstraer las direcciones de memoria del dispositivo de almacenamiento físico subyacente. En lugar de acceder directamente al dispositivo de almacenamiento, se realiza primero un paso de traducción. Para la segmentación, el paso de traducción consiste en agregar la dirección de desplazamiento del segmento activo. Imagina un programa que accede a la dirección de memoria 0x1234000 en un segmento con un desplazamiento de 0x1111000: La dirección que realmente se accede es 0x2345000.
Para diferenciar los dos tipos de direcciones, se llaman virtuales a las direcciones antes de la traducción, y físicas a las direcciones después de la traducción. Una diferencia importante entre estos dos tipos de direcciones es que las direcciones físicas son únicas y siempre se refieren a la misma ubicación de memoria distinta. Las direcciones virtuales, en cambio, dependen de la función de traducción. Es completamente posible que dos direcciones virtuales diferentes se refieran a la misma dirección física. Además, direcciones virtuales idénticas pueden referirse a diferentes direcciones físicas cuando utilizan diferentes funciones de traducción.
Un ejemplo donde esta propiedad es útil es ejecutar el mismo programa en paralelo dos veces:

Aquí el mismo programa se ejecuta dos veces, pero con diferentes funciones de traducción. La primera instancia tiene un desplazamiento de segmento de 100, de manera que sus direcciones virtuales 0–150 se traducen a las direcciones físicas 100–250. La segunda instancia tiene un desplazamiento de 300, que traduce sus direcciones virtuales 0–150 a direcciones físicas 300–450. Esto permite que ambos programas ejecuten el mismo código y utilicen las mismas direcciones virtuales sin interferir entre sí.
Otra ventaja es que los programas ahora se pueden colocar en ubicaciones de memoria física arbitrarias, incluso si utilizan direcciones virtuales completamente diferentes. Por lo tanto, el sistema operativo puede utilizar la cantidad total de memoria disponible sin necesidad de recompilar programas.
🔗Fragmentación
La diferenciación entre direcciones virtuales y físicas hace que la segmentación sea realmente poderosa. Sin embargo, tiene el problema de la fragmentación. Como ejemplo, imagina que queremos ejecutar una tercera copia del programa que vimos anteriormente:

No hay forma de mapear la tercera instancia del programa a la memoria virtual sin superposición, a pesar de que hay más que suficiente memoria libre disponible. El problema es que necesitamos memoria continua y no podemos utilizar los pequeños fragmentos libres.
Una forma de combatir esta fragmentación es pausar la ejecución, mover las partes utilizadas de la memoria más cerca entre sí, actualizar la traducción y luego reanudar la ejecución:

Ahora hay suficiente espacio continuo para iniciar la tercera instancia de nuestro programa.
La desventaja de este proceso de desfragmentación es que necesita copiar grandes cantidades de memoria, lo que disminuye el rendimiento. También necesita hacerse regularmente antes de que la memoria se fragmenta demasiado. Esto hace que el rendimiento sea impredecible, ya que los programas son pausados en momentos aleatorios y podrían volverse no responsivos.
El problema de la fragmentación es una de las razones por las que la segmentación ya no se utiliza en la mayoría de los sistemas. De hecho, la segmentación ni siquiera es compatible en el modo de 64 bits en x86. En su lugar, se utiliza paginación (paging), que evita por completo el problema de la fragmentación.
🔗Paginación
La idea es dividir tanto el espacio de memoria virtual como el físico en bloques pequeños de tamaño fijo. Los bloques del espacio de memoria virtual se llaman páginas (pages), y los bloques del espacio de direcciones físicas se llaman marcos (frames). Cada página puede ser mapeada individualmente a un marco, lo que hace posible dividir regiones de memoria más grandes a través de marcos físicos no consecutivos.
