Async/Await
翻譯內容: 這是對原文章 Async/Await 的社區中文翻譯。它可能不完整,過時或者包含錯誤。可以在 這個 Issue 上評論和提問!
翻譯者: @ssrlive.
在這篇文章中,我們將探索 協作式多任務 和 Rust 的 async/await 功能。我們將詳細了解 Rust 中的 async/await 是如何工作的,
包括 Future trait 的設計、狀態機轉換和 pinning。
然後,我們通過創建一個異步鍵盤任務和一個基本的執行器,為我們的內核添加了對 async/await 的基本支持。
本文將
trait翻譯爲特型, 不接受什麼特性,特質等亂七八糟不知所云的譯法。
本博客在 GitHub 上開源。如果你有任何問題或疑問,請在那裡打開一個 issue。
你也可以在 at the bottom 留下評論。本文的完整源代碼可以在 post-12 分支中找到。
目錄
🔗多任務
絕大多數操作系統的一個基本特性是多任務 multitasking ,它能夠同時執行多個任務。 例如,你可能在看這篇文章的同時打開了其他程序,比如文本編輯器或終端窗口。 即使你只打開了一個瀏覽器窗口,也可能有各種後台任務在管理你的桌面窗口、檢查更新或索引文件。
看起來所有的任務都在同時運行,但實際上一個 CPU 核心一次只能執行一個任務。為了創建任務同時運行的假象,操作系統會快速地在活動任務之間切換, 這樣每個任務都能取得一點進展。由於計算機的速度很快,我們大多數時候都不會注意到這些切換。
當單核 CPU 一次只能執行一個任務時,多核 CPU 可以真正並行地運行多個任務。例如,一個有 8 個核心的 CPU 可以同時運行 8 個任務。 我們將在未來的文章中解釋如何設置多核 CPU。在本文中,我們將專注於單核 CPU,以保持簡單。 (值得注意的是,所有多核 CPU 都是從只有一個活動核心開始的,所以我們現在可以將它們視為單核 CPU。)
有兩種形式的多任務:協作式 多任務要求任務定期放棄對 CPU 的控制,以便其他任務可以取得進展。 抢占式 多任務使用操作系統功能在任意時間點強制暫停線程來切換線程。接下來,我們將更詳細地探討兩種多任務的形式,並討論它們各自的優點和缺點。
🔗搶佔式多任務
搶佔式多任務後面的思想是操作系統控制何時切換任務。為此,它利用了操作系統在每次中斷時重新獲得對 CPU 的控制。這使得在系統有新的輸入時切換任務成為可能。例如,當滑鼠移動或網絡數據包到達時,可以切換任務。操作系統還可以通過配置硬件計時器在一段時間後發送中斷來確定任務允許運行的確切時間
下面的圖形展示了硬件中斷時的任務切換過程:

第一行中,CPU 正在執行程序 A 的任務 A1。所有其他任務都被暫停了。在第二行中,硬件中斷到達了 CPU。
正如在 硬件中斷 Hardware Interrupts 文章中描述的那樣,CPU 立即停止了任務 A1 的執行,並跳轉到中斷描述符表(IDT)中定義的中斷處理程序。
通過這個中斷處理程序,操作系統現在再次控制了 CPU,這使得它可以切換到任務 B1 而不是繼續任務 A1。
🔗保存狀態
既然任務在任意時間點被中斷,它們可能在一些計算的中間。為了能夠稍後恢復它們,操作系統必須備份任務的整個狀態, 包括它的調用棧 call stack 和所有 CPU 寄存器的值。這個過程被稱為上下文切換 context switch。
由於調用棧可能非常大,操作系統通常為每個任務設置一個單獨的調用棧,而不是在每次任務切換時備份調用棧內容。 這種帶有其自己的棧的認爲被稱為 執行線程 thread of execution 或簡稱為 線程 thread。 通過為每個任務使用單獨的棧,只需要在上下文切換時保存寄存器內容(包括程序計數器和棧指針)。
🔗討論
搶佔式多任務主要的好處是操作系統可以完全控制任務的允許執行時間。這樣,它可以保證每個任務都能公平地獲得 CPU 的時間,而不需要信任 任務的合作。 這在運行第三方任務或多個用戶共享系統時尤為重要。
搶佔式多任務的缺點是每個任務都需要自己的棧。與共享棧相比,這導致每個任務的內存使用量更高,並且通常限制了系統中的任務數量。 另一個缺點是操作系統總是需要在每次任務切換時保存完整的 CPU 寄存器狀態,即使任務只使用了寄存器的一小部分。
搶佔式多任務和線程是操作系統的基本組件,因為它們使得運行不受信任的用戶空間程序成為可能。 我們將在未來的文章中詳細討論這些概念。然而,在本文中,我們將專注於協作式多任務,它也為我們的內核提供了有用的功能。
🔗協作式多任務
協作式多任務讓每個任務運行直到它自願放棄對 CPU 的控制,而不是在任意時間點強制暫停運行的任務。 這使得任務可以在方便的時間點暫停自己,例如,當它們需要等待 I/O 操作時。
協作式多任務通常用於語言級別,比如協程 coroutines 或 async/await 的形式。 其思想是程序員或編譯器在程序中插入 yield 操作,這樣可以放棄對 CPU 的控制,讓其他任務運行。 例如,可以在復雜循環的每次迭代後插入一個 yield。
通常將協作式多任務與 異步操作 asynchronous operations 結合在一起。 當一個操作還沒有完成時,它不會阻止其他任務運行,而是返回一個 “未就緒” 的狀態。在這種情況下,等待的任務可以執行一個 yield 操作,讓其他任務運行。
🔗保存狀態
既然任務自己定義了暫停點,它們不需要操作系統保存它們的狀態。相反,它們可以在暫停自己之前保存它們需要的狀態, 這通常會帶來更好的性能。例如,一個剛完成了復雜計算的任務可能只需要備份計算的最終結果,因為它不再需要中間結果。
協作式多任務的語言級實現通常甚至能夠在暫停之前備份調用棧的必要部分。 例如,Rust 的 async/await 實現會在暫停之前備份所有仍然需要的本地變量到一個自動生成的結構體中(見下文)。 通過在暫停之前備份調用棧的相關部分,所有任務都可以共享一個調用棧,這導致每個任務的內存消耗大大降低。 這使得可以創建幾乎任意數量的協作式任務而不會耗盡內存。
🔗討論
協作式多任務的缺點是一個不合作的任務可能運行無限長的時間。因此,一個惡意或有缺陷的任務可能會阻止其他任務運行,從而減慢甚至阻塞整個系統。 因此,只有當所有任務都知道合作時,協作式多任務才應該使用。舉個反例,讓操作系統依賴於任意用戶級程序的合作是不明智的。
然而,協作式多任務的強大性能和內存優勢使得它成為程序內部使用的一個好方法,特別是與異步操作結合使用。 由於操作系統內核是一個與異步硬件交互的性能關鍵型程序,協作式多任務似乎是實現並發性的一個好方法。
🔗Async/Await in Rust
Rust 語言提供了對協作式多任務的第一級別支持,這種支持以 async/await 的形式呈現。 在我們探討 async/await 是什麼以及它是如何工作之前,我們需要了解 Rust 中 futures 和異步編程是如何工作的。
🔗Futures
一個 future 代表一個可能還沒有可用的值。這可能是,例如,由另一個任務計算的整數或從網絡下載的文件。 與等待值可用不同,future 使得可以繼續執行直到需要值。
🔗例子
futures 的概念最好通過一個小例子來說明:

這個序列圖展示了一個 main 函數,它從文件系統讀取文件,然後調用一個 foo 函數。
這個過程重複了兩次:一次是同步的 read_file 調用,一次是異步的 async_read_file 調用。
使用同步調用,main 函數需要等待直到文件從文件系統加載完畢。只有這樣它才能調用 foo 函數,這需要它再次等待結果。
使用異步 async_read_file 調用,文件系統直接返回一個 future,並在後台異步加載文件。
這使得 main 函數可以更早地調用 foo,這樣它可以與文件加載並行運行。
在這個例子中,文件加載甚至在 foo 返回之前就完成了,所以 main 可以在 foo 返回後直接使用文件而不需要進一步等待。
🔗Futures in Rust
在 Rust 中,futures 由 Future trait 表示,它看起來像這樣:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>;
}
那個 關聯類型 [associated type] Output 指定了異步值的類型。
例如,上面的示例中的 async_read_file 函數將返回一個 Output 設置為 File 的 Future 實例。
那個 poll 方法允許檢查值是否已經可用。它返回一個 Poll 枚舉,看起來像這樣:
pub enum Poll<T> {
Ready(T),
Pending,
}
當那個值已經可用(例如,文件已經完全從磁盤讀取完畢),它被包裝在 Ready 變體中返回。
否則,返回 Pending 變體,這通知調用者該值尚不可用。
方法 poll 接受兩個參數:self: Pin<&mut Self> 和 cx: &mut Context。
前者的行為與普通的 &mut self 引用類似,只是 Self 值被 釘住 pinned 在它的內存位置。
在理解 async/await 是如何工作之前,理解 Pin 以及為什麼它是必要的是困難的。因此,我們將在本文後面解釋它。
參數 cx: &mut Context 的目的是將一個 喚醒器 Waker 實例傳遞給異步任務,例如文件系統加載。
這個 Waker 允許異步任務發出信號,表明它(或它的一部分)已經完成,例如文件已經從磁盤加載完畢。
由於主任務知道當 Future 可用時它將被通知,所以它不需要一遍又一遍地調用 poll。
我們將在本文後面實現自己的 Waker 類型時更詳細地解釋這個過程。
🔗同 Futures 一起工作
我們現在知道了 futures 是如何定義的,並且了解了 poll 方法背後的基本思想。然而,我們仍然不知道如何有效地使用 futures。
問題在於 futures 代表了異步任務的結果,這些結果可能還不可用。然而,在實踐中,我們經常需要這些值來進行進一步的計算。
所以問題是:當我們需要時,我們如何有效地獲取 future 的值?
