Async/Await
Переведенное содержание: Это перевод сообщества поста Async/Await. Он может быть неполным, устаревшим или содержать ошибки. Пожалуйста, сообщайте о любых проблемах!
Перевод сделан @TakiMoysha.
В этом посте мы рассмотрим кооперативную многозадачность и возможности async/await в Rust. Мы подробно рассмотрим, как async/await работает в Rust, включая трейт Future, переходы в конечных автоматах и закрепления (pinning). Мы добавим базовую поддержку async/await в наше ядро путем создания асинхронных задач обработки ввода с клавиатуры и базовый исполнитель (executor).
Этот блог открыто разрабатывается на GitHub. Если у вас возникают проблемы или вопросы, пожалуйста, откройте issue. Также вы можете оставлять комментарии внизу. Исходный код этого поста можно найти в post-12.
🔗Многозадачность
Одной из основных возможностей операционных систем является многозадачность, то есть возможность одновременного выполнения нескольких задач. Например, вероятно, пока вы читаете этот пост у вас открыты другие программы, вроде текстового редактора или терминала. Даже если у вас открыт только один браузер, в фоновом режиме выполняются различные задачи по управлению окнами рабочего стола, проверке обновлений или индексированию файлов.
Хотя кажется, что все задачи выполняются параллельно, на одном ядре процессора может выполняться только одна задача за раз. Чтобы создать иллюзию параллельного выполнения задач, операционная система быстро переключается между активными задачами, чтобы каждая из них могла совершить небольшой прогресс. Поскольку компьютеры работают быстро, мы в большинстве случаев не замечаем этих переключений.
Одноядерные центральные процессоры (ЦП) могут выполнять только одну задачу за раз, а многоядерные ЦП могут выполнять несколько задач по настоящему параллельно. Например, процессор с 8 ядрами может выполнять 8 задач одновременно. В следующей статье мы расскажем, как использовать многоядерные ЦП . В этой статье, для простоты, мы сосредоточимся на одноядерных процессорах. (Стоит отметить, что все многоядерные ЦП запускаются с одним активным ядром, поэтому пока мы можем рассматривать их как одноядерные процессоры).
Есть две формы многозадачности: кооперативная или совместная (cooperative) - требует, чтобы задачи регулярно отдавали контроль над процессором для продвижения других задач; вытесняющая или приоритетная (preemptive) - использующая функционал операционной системы (ОС) для переключения потоков в произвольные моменты моменты времени через принудительную остановку. Далее мы рассмотрим две формы многозадачности более подробно и обсудим их преимущества и недостатки.
🔗Вытесняющая Многозадачность
При вытесняющей многозадачности за переключение задач отвечает сама ОС. Используется тот факт, что при каждом прерывании ОС восстанавливает контроль над ЦП. Это позволяет переключать задачи всякий раз, когда в системе появляется новый ввод. Например, возможность переключать задачи когда двигается мышка или приходят пакеты по сети. ОС также может определять точное время, в течении которого задаче разрешается выполняться, настроив аппаратный таймер на прерывание по истечению этого времени.
На следующем рисунтке изображен процесс переключения задач при аппаратном прерывании:

На первой строке ЦП выполняет задачу A1 программы A. Все другие задачи приостановлены. На второй строке, наступает аппаратное прерывание. Как описанно в посте Аппаратные Прерывания, ЦП немедленно останавливает выполнение задачи A1 и переходит к обработчику прерываний, определенному в таблице векторов прерываний (Interrupt Descriptor Table, IDT). Благодаря этому обработчику прерываний, ОС снова обладает контролем над ЦП, что позволяет ей переключиться на задачу B1 вместо продолжения задачи A1.
🔗Сохранение состояния
Поскольку задачи прерываются в произвольные моменты времени, они могут находиться в середине вычислений. Чтобы иметь возможность возобновить их позже, ОС должна создать копию всего состояния задачи, включая ее стек вызовов и значения всех регистров ЦП. Этот процесс называется переключение контекста.
Поскольку стек вызовов может быть очень большим, ОС обычно создает отдельный стек вызовов для каждой задачи, вместо того чтобы сохранять содержимое стека вызовов при каждом переключении задач. Такая задача со своим собственным стеком называется поток выполнения или сокращенно поток. Используя отдельный стек для каждой задачи, при переключении контекста необходимо сохранять только содержимое регистров (включая программный счетчик и указатель стека). Такой подход минимизирует накладные расходы на производительность при переключении контекста, что очень важно, поскольку переключения контекста часто происходят до 100 раз в секунду.
🔗Обсуждение
Основным преимуществом вытесняющей многозадачности является то, что операционная система может полностью контролировать время выполнения каждой задачи. Таким образом, ОС может гарантировать, что каждая задача получит справедливую долю времени ЦП, без необходимости полагаться на кооперацию задач. Это особенно важно при выполнении сторонних задач или когда несколько пользователей совместно используют одну систему.
Недостатком вытесняющей многозадачности в том, что каждой задаче требуется собственный стек. По сравнению с общим стеком это приводит к более высокому использованию памяти на задачу и часто ограничивает количество задач в системе. Другим недостатком является то, что ОС всегда должна сохранять полное состояние регистров ЦП при каждом переключении задач, даже если задача использовала только небольшую часть регистров.
Вытесняющая многозадачность и потоки - фундаментальные компоненты ОС, т.к. они позволяют запускать неизвестные программы в userspace . Мы подробнее обсудим эти концепции в будущих постах. Однако сейчас, мы сосредоточимся на кооперативной многозадачности, которая также предоставляет полезные возможности для нашего ядра.
🔗Кооперативная Многозадачность
Вместо принудительной остановки выполняющихся задач в произвольные моменты времени, кооперативная многозадачность позволяет каждой задаче выполняться до тех пор, пока она добровольно не уступит контроль над ЦП. Это позволяет задачам самостоятельно приостанавливаться в удобные моменты времени, например, когда им нужно ждать операции ввода-вывода.
Кооперативная многозадачность часто используется на языковом уровне, например в виде сопрограмм (coroutines) или async/await. Идея в том, что программист или компилятор вставляет в программу операции yield, которые отказываются от управления ЦП и позволяют выполняться другим задачам. Например, yield может быть вставлен после каждой итерации сложного цикла.
Часто кооперативную многозадачность совмещают с асинхронными операциями. Вместо того чтобы ждать завершения операции и препятствовать выполнению других задач, асинхронные операции возвращают статус «не готов», если операция еще не завершена. В этом случае ожидающая задача может выполнить операцию yield, чтобы другие можно было переключиться на другие задачи.
🔗Сохранение состояния
Поскольку задачи сами определяют точки паузы, им не нужно, чтобы ОС сохраняла их состояние. Вместо этого они могут сохранять только то, что необходимо для продолжения работы и это часто приводит к улучшению производительности. Например, задача которая только что завершила сложные вычисления, может требоваться только резервное копирование конечного результата, т.к. промежуточные ей больше не нужны.
Поддерживаемые языком кооперативная многозадачность часто может сохранять только необходимые зачти стека вызовов перед паузой. Например, реализация async/await в Rust сохраняет все локальные переменные, которые еще нужны, в автоматически сгенерированной структуре (см. ниже). Благодаря резервному копированию соответствующих частей стека вызовов перед паузой, все задачи могут использовать один стек, что приводит к значительному снижению потребления памяти на задачу. Это позволяет создавать практически любое количество кооперативных задач без исчерпания памяти.
🔗Обсуждение
Недостатком кооперативной многозадачности является то, что некооперативная задача может потенциально выполняться в течение неограниченного времени. Таким образом, вредоносная или содержащая ошибки задача может помешать выполнению других задач, замедлить или даже заблокировать работу всей системы. По этой причине кооперативная многозадачность должна использоваться только в том случае если известно, что все задачи умеют кооперироваться. Как контрпример, не стоит полагаться на взаимодействие произвольных программ пользовательского пространства (user-level) в ОС.
Однако высокая производительность и преимущества кооперативной многозадачности в плане памяти делают ее хорошим подходом для использования внутри программы, особенно в сочетании с асинхронными операциями. Поскольку ядро операционной системы является программой, критичной с точки зрения производительности, которая взаимодействует с асинхронным оборудованием, кооперативная многозадачность кажется хорошим подходом для реализации параллелизма.
🔗Async/Await в Rust
Rust предоставляет отличную поддержку кооперативной многозадачности в виде async/await. Прежде чем мы сможем изучить, что такое async/await и как оно работает, нам необходимо понять, как работают futures (футуры) и асинхронное программирование в Rust.
🔗Futures
Future представляет значение, которое может быть еще недоступно. Например, это может быть целое число, вычисляемое другой задачей или файл, загружаемый из сети. Вместо того, чтобы ждать, пока значение станет доступным, futures позволяют продолжить выполнение до тех пор, пока значение не понадобится.