La ventaja de esto se ve claramente si recapitulamos el ejemplo del espacio de memoria fragmentado, pero usamos paginación en lugar de segmentación esta vez:

En este ejemplo, tenemos un tamaño de página de 50 bytes, lo que significa que cada una de nuestras regiones de memoria se divide en tres páginas. Cada página se mapea a un marco individualmente, por lo que una región de memoria virtual continua puede ser mapeada a marcos físicos no continuos. Esto nos permite iniciar la tercera instancia del programa sin realizar ninguna desfragmentación antes.
🔗Fragmentación Oculta
En comparación con la segmentación, la paginación utiliza muchas pequeñas regiones de memoria de tamaño fijo en lugar de unas pocas grandes regiones de tamaño variable. Dado que cada marco tiene el mismo tamaño, no hay marcos que sean demasiado pequeños para ser utilizados, por lo que no ocurre fragmentación.
O parece que no ocurre fragmentación. Aún existe algún tipo oculto de fragmentación, la llamada fragmentación interna (internal fragmentation). La fragmentación interna ocurre porque no cada región de memoria es un múltiplo exacto del tamaño de la página. Imagina un programa de tamaño 101 en el ejemplo anterior: aún necesitaría tres páginas de tamaño 50, por lo que ocuparía 49 bytes más de lo necesario. Para diferenciar los dos tipos de fragmentación, el tipo de fragmentación que ocurre al usar segmentación se llama fragmentación externa (external fragmentation).
La fragmentación interna es desafortunada pero a menudo es mejor que la fragmentación externa que ocurre con la segmentación. Aún desperdicia memoria, pero no requiere desfragmentación y hace que la cantidad de fragmentación sea predecible (en promedio, media página por región de memoria).
🔗Tablas de Páginas
Vimos que cada una de las potencialmente millones de páginas se mapea individualmente a un marco. Esta información de mapeo necesita ser almacenada en algún lugar. La segmentación utiliza un registro de selector de segmento individual para cada región de memoria activa, lo cual no es posible para la paginación, ya que hay muchas más páginas que registros. En su lugar, la paginación utiliza una estructura tabular llamada tabla de páginas (page table) para almacenar la información de mapeo.
Para nuestro ejemplo anterior, las tablas de páginas se verían así:

Vemos que cada instancia del programa tiene su propia tabla de páginas. Un puntero a la tabla actualmente activa se almacena en un registro especial de la CPU. En x86, este registro se llama CR3. Es trabajo del sistema operativo cargar este registro con el puntero a la tabla de páginas correcta antes de ejecutar cada instancia del programa.
En cada acceso a la memoria, la CPU lee el puntero de la tabla del registro y busca el marco mapeado para la página accedida en la tabla. Esto se realiza completamente en hardware y es completamente invisible para el programa en ejecución. Para agilizar el proceso de traducción, muchas arquitecturas de CPU tienen una caché especial que recuerda los resultados de las últimas traducciones.
Dependiendo de la arquitectura, las entradas de las tablas de páginas también pueden almacenar atributos como permisos de acceso en un campo de banderas. En el ejemplo anterior, la bandera “r/w” hace que la página sea tanto legible como escribible.
🔗Tablas de Páginas multinivel
Las simples tablas de páginas que acabamos de ver tienen un problema en espacios de direcciones más grandes: desperdician memoria. Por ejemplo, imagina un programa que utiliza las cuatro páginas virtuales 0, 1_000_000, 1_000_050 y 1_000_100 (usamos _ como separador de miles):

Solo necesita 4 marcos físicos, pero la tabla de páginas tiene más de un millón de entradas. No podemos omitir las entradas vacías porque entonces la CPU ya no podría saltar directamente a la entrada correcta en el proceso de traducción (por ejemplo, ya no se garantiza que la cuarta página use la cuarta entrada).
Para reducir la memoria desperdiciada, podemos usar una tabla de páginas de dos niveles. La idea es que utilizamos diferentes tablas de páginas para diferentes regiones de direcciones. Una tabla adicional llamada tabla de páginas nivel 2 (level 2) contiene el mapeo entre las regiones de direcciones y las tablas de páginas (nivel 1).