🔗Waiting on Futures
一個可能的答案是等待直到 future 變得可用。這可能看起來像這樣:
let future = async_read_file("foo.txt");
let file_content = loop {
match future.poll(…) {
Poll::Ready(value) => break value,
Poll::Pending => {}, // do nothing
}
}
在這裏我們 主動 等待 future,通過在一個循環中一遍又一遍地調用 poll。這裏 poll 的參數不重要,所以我們省略了它們。
雖然這個解決方案有效,但它非常低效,因為我們一直佔用 CPU 直到值變得可用。
更有效的方法可能是 阻塞 當前線程直到 future 變得可用。 當然,這只有在你有線程的時候才可能,所以這個解決方案對我們的內核來說不起作用,至少目前還不行。 即使在支持阻塞的系統上,這通常也是不希望的,因為它會將一個異步任務再次變成一個同步任務,從而抑制了並行任務的潛在性能優勢。
🔗Future 組合器
一個 等待 的替代方案是使用 future 組合器 (future combinators)。Future 組合器 是像 map 這樣的方法,它允許將 futures 連接和組合在一起,
類似於 Iterator trait 的方法。與等待 future 不同,這些 combinator 返回一個 future,它們自己應用 poll 上的映射操作。
做爲例子,一個簡單的 string_len 組合器,它將 Future<Output = String> 轉換成 Future<Output = usize> 可能看起來像這樣:
struct StringLen<F> {
inner_future: F,
}
impl<F> Future for StringLen<F> where F: Future<Output = String> {
type Output = usize;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
match self.inner_future.poll(cx) {
Poll::Ready(s) => Poll::Ready(s.len()),
Poll::Pending => Poll::Pending,
}
}
}
fn string_len(string: impl Future<Output = String>)
-> impl Future<Output = usize>
{
StringLen {
inner_future: string,
}
}
// Usage
fn file_len() -> impl Future<Output = usize> {
let file_content_future = async_read_file("foo.txt");
string_len(file_content_future)
}
這段代碼不完全能工作,因為它沒有處理 pinning,但它足以作為一個例子。
基本思想是 string_len 函數將給定的 Future 實例包裝到一個新的 StringLen 結構體中,它也實現了 Future。
當包裝的 future 被調用時,它調用內部 future。如果值還不可用,從包裝的 future 也返回 Poll::Pending。
如果值已經可用,則從 Poll::Ready 變體中提取字符串並計算它的長度。然後,它再次包裝在 Poll::Ready 中並返回。
用這個 string_len 函數,我們可以計算一個異步字符串的長度而不需要等待它。由於函數再次返回一個 Future,
調用者不能直接在返回的值上工作,但需要再次使用 組合器 函數。這樣,整個調用圖變成了異步的,
我們可以在某個時候有效地等待多個 futures,例如,在 main 函數中。
因爲手工編寫 組合器 函數是困難的,它們通常由庫提供。雖然 Rust 標準庫本身還沒有提供 組合器 方法,
但是半官方的(並且 no_std 兼容的) futures 庫提供了。它的 FutureExt trait 提供了高級 組合器 方法,
比如 map 或 then,它們可以用來使用任意的閉包來操作結果。
🔗優勢
Future 組合器的一個巨大優勢是它們保持了操作的異步性。與異步 I/O 接口結合使用,這種方法可以帶來非常高的性能。 Future 組合器作為具有 trait 實現的普通結構體,使得編譯器可以對它們進行極限優化。 有關更多細節,請參見 Zero-cost futures in Rust 文章,它宣布了將 futures 添加到 Rust 生態系統中。
🔗Drawbacks
當 future 組合器 使得編寫非常高效的代碼成為可能時,它們在某些情況下可能很難使用,這是因為類型系統和基於閉包的接口。例如,考慮這樣的代碼:
fn example(min_len: usize) -> impl Future<Output = String> {
async_read_file("foo.txt").then(move |content| {
if content.len() < min_len {
Either::Left(async_read_file("bar.txt").map(|s| content + &s))
} else {
Either::Right(future::ready(content))
}
})
}
這裏我們讀取文件 foo.txt,然後使用 then 組合器 來連接 基於文件內容的第二個 future。
如果內容的長度小於給定的 min_len,我們讀取一個不同的 bar.txt 文件並使用 map 組合器 將它附加到 content 上。
否則,我們只返回 foo.txt 的內容。
我們需要使用 [move] 關鍵字來修復傳遞給 then 的閉包,因為否則 min_len 將會有一個生命週期錯誤。
我們需要使用 Either 包裝器,因為 if 和 else 塊必須總是有相同的類型。由於我們在塊中返回不同的 future 類型,
我們必須使用包裝器類型將它們統一到一個類型中。
ready 函數將一個值包裝到一個 future 中,這個 future 立即就緒。這個函數在這裏是必需的,因為 Either 包裝器期望被包裝的值實現了 Future。
如你所想,這能很快地導致對於大型項目來說非常複雜的代碼。如果涉及借用和不同的生命週期,它會變得特別複雜。 因此,Rust 在添加對 async/await 的支持時投入了大量的工作,目標是使編寫異步代碼變得更簡單。
🔗The Async/Await Pattern
在 async/await 背後的思想是讓程序員編寫看起來像 正常同步代碼 的代碼,但是被編譯器轉換成異步代碼。
它基於兩個關鍵字 async 和 await。async 關鍵字可以在函數簽名中使用,將一個同步函數轉換成一個返回 future 的異步函數:
async fn foo() -> u32 {
0
}
// the above is roughly translated by the compiler to:
fn foo() -> impl Future<Output = u32> {
future::ready(0)
}
這個關鍵字單獨使用時並不是很有用。然而,在 async 函數內部,await 關鍵字可以用來獲取 future 的異步值:
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
這個函數是對 上面 的 example 函數的直接翻譯,它使用了組合器函數。
使用 .await 運算符,我們可以獲取 future 的值而不需要任何閉包或 Either 類型。
因此,我們可以像編寫正常的同步代碼一樣編寫我們的代碼,只是 這仍然是異步代碼。
🔗狀態機轉換
在幕後,編譯器將 async 函數體轉換成一狀態機 state machine,其中每個 .await 調用代表一個不同的狀態。
對於上面的 example 函數,編譯器創建了一個具有以下四個狀態的狀態機:

每個狀態代表了函數中的一個不同的暫停點。 “Start” 和 “End” 狀態代表了函數在執行的開始和結束。
“Waiting on foo.txt” 狀態代表了函數當前正在等待第一個 async_read_file 的結果。
同樣地, “Waiting on bar.txt” 狀態代表了函數正在等待第二個 async_read_file 的結果的暫停點。
狀態機通過使每個 poll 調用成為一個可能的狀態轉換來實現 Future trait:

該圖使用箭頭表示狀態轉換,使用菱形表示替代路徑。例如,如果 foo.txt 文件還沒有準備好,則採用 “no” 路徑,並達到 “Waiting on foo.txt” 狀態。
否則,採用 “yes” 路徑。沒有標題的小紅色菱形代表 example 函數的 if content.len() < 100 分支。
我們看到第一個 poll 調用啟動了函數並讓它運行直到它達到一個還未準備好的 future。
如果所有的 future 都準備好了,函數可以運行到 “End” 狀態,並在 Poll::Ready 中返回它的結果。
否則,狀態機進入等待狀態並返回 Poll::Pending。在下一個 poll 調用中,狀態機從最後一個等待的狀態開始,並重試最後一個操作。
🔗保存狀態
為了能夠從上一個等待狀態繼續,狀態機必須在內部保持當前的狀態。此外,它必須保存所有它需要在下一個 poll 調用中繼續執行的變量。
這就是編譯器真正發揮作用的地方:因為它知道哪些變量何時使用,它可以自動生成具有確切所需變量的結構體。
作為一個例子,編譯器為上面的 example 函數生成了像下面這樣的結構體:
// The `example` function again so that you don't have to scroll up
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
// The compiler-generated state structs:
struct StartState {
min_len: usize,
}
struct WaitingOnFooTxtState {
min_len: usize,
foo_txt_future: impl Future<Output = String>,
}
struct WaitingOnBarTxtState {
content: String,
bar_txt_future: impl Future<Output = String>,
}
struct EndState {}
在 “start” 和 “Waiting on foo.txt” 狀態中,min_len 參數需要被保存以便與 content.len() 進行後續比較。
“Waiting on foo.txt” 狀態另外保存了一個 foo_txt_future,它代表了 async_read_file 調用返回的 future。
當狀態機繼續運行時,這個 future 需要再次被調用,所以它需要被保存。
“Waiting on bar.txt” 狀態包含了 content 變量,以便在 bar.txt 可用時進行字符串連接。
它還保存了一個 bar_txt_future,它代表了 bar.txt 的異步加載過程。這個結構體不包含 min_len 變量,因為在 content.len() 比較之後它不再需要了。
在 “end” 狀態中不保存任何變量,因為函數已經運行到了結束。
請記住,這只是編譯器可能生成的代碼的一個例子。結構體名稱和字段布局是實現細節,可能是不同的。
🔗完整的狀態機類型
雖然確切的編譯器生成的代碼是一個實現細節,但它有助於理解想象 example 函數的狀態機 可能 看起來像什麼。
我們已經定義了表示不同狀態的結構體並包含了所需的變量。為了在它們之上創建一個狀態機,我們可以將它們組合成一個 enum:
enum ExampleStateMachine {
Start(StartState),
WaitingOnFooTxt(WaitingOnFooTxtState),
WaitingOnBarTxt(WaitingOnBarTxtState),
End(EndState),
}
我們定義了一個獨立的枚舉變體來表示每個狀態,並將相應的狀態結構體作為每個變體的字段添加到其中。
為了實現狀態轉換,編譯器基於 example 函數生成了 Future trait 的實現:
impl Future for ExampleStateMachine {
type Output = String; // return type of `example`
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output> {
loop {
match self { // TODO: handle pinning
ExampleStateMachine::Start(state) => {…}
ExampleStateMachine::WaitingOnFooTxt(state) => {…}
ExampleStateMachine::WaitingOnBarTxt(state) => {…}
ExampleStateMachine::End(state) => {…}
}
}
}
}
該 future 的 Output 類型是 String,因為它是 example 函數的返回類型。
為了實現 poll 函數,我們在一個 loop 中使用 match 語句對當前狀態進行分支。
我們的想法是只要可能就切換到下一個狀態,並在無法繼續時使用顯式的 return Poll::Pending。
為了簡化,我們只顯示簡化的代碼並且不處理 釘住、所有權、生命週期等。因此,這裏和下面的代碼應該被視為偽代碼,不應該直接使用。 當然,真正的編譯器生成的代碼可以正確地處理所有事情,盡管可能是以與這裏展示的不同的方式。
爲了使代碼片段更小,我們分別展示每個 match 分支的代碼。讓我們從 Start 狀態開始:
ExampleStateMachine::Start(state) => {
// from body of `example`
let foo_txt_future = async_read_file("foo.txt");
// `.await` operation
let state = WaitingOnFooTxtState {
min_len: state.min_len,
foo_txt_future,
};
*self = ExampleStateMachine::WaitingOnFooTxt(state);
}
狀態機在函數的開始時處於 Start 狀態。在這種情況下,我們執行 example 函數的所有代碼直到第一個 .await。
為了處理 .await 操作,我們將狀態機 self 的狀態更改為 WaitingOnFooTxt,這包括了 WaitingOnFooTxtState 結構體的構造.