🔗Пример
Концепцию футур лучше всего проиллюстрировать небольшим примером:

Эта диаграмма последовательности показывает функцию main, которая читает файл из файловой системы, а затем вызывает функцию foo. Этот процесс повторяется дважды: один раз с синхронным вызовом read_file и один раз с асинхронным вызовом async_read_file.
При вызове синхронной функции main мы должны ждать, пока файл не будет загружен из файловой системы. Только после этого мы сможем вызвать функцию foo и завершения которой тоже будем ждать.
При асинхронном вызове async_read_file файловая система напрямую возвращает футуру и загружает файл асинхронно в фоновом режиме. Это позволяет функции main вызвать foo гораздо раньше, которая затем выполняется параллельно с загрузкой файла. В этом примере загрузка файла заканчивается даже до завершения foo, поэтому main может напрямую работать с файлом без ожидания пока foo вернет результат.
🔗Futures в Rust
В Rust, futures представленны трейтом Future, который выглядит примерно так:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>;
}
Ассоциированный тип Output определяет тип асинхронного значения. Например, функция async_read_file на приведенной выше диаграмме вернет экземпляр Future с Output, установленным как File.
Метод poll позволяет проверить, доступно ли значение. Он возвращает enum Poll:
pub enum Poll<T> {
Ready(T),
Pending,
}
Когда значение доступно (например, файл был полностью прочитан с диска), результат возвращается обернутый в Ready. В ином случае возвращается Pending, который сигнализирует, что значение еще не доступно.
Метод poll принимает два аргумента: self: Pin<&mut Self> и cx: &mut Context. Первый аргумент ведет себя аналогично ссылке &mut self, за исключением того, что значение Self закрепленно (pinned) к месту в памяти. Понять концепцию закрепления (Pin) и его необходимость сложно, если не понимать как работает async/await. Поэтому мы объясним это позже в этом посте.
Параметр cx: &mut Context нужен для передачи экземпляра Waker в асинхронную задачу, например, загрузку файловой системы. Этот Waker позволяет асинхронной задаче сообщать о том, что она (или ее часть) завершена, например, что файл был загружен с диска. Поскольку основная задача знает, что она будет уведомлена, когда Future будет готов, ей не нужно повторно вызывать poll. Мы объясним этот процесс более подробно позже в этом посте, когда будем реализовывать наш собственный тип waker.
🔗Работа с Futures
Теперь мы знаем, как определяются футуры, и понимаем основную идею метода poll. Однако мы все еще не знаем, как эффективно работать с футурами. Проблема в том, что они представляют собой результаты асинхронных задач, которые могут быть еще недоступны. Однако на практике нам часто нужны эти значения непосредственно для дальнейших вычислений. Поэтому возникает вопрос: как мы можем эффективно получить значение, когда оно нам нужно?
🔗Ожидание Futures
Один из возможных ответов — дождаться пока футура исполнится. Это может выглядеть примерно так:
let future = async_read_file("foo.txt");
let file_content = loop {
match future.poll(…) {
Poll::Ready(value) => break value,
Poll::Pending => {}, // ничего не делать
}
}
Здесь мы активно ждем футуру, вызывая poll снова и снова в цикле. Аргументы poll опущены, т.к. здесь они не имеют значения. Хотя это решение работает, оно очень неэффективно, потому что мы занимаем CPU до тех пор, пока значение не станет доступным.
Более эффективным подходом может быть блокировка текущего потока до тех пор, пока футура не станет доступной. Конечно, это возможно только при наличии потоков, поэтому это решение не работает для нашего ядра, по крайней мере, пока. Даже в системах, где поддерживается блокировка, она часто нежелательна, поскольку превращает асинхронную задачу в синхронную, тем самым сдерживая потенциальные преимущества параллельных задач в плане производительности.
🔗Комбинаторы Future
Альтернативой ожиданию является использование комбинаторов футур. Комбинаторы future - это методы вроде map, которые позволяют объединять и связывать футуры между собой, аналогично методам трейта Iterator. Вместо того чтобы ожидать футуры, комбинатор сам возвращает футуру, которая будте применяет операцию сопоставления при вызове poll.
Например, простой комбинатор string_len для преобразования Future<Output = String> в Future<Output = usize> может выглядеть так:
struct StringLen<F> {
inner_future: F,
}
impl<F> Future for StringLen<F> where F: Future<Output = String> {
type Output = usize;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
match self.inner_future.poll(cx) {
Poll::Ready(s) => Poll::Ready(s.len()),
Poll::Pending => Poll::Pending,
}
}
}
fn string_len(string: impl Future<Output = String>)
-> impl Future<Output = usize>
{
StringLen {
inner_future: string,
}
}
// применение
fn file_len() -> impl Future<Output = usize> {
let file_content_future = async_read_file("foo.txt");
string_len(file_content_future)
}
Этот код не совсем корректен, потому что не учитывает закрепление, но он подходит для примера. Суть в том, что функция string_len оборачивает переданный экземпляр Future в новую структуру StringLen, которая также реализует Future. При опросе футуры-обертки опрашивается внутренняя футура. Если значение ещё не готово, из футуры-обертки возвращается Poll::Pending. Если значение готово, строка извлекается из Poll::Ready, вычисляется её длина, после чего результат снова оборачивается в Poll::Ready и возвращается.
С помощью функции string_len можно вычислить длину асинхронной строки, не дожидаясь её завершения. Поскольку функция снова возвращает Future, вызывающий код не может работать с возвращённым значением напрямую, а должен использовать комбинаторы. Таким образом, весь граф вызовов становится асинхронным, и в какой-то момент (например, в основной функции) можно эффективно ожидать завершения нескольких футур одновременно.
Так как ручное написание функций-комбинаторов сложно, они обычно предоставляются библиотеками. Стандартная библиотека Rust пока не содержит методов-комбинаторов, но полуофициальная (и совместимая с no_std) библиотека futures предоставляет их. Её трейт FutureExt включает высокоуровневые методы-комбинаторы, такие как map или then, которые позволяют манипулировать результатом с помощью произвольных замыканий.
🔗Преимущества
Большое преимущество комбинаторов футур (future combinators) в том, что они сохраняют асинхронность. В сочетании с асинхронными интерфейсами ввода-вывода такой подход может обеспечить очень высокую производительность. То, что future комбинаторы реализованы как обычные структуры с имплементацией трейтов, позволяет компилятору чрезвычайно оптимизировать их. Подробнее см. в посте Zero-cost futures in Rust, где было объявлено о добавлении futures в экосистему Rust.
🔗Недостатки
Хотя комбинаторы футур позволяют писать очень эффективный код, их может быть сложно использовать в некоторых ситуациях из-за системы типов и интерфейса на основе замыканий. Например, рассмотрим такой код:
fn example(min_len: usize) -> impl Future<Output = String> {
async_read_file("foo.txt").then(move |content| {
if content.len() < min_len {
Either::Left(async_read_file("bar.txt").map(|s| content + &s))
} else {
Either::Right(future::ready(content))
}
})
}
Мы читаем файл foo.txt, а затем используем комбинатор then, чтобы связать вторую футуру на основе содержимого файла. Если длина содержимого меньше заданного min_len, мы читаем другой файл bar.txt и добавляем его к content с помощью комбинатора map. В противном случае возвращаем только содержимое foo.txt.
Нам нужно использовать ключевое слово [move] для замыкания, передаваемого в then, иначе возникнет ошибка времени жизни (lifetime) для min_len. Причина использования обёртки Either в том, что блоки if и else всегда должны возвращать значения одного типа. Поскольку возвращаются разные типы футур в блоке, нам необходимо использовать тип-обертку, чтобы привести их к единому типу. Функция ready оборачивает значение в футуру, которая сразу готова к использованию. Здесь она необходима, потому что обёртка Either ожидает, что обёрнутое значение реализует Future.
Как можно догадаться, такой подход быстро приводит к очень сложному коду, особенно в крупных проектах. Ситуация ещё больше усложняется, если задействованы заимствования (borrowing) и разные времена жизни (lifetimes). Именно поэтому в Rust было вложено много усилий для добавления поддержки async/await — с целью сделать написание асинхронного кода радикально проще.
🔗Паттерн Async/Await
Идея async/await заключается в том, чтобы позволить программисту писать код, который выглядит как синхронный код, но компилятор превращает его в асинхронный. Это работает на основе двух ключевых слов async и await. Ключевое слово async можно использовать в сигнатуре функции для превращения синхронной функции в асинхронную, возвращающую future:
async fn foo() -> u32 {
0
}
// примерно переводится компилятором в:
fn foo() -> impl Future<Output = u32> {
future::ready(0)
}
Один async не будет особо полезен. Однако внутри функции мы можем использовать await, чтобы получить асинхронное значение из футуры:
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
Эта функция - прямой перевод example написанной выше, которая использовала комбинаторы. Используя оператор .await, мы можем получить результат из футуры без необходимости использования каких-либо замыканий или типов Either. В результате мы можем писать наш код так же, как если бы это был обычный синхронный код, с той лишь разницей, что это все еще асинхронный код.