Esto se explica mejor con un ejemplo. Supongamos que cada tabla de páginas de nivel 1 es responsable de una región de tamaño 10_000. Entonces, las siguientes tablas existirían para el mapeo anterior:

La página 0 cae en la primera región de 10_000 bytes, por lo que utiliza la primera entrada de la tabla de páginas de nivel 2. Esta entrada apunta a la tabla de páginas de nivel 1 T1, que especifica que la página 0 apunta al marco 0.
Las páginas 1_000_000, 1_000_050 y 1_000_100 caen todas en la entrada número 100 de la región de 10_000 bytes, por lo que utilizan la entrada 100 de la tabla de páginas de nivel 2. Esta entrada apunta a una tabla de páginas de nivel 1 diferente T2, que mapea las tres páginas a los marcos 100, 150 y 200. Ten en cuenta que la dirección de página en las tablas de nivel 1 no incluye el desplazamiento de región. Por ejemplo, la entrada para la página 1_000_050 es solo 50.
Aún tenemos 100 entradas vacías en la tabla de nivel 2, pero muchas menos que el millón de entradas vacías de antes. La razón de este ahorro es que no necesitamos crear tablas de páginas de nivel 1 para las regiones de memoria no mapeadas entre 10_000 y 1_000_000.
El principio de las tablas de páginas de dos niveles se puede extender a tres, cuatro o más niveles. Luego, el registro de la tabla de páginas apunta a la tabla de nivel más alto, que apunta a la tabla de nivel más bajo, que apunta a la siguiente tabla de nivel inferior, y así sucesivamente. La tabla de páginas de nivel 1 luego apunta al marco mapeado. El principio en general se llama tabla de páginas multinivel (multilevel page table) o jerárquica.
Ahora que sabemos cómo funcionan la paginación y las tablas de páginas multinivel, podemos ver cómo se implementa la paginación en la arquitectura x86_64 (suponemos en lo siguiente que la CPU funciona en modo de 64 bits).
🔗Paginación en x86_64
La arquitectura x86_64 utiliza una tabla de páginas de 4 niveles y un tamaño de página de 4 KiB. Cada tabla de páginas, independientemente del nivel, tiene un tamaño fijo de 512 entradas. Cada entrada tiene un tamaño de 8 bytes, por lo que cada tabla tiene un tamaño de 512 * 8 B = 4 KiB y, por lo tanto, encaja exactamente en una página.
El índice de la tabla de páginas para cada nivel se deriva directamente de la dirección virtual:

Vemos que cada índice de tabla consta de 9 bits, lo que tiene sentido porque cada tabla tiene 2^9 = 512 entradas. Los 12 bits más bajos son el desplazamiento en la página de 4 KiB (2^12 bytes = 4 KiB). Los bits 48 a 64 se descartan, lo que significa que x86_64 no es realmente de 64 bits, ya que solo admite direcciones de 48 bits.
A pesar de que se descartan los bits 48 a 64, no pueden establecerse en valores arbitrarios. En cambio, todos los bits en este rango deben ser copias del bit 47 para mantener las direcciones únicas y permitir extensiones futuras como la tabla de páginas de 5 niveles. Esto se llama extensión de signo (sign-extension) porque es muy similar a la extensión de signo en complemento a dos. Cuando una dirección no está correctamente extendida de signo, la CPU lanza una excepción.
Cabe destacar que los recientes procesadores Intel “Ice Lake” admiten opcionalmente tablas de páginas de 5 niveles para extender las direcciones virtuales de 48 bits a 57 bits. Dado que optimizar nuestro núcleo para una CPU específica no tiene sentido en esta etapa, solo trabajaremos con tablas de páginas de 4 niveles estándar en esta publicación.