因爲 match self {…} 語句在一個循環中執行,所以執行直接跳到 WaitingOnFooTxt 分支:
ExampleStateMachine::WaitingOnFooTxt(state) => {
match state.foo_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(content) => {
// from body of `example`
if content.len() < state.min_len {
let bar_txt_future = async_read_file("bar.txt");
// `.await` operation
let state = WaitingOnBarTxtState {
content,
bar_txt_future,
};
*self = ExampleStateMachine::WaitingOnBarTxt(state);
} else {
*self = ExampleStateMachine::End(EndState);
return Poll::Ready(content);
}
}
}
}
在這個 match 分支中,我們首先調用 foo_txt_future 的 poll 函數。如果它還沒有準備好,我們退出循環並返回 Poll::Pending。
由於在這種情況下 self 保持在 WaitingOnFooTxt 狀態,下一個 poll 調用將進入相同的 match 分支並重試 foo_txt_future 的輪詢。
當 foo_txt_future 準備好時,我們將結果分配給 content 變量並繼續執行 example 函數的代碼:
如果 content.len() 小於狀態結構體中保存的 min_len,我們異步讀取 bar.txt 文件。
我們再次將 .await 操作轉換成一個狀態變化,這次是到 WaitingOnBarTxt 狀態。
由於我們在一個循環中執行 match,所以執行直接跳到新狀態的 match 分支,並輪詢 bar_txt_future。
如果我們進入 else 分支,則不會進行進一步的 .await 操作。我們達到函數的結尾並將 content 包裝在 Poll::Ready 中返回。
我們還將當前的狀態更改為 End 狀態。
狀態 WaitingOnBarTxt 的代碼如下:
ExampleStateMachine::WaitingOnBarTxt(state) => {
match state.bar_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(bar_txt) => {
*self = ExampleStateMachine::End(EndState);
// from body of `example`
return Poll::Ready(state.content + &bar_txt);
}
}
}
類似於 WaitingOnFooTxt 狀態,我們首先輪詢 bar_txt_future。如果它還沒有準備好,我們退出循環並返回 Poll::Pending。
反之,我們可以執行 example 函數的最後一個操作:將 content 變量與 future 的結果連接起來。
我們將狀態機更改為 End 狀態並在 Poll::Ready 中返回結果。
最後,End 狀態的代碼如下:
ExampleStateMachine::End(_) => {
panic!("poll called after Poll::Ready was returned");
}
Future 在返回 Poll::Ready 後不應再次被輪詢到,所以如果在 End 狀態下調用 poll,我們會 panic。
我們現在知道了編譯器生成的狀態機及其對 Future trait 的實現 可能 看起來的樣子。 真實情況下,編譯器以不同的方式生成代碼。
(如果你感興趣,看看目前的基於 coroutines 的實現,但這只是個實現細節之一。)
整個狀態機的最後一塊拼圖是 example 函數本身的生成代碼。記住,函數頭部是這樣定義的:
async fn example(min_len: usize) -> String
因爲完整函數體現在被狀態機實現,函數唯一需要做的事情就是初始化狀態機並返回它。生成的代碼可能看起來像這樣:
fn example(min_len: usize) -> ExampleStateMachine {
ExampleStateMachine::Start(StartState {
min_len,
})
}
該函數不再有 async 修飾符,因為它現在明確地返回一個實現了 Future trait 的 ExampleStateMachine 類型。
正如預期的那樣,狀態機在 Start 狀態中構造,相應的狀態結構體被初始化為 min_len 參數。
注意,這個函數不開始狀態機的執行。這是 Rust 中 futures 的一個基本設計決策:它們在第一次輪詢之前不做任何事情。
🔗Pinning
我們已經在本文中多次遇到了 釘住 (pinning) 這個詞。現在終於是時候探索 釘住操作 是什麼以及為什麼它是必需的。
🔗Self-Referential Structs
自引用結構體 (Self-Referential Structs)
正如上面所解釋的,狀態機轉換將每個暫停點的本地變量存儲在一個結構體中。
對於像我們的 example 函數這樣的小例子來說,這是直接的,並且不會導致任何問題。
然而,當變量相互引用時,事情將變得更加困難起來。例如,考慮這個函數:
async fn pin_example() -> i32 {
let array = [1, 2, 3];
let element = &array[2];
async_write_file("foo.txt", element.to_string()).await;
*element
}
這函數創建了一個包含 1、2 和 3 的小 array。然後它創建了對最後一個數組元素的引用並將它存儲在一個 element 變量中。
接下來,它異步地將數字轉換為字符串寫入到 foo.txt 文件中。最後,它返回 element 引用的數字。
由於函數使用了單個 await 操作,生成的狀態機有三個狀態:開始、結束和 “等待寫入”。該函數不接受任何參數,所以開始狀態的結構體是空的。
就像之前一樣,結束狀態的結構體是空的,因為函數在這一點上已經完成了。 “等待寫入” 狀態的結構體更有趣:
struct WaitingOnWriteState {
array: [1, 2, 3],
element: 0x1001c, // address of the last array element
}
我們需要存儲 array 和 element 變量的值,因為 element 是返回值的一部分,而 array 被 element 所引用。
由於 element 是一個引用,它存儲了一個指向被引用元素的 指針(即,一個內存地址)。我們在這裏使用 0x1001c 為例指代該地址。
實際上,它需要是 array 字段的最後一個元素的地址,所以它取決於結構體在內存中的位置。
具有這種內部指針的結構體被稱為 自引用 結構體,因為它們從它們自己的一個字段中引用自己。
🔗自引用結構體的問題
自引用結構體的內部指針導致了一個基本問題,當我們觀察它們的內存布局時就會變得明顯:

array 字段從地址 0x10014 開始,element 字段從地址 0x10020 開始。它指向地址 0x1001c,因為最後一個數組元素位於這個地址。在這一點上,一切都還好。然而,當我們將這個結構體移動到不同的內存地址時,問題就出現了:

我們移動了結構體,使它現在從地址 0x10024 開始。這可能發生在我們將結構體作為函數參數傳遞或將它賦值給不同的棧變量時。問題在於 element 字段仍然指向地址 0x1001c,即使最後一個 array 元素現在位於地址 0x1002c。因此,指針是懸空的,這導致下一個 poll 調用時發生未定義的行為。
🔗可能的解決方案
有三個基本方法來解決懸空指針問題:
-
在移動時更新指針: 這個方法的想法是在結構體在內存中移動時更新內部指針,以便它在移動後仍然有效。不幸的是,這種方法需要對 Rust 進行大量的更改,這可能導致巨大的性能損失。原因是某種類型的運行時需要跟踪所有結構體字段的類型,並在每次移動操作時檢查是否需要更新指針。
-
存儲偏移量而不是自引用: 為了避免更新指針的要求,編譯器可以嘗試將自引用存儲為結構體開始的偏移量。例如,上面的
WaitingOnWriteState結構體的element字段可以以element_offset字段的形式存儲,其值為 8,因為引用的數組元素在結構體開始的 8 字節後開始。由於結構體移動時偏移量保持不變,因此不需要進行字段更新。這個方法的問題在於它需要編譯器檢測所有的自引用。這在編譯時是不可能的,因為引用的值可能取決於用戶輸入,所以我們需要一個運行時系統來分析引用並正確地創建狀態結構體。這不僅會導致運行時成本,還會阻止某些編譯器優化,這將導致大量的性能損失。
-
禁止移動結構體: 正如我們上面看到的,懸空指針只有在我們移動結構體時才會出現。通過完全禁止對自引用結構體的移動操作,問題也可以避免。這種方法的巨大優勢在於它可以在類型系統級別實現而不需要額外的運行時成本。缺點是它將 可能的自引用結構體的移動操作 的 處理負擔 放在了程序員身上。
Rust 選擇了第三種解決方案,因為它的原則是提供 零成本抽象,這意味著抽象不應該帶來額外的運行時成本。 釘住 pinning API 是為此目的而提出的,它在 RFC 2349。 在接下來的內容中,我們將簡要介紹這個 API,並解釋它如何與 async/await 和 futures 一起工作。
🔗堆上之數值
第一個觀察是, 堆分配的 heap-allocated 值大多數情況下已經有一個固定的內存地址。
它們是通過調用 allocate 函數創建的,然後通過指針類型(如 Box<T>)引用。
雖然移動指針類型是可能的,但指針指向的堆值保持在相同的內存地址,直到它再次通過 deallocate 調用被釋放。
使用堆分配,我們可以嘗試創建一個自引用結構體:
fn main() {
let mut heap_value = Box::new(SelfReferential {
self_ptr: 0 as *const _,
});
let ptr = &*heap_value as *const SelfReferential;
heap_value.self_ptr = ptr;
println!("heap value at: {:p}", heap_value);
println!("internal reference: {:p}", heap_value.self_ptr);
}
struct SelfReferential {
self_ptr: *const Self,
}
我們創建了一個名為 SelfReferential 的簡單結構體,它包含一個單指針字段。首先,我們使用空指針初始化這個結構體,然後使用 Box::new 在堆上分配它。然後,我們確定堆分配的結構體的內存地址並將其存儲在 ptr 變量中。最後,我們通過將 ptr 變量賦值給 self_ptr 字段使結構體成為自引用。
當我們執行這段代碼 on the playground 時,我們看到堆值的地址和它的內部指針是相等的,
這意味著 self_ptr 字段是一個有效的自引用。由於 heap_value 變量只是一個指針,
移動它(例如,通過將它傳遞給一個函數)不會改變結構體本身的地址,所以 self_ptr 即使指針被移動也保持有效。
然而,這仍然有個辦法破壞這個例子:我們可以移出一個 Box<T> 或替換它的內容:
let stack_value = mem::replace(&mut *heap_value, SelfReferential {
self_ptr: 0 as *const _,
});
println!("value at: {:p}", &stack_value);
println!("internal reference: {:p}", stack_value.self_ptr);
這裏我們使用 mem::replace 函數將堆分配的值替換為一個新的結構體實例。
這允許我們將原始的 heap_value 移動到棧上,而結構體的 self_ptr 字段現在是一個懸空指針,它仍然指向舊的堆地址。
當你在 playground 上嘗試運行這個例子時,你會看到打印的 “value at:” 和 “internal reference:” 行確實顯示了不同的指針。
因此,僅僅堆分配一個值並不足以使自引用安全。
這裏根本的問題是 Box<T> 允許我們獲得對堆分配值的 &mut T 引用。這個 &mut 引用使得我們可以使用 mem::replace 或 mem::swap 這樣的方法來使堆分配的值失效。為了解決這個問題,我們必須防止創建對自引用結構體的 &mut 引用。
🔗Pin<Box<T>> and Unpin
釘住 pinning API 提供了一個對 &mut T 問題的解決方案,即 Pin 包裝類型和 Unpin 標記特型 trait。
這些類型後面的想法是,在 Pin 的所有方法上設置門檻,這些方法可以用來獲得對包裝值的 &mut 引用(例如 get_mut 或 deref_mut),這些門檻是 Unpin 特型。
Unpin 特型是一個 auto trait,Rust自動爲所有類型實現了它,除了那些明確地選擇了不實現的類型。
通過使自引用結構體選擇不實現 Unpin 的類型,對於它們來說,要從 Pin<Box<T>> 類型獲得 &mut T 是沒有(安全的)的辦法的。
舉個例子,讓我們更新上面的 SelfReferential 類型來選擇不實現 Unpin:
use core::marker::PhantomPinned;
struct SelfReferential {
self_ptr: *const Self,
_pin: PhantomPinned,
}
我們選擇性地添加了另一個 PhantomPinned 類型的 _pin 字段到結構體。它是個零大小的標記類型,它的唯一目的是 不 實現 Unpin 特型。
由於 auto traits 的工作方式,一個不是 Unpin 的字段足以阻止整個結構體實現 Unpin。
第二步是將示例中的 Box<SelfReferential> 類型更改為 Pin<Box<SelfReferential>> 類型。
最簡單的方法是使用 Box::pin 函數而不是 Box::new 來創建堆分配的值:
let mut heap_value = Box::pin(SelfReferential {
self_ptr: 0 as *const _,
_pin: PhantomPinned,
});
除了將 Box::new 更改為 Box::pin 之外,我們還需要在結構體初始化程序中添加新的 _pin 字段。由於 PhantomPinned 是一個零大小的類型,我們只需要它的類型名稱來初始化它。