🔗Преобразования Конечных Автоматов
За кулисами компилятор преобразует тело функции async в конечный автомат (state machine) с каждым вызовом .await, представляющим собой разное состояние. Для вышеуказанной функции example, компилятор создает конечный автомат с четырьмя состояниями.

Каждое состояние представляет собой точку остановки в функции. Состояния “Start” и “End”, указывают на начало и конец выполнения ф-ции. Состояние “waiting on foo.txt” - функция в данный момент ждёт первого результата async_read_file. Аналогично, состояние “waiting on bar.txt” представляет остановку, когда функция ожидает второй результат async_read_file.
Конечный автомат реализует trait Future делая каждый вызов poll возможным переход между состояниями:

Диаграмма использует стрелки для представления переключений состояний и ромбы для представления альтернативных путей. Например, если файл foo.txt не готов, то мы идем по пути “no” переходя в состояние “waiting on foo.txt”. Иначе, идем по пути “yes”. Где маленький красный ромб без подписи - ветвь функции example, где if content.len() < 100.
Мы видим, что первый вызов poll запускает функцию и она выполняться до тех пор, пока у футуры не будет результата. Если все футуры на пути готовы, функция может выполниться до состояния “end” , то есть вернуть свой результат, завернутый в Poll::Ready. В противном случае конечный автомат переходит в состояние ожидания и возвращает Poll::Pending. При следующем вызове poll машина состояний начинает с последнего состояния ожидания и повторяет последнюю операцию.
🔗Сохранение состояния
Для продолжения работы с последнего состояния ожидания, автомат должен отслеживать текущее состояние внутри себя. Дополнительно, он должен сохранять все переменные, которые необходимы для продолжения выполнения при следующем вызове poll. Здесь компилятор действительно может проявить себя: зная, когда используются те или иные переменные, он может автоматически создавать структуры с точным набором требуемых переменных.
Например, компилятор генерирует структуры для вышеприведенной ф-ции example:
// снова `example` что бы вам не пришлось прокручивать вверх
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
// state-структуры генерируемые компилятором
struct StartState {
min_len: usize,
}
struct WaitingOnFooTxtState {
min_len: usize,
foo_txt_future: impl Future<Output = String>,
}
struct WaitingOnBarTxtState {
content: String,
bar_txt_future: impl Future<Output = String>,
}
struct EndState {}
В состояниях “start” и “waiting on foo.txt” необходимо сохранить параметр min_len для последующего сравнения с content.len(). Состояние “waiting on foo.txt” дополнительно содержит foo_txt_future, представляющий future возвращаемое вызовом async_read_file. Эту футуру нужно опросить снова, когда автомат продолжит свою работу, поэтому его нужно сохранить.
Состояние “waiting on bar.txt” содержит переменную content для последующей конкатенации строк при загрузке файла bar.txt. Оно также хранит bar_txt_future, отвечающая за загрузку файла bar.txt. Эта структура не содержит переменную min_len, потому что она уже не нужна после проверки длины строки content.len(). В состоянии “end”, в структуре ничего нет, т.к. ф-ция завершилась полностью.
Учтите, что приведенный здесь код - это только пример того, какая структура может быть сгенерирована компилятором Имена структур и расположение полей - детали реализации и могут отличаться.
🔗Полный Конечный Автомат
При этом точно сгенерированный код компилятора является деталью реализации, это помогает понять, представив, как могла бы выглядеть машина состояний для функции example. Мы уже определили структуры, представляющие разные состояния и содержащие необходимые переменные. Чтобы создать машину состояний на их основе, мы можем объединить их в enum:
enum ExampleStateMachine {
Start(StartState),
WaitingOnFooTxt(WaitingOnFooTxtState),
WaitingOnBarTxt(WaitingOnBarTxtState),
End(EndState),
}
Мы определяем отдельный вариант enum для каждого состояния и добавляем соответствующую структуру состояния в каждый вариант как поле. Чтобы реализовать переходы между состояниями, компилятор генерирует реализацию трейта Future на основе функции example:
impl Future for ExampleStateMachine {
type Output = String; // возвращает тип из `example`
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output> {
loop {
match self { // TODO: обработка закрепления (pinning)
ExampleStateMachine::Start(state) => {…}
ExampleStateMachine::WaitingOnFooTxt(state) => {…}
ExampleStateMachine::WaitingOnBarTxt(state) => {…}
ExampleStateMachine::End(state) => {…}
}
}
}
}
Тип для Output указан String, потому что этот тип возвращает функция example. Для реализации метода poll мы используем оператор match на текущем состоянии внутри цикла. Идея в том, что мы переходим к следующему состоянию пока это возможно и явно возвращаем Poll::Pending когда мы не можем продолжить.
Для упрощения мы показываем только упрощенный код и не обрабатываем закрепления, владения, варемя жизни, и т.д. Поэтому этот и следующий код должны быть восприняты как псевдокод и не использоваться напрямую. Конечно, реальный генерируемый компилятором код обрабатывает корректно, хотя возможно это будет сделано по-другому.
Чтобы сохранить примеры кода маленькими, мы напишем код для каждой ветки match отдельно. Начнем с состояния Start:
ExampleStateMachine::Start(state) => {
// из тела `example`
let foo_txt_future = async_read_file("foo.txt");
// операция`.await`
let state = WaitingOnFooTxtState {
min_len: state.min_len,
foo_txt_future,
};
*self = ExampleStateMachine::WaitingOnFooTxt(state);
}
Автомат находится в состоянии Start, когда ф-ция только начинает выполнение. В этом случае выполняем весь код из тела функции example до первого .await. Чтобы обработать операцию .await, мы меняем состояние на WaitingOnFooTxt, которое включает в себя построение структуры WaitingOnFooTxtState.
Пока match self {…} выполняется в цикле, выполнение переходит к ветке WaitingOnFooTxt:
ExampleStateMachine::WaitingOnFooTxt(state) => {
match state.foo_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(content) => {
// из тела `example`
if content.len() < state.min_len {
let bar_txt_future = async_read_file("bar.txt");
// операция `.await`
let state = WaitingOnBarTxtState {
content,
bar_txt_future,
};
*self = ExampleStateMachine::WaitingOnBarTxt(state);
} else {
*self = ExampleStateMachine::End(EndState);
return Poll::Ready(content);
}
}
}
}
Эта ветка match начинается с вызова poll для foo_txt_future. Если она не готова, мы выходим из цикла и возвращаем Poll::Pending. В этом случае self остается в состоянии WaitingOnFooTxt, следующий вызов poll на автомате попадёт в ту же ветку match и повторит проверку готовности foo_txt_future.
Когда foo_txt_future будет готов, мы присваиваем результат переменной content и продолжаем выполнять код функции example: Если content.len() меньше чем min_len сохраненной в state-структуре, асинхронно читаем файл bar.txt. Мы ещё раз переключаем состояние операцией .await, на этот раз, в состояние WaitingOnBarTxt. Пока мы выполняем match внутри цикла, исполнение переходит к той ветке match, которая проверяет готовность bar_txt_future.
В случае перехода в ветку else, более никаких операций .await не происходит. Мы достигаем конца функции и возвращаем content обёрнутую в Poll::Ready. Также меняем текущее состояние на End.
Код для состояния WaitingOnBarTxt выглядит следующим образом:
ExampleStateMachine::WaitingOnBarTxt(state) => {
match state.bar_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(bar_txt) => {
*self = ExampleStateMachine::End(EndState);
// из тела `example`
return Poll::Ready(state.content + &bar_txt);
}
}
}
Аналогично состоянию WaitingOnFooTxt, мы начинаем с проверки готовности bar_txt_future. Если она ещё не готова, мы выходим из цикла и возвращаем Poll::Pending. В противном случае мы можем выполнить последнюю операцию функции example: конкатенацию переменной content с результатом футуры. Переводим автомат в состояние End и затем возвращаем результат обёрнутый в Poll::Ready.
В итоге код для End состояния выглядит так:
ExampleStateMachine::End(_) => {
panic!("poll вызван после возврата Poll::Ready");
}
Футуры не должны повторно проверяться после того, как они вернули Poll::Ready, поэтому паникуем, если вызвана функция poll при состоянии End.
Теперь мы знаем, что сгенерированный компилятором конечный автомат и его реализация трейта Future могла бы выглядеть так. На практике компилятор генерирует код по-другому. (Если вас интересно, то реализация ныне основана на корутинах, но это только деталь имплементации.)