🔗Ejemplo de Traducción
Pasemos por un ejemplo para entender cómo funciona el proceso de traducción en detalle:

La dirección física de la tabla de páginas de nivel 4 actualmente activa, que es la raíz de la tabla de páginas de 4 niveles, se almacena en el registro CR3. Cada entrada de la tabla de nivel 1 luego apunta al marco físico de la tabla del siguiente nivel. La entrada de la tabla de nivel 1 luego apunta al marco mapeado. Ten en cuenta que todas las direcciones en las tablas de páginas son físicas en lugar de virtuales, porque de lo contrario la CPU también necesitaría traducir esas direcciones (lo que podría provocar una recursión interminable).
La jerarquía de tablas de páginas anterior mapea dos páginas (en azul). A partir de los índices de la tabla de páginas, podemos deducir que las direcciones virtuales de estas dos páginas son 0x803FE7F000 y 0x803FE00000. Veamos qué sucede cuando el programa intenta leer desde la dirección 0x803FE7F5CE. Primero, convertimos la dirección a binario y determinamos los índices de la tabla de páginas y el desplazamiento de la página para la dirección:

Con estos índices, ahora podemos recorrer la jerarquía de la tabla de páginas para determinar el marco mapeado para la dirección:
- Comenzamos leyendo la dirección de la tabla de nivel 4 del registro
CR3. - El índice de nivel 4 es 1, así que miramos la entrada en el índice 1 de esa tabla, que nos dice que la tabla de nivel 3 se almacena en la dirección 16 KiB.
- Cargamos la tabla de nivel 3 desde esa dirección y miramos la entrada en el índice 0, que nos apunta a la tabla de nivel 2 en 24 KiB.
- El índice de nivel 2 es 511, así que miramos la última entrada de esa página para averiguar la dirección de la tabla de nivel 1.
- A través de la entrada en el índice 127 de la tabla de nivel 1, finalmente descubrimos que la página está mapeada al marco de 12 KiB, o 0x3000 en hexadecimal.
- El paso final es agregar el desplazamiento de la página a la dirección del marco para obtener la dirección física 0x3000 + 0x5ce = 0x35ce.

Los permisos para la página en la tabla de nivel 1 son r, lo que significa que es solo de lectura. El hardware hace cumplir estos permisos y lanzaría una excepción si intentáramos escribir en esa página. Los permisos en las páginas de niveles superiores restringen los posibles permisos en niveles inferiores, por lo que si establecemos la entrada de nivel 3 como solo lectura, ninguna página que use esta entrada puede ser escribible, incluso si los niveles inferiores especifican permisos de lectura/escritura.
Es importante tener en cuenta que, aunque este ejemplo utilizó solo una instancia de cada tabla, normalmente hay múltiples instancias de cada nivel en cada espacio de direcciones. En el máximo, hay:
- una tabla de nivel 4,
- 512 tablas de nivel 3 (porque la tabla de nivel 4 tiene 512 entradas),
- 512 * 512 tablas de nivel 2 (porque cada una de las 512 tablas de nivel 3 tiene 512 entradas), y
- 512 * 512 * 512 tablas de nivel 1 (512 entradas para cada tabla de nivel 2).
🔗Formato de la Tabla de Páginas
Las tablas de páginas en la arquitectura x86_64 son básicamente un array de 512 entradas. En sintaxis de Rust:
#[repr(align(4096))]
pub struct PageTable {
entries: [PageTableEntry; 512],
}
Como se indica por el atributo repr, las tablas de páginas necesitan estar alineadas a la página, es decir, alineadas en un límite de 4 KiB. Este requisito garantiza que una tabla de páginas siempre llene una página completa y permite una optimización que hace que las entradas sean muy compactas.