當我們 嘗試運行我們調整後的例子 時,我們看到它不再工作:
error[E0594]: cannot assign to data in dereference of `Pin<Box<SelfReferential>>`
--> src/main.rs:10:5
|
10 | heap_value.self_ptr = ptr;
| ^^^^^^^^^^^^^^^^^^^^^^^^^ cannot assign
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
error[E0596]: cannot borrow data in dereference of `Pin<Box<SelfReferential>>` as mutable
--> src/main.rs:16:36
|
16 | let stack_value = mem::replace(&mut *heap_value, SelfReferential {
| ^^^^^^^^^^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
由於 Pin<Box<SelfReferential>> 類型不再實現 DerefMut 特型,所以這兩個錯誤都發生了。
這正是我們想要的,因為 DerefMut 特型會返回一個 &mut 引用,而我們想要防止這種情況發生。
這只是因為我們選擇了不實現 Unpin,並將 Box::new 更改為 Box::pin。
現在的問題是編譯器不僅阻止了在第16行移動類型,而且還禁止了在第10行初始化 self_ptr 字段。
這是因為編譯器無法區分 &mut 引用的有效和無效使用。為了讓初始化再次工作,我們必須使用不安全的 get_unchecked_mut 方法:
// safe because modifying a field doesn't move the whole struct
unsafe {
let mut_ref = Pin::as_mut(&mut heap_value);
Pin::get_unchecked_mut(mut_ref).self_ptr = ptr;
}
get_unchecked_mut 函數在 Pin<&mut T> 上工作,而不是在 Pin<Box<T>> 上,因此我們必須使用 Pin::as_mut 來轉換值。
然後我們可以使用 get_unchecked_mut 返回的 &mut 引用來設置 self_ptr 字段。
現在唯一剩下的錯誤是,我們所期待的在 mem::replace 上出現的錯誤。
記住,這個操作嘗試將堆分配的值移動到棧上,這將破壞存儲在 self_ptr 字段中的自引用。
通過選擇不實現 Unpin 並使用 Pin<Box<T>>,我們可以在編譯時阻止這個操作,從而安全地使用自引用結構體。
正如我們所看到的,編譯器無法證明創建自引用是安全的(目前是這樣),所以我們需要使用一個不安全的塊並自己驗證其正確性。
🔗棧上釘住和 Pin<&mut T>
前一節中,我們學習了如何使用 Pin<Box<T>> 安全地創建堆分配的自引用值。
雖然這種方法運行良好並且相對安全(除了不安全的構造),但所需的堆分配會帶來性能成本。
由於 Rust 力求在可能的情況下提供 零成本抽象,釘住 pinning API 也允許創建指向棧分配值的 Pin<&mut T> 實例。
不像 Pin<Box<T>> 实例拥有被包装的值的 所有权,Pin<&mut T> 实例只是暂时借用了被包装的值。
这使得事情变得更加复杂,因为它要求程序员自己确保额外的保证。
最重要的是,Pin<&mut T> 必须在整个 T 的引用生命周期内保持固定,對於基於棧的變量來說,这可能很难验证。
为了帮助解决这个问题,存在像 pin-utils 这样的 crate,但我仍然不建议将 釘住操作 应用到栈上,除非你真的知道你在做什么。
更多資訊,請查看 pin module 的文檔和 Pin::new_unchecked 方法。
🔗釘住操作和 Futures
就如我們已在本文中看到的那樣,Future::poll 方法使用釘住操作,它的形式是一個 Pin<&mut Self> 參數:
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>
該方法帶有 self: Pin<&mut Self> 而不是普通的 &mut self 的原因是,從 async/await 創建的 future 實例通常是自引用的,正如我們 上面 所看到的。
通過將 Self 包裝到 Pin 中,並讓編譯器為從 async/await 生成的自引用 future 選擇不實現 Unpin,可以保證在 poll 調用之間不會在內存中移動 future。這確保了所有內部引用仍然有效。
值得注意的是,在第一次 poll 調用之前移動 future 是沒問題的。這是因為 future 是惰性的,直到第一次被輪詢之前它們不會做任何事情。
生成的狀態機的 start 狀態因此只包含函數參數,而沒有內部引用。為了調用 poll,調用者必須首先將 future 包裝到 Pin 中,
這確保了 future 在內存中不會再被移動。由於 棧上 釘住操作 更難正確使用,我建議總是使用 Box::pin 結合 Pin::as_mut 來實現。
如果你有興趣了解如何安全地使用 棧上 釘住操作 自己實現一個 future 組合器 函數,請查看 futures crate 的相對短的 source of the map combinator method 和釘住操作文檔的 projections and structural pinning 部分。
🔗執行器 和 喚醒器
使用 async/await,我們可以使用完全異步的方式舒適地使用 futures。然而,正如我們上面所學到的,futures 在被輪詢之前不會做任何事情。這意味著我們必須在某個時候調用 poll,否則異步代碼永遠不會被執行。
使用單個 future,我們總是可以 如上所述 地使用循環手動等待每個 future。 然而,這種方法非常低效,對於創建大量 future 的程序來說並不實用。這個問題的最常見解決方案是定義一個全局的 執行器,它負責輪詢系統中的所有 future 直到它們完成。
🔗執行器 Executors
執行器的目的是允許將 future 作為獨立任務進行生成,通常通過某種 spawn 方法。然後執行器負責輪詢所有 future 直到它們完成。
管理所有 future 的一個重要優勢是,當 future 返回 Poll::Pending 時,執行器可以切換到另一個 future。
因此,異步操作是並行運行的,並且 CPU 保持忙碌。
許多執行器的實現也可以利用具有多個 CPU 核心的系統。它們創建了一個 線程池 thread pool,如果有足夠的工作可用, 它可以利用所有核心,並使用諸如 work stealing 之類的技術來平衡核心之間的負載。 還有一些針對嵌入式系統的特殊執行器實現,它們優化了低延遲和內存開銷。
為了避免重複輪詢 future 的開銷,執行器通常利用 Rust 的 futures 支持的 喚醒器 waker API。
🔗喚醒器 Wakers
喚醒器 API 的想法是,一個特殊的 Waker 類型被傳遞給每個 poll 調用,它被包裝在 Context 類型中。
這個 Waker 類型是由執行器創建的,可以被異步任務用來通知它的(部分)完成。
因此,執行器不需要在之前返回 Poll::Pending 的 future 上調用 poll,直到它被相應的喚醒器通知。
這最好通過一個小例子來說明:
async fn write_file() {
async_write_file("foo.txt", "Hello").await;
}
這個函數異步地將字符串 “Hello” 寫入到 foo.txt 文件中。由於硬盤寫入需要一些時間,這個 future 的第一次 poll 調用可能會返回 Poll::Pending。
然而,硬盤驅動程序將內部存儲傳遞給 poll 調用的 Waker,並在文件寫入到硬盤時使用它來通知執行器。
這樣,執行器在收到喚醒器通知之前不需要浪費任何時間嘗試再次 poll 這個 future。
我們將在本文的實現部分中看到 Waker 類型的工作原理,當我們創建一個具有喚醒器支持的執行器時。
🔗協作式多任務?
在本文的開頭,我們談到了抢占式和協作式多任務。雖然抢占式多任務依賴於操作系統強制在運行任務之間切換, 但協作式多任務要求任務定期通過 yield 操作自願放棄 CPU 控制。協作式方法的一個巨大優勢是任務可以自己保存它們的狀態, 這導致更有效的上下文切換,並且使得可以在任務之間共享相同的調用棧。
這可能不是顯而易見的,但 futures 和 async/await 是協作式多任務模式的一種實現:
-
每個添加到執行器的 future 基本上是一個協作式任務。
-
不同於顯式的使用 yield 操作,futures 通過返回
Poll::Pending來放棄 CPU 控制(或者在結束時返回Poll::Ready)。-
沒有任何東西強制 futures 放棄 CPU 控制。如果他們想要,他們可以永遠不從
poll返回,例如,通過在循環中無休止地旋轉。 -
由於每個 future 都可以阻塞執行器中的其他 future 的執行,我們需要相信它們不是惡意的。
-
-
Futures 內部存儲了所有它們需要的狀態,以便在下一次
poll調用時繼續執行。 使用 async/await,編譯器自動檢測所有需要的變量並將它們存儲在生成的狀態機中。-
只保存了繼續執行所需的最小狀態。
-
翻譯上面的文字: 由於
poll方法在返回時放棄了調用棧,因此可以使用相同的棧來輪詢其他 futures。
-
我們看到 futures 和 async/await 完美地適應了協作式多任務模式;它們只是使用了一些不同的術語。 在接下來的內容中,我們將 “任務” 和 “future” 兩個術語混着使用。
🔗實現
現在我們了解了基於 futures 和 async/await 的協作式多任務在 Rust 中是如何工作的,是時候將對它的支持添加到我們的內核中了。
由於 Future trait 是 core 库的一部分,而 async/await 是語言本身的一個特性,我們在 #![no_std] 內核中使用它時不需要做任何特殊的事情。
唯一的要求是我們至少使用 Rust 的 nightly 版本 2020-03-25,因為在此之前,async/await 不兼容 no_std。
就着足夠新的 nightly 版本,我們可以在 main.rs 中開始使用 async/await:
// in src/main.rs
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
函數 async_number 是一個 async fn,所以編譯器將它轉換為一個實現了 Future 的狀態機。
由於函數只返回 42,所以生成的 future 將在第一次 poll 調用時直接返回 Poll::Ready(42)。
像 async_number 一樣,example_task 函數也是一個 async fn。它等待 async_number 返回的數字,然後使用 println 宏打印它。
爲運行 example_task 返回的 future,我們需要在它上調用 poll 直到它通過返回 Poll::Ready 來標誌它的完成。
為了做到這一點,我們需要創建一個簡單的執行器類型。
🔗任務 Task
實現執行器之前,我們先創建一個新的 task 模塊,裡面包含一個 Task 類型:
// in src/lib.rs
pub mod task;
// in src/task/mod.rs
use core::{future::Future, pin::Pin};
use alloc::boxed::Box;
pub struct Task {
future: Pin<Box<dyn Future<Output = ()>>>,
}
Task 結構體是一個對堆分配的、釘住的、動態分發的 future 的新型包裝,它的輸出類型是空類型 ()。讓我們逐一詳細說明:
-
我們要求與任務關聯的 future 返回
()。這意味着任務不返回任何結果,它們只是執行它們的副作用。例如,我們上面定義的example_task函數沒有返回值,但它作為副作用打印了一些東西到屏幕上。 -
關鍵字
dyn表示我們在Box中存儲了一個 trait object。這意味着 future 上的方法是 動態分發 dynamically dispatched 的,允許不同類型的 future 存儲在Task類型中。這一點很重要,因為每個async fn都有自己的類型,我們希望能夠創建多個不同的任務。 -
正如我們在 釘住操作 部分 section about pinning 學到的,
Pin<Box>類型通過將值放在堆上並防止創建對它的&mut引用來確保值在內存中不會被移動。這一點很重要,因為由 async/await 生成的 future 可能是自引用的,即包含指向自己的指針,當 future 被移動時這些指針將失效。
爲允許從 future 創建新的 Task 結構體,我們創建一個 new 函數:
// in src/task/mod.rs
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
future: Box::pin(future),
}
}
}
函數帶有一個任意的 future,它的輸出類型是 (),並通過 Box::pin 函數在內存中釘住它。
然後它將被包裝的 future 放到 Task 結構體中並返回它。這裡需要 'static 生命周期,因為返回的 Task 可以存活在任意時間,
所以 future 也需要在那個時間內有效。
我們還加了一個 poll 方法,允許執行器輪詢持有的 future:
// in src/task/mod.rs
use core::task::{Context, Poll};
impl Task {
fn poll(&mut self, context: &mut Context) -> Poll<()> {
self.future.as_mut().poll(context)
}
}
由於 Future trait 的 poll 方法期望在 Pin<&mut T> 類型上調用,我們首先使用 Pin::as_mut 方法將 self.future 字段從 Pin<Box<T>> 類型轉換為 Pin<&mut T> 類型。然後我們在轉換後的 self.future 字段上調用 poll,並返回結果。
由於 Task::poll 方法只應該由我們即將創建的執行器調用,我們將函數保持為 task 模塊的私有。
🔗簡單的執行器
因爲執行器可能相當複雜,我們故意在實現更多功能的執行器之前先創建一個非常基本的執行器。為此,我們首先創建一個新的 task::simple_executor 子模塊:
// in src/task/mod.rs
pub mod simple_executor;
// in src/task/simple_executor.rs