Последняя часть пазла – сгенерированный код для самой функции example. Помните, что заголовок функции был определён следующим образом:
async fn example(min_len: usize) -> String
Теперь, когда весь функционал реализуется конечным автоматом, единственное, что ф-ция должна сделать - это инициализировать этот автомат и вернуть его. Сгенерированный код может выглядеть так:
fn example(min_len: usize) -> ExampleStateMachine {
ExampleStateMachine::Start(StartState {
min_len,
})
}
Функция больше не имеет модификатора async, поскольку теперь явно возвращает тип ExampleStateMachine, который реализует трейт Future. Как ожидалось, автомат создается в состоянии start и соответствующая ему структура состояния инициализируется параметром min_len.
Заметьте, что эта функция не запускает автомат. Это фундаментальное архитектурное решение для футур в Rust: они ничего не делают, пока не будет произведена первая проверка на готовность.
🔗Закрепление
Мы уже несколько раз столкнулись с понятием закрепления (pinnig, пиннинг) в этом посте. Наконец пришло время чтобы изучить что это такое и почему оно необходимо.
🔗Самоссылающиеся структуры
Как объяснялось выше, переходы хранял структуру с локальными перемеными для каждой паузы . Для простых примеров, как наша функция example, это было просто и не привело к никаким проблемам. Однако, дела обстоят сложнее, когда переменные ссылаются друг на друга. Рассмотрим код:
async fn pin_example() -> i32 {
let array = [1, 2, 3];
let element = &array[2];
async_write_file("foo.txt", element.to_string()).await;
*element
}
Эта функция создает небольшой array содержащий 1, 2, 3. Затем она создает ссылку на последний элемент массива и хранит ее в переменной element. Далее, асинхронно записывает число, преобразованное в строку, в файл foo.txt. В конце, возвращает число, ссылка на которое хранится в element.
Так как ф-ция использует одну операцию await, конечный автомат будет состоять из трех состояний: start, end и “waiting on write”. Функция не принимает аргументов, поэтому структура для “start” пуста. Аналогично, структура для “end” также пустая, поскольку функция завершена на этом этапе. Нам интересна структура “waiting on write”:
struct WaitingOnWriteState {
array: [1, 2, 3],
element: 0x1001c, // адрес последнего элемента в array
}
Мы должны хранить и array, и element, потому что element требуется для значения возврата, а array ссылается на element. Следовательно, element является указателем (pointer) (адресом в памяти), который хранит адрес ссылаемого элемента. В этом примере мы использовали 0x1001c в качестве адреса, в реальности он должен быть адресом последнего элемента поля array, что зависит от места расположения структуры в памяти. Структуры с такими внутренними указателями называются самоссылочными (self-referential) структурами, потому что они ссылаются на себя из одного из своих полей.
🔗Проблемы с Самоссылочными Структурами
Внутренний указатель нашей самоссылочной структуры приводит к базовой проблеме, которая становится очевидной, когда мы посмотрим на её раскладку памяти:

Поле array начинается в адресе 0x10014, а поле element - в адресе 0x10020. Оно указывает на адрес 0x1001c, потому что последний элемент массива находится там. На текущий момент все в порядке. Однако проблема возникает когда мы перемещаем эту структуру на другой адрес памяти:

Мы переместили структуру немного так, чтобы она теперь начиналась в адресе 0x10024. Это могло произойти, например, когда мы передаем структуру как аргумент функции или присваиваем ее другой переменной на стеке. Проблема заключается в том, что поле element все ещё указывает на адрес 0x1001c, хотя последний элемент массива теперь находится в адресе 0x1002c. Теперь это висячий указатель, то есть он указывает на недопустимый объект и при следующий вызове poll будет ошибка undefined behavior.
🔗Возможные решения
Существует три основных подхода к решению проблемы висящих указателей (dangling pointers):
-
Обновление указателя при перемещении: Суть в обновлении внутреннего указателя при каждом перемещении структуры в памяти, чтобы она оставалась действительной после перемещения. Однако этот подход требует значительных изменений в Rust, которые могут привести к потенциальным значительным потерям производительности. Причина в том, что необходимо каким-то образом отслеживать тип всех полей структуры и проверять на каждой операции перемещения требуется ли обновление указателя.
-
Хранение смещения (offset) вместо самоссылающихся ссылок: Чтобы избежать необходимости обновления указателей, компилятор мог бы попытаться хранить саммоссылки в форме смещений от начала структуры вместо прямых ссылок. Например, поле
elementвышеупомянутойWaitingOnWriteStateструктуры можно было бы хранить в виде поляelement_offsetc значением 8, потому что элемент массива, на который указывает ссылка, находится за 8 байтов после начала структуры. Смещение остается неизменным при перемещении структуры, так что не требуются обновления полей.Проблема с этим подходом в том, что он требует от компилятора обнаружения всех самоссылок. Это невозможно на этапе компилящии, т.к. значения ссылки может зависеть от ввода пользователя, так что нам потребуется система анализа ссылок и корректная генерация состояния для структур во время исполнения. Это накладывает расходы на время выполнения и предотвратит определённые оптимизации компилятора, что приведёт к еще большим потерям производительности.
-
Запретить перемещать структуру: Мы увидели выше, что висящий указатель возникает только при перемещении структуры в памяти. Запретив все операции перемещения для самоссылающихся структур, можно избежать этой проблемы. Большое преимущество том, что это можно реализовать на уровне системы типов без расходов к времени исполнения. Недостаток в том, что оно возлагает на программиста обязанности по обработке перемещений самоссылающихся структур.
Rust выбрал третий подход из-за принципа предоставления бесплатных абстракций (zero-cost abstractions), что означает, что абстракции не должны накладывать дополнительные расходы на временя исполнения. API pinning предлагалось для решения этой проблемы в RFC 2349. В следующем разделе мы дадим краткий обзор этого API и объясним, как оно работает с async/await и futures.
🔗Значения в Куче (Heap)
Первое наблюдение состоит в том, что значения аллоцированные в куче, обычно имеют фиксированный адрес памяти. Они создаются с помощью вызова allocate и затем ссылаются на тип указателя, такой как Box<T>. Хотя перемещение типа-указателя возможно, значение кучи, которое указывает на него, остается в том же адресе памяти до тех пор, пока оно не будет освобождено с помощью вызова deallocate еще раз.
При аллокации в куче, можно попытаться создать самоссылающуюся структуру:
fn main() {
let mut heap_value = Box::new(SelfReferential {
self_ptr: 0 as *const _,
});
let ptr = &*heap_value as *const SelfReferential;
heap_value.self_ptr = ptr;
println!("heap value at: {:p}", heap_value);
println!("internal reference: {:p}", heap_value.self_ptr);
}
struct SelfReferential {
self_ptr: *const Self,
}
Мы создаем простую структуру с названием SelfReferential, которая содержит только одно поле с указателем. Во-первых, мы инициализируем эту структуру с пустым указателем и затем выделяем место в куче с помощью Box::new. Затем мы определяем адрес кучи для выделенной структуры и храним его в переменной ptr. В конце концов, мы делаем структуру самоссылающейся, назначив переменную ptr полю self_ptr.
Когда мы запускаем этот код в песочнице, мы видим, что адрес на куче и внутренний указатель равны, что означает, что поле self_ptr валидное. Поскольку переменная heap_value является только указателем, перемещение его (например, передачей в функцию) не изменяет адрес самой структуры, поэтому self_ptr остается действительным даже при перемещении указателя.
Тем не менее все еще есть путь сломать этот пример: мы можем выйти из Box<T> или изменить содержимое:
let stack_value = mem::replace(&mut *heap_value, SelfReferential {
self_ptr: 0 as *const _,
});
println!("value at: {:p}", &stack_value);
println!("internal reference: {:p}", stack_value.self_ptr);
Мы используем функцию mem::replace, чтобы заменить значение, выделенное в куче, новым экземпляром структуры. Это позволяет нам переместить исходное значение heap_value в стек, в то время как поле self_ptr структуры теперь является висящим указателем, который по-прежнему указывает на старый адрес в куче. Когда вы запустите пример в песочнице, вы увидите, что строки «value at:» и «internal reference:», показывают разные указатели. Таким образом, выделение значения в куче недостаточно для обеспечения безопасности самоссылок.
Основная проблема, которая привела к вышеуказанной ошибке в том, что Box<T> позволяет нам получить ссылку &mut T на значение, которое выделенно в куче. При этом ссылка &mut позволяет использовать такие методы, как mem::replace или mem::swap, который сделаеют значение на куче невалидным. Чтобы решить эту проблему, мы должны предотвратить создание ссылок &mut на самоссылающиеся структуры.