Cada entrada tiene un tamaño de 8 bytes (64 bits) y tiene el siguiente formato:
| Bit(s) | Nombre | Significado |
|---|---|---|
| 0 | presente | la página está actualmente en memoria |
| 1 | escribible | se permite escribir en esta página |
| 2 | accesible por el usuario | si no se establece, solo el código en modo núcleo puede acceder a esta página |
| 3 | caché de escritura a través | las escrituras van directamente a la memoria |
| 4 | desactivar caché | no se utiliza caché para esta página |
| 5 | accedido | la CPU establece este bit cuando se utiliza esta página |
| 6 | sucio | la CPU establece este bit cuando se realiza una escritura en esta página |
| 7 | página enorme/null | debe ser 0 en P1 y P4, crea una página de 1 GiB en P3, crea una página de 2 MiB en P2 |
| 8 | global | la página no se borra de las cachés al cambiar el espacio de direcciones (el bit PGE del registro CR4 debe estar establecido) |
| 9-11 | disponible | puede ser utilizado libremente por el sistema operativo |
| 12-51 | dirección física | la dirección física alineada de 52 bits del marco o de la siguiente tabla de páginas |
| 52-62 | disponible | puede ser utilizado libremente por el sistema operativo |
| 63 | no ejecutar | prohibir la ejecución de código en esta página (el bit NXE en el registro EFER debe estar establecido) |
Vemos que solo los bits 12–51 se utilizan para almacenar la dirección física del marco. Los bits restantes se utilizan como banderas o pueden ser utilizados libremente por el sistema operativo. Esto es posible porque siempre apuntamos a una dirección alineada a 4096 bytes, ya sea a una tabla de páginas alineada a la página o al inicio de un marco mapeado. Esto significa que los bits 0–11 son siempre cero, por lo que no hay razón para almacenar estos bits porque el hardware puede simplemente configurarlos en cero antes de usar la dirección. Lo mismo es cierto para los bits 52–63, ya que la arquitectura x86_64 solo admite direcciones físicas de 52 bits (similar a como solo admite direcciones virtuales de 48 bits).
Veamos más de cerca las banderas disponibles:
- La bandera
presentediferencia las páginas mapeadas de las no mapeadas. Puede usarse para intercambiar temporalmente páginas en disco cuando la memoria principal se llena. Cuando la página se accede posteriormente, ocurre una excepción especial llamada fallo de página (page fault), a la cual el sistema operativo puede reaccionar volviendo a cargar la página faltante desde el disco y luego continuar el programa. - Las banderas
escribibleyno ejecutarcontrolan si el contenido de la página es escribible o contiene instrucciones ejecutables, respectivamente. - Las banderas
accedidoysucioson automáticamente configuradas por la CPU cuando se produce una lectura o escritura en la página. Esta información puede ser utilizada por el sistema operativo, por ejemplo, para decidir qué páginas intercambiar o si el contenido de la página ha sido modificado desde el último guardado en disco. - Las banderas
caché de escritura a travésydesactivar cachépermiten el control de cachés para cada página individualmente. - La bandera
accesible por el usuariohace que una página esté disponible para el código de espacio de usuario, de lo contrario, solo es accesible cuando la CPU está en modo núcleo. Esta característica puede utilizarse para hacer llamadas al sistema más rápidas manteniendo el núcleo mapeado mientras un programa de espacio de usuario se está ejecutando. Sin embargo, la vulnerabilidad Spectre puede permitir que los programas de espacio de usuario lean estas páginas, sin embargo. - La bandera
globalle indica al hardware que una página está disponible en todos los espacios de direcciones y, por lo tanto, no necesita ser eliminada de la caché de traducción (ver la sección sobre el TLB a continuación) al cambiar de espacio de direcciones. Esta bandera se utiliza comúnmente junto con una banderaaccesible por el usuariodesactivada para mapear el código del núcleo a todos los espacios de direcciones. - La bandera
página enormepermite la creación de páginas de tamaños más grandes al permitir que las entradas de las tablas de nivel 2 o nivel 3 apunten directamente a un marco mapeado. Con este bit establecido, el tamaño de la página aumenta por un factor de 512 a 2 MiB = 512 * 4 KiB para las entradas de nivel 2 o incluso 1 GiB = 512 * 2 MiB para las entradas de nivel 3. La ventaja de usar páginas más grandes es que se necesitan menos líneas de la caché de traducción y menos tablas de páginas.