use super::Task;
use alloc::collections::VecDeque;
pub struct SimpleExecutor {
task_queue: VecDeque<Task>,
}
impl SimpleExecutor {
pub fn new() -> SimpleExecutor {
SimpleExecutor {
task_queue: VecDeque::new(),
}
}
pub fn spawn(&mut self, task: Task) {
self.task_queue.push_back(task)
}
}
這結構體包含一個 task_queue 字段,類型是 VecDeque,它基本上是一個允許在兩端進行推送和彈出操作的向量。
使用這種類型的想法是,我們通過 spawn 方法在末尾插入新的任務,並從前面彈出下一個任務進行執行。
這樣,我們得到了一個簡單的 FIFO queue(“first in, first out” 先進先出)隊列容器。
🔗擺設型喚醒器 Dummy Waker
爲了調用 poll 方法,我們需要創建一個 Context 類型,它包裝了一個 Waker 類型。
為了簡單起見,我們首先創建一個什麼都不做的假貨喚醒器。
為此,我們創建了一個 RawWaker 實例,它定義了 Waker 的各種方法的實現,然後使用 Waker::from_raw 函數將它轉換為 Waker:
// in src/task/simple_executor.rs
use core::task::{Waker, RawWaker};
fn dummy_raw_waker() -> RawWaker {
todo!();
}
fn dummy_waker() -> Waker {
unsafe { Waker::from_raw(dummy_raw_waker()) }
}
函數 from_raw 是不安全的,因為如果程序員不遵守 RawWaker 的文檔要求,就可能發生未定義的行為。
在我們查看 dummy_raw_waker 函數的實現之前,我們首先試圖理解 RawWaker 類型的工作原理。
🔗RawWaker
類型 RawWaker 要求程序員明確地定義一個 virtual method table (vtable),它指定了在 RawWaker 被克隆、喚醒或丟棄時應該調用的函數。
這個 vtable 的佈局由 RawWakerVTable 類型定義。每個函數接收一個 *const () 參數,這是一個對某個值的 type-erased 指針。
使用 *const () 指針而不是正確的引用的原因是,RawWaker 類型應該是非泛型的,但仍然支持任意類型。
通過將它放入 RawWaker::new 的 data 參數中提供,這個函數只是初始化了一個 RawWaker。
然後 Waker 使用這個 RawWaker 來使用 data 調用 vtable 函數。
通常,RawWaker 是為一些堆分配的結構體創建的,它被包裝到 Box 或 Arc 類型中。
對於這樣的類型,可以使用 Box::into_raw 這樣的方法將 Box<T> 轉換為 *const T 指針。
然後可以將這個指針轉換為匿名的 *const () 指針並傳遞給 RawWaker::new。
由於每個 vtable 函數都接收相同的 *const () 作為參數,所以函數可以安全地將指針轉換回 Box<T> 或 &T 來操作它。
正如你所預料的,這個過程是非常危險的,並且很容易在出錯時導致未定義的行為。因此,除非必要,否則不建議手動創建 RawWaker。
🔗擺設型 RawWaker
既然手工創建 RawWaker 不被推薦,目前沒有其他方法可以創建一個什麼都不做的假貨喚醒器 Waker。
幸運的是,我們想要什麼都不做這一事實使得實現 dummy_raw_waker 函數相對安全:
// in src/task/simple_executor.rs
use core::task::RawWakerVTable;
fn dummy_raw_waker() -> RawWaker {
fn no_op(_: *const ()) {}
fn clone(_: *const ()) -> RawWaker {
dummy_raw_waker()
}
let vtable = &RawWakerVTable::new(clone, no_op, no_op, no_op);
RawWaker::new(0 as *const (), vtable)
}
首先,我們定義了兩個內部函數 no_op 和 clone。no_op 函數接收一個 *const () 指針並且什麼都不做。
clone 函數也接收一個 *const () 指針並且通過再次調用 dummy_raw_waker 返回一個新的 RawWaker。
我們使用這兩個函數來創建一個最小的 RawWakerVTable:clone 函數用於克隆操作,no_op 函數用於所有其他操作。
由於 RawWaker 什麼都不做,所以我們從 clone 返回一個新的 RawWaker 而不是克隆它,這並不重要。
創建 vtable 後,我們使用 RawWaker::new 函數創建 RawWaker。
傳遞的 *const () 沒有關係,因為 vtable 函數都不使用它。因此,我們只是簡單地傳遞了一個空指針。
🔗run 方法
現在我們有了創建 Waker 實例的方法,我們可以使用它來在執行器上實現一個 run 方法。
最簡單的 run 方法是重複地在循環中輪詢所有排隊的任務,直到它們全部完成。
這並不是非常高效,因為它沒有利用 Waker 類型的通知,但這是一個讓執行器運行起來的簡單方法:
// in src/task/simple_executor.rs
use core::task::{Context, Poll};
impl SimpleExecutor {
pub fn run(&mut self) {
while let Some(mut task) = self.task_queue.pop_front() {
let waker = dummy_waker();
let mut context = Context::from_waker(&waker);
match task.poll(&mut context) {
Poll::Ready(()) => {} // task done
Poll::Pending => self.task_queue.push_back(task),
}
}
}
}
函數使用 while let 循環來處理 task_queue 中的所有任務。
對於每個任務,它首先通過包裝 dummy_waker 函數返回的 Waker 實例來創建一個 Context 類型。
然後它使用這個 context 調用 Task::poll 方法。如果 poll 方法返回 Poll::Ready,則任務已完成,我們可以繼續下一個任務。
如果任務仍然是 Poll::Pending,我們將它再次添加到隊列的末尾,這樣它將在後續的循環迭代中再次被輪詢。
🔗Trying It
就着我們的 SimpleExecutor 類型,我們現在可以嘗試在 main.rs 中運行 example_task 函數返回的任務了:
// in src/main.rs
use blog_os::task::{Task, simple_executor::SimpleExecutor};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] initialization routines, including `init_heap`
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.run();
// […] test_main, "it did not crash" message, hlt_loop
}
// Below is the example_task function again so that you don't have to scroll up
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
在我們運行它時,我們看到了預期的 “async number: 42” 消息被打印到屏幕上:
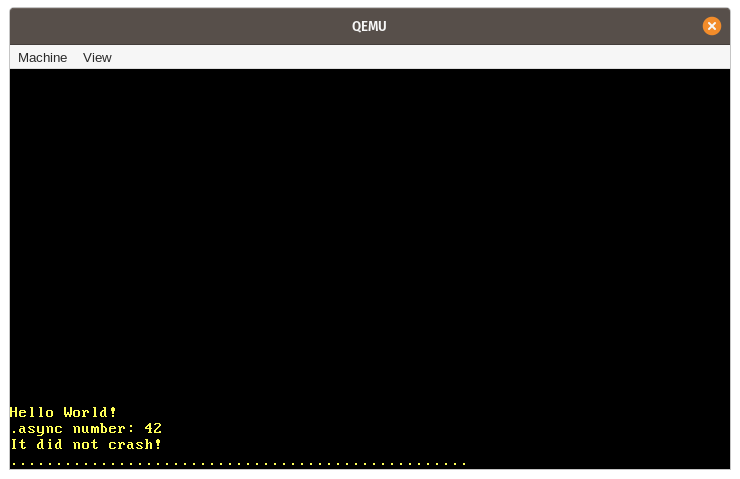
讓我們總結一下這個例子中發生的各種步驟:
-
首先,創建了一個新的
SimpleExecutor類型的實例,它的task_queue是空的。 -
其次,我們調用異步
example_task函數,它返回一個 future。我們將這個 future 包裝在Task類型中,這將它移動到堆上並釘住它,然後通過spawn方法將任務添加到執行器的task_queue中。 -
我們然後調用
run方法來開始執行隊列中的單個任務。這包括: -
方法
run在task_queue變為空後返回。我們的kernel_main函數的執行繼續進行,並打印了 “It did not crash!” 消息。
🔗異步鍵盤輸入
我們的簡單執行器沒有利用 Waker 通知,只是循環遍歷所有任務,直到它們完成。
這對我們的例子來說並不是問題,因為我們的 example_task 可以直接在第一次 poll 調用時運行到結束。
為了看到正確的 Waker 實現的性能優勢,我們首先需要創建一個真正異步的任務,即一個任務,它可能在第一次 poll 調用時返回 Poll::Pending。
我們已經有一些我們可以用來實現這一點的系統異步性:硬件中斷。正如我們在 Interrupts 文章中了解到的,硬件中斷可以在任意時間點發生,由某個外部設備決定。 例如,硬件計時器在某個預定的時間後向 CPU 發送一個中斷。當 CPU 收到一個中斷時,它立即將控制權轉移到中斷描述符表(IDT)中定義的相應處理函數。
在接下來的內容中,我們將基於鍵盤中斷創建一個異步任務。鍵盤中斷是一個很好的候選者,因為它既是非確定性的,又是延遲關鍵的。
非確定性意味着沒有辦法預測下一次按鍵何時發生,因為它完全取決於用戶。
延遲關鍵意味着我們希望及時處理鍵盤輸入,否則用戶會感到延遲。為了支持這樣的任務,執行器對 Waker 通知的支持是至關重要的。
🔗掃描碼隊列 Scancode Queue
目前,我們直接在中斷處理程序中處理鍵盤輸入。這對長期來說並不是一個好主意,因為中斷處理程序應該保持盡可能短,因為它們可能會中斷重要的工作。 相反,中斷處理程序應該只執行必要的最小工作(例如,讀取鍵盤掃描碼),並將其餘的工作(例如,解釋掃描碼)留給後台任務。
將工作委派給後台任務的常見模式是創建某種類型的隊列。中斷處理程序將工作單元推送到隊列,後台任務處理隊列中的工作。應用到我們的鍵盤中斷,這意味着中斷處理程序只從鍵盤讀取掃描碼,將其推送到隊列,然後返回。鍵盤任務位於隊列的另一端,解釋和處理推送到它的每個掃描碼:

那隊列的一個簡單實現可以是一個互斥保護的 VecDeque。然而,在中斷處理程序中使用互斥鎖並不是一個好主意,因為它很容易導致死鎖。
例如,當用戶在鍵盤任務鎖定隊列時按下一個鍵,中斷處理程序再次嘗試獲取鎖,這會導致無限期地掛起。
這種方法的另一個問題是,當 VecDeque 變滿時,它會自動通過執行新的堆分配來增加其容量。
這可能再次導致死鎖,因為我們的分配器也在內部使用互斥鎖。進一步的問題是,當堆被碎片化時,堆分配可能會失敗或花費相當多的時間。
T爲避免這些問題,我們需要一個隊列實現,它不需要互斥鎖或堆分配來進行 push 操作。
這樣的隊列可以通過使用無鎖的 原子操作 atomic operations 來實現,用於推送和彈出元素。
這樣,可以創建只需要 &self 引用的 push 和 pop 操作,因此可以在沒有互斥鎖的情況下使用。
爲了避免在 push 上進行分配,隊列可以由一個預先分配的固定大小的緩衝區支持。
雖然這使得隊列 有界(即,它有一個最大長度),但實際上通常可以定義合理的隊列長度上限,因此這並不是一個大問題。
🔗The crossbeam Crate
正確而高效地實現這樣一個隊列是非常困難的,所以我建議使用現有的經過充分測試的實現。
一個流行的 Rust 項目,它實現了各種無鎖類型來進行並發編程,就是 crossbeam。
它提供了一個名為 ArrayQueue 的類型,這正是我們在這種情況下所需要的。而且我們很幸運:這個類型完全兼容 具有分配支持的 no_std 庫。
爲使用這個類型,我們需要在 Cargo.toml 中添加對 crossbeam-queue 的依賴:
# in Cargo.toml
[dependencies.crossbeam-queue]
version = "0.2.1"
default-features = false
features = ["alloc"]
翻譯上面的文字: 默認情況下,這個 crate 依賴於標準庫。為了使它兼容 no_std,我們需要禁用它的默認功能,並啓用 alloc 功能。 (注意,我們也可以添加對主要的 crossbeam crate 的依賴,它重新導出了 crossbeam-queue crate,但這將導致更多的依賴和更長的編譯時間。)
🔗Queue Implementation
使用 ArrayQueue 類型,我們現在可以在一個新的 task::keyboard 模塊中創建一個全局的掃描碼隊列:
// in src/task/mod.rs
pub mod keyboard;
// in src/task/keyboard.rs
use conquer_once::spin::OnceCell;
use crossbeam_queue::ArrayQueue;
static SCANCODE_QUEUE: OnceCell<ArrayQueue<u8>> = OnceCell::uninit();
由於 ArrayQueue::new 執行了堆分配,這在編譯時是不可能的(目前不可能,但有可能)。我們不能直接初始化靜態變量。
相反,我們使用 conquer_once crate 的 OnceCell 類型,它使得可以對靜態值進行安全的一次性初始化。
要包含這個 crate,我們需要在 Cargo.toml 中將它添加為依賴:
# in Cargo.toml
[dependencies.conquer-once]
version = "0.2.0"
default-features = false
異於 OnceCell 源語,我們也可以在這裡使用 lazy_static 宏。
然而,OnceCell 類型的優點是我們可以確保初始化不會在中斷處理程序中進行,從而防止中斷處理程序執行堆分配。
🔗填充掃描碼隊列
爲填充掃描碼隊列,我們創建一個新的 add_scancode 函數,我們將從中斷處理程序中調用:
// in src/task/keyboard.rs
use crate::println;
/// Called by the keyboard interrupt handler
///
/// Must not block or allocate.