🔗Pin<Box<T>> и Unpin
API закрепления предоставляет решение проблемы &mut T в виде типа-обертки Pin и трейта-маркера Unpin. Идея их использования в том, что бы ограничить все методы Pin, которые могут быть использованы для получения ссылок &mut на обернутое значение (например, get_mut или deref_mut), на трейт Unpin. Трейт Unpin является автоматическим трейтом (auto trait), то есть автоматически реализуется для всех типов, кроме тех, которые явно исключают его. Исключая Unpin в самоссылающихся структурах, не остается (безопасного) способа) получить &mut T из типа Ping<Box<T>> для них. В результате их внутренние самоссылки гарантированно остаются действительными.
Как пример обновим тип SelfReferential из примера выше, что бы отказаться от Unpin:
use core::marker::PhantomPinned;
struct SelfReferential {
self_ptr: *const Self,
_pin: PhantomPinned,
}
Мы отказываемся от Unpin, добавляя второе поле _pin типа PhantomPinned. Этот тип является маркерным типом нулевого размера, единственной целью которого является отказ от реализации трейта Unpin. Из-за того как работают [автоматические трейты], одного поля, которое не является Unpin, достаточно, чтобы полностью исключить реализацию Unpin для структуры.
Второй шаг — изменить тип Box<SelfReferential> в примере на Pin<Box<SelfReferential>>. Самый простой способ сделать это — использовать функцию Box::pin вместо Box::new для создания значения, размещаемого в куче:
let mut heap_value = Box::pin(SelfReferential {
self_ptr: 0 as *const _,
_pin: PhantomPinned,
});
В дополнение к изменению Box::new на Box::pin, нам также нужно добавить новое поле _pin в инициализатор структуры. Т.к. PhantomPinned является типом нулевого размера, нам нужно только его имя типа для инициализации.
Если мы попробуем запустить наш пример после правки, то увидим, что он больше на работает:
error[E0594]: cannot assign to data in dereference of `Pin<Box<SelfReferential>>`
--> src/main.rs:10:5
|
10 | heap_value.self_ptr = ptr;
| ^^^^^^^^^^^^^^^^^^^^^^^^^ cannot assign
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `std::pin::Pin<std::boxed::Box<SelfReferential>>`
error[E0596]: cannot borrow data in dereference of `Pin<Box<SelfReferential>>` as mutable
--> src/main.rs:16:36
|
16 | let stack_value = mem::replace(&mut *heap_value, SelfReferential {
| ^^^^^^^^^^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
Обе ошибки возникают потому, что тип Pin<Box<SelfReferential>> больше не реализует трейт DerefMut. Это именно то, чего мы и хотели, поскольку трейт DerefMut возвращал бы ссылку &mut, что мы предотвратить. Это происходит только потому, что мы отказались от Unpin и изменили Box::new на Box::pin.
Теперь проблема в том, что компилятор не только предотвращает перемещение типа в строке 16, но и запрещает инициализацию поля self_ptr в строке 10. Компилятор не может различить допустимые и недопустимые использования ссылок &mut. Чтобы инициализация снова заработала, нам нужно использовать небезопасный метод get_unchecked_mut:
// безопасно, т.к. изменение поля не перемещает всю структуру
unsafe {
let mut_ref = Pin::as_mut(&mut heap_value);
Pin::get_unchecked_mut(mut_ref).self_ptr = ptr;
}
Функция get_unchecked_mut работает с Pin<&mut T> вместо Pin<Box<T>>, поэтому нам нужно использовать Pin::as_mut для преобразования значения. Затем мы можем установить поле self_ptr, используя ссылку &mut, возвращаемую get_unchecked_mut.
Теперь единственной оставшейся ошибкой является желаемая ошибка на mem::replace. Помните, что эта операция пытается переместить значение из кучи на стек, что нарушило бы самоссылку, хранящуюся в поле self_ptr. Отказываясь от Unpin и используя Pin<Box<T>>, мы можем предотвратить эту операцию на этапе компиляции и безопасно работать с самоссыльными структурами. Как мы видели, компилятор не может доказать, что создание самоссылки безопасно (пока), поэтому нам нужно использовать небезопасный блок и самостоятельно проверить корректность.
🔗Закрепление в стеке и Pin<&mut T>
В предыдущем разделе мы узнали, как использовать Pin<Box<T>> для безопасного создания самоссыльного значения в куче. Хотя этот подход работает хорошо и относительно безопасен (кроме unsafe), необходимость аллокация в куче бьет по производительности. Поскольку Rust стремится предоставлять абстракции с нулевой стоимостью (zero-cost abstractions) где это возможно, API закрепления также позволяет создавать экземпляры Pin<&mut T>, которые указывают на значения, размещённые в стеке.
В отличие от экземпляров Pin<Box<T>>, которые владеют обёрнутым значением, экземпляры Pin<&mut T> лишь временно заимствуют это значение значение. Это усложняет задачу, так как программисту необходимо самостоятельно обеспечивать дополнительные гарантии. Pin<&mut T> должен оставаться закрепленным на протяжении всего жизненного цилка ссылочного T, что может быть сложно обеспечить для переменных на стеке. Чтобы помочь с этим, существуют такие крейты, как pin-utils, но я все же не рекомендую закреплять на стеке, если вы не уверены в своих действиях.
Что бы узнать большое обратитесь к документации модуля pin и метода Pin::new_unchecked.
🔗Закрепление и Футуры
Как мы уже увидели в этом посте, метод Future::poll использует закрепление в виде параметра Pin<&mut Self>:
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>
Причина, по которой этот метод принимает self: Pin<&mut Self> вместо обычного &mut self в том, что экземпляры футур, созданные через async/await, часто являются самоссыльными, как мы видели выше. Оборачивая Self в Pin и позволяя компилятору исключить Unpin для самоссыльных футур, генерируемых из async/await, мы гарантируем, что футуры не будут перемещаться в памяти между вызовами poll. Это обеспечивает сохранение валидности всех внутренних ссылок.
Стоит отметить, что перемещение футур до первого вызова poll допустимо. Как упоминалось выше, футуры ленивые и ничего не делают, пока их не опросят (polled) в первый раз. Состояние start сгенерированных автоматов, следовательно, содержит только аргументы функции, но не внутренние ссылки. Чтобы вызвать poll, вызывающему необходимо сначала обернуть футуру в Pin, что гарантирует, что футура больше не может быть перемещена в памяти. Поскольку закрепление на стеке (stack pining) сложнее сделать правильно, я рекомендую всегда использовать Box::pin в сочетании с Pin::as_mut для этого.
Если вас интересует, как безопасно реализовать комбинатора футур с использованием закрепления на стеке, взгляните на относительно короткий исходный код метода комбинатора map из крейта futures и раздел о projections and structural pinning в документации pin.
🔗Executors и Wakers
Используя async/await, можно удобно работать с футурами в полностью асинхронном режиме. Однако, как мы узнали выше, футуры ничего не делают, пока их не спросят. Это означает, что нам нужно в какой-то момент вызвать poll, иначе асинхронный код никогда не будет выполнен.
Запуская одну футуры, мы можем вручную ожидать ее исполнения в цикле, как упоминалось выше. Однако этот подход очень неэффективен и непрактичен для программ, создающих большое количество футур. Наиболее распространённым решением этого является создание глобального исполнителя (executor), который отвечает за опрос (polling) всех футур в системе, пока они не завершатся.
🔗Исполнитель
Цель исполнителя в том, чтобы позволить создавать футуры в качестве независимых задач, обычно через какой-либо метод spawn. Исполнитель отвечает за опрос всех футур, пока они не закончаться. Большое преимущество управления всеми футурами в одном месте в том, что исполнитель может переключаться на другую футуру, когда текущая футура возвращает Poll::Pending. Таким образом, асинхронные операции выполняются параллельно, и процессор остаётся загруженным.
Многие реализации исполнителей также могут использовать преимущества систем с многоядерными процессорами. Они создают пул потоков, способный использовать все ядра, если достаточно работы, и применяют такие техники, как work stealing, для балансировки нагрузки между ядрами. Существуют также специальные реализации исполнителей для встроенных систем, которые оптимизируют низкую задержку и затраты памяти.
Чтобы избежать накладных расходов на повторный опрос футур, исполнители обычно используют API waker, поддерживаемый футурами Rust.
🔗Wakers
Идея API waker в том, что специальный тип Waker передаётся при каждом вызове poll, при этом обернутый в тип Context. Этот тип Waker создаётся исполнителем и может использоваться асинхронной задачей для сигнализации о своём (частичном) завершении. В результате исполнитель не должен вызывать poll на футуре, которая ранее вернула Poll::Pending, пока не получит уведомление от соответствующего waker.