El crate x86_64 proporciona tipos para tablas de páginas y sus entradas, por lo que no necesitamos crear estas estructuras nosotros mismos.
🔗El Buffer de Traducción (TLB)
Una tabla de páginas de 4 niveles hace que la traducción de direcciones virtuales sea costosa porque cada traducción requiere cuatro accesos a la memoria. Para mejorar el rendimiento, la arquitectura x86_64 almacena en caché las últimas traducciones en el denominado buffer de traducción (translation lookaside buffer, TLB). Esto permite omitir la traducción cuando todavía está en caché.
A diferencia de las demás cachés de la CPU, el TLB no es completamente transparente y no actualiza ni elimina traducciones cuando cambian los contenidos de las tablas de páginas. Esto significa que el núcleo debe actualizar manualmente el TLB cada vez que modifica una tabla de páginas. Para hacer esto, hay una instrucción especial de la CPU llamada invlpg (“invalidar página”) que elimina la traducción para la página especificada del TLB, de modo que se vuelva a cargar desde la tabla de páginas en el siguiente acceso. El crate x86_64 proporciona funciones en Rust para ambas variantes en el módulo tlb.
Es importante recordar limpiar el TLB en cada modificación de tabla de páginas porque de lo contrario, la CPU podría seguir utilizando la vieja traducción, lo que puede llevar a errores no determinísticos que son muy difíciles de depurar.
🔗Implementación
Una cosa que aún no hemos mencionado: Nuestro núcleo ya se ejecuta sobre paginación. El bootloader (cargador de arranque) que añadimos en la publicación “Un núcleo mínimo de Rust” ya ha configurado una jerarquía de paginación de 4 niveles que mapea cada página de nuestro núcleo a un marco físico. El bootloader hace esto porque la paginación es obligatoria en el modo de 64 bits en x86_64.
Esto significa que cada dirección de memoria que utilizamos en nuestro núcleo era una dirección virtual. Acceder al búfer VGA en la dirección 0xb8000 solo funcionó porque el bootloader mapeó por identidad esa página de memoria, lo que significa que mapeó la página virtual 0xb8000 al marco físico 0xb8000.
La paginación hace que nuestro núcleo ya sea relativamente seguro, ya que cada acceso a memoria que está fuera de límites causa una excepción de fallo de página en lugar de escribir en la memoria física aleatoria. El bootloader incluso establece los permisos de acceso correctos para cada página, lo que significa que solo las páginas que contienen código son ejecutables y solo las páginas de datos son escribibles.
🔗Fallos de Página
Intentemos causar un fallo de página accediendo a alguna memoria fuera de nuestro núcleo. Primero, creamos un controlador de fallos de página y lo registramos en nuestra IDT, para que veamos una excepción de fallo de página en lugar de un fallo doble genérico:
// en src/interrupts.rs
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
[…]
idt.page_fault.set_handler_fn(page_fault_handler); // nuevo
idt
};
}
use x86_64::structures::idt::PageFaultErrorCode;
use crate::hlt_loop;
extern "x86-interrupt" fn page_fault_handler(
stack_frame: InterruptStackFrame,
error_code: PageFaultErrorCode,
) {
use x86_64::registers::control::Cr2;
println!("EXCEPCIÓN: FALLO DE PÁGINA");
println!("Dirección Accedida: {:?}", Cr2::read());
println!("Código de Error: {:?}", error_code);
println!("{:#?}", stack_frame);
hlt_loop();
}
El registro CR2 se configura automáticamente por la CPU en un fallo de página y contiene la dirección virtual accedida que provocó el fallo de página. Usamos la función Cr2::read del crate x86_64 para leerla e imprimirla. El tipo PageFaultErrorCode proporciona más información sobre el tipo de acceso a la memoria que causó el fallo de página, por ejemplo, si fue causado por una operación de lectura o escritura. Por esta razón, también la imprimimos. No podemos continuar la ejecución sin resolver el fallo de página, por lo que entramos en un hlt_loop al final.