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}
我們使用 OnceCell::try_get 來獲取初始化的隊列的引用。如果隊列還沒有初始化,我們忽略鍵盤掃描碼並打印一個警告。
重要的是,我們不應該在這個函數中嘗試初始化隊列,因為它將被中斷處理程序調用,而中斷處理程序不應該執行堆分配。
由於這個函數不應該從我們的 main.rs 中調用,我們使用 pub(crate) 可見性來使它只對我們的 lib.rs 可用。
方法 ArrayQueue::push 只需要一個 &self 引用,這使得在靜態隊列上調用這個方法非常簡單。
ArrayQueue 類型自己執行所有必要的同步,所以我們這裡不需要一個互斥鎖包裝器。如果隊列已滿,我們也打印一個警告。
爲在鍵盤中斷上調用 add_scancode 函數,我們更新 interrupts 模塊中的 keyboard_interrupt_handler 函數:
// in src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame
) {
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
crate::task::keyboard::add_scancode(scancode); // new
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
我們移除了這個函數中的所有鍵盤處理代碼,並添加了一個對 add_scancode 函數的調用。這個函數的其餘部分與之前的一樣。
符合預期,當我們使用 cargo run 運行我們的項目時,按鍵不再被打印到屏幕上。相反,我們看到了每次按鍵都會警告說掃描碼隊列未初始化。
🔗掃描碼流 Scancode Stream
爲初始化 SCANCODE_QUEUE 並以異步方式從隊列中讀取掃描碼,我們創建了一個新的 ScancodeStream 類型:
// in src/task/keyboard.rs
pub struct ScancodeStream {
_private: (),
}
impl ScancodeStream {
pub fn new() -> Self {
SCANCODE_QUEUE.try_init_once(|| ArrayQueue::new(100))
.expect("ScancodeStream::new should only be called once");
ScancodeStream { _private: () }
}
}
字段 _private 的目的是防止從模塊外部構造結構。這使得 new 函數成為構造類型的唯一方法。在這個函數中,我們首先嘗試初始化 SCANCODE_QUEUE 靜態變量。
如果它已經初始化,我們會 panic,以確保只能創建單一 ScancodeStream 實例。
爲了使掃描碼對異步任務可用,下一步是實現一個類似 poll 的方法,它嘗試從隊列中彈出下一個掃描碼。
雖然這聽起來像是我們應該爲我們的類型實現 Future trait,但這並不完全適用於這裡。
問題是 Future trait 只是對單個異步值進行抽象,並且期望 poll 方法在返回 Poll::Ready 後不再被調用。
然而,我們的掃描碼隊列包含多個異步值,所以保持對它的輪詢是可以的。
🔗The Stream Trait
由於產生多個異步值的類型很常見,futures crate 提供了一種對這類型的有用抽象:Stream trait。該 特型 trait 的定義如下:
pub trait Stream {
type Item;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Option<Self::Item>>;
}
這個定義與 Future trait 非常相似,但有以下區別:
-
關聯類型命名為
Item而不是Output。 -
不同於
pool方法返回Poll<Self::Item>,Streamtrait 定義了一個poll_next方法,它返回Poll<Option<Self::Item>>(注意額外的Option)。
還有個語義上的區別:poll_next 可以被重複調用,直到它返回 Poll::Ready(None) 來表示流結束。
在這方面,這個方法類似於 Iterator::next 方法,它在最後一個值之後也返回 None。
🔗實現 Stream
我們來爲 ScancodeStream 實現 Stream trait,以提供 SCANCODE_QUEUE 的值。
爲此,我們首先需要添加對 futures-util crate 的依賴,它包含了 Stream 類型:
# in Cargo.toml
[dependencies.futures-util]
version = "0.3.4"
default-features = false
features = ["alloc"]
我們禁用了默認功能,以使這個 crate 兼容 no_std,並啓用 alloc 功能以使其 基於分配的類型 可用(我們稍後會需要這個)。
(注意,我們也可以添加對主要的 futures crate 的依賴,它重新導出了 futures-util crate,但這將導致更多的依賴和更長的編譯時間。)
現在我們可以導入並實現 Stream trait:
// in src/task/keyboard.rs
use core::{pin::Pin, task::{Poll, Context}};
use futures_util::stream::Stream;
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE.try_get().expect("not initialized");
match queue.pop() {
Ok(scancode) => Poll::Ready(Some(scancode)),
Err(crossbeam_queue::PopError) => Poll::Pending,
}
}
}
我們首先使用 OnceCell::try_get 方法來獲取初始化的掃描碼隊列的引用。
這應該永遠不會失敗,因為我們在 new 函數中初始化了隊列,所以我們可以安全地使用 expect 方法來在它未初始化時 panic。
接下來,我們使用 ArrayQueue::pop 方法來嘗試從隊列中獲取下一個元素。如果成功,我們返回包裝在 Poll::Ready(Some(…)) 中的掃描碼。
如果失敗,這意味着隊列是空的。在這種情況下,我們返回 Poll::Pending。
🔗喚醒器 Waker 支持
就像 Futures::poll 方法一樣,Stream::poll_next 方法要求異步任務在返回 Poll::Pending 後讓執行器知道它何時變得可用。
這樣,執行器就不需要再次輪詢同一個任務,直到它被通知,這大大減少了等待任務的性能開銷。
爲發送這個通知,任務應該從傳遞的 Context 引用中提取 Waker,並將它存儲在某個地方。
當任務變得可用時,它應該在存儲的 Waker 上調用 wake 方法,以通知執行器該任務應該再次被輪詢。
🔗AtomicWaker
爲實現 ScancodeStream 的 Waker 通知,我們需要在輪詢調用之間找個地方來存儲 Waker。
我們不能將它存儲為 ScancodeStream 本身的字段,因為它需要從 add_scancode 函數中訪問。
這個問題的解決方案是使用 futures-util crate 提供的 AtomicWaker 類型的靜態變量。
像 ArrayQueue 類型一樣,這個類型基於原子指令,可以安全地存儲在 static 靜態變量 中並且可以並發修改。
我們使用 AtomicWaker 類型來定義一個靜態的 WAKER:
// in src/task/keyboard.rs
use futures_util::task::AtomicWaker;
static WAKER: AtomicWaker = AtomicWaker::new();
意思就是 poll_next 實現將當前的 waker 存儲在這個靜態變量中,而 add_scancode 函數在將新的掃描碼添加到隊列時在它上調用 wake 函數。
🔗存儲喚醒器 Storing a Waker
由 poll/poll_next 定義的規則要求當任務返回 Poll::Pending 時,它應該爲傳遞的 Waker 註冊一個喚醒動作。
我們修改我們的 poll_next 實現來滿足這個要求:
// in src/task/keyboard.rs
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE
.try_get()
.expect("scancode queue not initialized");
// fast path
if let Ok(scancode) = queue.pop() {
return Poll::Ready(Some(scancode));
}
WAKER.register(&cx.waker());
match queue.pop() {
Ok(scancode) => {
WAKER.take();
Poll::Ready(Some(scancode))
}
Err(crossbeam_queue::PopError) => Poll::Pending,
}
}
}
像之前一樣,我們首先使用 OnceCell::try_get 函數來獲取初始化的掃描碼隊列的引用。然後我們嘗試從隊列中 pop 掃描碼,並在成功時返回 Poll::Ready。
這樣,我們可以避免在隊列不為空時註冊一個喚醒器的性能開銷。
如果 queue.pop() 的第一次調用不成功,隊列可能是空的。只是可能,因爲中斷處理程序可能在檢查後立即異步填充了隊列。
由於這種競態條件可能再次發生在下一次檢查中,我們需要在第二次檢查之前在 WAKER 靜態變量中註冊 Waker。
這樣,一個喚醒動作可能會在我們返回 Poll::Pending 之前發生,但可以保證我們會在檢查後推送的任何掃描碼上得到一個喚醒動作。
在通過函數 AtomicWaker::register 註冊了傳遞的 Context 中包含的 Waker 之後,我們嘗試第二次從隊列中彈出。
如果這次成功,我們返回 Poll::Ready。我們還使用 AtomicWaker::take 再次移除註冊的喚醒器,因爲不再需要喚醒通知。
如果 queue.pop() 第二次失敗,我們像之前一樣返回 Poll::Pending,但這次帶有一個已註冊的喚醒動作。
注意,對於一個(可能還)沒有返回 Poll::Pending 的任務,有兩種方式可以進行喚醒。
一種方式是上面提到的競態條件,當喚醒在返回 Poll::Pending 之前立即發生。
另一種方式是在註冊喚醒器後隊列不再為空,這樣 Poll::Ready 就會被返回。
由於這些虛假的喚醒是無法防止的,執行器需要能夠正確地處理它們。
🔗喚醒存儲的喚醒器 Waker
要喚醒存儲的 Waker,我們在 add_scancode 函數中添加一個對 WAKER.wake() 的調用:
// in src/task/keyboard.rs
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
} else {
WAKER.wake(); // new
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}
我們做出的唯一更改是在成功推送到掃描碼隊列時添加了一個對 WAKER.wake() 的調用。
如果在 WAKER 靜態變量中註冊了一個喚醒器,這個方法將在它上面調用同名的 wake 方法,這將通知執行器。否則,這個操作是一個空操作,即,什麼也不會發生。
很重要的是,我們只在推送到隊列後調用 wake,否則任務可能會在隊列仍然為空時被過早地喚醒。
這可能發生在使用多線程執行器時,它在不同的 CPU 核心上同時啓動被喚醒的任務。雖然我們還沒有線程支持,但我們很快就會添加它,並且不希望事情在那時候出問題。
🔗鍵盤任務
我們現在爲 ScancodeStream 實現了 Stream trait,我們可以使用它來創建一個異步鍵盤任務:
// in src/task/keyboard.rs
use futures_util::stream::StreamExt;
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use crate::print;
pub async fn print_keypresses() {
let mut scancodes = ScancodeStream::new();
let mut keyboard = Keyboard::new(layouts::Us104Key, ScancodeSet1,
HandleControl::Ignore);
while let Some(scancode) = scancodes.next().await {
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
}
}
代碼與我們之前在 keyboard interrupt handler 中的代碼非常相似,只是我們不再從 I/O 端口讀取掃描碼,而是從 ScancodeStream 中獲取它。
爲此,我們首先創建一個新的 Scancode 流,然後重複使用由 StreamExt trait 提供的 next 方法來獲取一個 Future,它解析爲流中的下一個元素。
通過在它上使用 await 運算符,我們異步等待 future 的結果。
我們使用 while let 循環直到流返回 None 標誌它的結束。由於我們的 poll_next 方法從不返回 None,
這實際上是一個無限循環,所以 print_keypresses 任務永遠不會結束。
我們在 main.rs 中將 print_keypresses 任務添加到執行器中,以便再次獲得鍵盤輸入:
// in src/main.rs
use blog_os::task::keyboard; // new
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] initialization routines, including init_heap, test_main
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses())); // new
executor.run();
// […] "it did not crash" message, hlt_loop
}
現在我們執行 cargo run,我們會看到鍵盤輸入再次可用了:

如果你在你的計算機上保持對 CPU 利用率的關注,你會看到 QEMU 進程現在讓 CPU 非常忙碌。
這是因爲我們的 SimpleExecutor 在一個循環中一遍又一遍地輪詢任務。
所以即使我們沒有在鍵盤上按任何鍵,執行器也會一遍又一遍地調用我們的 print_keypresses 任務的 poll 方法,即使該任務無法取得任何進展,並且每次都會返回 Poll::Pending。