Лучше всего иллюстрируется небольшим примером:
async fn write_file() {
async_write_file("foo.txt", "Hello").await;
}
Эта функция асинхронно записывает строку “Hello” в файл foo.txt. Поскольку запись на жёсткий диск занимает некоторое время, первый вызов poll на этой футуре, вероятно, вернёт Poll::Pending. Однако драйвер жёсткого диска внутри будет хранить Waker, переданный в вызов poll, и использовать его для уведомления исполнителя, когда файл будет записан на диск. Таким образом, исполнитель не тратит время на poll футуры, пока не получит уведомление от waker.
Мы увидим, как работает тип Waker в деталях, когда создадим свой собственный исполнитель с поддержкой waker в разделе реализации этого поста.
🔗Кооперативная Многозадачности?
В начале этого поста мы говорили о вытесняющей (preemptive) и кооперативной (cooperative) многозадачности. В то время как вытесняющая многозадачность полагается на операционную систему для принудительного переключения между выполняемыми задачами, кооперативная многозадачность требует, чтобы задачи добровольно уступали контроль над CPU через операцию yield на регулярной основе. Большое преимущество кооперативного подхода в том, что задачи могут сохранять своё состояние самостоятельно, что приводит к более эффективным переключениям контекста и делает возможным совместное использование одного и того же стека вызовов между задачами.
Это может не быть сразу очевидным, но футуры и async/await представляют собой реализацию кооперативного паттерна многозадачности:
- Каждая футура, добавленная в исполнителя, по сути является кооперативной задачей.
- Вместо использования явной операции yield, футуры уступают контроль над ядром CPU, возвращая
Poll::Pending(илиPoll::Readyв конце).- Нет ничего, что заставляло бы футуру уступать ЦПУ. Если они захотят, они могут никогда не возвращать ответ на
poll, например, бесконечно выполняя цикл. - Поскольку каждая футура может блокировать выполнение других футур в исполнителе, нам нужно доверять им, чтобы они не были вредоносными (malicious).
- Нет ничего, что заставляло бы футуру уступать ЦПУ. Если они захотят, они могут никогда не возвращать ответ на
- Футуры хранят состояние внутри, которое необходимо для продолжения исполнении при следующем вызове
poll. При использовании async/await компилятор автоматически определяет все переменные, которые необходимы, и сохраняет их внутри сгенерированной машины состояний.- Сохраняется только минимально необходимое состояние для продолжения.
- Поскольку метод
pollотдает стек вызовов при возврате, тот же стек может использоваться для опроса других футур.
Мы видим, что футуры и async/await идеально соответствуют паттерну кооперативной многозадачности; они просто используют другую терминологию. В дальнейшем мы будем использовать термины “задача” и “футура” взаимозаменяемо.
🔗Реализация
Теперь, когда мы понимаем, как работает кооперативная многозадачность на основе футур и async/await в Rust, пора добавить поддержку этого в наше ядро. Поскольку трейт Future является частью библиотеки core, а async/await — это особенность самого языка, нам не нужно делать ничего особенного, чтобы использовать его в нашем #![no_std] ядре. Единственное условие - версия rust, как минимум, nightly от 2020-03-25, поскольку до этого времени async/await не поддерживала no_std.
С достаточно свежей nightly версией мы можем начать использовать async/await в нашем main.rs:
// src/main.rs
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
Здесь async_number является async fn, поэтому компилятор преобразует её в машину состояний, реализующую Future. Поскольку функция возвращает только 42, результирующая футура непосредственно вернёт Poll::Ready(42) при первом вызове poll. Как и async_number, функция example_task также является async fn. Она ожидает число, возвращаемое async_number, а затем выводит его с помощью макроса println.
Чтобы запустить футуру, которую вернул example_task, нам нужно вызывать poll на ней, пока он не сигнализирует о своём завершении, возвращая Poll::Ready. Для этого нам нужно создать простой тип исполнителя.
🔗Задачи (Таски)
Перед тем как начать реализацию исполнителя, мы создаем новый модуль task с типом Task:
// src/lib.rs
pub mod task;
// src/task/mod.rs
use core::{future::Future, pin::Pin};
use alloc::boxed::Box;
pub struct Task {
future: Pin<Box<dyn Future<Output = ()>>>,
}
Структура Task является обёрткой вокруг закрепленной, размещённой в куче и динамически диспетчерезуемой футуры с пустым типом () в качестве выходного значения. Разберём её подробнее:
- Мы требуем, чтобы футура, связанная с задачей, возвращала
(). Это означает, что задачи не возвращают никаких результатов, они просто выполняются для побочных эффектов. Например, функцияexample_task, которую мы определили выше, не имеет возвращаемого значения, но выводит что-то на экран как побочный эффект (side effect). - Ключевое слово
dynуказывает на то, что мы храним trait object вBox. Это означает, что методы на футуре диспетчеризуются динамически, позволяя хранить в типеTaskразные типы футур. Это важно, поскольку каждаяasync fnимеет свой собственный тип, и мы хотим иметь возможность создавать несколько разных задач. - Как мы узнали в разделе о закреплении, тип
Pin<Box>обеспечивает, что значение не может быть перемещено в памяти, помещая его в кучу и предотвращая создание&mutссылок на него. Это важно, потому что футуры, генерируемые async/await, могут быть самоссылающимися, т.е. содержать указатели на себя, которые станут недействительными, если футура будет перемещена.
Чтобы разрешить создание новых структур Task из футур, мы создаём функцию new:
// src/task/mod.rs
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
future: Box::pin(future),
}
}
}
Функция принимает произвольную футуру с выходным типом () и закрепляет его в памяти через Box::pin. Затем она оборачивает упакованную футуру в структуру Task и возвращает ее. Здесь нужно время жизни 'static, т.к. возвращаемый Task может жить произвольное время, следовательно, футура также должна быть действительной в течение этого времени.
Мы также добавляем метод poll, чтобы позволить исполнителю опрашивать хранимую футуру:
// src/task/mod.rs
use core::task::{Context, Poll};
impl Task {
fn poll(&mut self, context: &mut Context) -> Poll<()> {
self.future.as_mut().poll(context)
}
}
Поскольку метод poll трейта Future ожидает вызова на типе Pin<&mut T>, мы сначала используем метод Pin::as_mut, чтобы преобразовать поле self.future типа Pin<Box<T>>. Затем мы вызываем poll на преобразованном поле self.future и возвращаем результат. Поскольку метод Task::poll должен вызываться только исполнителем, который мы создадим через мгновение, мы оставляем функцию приватной для модуля task.
🔗Простой Исполнитель
Поскольку исполнители могут быть довольно сложными, мы намеренно начинаем с создания очень базового исполнителя, прежде чем реализовывать более продвинутого. Для этого мы сначала создаём новый подмодуль task::simple_executor:
// src/task/mod.rs
pub mod simple_executor;
// src/task/simple_executor.rs
use super::Task;
use alloc::collections::VecDeque;
pub struct SimpleExecutor {
task_queue: VecDeque<Task>,
}
impl SimpleExecutor {
pub fn new() -> SimpleExecutor {
SimpleExecutor {
task_queue: VecDeque::new(),
}
}
pub fn spawn(&mut self, task: Task) {
self.task_queue.push_back(task)
}
}
Структура содержит единственное поле task_queue типа VecDeque, которое по сути является вектором, позволяющим выполнять операции добавления и удаления с обоих концов. Идея в том, что мы можем вставлять новые задачи через метод spawn в конец и извлекаем следующую задачу для выполнения из начала. Таким образом, мы получаем простую FIFO очередь (“первый пришёл — первый вышел”).
🔗Dummy Waker
Чтобы вызвать метод poll, нам нужно создать тип Context, который оборачивает тип Waker. Начнём с простого: мы сначала создадим заглушку waker, которая ничего не делает. Для этого мы создаём экземпляр RawWaker, который определяет реализацию различных методов Waker, а затем используем функцию Waker::from_raw, чтобы превратить его в Waker:
// src/task/simple_executor.rs
use core::task::{Waker, RawWaker};
fn dummy_raw_waker() -> RawWaker {
todo!();
}
fn dummy_waker() -> Waker {
unsafe { Waker::from_raw(dummy_raw_waker()) }
}
Функция from_raw является небезопасной, может привести к неопределенному поведению (undefined behavior) если программист не соблюдает документированные требования к RawWaker. Прежде чем мы рассмотрим реализацию функции dummy_raw_waker, давайте сначала попытаемся понять, как работает тип RawWaker.