Ahora podemos intentar acceder a alguna memoria fuera de nuestro núcleo:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("¡Hola Mundo{}", "!");
blog_os::init();
// nuevo
let ptr = 0xdeadbeaf as *mut u8;
unsafe { *ptr = 42; }
// como antes
#[cfg(test)]
test_main();
println!("¡No se estrelló!");
blog_os::hlt_loop();
}
Cuando lo ejecutamos, vemos que se llama a nuestro controlador de fallos de página:
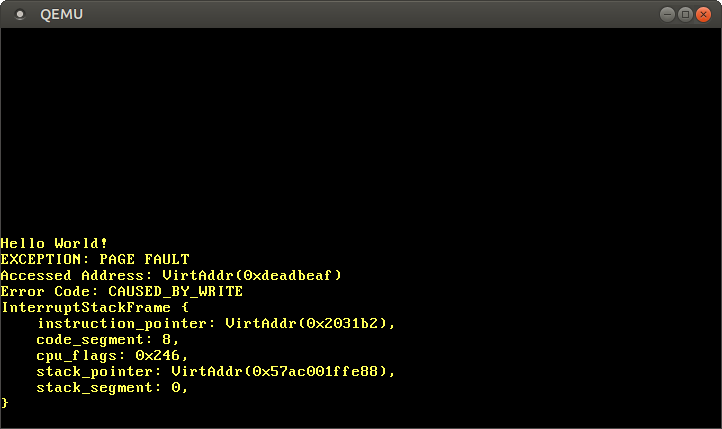
El registro CR2 efectivamente contiene 0xdeadbeaf, la dirección que intentamos acceder. El código de error nos dice a través del CAUSED_BY_WRITE que la falla ocurrió mientras intentábamos realizar una operación de escritura. También nos dice más a través de los bits que no están establecidos. Por ejemplo, el hecho de que la bandera PROTECTION_VIOLATION no esté establecida significa que el fallo de página ocurrió porque la página objetivo no estaba presente.
Vemos que el puntero de instrucciones actual es 0x2031b2, así que sabemos que esta dirección apunta a una página de código. Las páginas de código están mapeadas como solo lectura por el bootloader, así que leer desde esta dirección funciona, pero escribir causa un fallo de página. Puedes intentar esto cambiando el puntero 0xdeadbeaf a 0x2031b2:
// Nota: La dirección real podría ser diferente para ti. Usa la dirección que
// informa tu controlador de fallos de página.
let ptr = 0x2031b2 as *mut u8;
// leer desde una página de código
unsafe { let x = *ptr; }
println!("la lectura funcionó");
// escribir en una página de código
unsafe { *ptr = 42; }
println!("la escritura funcionó");
Al comentar la última línea, vemos que el acceso de lectura funciona, pero el acceso de escritura causa un fallo de página:
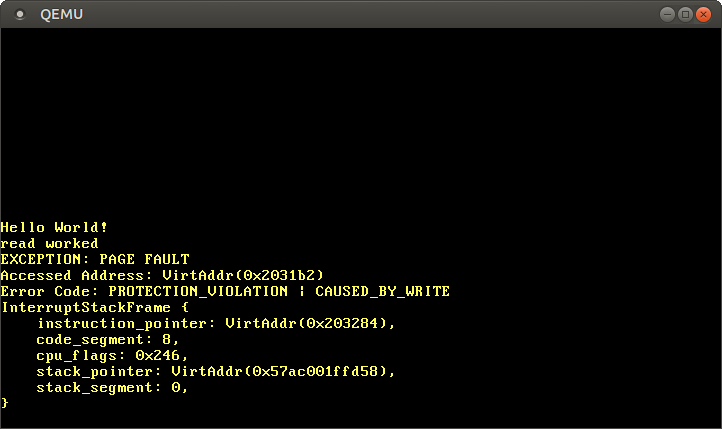
Vemos que el mensaje “la lectura funcionó” se imprime, lo que indica que la operación de lectura no causó errores. Sin embargo, en lugar del mensaje “la escritura funcionó”, ocurre un fallo de página. Esta vez la bandera PROTECTION_VIOLATION está establecida además de la bandera CAUSED_BY_WRITE, lo que indica que la página estaba presente, pero la operación no estaba permitida en ella. En este caso, las escrituras a la página no están permitidas ya que las páginas de código están mapeadas como solo lectura.