🔗帶喚醒器支持的執行器
爲修復性能問題,我們需要創建一個執行器,它正確地利用了 Waker 通知。
這樣,當下一個鍵盤中斷發生時,執行器就會被通知,所以它不需要一遍又一遍地輪詢 print_keypresses 任務。
🔗Task Id
創建具有正確的喚醒器通知支持的 執行器 的第一步是給每個任務分配一個唯一的 ID。
這是必需的,因為我們需要一種方法來指定應該喚醒哪個任務。我們首先創建一個新的 TaskId 包裝類型:
// in src/task/mod.rs
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord)]
struct TaskId(u64);
結構體 TaskId 是一個簡單的 u64 包裝類型。我們爲它衍生了一些特性,使它可以被打印、複製、比較和排序。
後者很重要,因爲我們希望在一會兒使用 TaskId 作爲 BTreeMap 的鍵類型。
爲了創建一個新的唯一 ID,我們創建了一個 TaskId::new 函數:
use core::sync::atomic::{AtomicU64, Ordering};
impl TaskId {
fn new() -> Self {
static NEXT_ID: AtomicU64 = AtomicU64::new(0);
TaskId(NEXT_ID.fetch_add(1, Ordering::Relaxed))
}
}
函數使用了一個 AtomicU64 類型的靜態變量 NEXT_ID 來確保每個 ID 只分配一次。fetch_add 方法以原子方式增加值並在一個原子操作中返回先前的值。
這意味着即使 TaskId::new 方法並行調用,每個 ID 都只返回一次。Ordering 參數定義了編譯器是否允許重新排列指令流中的 fetch_add 操作。
由於我們只需要 ID 是唯一的,這種情況下最弱的要求 Relaxed 排序就足夠了。
現在我們可以通過添加一個額外的 id 字段來擴展我們的 Task 類型:
// in src/task/mod.rs
pub struct Task {
id: TaskId, // new
future: Pin<Box<dyn Future<Output = ()>>>,
}
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
id: TaskId::new(), // new
future: Box::pin(future),
}
}
}
新的 id 字段使得可以唯一地命名一個任務,這是喚醒特定任務所必需的。
🔗The Executor Type
我們在 task::executor 模塊中創建我們的新 Executor 類型:
// in src/task/mod.rs
pub mod executor;
// in src/task/executor.rs
use super::{Task, TaskId};
use alloc::{collections::BTreeMap, sync::Arc};
use core::task::Waker;
use crossbeam_queue::ArrayQueue;
pub struct Executor {
tasks: BTreeMap<TaskId, Task>,
task_queue: Arc<ArrayQueue<TaskId>>,
waker_cache: BTreeMap<TaskId, Waker>,
}
impl Executor {
pub fn new() -> Self {
Executor {
tasks: BTreeMap::new(),
task_queue: Arc::new(ArrayQueue::new(100)),
waker_cache: BTreeMap::new(),
}
}
}
不同於我們在 SimpleExecutor 中使用 VecDeque 存儲任務,我們使用了一個任務 ID 的 task_queue 和一個名爲 tasks 的 BTreeMap,它包含了實際的 Task 實例。這個 map 是由 TaskId 索引的,這樣可以高效地繼續特定的任務。
字段 task_queue 是任務 ID 的 ArrayQueue 類型的容器,包裝在 Arc 類型中, Arc 實現了 引用計數。
引用計數使得可以在多個所有者之間共享值的所有權。它通過在堆上分配值並計算對它的活動引用數量來工作。
當活動引用的數量達到零時,就不再需要這個值,它可以被釋放。
我們使用這個 Arc<ArrayQueue> 類型來存儲 task_queue,因爲它將在執行器和喚醒器之間共享。
這個設計的基本思想是喚醒器將被喚醒的任務的 ID 推送到隊列中。
執行器則在隊列的接收端,通過 ID 從 tasks map 中檢索被喚醒的任務,然後運行它們。
使用固定大小的隊列而不是像 SegQueue 這樣的無界隊列的原因是中斷處理程序不應該在推送到這個隊列時分配內存。
翻譯上面的文字: 除了 task_queue 和 tasks map 之外,Executor 類型還有一個 waker_cache 字段,它也是一個 map。
這個 map 在創建後緩存了任務的 Waker。這有兩個原因:首先,它通過重用同一個任務的多次喚醒而不是每次都創建一個新的喚醒器來提高性能。
其次,它確保引用計數的喚醒器不會在中斷處理程序中被釋放,因爲這可能導致死鎖(下面有更多細節)。
要創建一個 執行器 Executor,我們提供了一個簡單的 new 函數。我們選擇了 100 的容量作爲 task_queue,這應該足夠應付可預見的未來。如果我們的系統在某個時候有超過 100 個並發任務,我們可以輕鬆地增加這個大小。
🔗Spawning Tasks
就像 SimpleExecutor 一樣,我們在 執行器 Executor 類型上提供了一個 spawn 方法,
它將給定的任務添加到 tasks map 中,並立即通過將它的 ID 推送到 task_queue 中來喚醒它:
// in src/task/executor.rs
impl Executor {
pub fn spawn(&mut self, task: Task) {
let task_id = task.id;
if self.tasks.insert(task.id, task).is_some() {
panic!("task with same ID already in tasks");
}
self.task_queue.push(task_id).expect("queue full");
}
}
如果 map 中已經有一個具有相同 ID 的任務,[BTreeMap::insert] 方法會返回它。
這應該永遠不會發生,因爲每個任務都有一個唯一的 ID,所以在這種情況下我們會 panic,因爲這表明我們的代碼中有一個 bug。
同樣,如果我們選擇了足夠大的隊列大小,當 task_queue 滿時我們也會 panic,因爲這應該永遠不會發生。
🔗運行任務 Running Tasks
爲在 task_queue 中運行所有任務,我們創建了一個私有的 run_ready_tasks 方法:
// in src/task/executor.rs
use core::task::{Context, Poll};
impl Executor {
fn run_ready_tasks(&mut self) {
// destructure `self` to avoid borrow checker errors
let Self {
tasks,
task_queue,
waker_cache,
} = self;
while let Ok(task_id) = task_queue.pop() {
let task = match tasks.get_mut(&task_id) {
Some(task) => task,
None => continue, // task no longer exists
};
let waker = waker_cache
.entry(task_id)
.or_insert_with(|| TaskWaker::new(task_id, task_queue.clone()));
let mut context = Context::from_waker(waker);
match task.poll(&mut context) {
Poll::Ready(()) => {
// task done -> remove it and its cached waker
tasks.remove(&task_id);
waker_cache.remove(&task_id);
}
Poll::Pending => {}
}
}
}
}
這函數基本的想法與我們的 SimpleExecutor 類型相似:循環遍歷 task_queue 中的所有任務,爲每個任務創建一個喚醒器,然後輪詢它們。
然而,與將待定任務添加回 task_queue 的 SimpleExecutor 不同,我們讓我們的 TaskWaker 實現來處理將被喚醒的任務添加回隊列。
這個喚醒器類型的實現將在下面展示。
讓我們來看看這個 run_ready_tasks 方法的一些實現細節:
-
我們使用 destructuring 將
self分成它的三個字段,以避免一些借用檢查錯誤。 換句話說,我們的實現需要從一個閉包中訪問self.task_queue,這個閉包目前嘗試完全借用self。 這是一個基本的借用檢查問題,將在 RFC 2229 被 實現 時解決。 -
對於每個彈出的任務 ID,我們從
tasksmap 中獲取了一個對應任務的可變引用。由於我們的ScancodeStream實現在檢查任務是否需要睡眠之前註冊了喚醒器,可能會發生一個任務不存在的情況。在這種情況下,我們只是忽略這個喚醒,並繼續處理隊列中的下一個 ID。 -
爲避免在每次輪詢時創建喚醒器的性能開銷,我們使用
waker_cachemap 來存儲每個任務的喚醒器。爲此,我們使用了BTreeMap::entry方法和Entry::or_insert_with來在它不存在時創建一個新的喚醒器,然後獲取一個對它的可變引用。爲創建一個新的喚醒器,我們克隆了task_queue,並將它與任務 ID 一起傳遞給TaskWaker::new函數(下面展示了實現)。由於task_queue被包裝在一個Arc中,clone只增加了值的引用計數,但仍然指向同一個堆分配的隊列。請注意,像這樣重用喚醒器對於所有的喚醒器實現來說都是不可能的,但我們的TaskWaker類型將允許它。
當任務返回 Poll::Ready 時,它就完成了。在這種情況下,我們使用 BTreeMap::remove 方法從 tasks map 中移除它。如果它的緩存喚醒器存在,我們也會移除它。
🔗喚醒器 Waker 設計
喚醒器的工作是將被喚醒的任務的 ID 推送到執行器的 task_queue 中。
我們通過創建一個新的 TaskWaker 結構來實現這一點,它存儲任務 ID 和對 task_queue 的引用:
// in src/task/executor.rs
struct TaskWaker {
task_id: TaskId,
task_queue: Arc<ArrayQueue<TaskId>>,
}
因爲 task_queue 的所有權在執行器和喚醒器之間共享,我們使用了 Arc 包裝類型來實現共享的引用計數所有權。
喚醒操作的實現非常簡單:
// in src/task/executor.rs
impl TaskWaker {
fn wake_task(&self) {
self.task_queue.push(self.task_id).expect("task_queue full");
}
}
我們推送 task_id 到引用的 task_queue。由於對 ArrayQueue 類型的修改只需要一個共享引用,我們可以在 &self 上實現這個方法,而不是在 &mut self 上。
🔗The Wake Trait
爲了使用我們的 TaskWaker 類型來輪詢 future,我們首先需要將它轉換爲一個 Waker 實例。
這是必需的,因爲 Future::poll 方法接受一個 Context 實例作爲參數,這個實例只能從 Waker 類型構建。
雖然我們可以通過提供 RawWaker 類型的實現來做到這一點,但通過實現基於 Arc 的 Wake trait 並使用標准庫提供的 From 實現來構建 Waker 來說,這既更簡單又更安全。
這個 trait 實現看起來像這樣:
// in src/task/executor.rs
use alloc::task::Wake;
impl Wake for TaskWaker {
fn wake(self: Arc<Self>) {
self.wake_task();
}
fn wake_by_ref(self: &Arc<Self>) {
self.wake_task();
}
}
由於喚醒器通常在執行器和異步任務之間共享,這個 trait 的方法要求 Self 實例被包裝在 Arc 類型中,Arc 實現了引用計數所有權。
這意味着我們必須將我們的 TaskWaker 移動到一個 Arc 中才能調用它們。
在 wake 和 wake_by_ref 方法之間的區別是,後者只需要一個對 Arc 的引用,而前者需要對 Arc 的所有權,因此通常需要增加引用計數。
並不是所有的類型都支持通過引用喚醒,所以實現 wake_by_ref 方法是可選的。
然而,它可以帶來更好的性能,因爲它避免了不必要的引用計數修改。
在我們的情況下,我們可以將這兩個 trait 方法簡單地轉發到我們的 wake_task 函數,這個函數只需要一個共享的 &self 引用。
🔗創建喚醒器 Creating Wakers
既然 Waker 類型支持所有實現了 Wake trait 的 Arc 包裝值的 From 轉換器,
我們現在可以實現 TaskWaker::new 函數,這是我們的 Executor::run_ready_tasks 方法所需要的:
// in src/task/executor.rs
impl TaskWaker {
fn new(task_id: TaskId, task_queue: Arc<ArrayQueue<TaskId>>) -> Waker {
Waker::from(Arc::new(TaskWaker {
task_id,
task_queue,
}))
}
}
We create the TaskWaker using the passed task_id and task_queue. We then wrap the TaskWaker in an Arc and use the Waker::from implementation to convert it to a Waker. This from method takes care of constructing a RawWakerVTable and a RawWaker instance for our TaskWaker type. In case you’re interested in how it works in detail, check out the implementation in the alloc crate.