🔗RawWaker
Тип RawWaker требует от программиста явного определения таблицы виртуальных методов (vtable), которая указывает функции, которые должны быть вызваны при клонировании (cloned), пробуждении (woken) или удалении (droppen) RawWaker. Расположение этой vtable определяется типом RawWakerVTable. Каждая функция получает аргумент *const (), который является type-erased указателем на некоторое значение. Причина использования указателя *const () вместо правильной ссылки в том, что тип RawWaker должен быть non-generic, но при этом поддерживать произвольные типы. Указатель передается в аргументе data функции RawWaker::new, которая просто инициализирует RawWaker. Затем Waker использует этот RawWaker, чтобы вызывать функции vtable с data.
Как правило, RawWaker создаётся для какой-то структуры, размещённой в куче, которая обёрнута в тип Box или Arc. Для таких типов можно использовать методы, такие как Box::into_raw, чтобы преобразовать Box<T> в указатель *const T. Этот указатель затем можно привести к анонимному указателю *const () и передать в RawWaker::new. Поскольку каждая функция vtable получает один и тот же *const () в качестве аргумента, функции могут безопасно привести указатель обратно к Box<T> или &T, чтобы работать с ним. Как вы можете себе представить, этот процесс крайне опасен и легко может привести к неопределённому поведению в случае ошибок. По этой причине вручную создавать RawWaker не рекомендуется, если это не является необходимым.
🔗Заглушка RawWaker
Хотя вручную создавать RawWaker не рекомендуется, в настоящее время нет другого способа создать заглушку Waker, которая ничего не делает. К счастью, тот факт, что мы хотим ничего не делать, делает реализацию функции dummy_raw_waker относительно безопасной:
// src/task/simple_executor.rs
use core::task::RawWakerVTable;
fn dummy_raw_waker() -> RawWaker {
fn no_op(_: *const ()) {}
fn clone(_: *const ()) -> RawWaker {
dummy_raw_waker()
}
let vtable = &RawWakerVTable::new(clone, no_op, no_op, no_op);
RawWaker::new(0 as *const (), vtable)
}
Сначала мы определяем две внутренние функции с именами no_op и clone. Функция no_op принимает указатель *const () и ничего не делает. Функция clone также принимает указатель *const () и возвращает новый RawWaker, снова вызывая dummy_raw_waker. Мы используем эти две функции для создания минимальной RawWakerVTable: функция clone используется для операций клонирования, а функция no_op — для всех остальных операций. Поскольку RawWaker ничего не делает, не имеет значения, что мы возвращаем новый RawWaker из clone вместо его клонирования.
После создания vtable мы используем функцию RawWaker::new для создания RawWaker. Переданный *const () не имеет значения, поскольку ни одна из функций vtable не использует его. По этой причине мы просто передаем нулевой указатель.
🔗Метод run
Теперь у нас есть способ создать экземпляр Waker, и мы можем использовать его для реализации метода run в нашем исполнителе. Самый простой метод run — это многократный опрос всех задач в очереди в цикле до тех пор, пока все они не будут выполнены. Это не очень эффективно, так как не использует уведомления от Waker, но это простой способ запустить это:
// src/task/simple_executor.rs
use core::task::{Context, Poll};
impl SimpleExecutor {
pub fn run(&mut self) {
while let Some(mut task) = self.task_queue.pop_front() {
let waker = dummy_waker();
let mut context = Context::from_waker(&waker);
match task.poll(&mut context) {
Poll::Ready(()) => {} // задача выполнена
Poll::Pending => self.task_queue.push_back(task),
}
}
}
}
Функция использует цикл while let, чтобы обработать все задачи в task_queue. Для каждой задачи сначала создаётся тип Context, оборачивая экземпляр Waker, возвращаемый нашей функцией dummy_waker. Затем вызывается метод Task::poll с этим context. Если метод poll возвращает Poll::Ready, задача завершена, и мы можем продолжить с следующей задачей. Если задача всё ещё Poll::Pending, мы добавляем её в конец очереди, чтобы она была опрошена снова в следующей итерации цикла.
🔗Попробуем это
С нашим типом SimpleExecutor мы теперь можем попробовать запустить задачу, возвращаемую функцией example_task, в нашем main.rs:
// src/main.rs
use blog_os::task::{Task, simple_executor::SimpleExecutor};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] инициализация всякого, включая `init_heap`
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.run();
// […] test_main, "It did not crash!" сообщение, hlt_loop
}
// ниже example_task, что бы вам не нужно было скролить
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
Когда мы запускаем её, мы видим, что ожидаемое сообщение “async number: 42” выводится на экран:
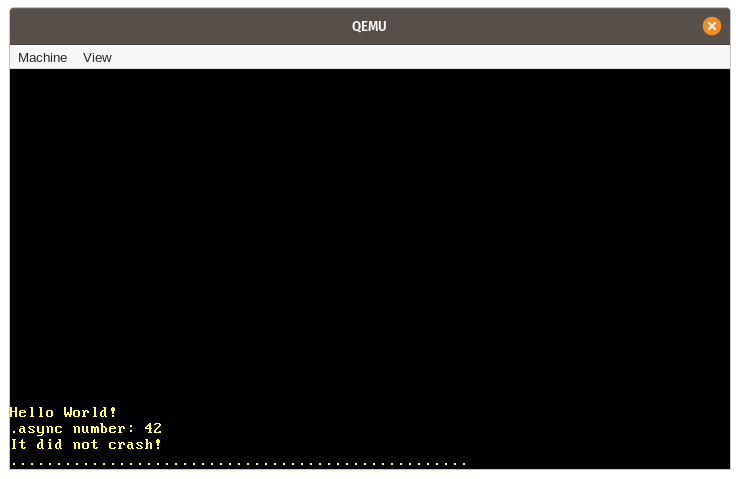
Давайте подытожим шаги, которые происходят в этом примере:
- Сначала создаётся новый экземпляр нашего типа
SimpleExecutorс пустойtask_queue. - Затем мы вызываем асинхронную функцию
example_task, которая возвращает футуру. Мы оборачиваем эту футуру в типTask, который перемещает её в кучу и закрепляет, а затем добавляем задачу вtask_queueисполнителя через методspawn. - После этого мы вызываем метод
run, чтобы начать выполнение единственной задачи в очереди. Это включает в себя:- Извлечение задачи из начала
task_queue. - Создание
RawWakerдля задачи, преобразование его в экземплярWakerи создание экземпляраContextна его основе. - Вызов метода
pollна футуре задачи, используя только что созданныйContext. - Поскольку
example_taskне ждёт ничего, она может непосредственно выполняться до конца при первом вызовеpoll. Именно здесь выводится строка “async number: 42”. - Т.к
example_taskнапрямую возвращаетPoll::Ready, она не добавляется обратно в очередь задач.
- Извлечение задачи из начала
- Метод
runвозвращается после того, какtask_queueстановится пустым. Выполнение нашей функцииkernel_mainпродолжается, и выводится сообщение “It did not crash!”.
🔗Асинхронный ввод с клавиатуры
Наш простой исполнитель не использует уведомления от Waker, а просто циклически обрабатывает все задачи до тех пор, пока они не завершатся. Это не проблема для нашего примера, так как example_task может завершиться сразу при первом вызове poll. Чтобы увидеть преимущества производительности при использования правильной реализации Waker, нам нужно сначала создать задачу, которая действительно асинхронна, т.е. задачу, которая, вернёт Poll::Pending при первом вызове poll.
У нас уже есть некий вид асинхронности в нашей системе, который мы можем использовать для этого: аппаратные прерывания. Как мы узнали в посте Interrupts, аппаратные прерывания могут происходить в произвольные моменты времени, определяемые каким-либо внешним устройством. Например, аппаратный таймер отправляет прерывание процессору после истечения заданного времени. Когда процессор получает прерывание, он немедленно передаёт управление соответствующей функции-обработчику, определённой в таблице дескрипторов прерываний (IDT).
В дальнейшем мы создадим асинхронную задачу на основе прерываний с клавиатуры. Это хороший кандидат, такие прерывания недетерминированны по времени и критичны к задержкам. Недетерминированность означает, что невозможно предсказать когда произойдёт нажатие клавиши, поскольку это полностью зависит от пользователя. Критичность к задержкам означает, что мы хотим обрабатывать ввод с клавиатуры своевременно, иначе пользователь почувствует задержку. Чтобы эффективно поддерживать такую задачу, исполнителю будет необходимо обеспечить надлежащую поддержку уведомлений Waker.
🔗Очередь Скан-кодов
Сейчас мы обрабатываем ввод с клавиатуры непосредственно в обработчике прерываний. Это не лучший подход в долгосрочной перспективе, обработка прерываний должна выполняться как можно быстрее, так как они могут прерывать важную работу. Вместо этого обработчики прерываний должны выполнять только минимальный объем необходимой работы (например, считывание кода сканирования клавиатуры) и оставлять остальную работу (например, интерпретацию кода сканирования) фоновой задаче.