🔗Accediendo a las Tablas de Páginas
Intentemos echar un vistazo a las tablas de páginas que definen cómo está mapeado nuestro núcleo:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
println!("¡Hola Mundo{}", "!");
blog_os::init();
use x86_64::registers::control::Cr3;
let (level_4_page_table, _) = Cr3::read();
println!("Tabla de páginas de nivel 4 en: {:?}", level_4_page_table.start_address());
[…] // test_main(), println(…), y hlt_loop()
}
La función Cr3::read del x86_64 devuelve la tabla de páginas de nivel 4 actualmente activa desde el registro CR3. Devuelve una tupla de un tipo PhysFrame y un tipo Cr3Flags. Solo nos interesa el marco, así que ignoramos el segundo elemento de la tupla.
Cuando lo ejecutamos, vemos la siguiente salida:
Tabla de páginas de nivel 4 en: PhysAddr(0x1000)
Entonces, la tabla de páginas de nivel 4 actualmente activa se almacena en la dirección 0x1000 en memoria física, como indica el tipo de wrapper PhysAddr. La pregunta ahora es: ¿cómo podemos acceder a esta tabla desde nuestro núcleo?
Acceder a la memoria física directamente no es posible cuando la paginación está activa, ya que los programas podrían fácilmente eludir la protección de memoria y acceder a la memoria de otros programas de lo contrario. Así que la única forma de acceder a la tabla es a través de alguna página virtual que esté mapeada al marco físico en la dirección 0x1000. Este problema de crear mapeos para los marcos de tabla de páginas es un problema general ya que el núcleo necesita acceder a las tablas de páginas regularmente, por ejemplo, al asignar una pila para un nuevo hilo.
Las soluciones a este problema se explican en detalle en la siguiente publicación.
🔗Resumen
Esta publicación introdujo dos técnicas de protección de memoria: segmentación y paginación. Mientras que la primera utiliza regiones de memoria de tamaño variable y sufre de fragmentación externa, la segunda utiliza páginas de tamaño fijo y permite un control mucho más detallado sobre los permisos de acceso.
La paginación almacena la información de mapeo para las páginas en tablas de páginas con uno o más niveles. La arquitectura x86_64 utiliza tablas de páginas de 4 niveles y un tamaño de página de 4 KiB. El hardware recorre automáticamente las tablas de páginas y almacena en caché las traducciones resultantes en el buffer de traducción (TLB). Este buffer no se actualiza de manera transparente y necesita ser limpiado manualmente en cambios de tabla de páginas.
Aprendimos que nuestro núcleo ya se ejecuta sobre paginación y que los accesos ilegales a la memoria provocan excepciones de fallo de página. Intentamos acceder a las tablas de páginas actualmente activas, pero no pudimos hacerlo porque el registro CR3 almacena una dirección física que no podemos acceder directamente desde nuestro núcleo.
🔗¿Qué sigue?
La siguiente publicación explica cómo implementar soporte para la paginación en nuestro núcleo. Presenta diferentes formas de acceder a la memoria física desde nuestro núcleo, lo que hace posible acceder a las tablas de páginas en las que se ejecuta nuestro núcleo. En este momento, seremos capaces de implementar funciones para traducir direcciones virtuales a físicas y para crear nuevos mapeos en las tablas de páginas.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.