我們使用傳遞的 task_id 和 task_queue 創建了 TaskWaker。
然後我們將 TaskWaker 包裝在一個 Arc 中,並使用 Waker::from 實現來將它轉換爲一個 Waker。
這個 from 方法負責構建一個 RawWakerVTable 和一個 RawWaker 實例,用於我們的 TaskWaker 類型。
如果你對它的工作細節感興趣,可以查看 alloc crate 中的實現。
🔗A run Method
就着我們的喚醒器實現,我們最終可以爲我們的執行器構建一個 run 方法:
// in src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
}
}
}
這個方法只是在一個循環中調用 run_ready_tasks 函數。雖然我們理論上可以在 tasks map 變爲空時從函數中返回,但這永遠不會發生,因爲我們的 keyboard_task 永遠不會結束,所以一個簡單的 loop 就足夠了。由於這個函數永遠不會返回,我們使用 ! 返回類型來將函數標記爲 diverging 給編譯器。
現在可以將我們的 kernel_main 改爲使用新 Executor 而不是 SimpleExecutor 了:
// in src/main.rs
use blog_os::task::executor::Executor; // new
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] initialization routines, including init_heap, test_main
let mut executor = Executor::new(); // new
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses()));
executor.run();
}
我們只需要改變導入和類型名稱。由於我們的 run 函數被標記爲 diverging,編譯器知道它永遠不會返回,所以我們不再需要在 kernel_main 函數的末尾調用 hlt_loop。
我們用 cargo run 運行我們的內核,現在我們可以看到鍵盤輸入仍然在起作用:

然而,QEMU 的 CPU 利用率並沒有得到改善。這是因爲我們仍然讓 CPU 一直忙碌。
我們不再輪詢任務直到它們再次被喚醒,但我們仍然在一個忙碌的循環中檢查 task_queue。
爲了解決這個問題,我們需要在沒有更多工作要做時讓 CPU 進入睡眠狀態。
🔗空閒時睡眠
基本的思路是,當 task_queue 爲空時執行 [hlt 指令]。這個指令將 CPU 進入睡眠狀態,直到下一個中斷到來。
CPU 在中斷時立即變爲活動狀態的事實確保了當中斷處理程序推送到 task_queue 時我們仍然可以直接做出反應。
爲實現這一點,我們在執行器中創建了一個新的 sleep_if_idle 方法,並從我們的 run 方法中調用它:
// in src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
self.sleep_if_idle(); // new
}
}
fn sleep_if_idle(&self) {
if self.task_queue.is_empty() {
x86_64::instructions::hlt();
}
}
}
由於我們直接在 run_ready_tasks 返回後調用 sleep_if_idle,而 run_ready_tasks 會一直循環直到 task_queue 變爲空,
所以再次檢查隊列可能看起來是不必要的。然而,硬件中斷可能會在 run_ready_tasks 返回後直接發生,
所以在調用 sleep_if_idle 函數時可能已經有一個新的任務在隊列中。只有在隊列仍然爲空時,
我們才通過 x86_64 提供的 instructions::hlt 包裝函數執行 hlt 指令將 CPU 進入睡眠狀態。
不幸的是,這個實現中仍然存在一個微妙的競爭條件。由於中斷是異步的,可以在任何時候發生,所以有可能在 is_empty 檢查和 hlt 調用之間發生中斷:
if self.task_queue.is_empty() {
/// <--- interrupt can happen here
x86_64::instructions::hlt();
}
在這種情況下,如果這個中斷推送到 task_queue,即使現在有一個準備好的任務,我們也會讓 CPU 進入睡眠狀態。
在最壞的情況下,這可能會延遲處理鍵盤中斷,直到下一次按鍵或下一次計時器中斷。那麼,我們如何防止這種情況呢?
答案就是,在檢查之前在 CPU 上禁用中斷,然後在 hlt 指令之後原子地再次啓用它們。
這樣,所有在中間發生的中斷都會在 hlt 指令之後延遲,這樣就不會錯過任何喚醒。
爲了實現這種方法,我們可以使用 x86_64 庫提供的 interrupts::enable_and_hlt 函數。
更新後的 sleep_if_idle 函數的實現如下:
// in src/task/executor.rs
impl Executor {
fn sleep_if_idle(&self) {
use x86_64::instructions::interrupts::{self, enable_and_hlt};
interrupts::disable();
if self.task_queue.is_empty() {
enable_and_hlt();
} else {
interrupts::enable();
}
}
}
爲避免競爭條件,我們在檢查 task_queue 是否爲空之前禁用中斷。
如果爲空,我們使用 enable_and_hlt 函數將中斷啓用並將 CPU 進入睡眠狀態作爲一個單一的原子操作。
如果隊列不再爲空,這意味着一個中斷在 run_ready_tasks 返回後喚醒了一個任務。在這種情況下,我們再次啓用中斷,並直接繼續執行而不執行 hlt。
現在,當沒有任務要執行時,我們的執行器可以正確地讓 CPU 進入睡眠狀態。
我們可以看到,當我們再次使用 cargo run 運行我們的內核時,QEMU 進程的 CPU 利用率大大降低。
🔗可能的擴展
我們的執行器現在能夠以高效的方式運行任務。它利用喚醒器通知來避免輪詢等待的任務,並在當前沒有工作要做時讓 CPU 進入睡眠狀態。然而,我們的執行器仍然相當基本,有許多可能的擴展功能:
-
排程:對於我們的
task_queue,我們目前使用VecDeque類型來實現 先進先出(FIFO)策略,這通常也被稱爲 輪詢 排程。這種策略可能不適用於所有的工作負載。例如,優先考慮優先處理延遲關鍵的任務或執行大量 I/O 的任務。有關更多信息,請參見 Operating Systems: Three Easy Pieces 書籍的 排程章節 scheduling chapter 或 Wikipedia 上的排程文章。 -
任務生成:我們的
Executor::spawn方法目前需要一個&mut self引用,因此在調用run方法後不再可用。爲了解決這個問題,我們可以創建一個額外的Spawner類型,它與執行器共享某種隊列,並允許任務在任務自身內部創建。隊列可以直接是task_queue,也可以是執行器在其運行循環中檢查的一個獨立的隊列。 -
利用線程:我們還沒有支持線程,但我們將在下一篇文章中添加它。這將使得在不同的線程中啟動執行器的多個實例成為可能。這種方法的優點是,由於其他任務可以並行運行,因此可以減少長時間運行任務所帶來的延遲。這種方法還允許它利用多個CPU核心。
-
負載均衡:在添加線程支持時,了解如何在執行器之間分配任務以確保所有 CPU 核心都得到利用,變得很重要。這方面的一個常見技術是 work stealing。
🔗摘要
我們首先介紹了 多任務,並區分了 抢占式 多任務和 協作式 多任務。前者會定期強制中斷正在運行的任務,而後者則讓任務運行,直到它們自願放棄 CPU 控制權。
然後,我們探索了 Rust 對 async/await 的支持,它提供了協作式多任務的語言級實現。Rust 基於 基於輪詢的 Future trait 實現,這個 trait 抽象了異步任務。
使用 async/await,我們可以幾乎像使用普通同步代碼一樣使用 future。
不同之處在於,異步函數再次返回一個 Future,這個 Future 需要在某個時候添加到執行器中才能運行它。
在幕後,編譯器將 async/await 代碼轉換爲 狀態機,其中每個 .await 操作對應於一個可能的暫停點。
通過利用它對程序的了解,編譯器能夠僅保存每個暫停點的最小狀態,從而使每個任務的內存消耗非常小。
一個挑戰是生成的狀態機可能包含 自引用 的結構,例如當異步函數的局部變量相互引用時。
爲了防止指針失效,Rust 使用 Pin 類型來確保 future 在第一次輪詢後不能再在內存中移動。
對於我們的 實現,我們首先創建了一個非常基本的執行器,它在一個忙碌的循環中輪詢所有的任務,而不使用 Waker 類型。
然後,我們通過實現一個異步鍵盤任務來展示喚醒通知的優勢。
這個任務定義了一個靜態變量 SCANCODE_QUEUE,使用 crossbeam 庫提供的無互斥鎖的 ArrayQueue 類型。
現在,鍵盤中斷處理程序不再直接處理按鍵,而是將所有接收到的掃描碼放入隊列,然後喚醒註冊的 Waker 來通知有新的輸入可用了。
在接收端,我們創建了一個 ScancodeStream 類型,它提供了一個 Future,解析隊列中的下一個掃描碼。
這使得我們可以創建一個使用 async/await 來解釋和打印隊列中掃描碼的異步 print_keypresses 任務。
爲了利用鍵盤任務的喚醒通知,我們創建了一個新的 Executor 類型,它使用一個 共享 Arc 的 task_queue 來存儲準備好的任務。
我們實現了一個 TaskWaker 類型,它將被喚醒的任務的 ID 直接推送到這個 task_queue,然後由執行器再次輪詢。
爲了在沒有任務可運行時節省電力,我們添加了使用 hlt 指令將 CPU 進入睡眠狀態的支持。
最後,我們討論了我們的執行器的一些潛在擴展,例如提供多核支持。
🔗下一步要幹嘛?
使用 async/await,我們現在在內核中基本支持了協作式多任務。雖然協作式多任務非常高效,但當單個任務運行時間過長時,會導致延遲問題,從而阻止其他任務運行。 因此,我們的內核也應該添加對抢占式多任務的支持。
下一篇文章中,我們將介紹 線程 作爲最常見的抢占式多任務形式。除了解決長時間運行任務的問題外,線程還將爲我們利用多個 CPU 核心和在將來運行不受信任的用戶程序做準備。
評論
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English and follow Rust's code of conduct. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
請儘可能使用英語評論。