Распространённым шаблоном для делегирования работы фоновым задачам является очередь. Обработчик прерываний добавляет единицы работы в очередь, а фоновая задача обрабатывает работу в очереди. Применительно к наим прерываниям это означает, что обработчик прерываний только считывает скан-код с клавиатуры, добавляет его в очередь, а затем возвращается. Задача клавиатуры находится на другом конце очереди и интерпретирует и обрабатывает каждый скан-код, который в неё добавляется:

Простая реализация такой очереди может быть основана на VecDeque, защищённом мьютексом. Однако использование мьютексов в обработчиках прерываний — не очень хорошая идея, так как это может легко привести к взаимным блокировкам (deadlock). Например, пользователь нажимает клавишу, но в тот же момент таска от клавиатуры заблокировала очередь, обработчик прерываний пытается снова захватить блокировку и застревает навсегда. Ещё одна проблема с этим подходом в том, что VecDeque автоматически увеличивает свою ёмкость, через аллокацию в куче, при заполнении. Это также может привести к взаимным блокировкам, так как наш аллокатор также использует внутренний мьютекс. Более того, выделение памяти в куче может не получиться или занять значительное время, если куча фрагментирована.
Чтобы предотвратить эти проблемы, нам нужна реализация очереди, которая не требует мьютексов или выделений памяти для своей операции push. Такие очереди могут быть реализованы с использованием неблокирующих [атомарных операций][atiomic operations] для добавления и извлечения элементов. Таким образом, возможно создать операции push и pop, которые требуют только ссылки &self и могут использоваться без мьютекса. Чтобы избежать выделений памяти при push, очередь может быть основана на заранее выделенном буфере фиксированного размера. Хотя это делает очередь ограниченной (bounded) (т.е. у неё есть максимальная длина), на практике часто возможно определить разумные верхние границы для длины очереди, так что это не представляет собой большой проблемы.
🔗Крейт crossbeam
Реализовать такую очередь правильно и эффективно очень сложно, поэтому я рекомендую придерживаться существующих, хорошо протестированных реализаций. Один из популярных проектов на Rust, который реализует различные типы без мьютексов для конкурентного программирования — это crossbeam. Он предоставляет тип под названием ArrayQueue, который именно то, что нам нужно в данном случае. И нам повезло: этот тип полностью совместим с no_std библиотеками, поддерживающими выделение памяти.
Чтобы использовать этот тип, нам нужно добавить зависимость на библиотеку crossbeam-queue:
# Cargo.toml
[dependencies.crossbeam-queue]
version = "0.3.11"
default-features = false
features = ["alloc"]
По умолчанию библиотека зависит от стандартной библиотеки. Чтобы сделать её совместимой с no_std, нам нужно отключить её стандартные функции и вместо этого включить функцию alloc. (Заметьте, что мы также могли бы добавить зависимость на основную библиотеку crossbeam, которая повторно экспортирует библиотеку crossbeam-queue, но это привело бы к большему количеству зависимостей и более длительному времени компиляции.)
🔗Реализация Очереди
Используя тип ArrayQueue, мы теперь можем создать глобальную очередь скан-кодов в новом модуле task::keyboard:
// src/task/mod.rs
pub mod keyboard;
// src/task/keyboard.rs
use conquer_once::spin::OnceCell;
use crossbeam_queue::ArrayQueue;
static SCANCODE_QUEUE: OnceCell<ArrayQueue<u8>> = OnceCell::uninit();
Поскольку ArrayQueue::new выполняет выделение памяти в куче, что невозможно на этапе компиляции (пока что), мы не можем инициализировать статическую переменную напрямую. Вместо этого мы используем тип OnceCell из библиотеки conquer_once, который позволяет безопасно выполнить одноразовую инициализацию статических значений. Чтобы включить библиотеку, нам нужно добавить её как зависимость в наш Cargo.toml:
# Cargo.toml
[dependencies.conquer-once]
version = "0.2.0"
default-features = false
Вместо примитива OnceCell мы также могли бы использовать макрос lazy_static. Однако тип OnceCell имеет то преимущество, что мы можем гарантировать, что инициализация не произойдёт в обработчике прерываний, тем самым предотвращая выполнение аллокации в куче в обработчике прерываний.
🔗Наполнение очереди
Чтобы заполнить очередь скан-кодов, мы создаём новую функцию add_scancode, которую будем вызывать из обработчика прерываний:
// src/task/keyboard.rs
use crate::println;
/// вызывается обработчиком прерываний клавиатуры
///
/// не должен блокировать или аллоцировать память
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}
Мы используем OnceCell::try_get для получения ссылки на инициализированную очередь. Если очередь ещё не инициализирована, мы игнорируем скан-код клавиатуры и печатаем предупреждение. Важно, чтобы мы не пытались инициализировать очередь в этой функции, так как она будет вызываться обработчиком прерываний, который не должен выполнять аллокации в куче. Поскольку эта функция не должна быть доступна из нашего main.rs, мы используем видимость pub(crate), чтобы сделать её доступной только для нашего lib.rs.
Тот факт, что метод ArrayQueue::push требует только ссылки &self, делает его очень простым для вызова на статической очереди. Тип ArrayQueue выполняет все необходимые синхронизации сам, поэтому нам не нужен мьютекс-обёртка. В случае, если очередь полна, мы также выводим предупреждение.
Чтобы вызывать функцию add_scancode при прерываниях клавиатуры, мы обновляем нашу функцию keyboard_interrupt_handler в модуле interrupts:
// src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame
) {
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
crate::task::keyboard::add_scancode(scancode); // новое
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
Мы убрали весь код обработки клавиатуры из этой функции и вместо этого добавили вызов функции add_scancode. Остальная часть функции остаётся такой же, как и прежде.
Как и ожидалось, нажатия клавиш больше не выводятся на экран, когда мы запускаем наш проект с помощью cargo run. Вместо этого пишется предупреждение, что очередь не инициализирована при каждом нажатия клавиши.
🔗Стрим Скан-кодов
Чтобы инициализировать SCANCODE_QUEUE и считывать скан-коды из очереди асинхронным способом, мы создаём новый тип ScancodeStream:
// src/task/keyboard.rs
pub struct ScancodeStream {
_private: (),
}
impl ScancodeStream {
pub fn new() -> Self {
SCANCODE_QUEUE.try_init_once(|| ArrayQueue::new(100))
.expect("ScancodeStream::new should only be called once");
ScancodeStream { _private: () }
}
}
Цель поля _private — предотвратить создание структуры из внешних модулей. Это делает функцию new единственным способом создать данный тип. В функции мы сначала пытаемся инициализировать статическую переменную SCANCODE_QUEUE. Если она уже инициализирована, мы вызываем панику, чтобы гарантировать, что можно создать только один экземпляр ScancodeStream.
Чтобы сделать скан-коды доступными для асинхронных задач, нужно реализовать метод, подобный poll, который пытается извлечь следующий скан-код из очереди. Хотя это звучит так, будто мы должны реализовать трейт Future для нашего типа, здесь он не подходит. Проблема в том, что трейт Future абстрагируется только над одним асинхронным значением и ожидает, что метод poll не будет вызываться снова после того, как он вернёт Poll::Ready. Наша очередь скан-кодов, однако, содержит несколько асинхронных значений, поэтому нормально продолжать опрашивать её.
🔗Трейт Stream
Поскольку типы, которые возвращают несколько асинхронных значений, являются распространёнными, библиотека futures предоставляет полезную абстракцию для таких типов: трейт Stream. Определение трейта:
pub trait Stream {
type Item;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Option<Self::Item>>;
}
Это определение довольно похоже на трейт Future, со следующими отличиями:
- Ассоциированный тип называется
Item, а неOutput. - Вместо метода
poll, который возвращаетPoll<Self::Item>, трейтStreamопределяет методpoll_next, который возвращаетPoll<Option<Self::Item>>(обратите внимание на дополнительныйOption).
Существует также семантическое отличие: метод poll_next можно вызывать многократно, пока он не вернёт Poll::Ready(None), чтобы сигнализировать о том, что стрим завершён. В этом отношении метод похож на метод Iterator::next, который также возвращает None после последнего значения.
🔗Реализация Stream
Давайте реализуем трейт Stream для нашего ScancodeStream, чтобы предоставлять значения из SCANCODE_QUEUE асинхронным способом. Для этого нам сначала нужно добавить зависимость на библиотеку futures-util, которая содержит тип Stream:
# Cargo.toml
[dependencies.futures-util]
version = "0.3.4"
default-features = false
features = ["alloc"]
Мы отключаем стандартные функции, чтобы сделать библиотеку совместимой с no_std, и включаем функцию alloc, чтобы сделать доступными её типы, основанные на аллокации памяти (это понадобится позже). (Заметьте, что мы также могли бы добавить зависимость на основную библиотеку futures, которая повторно экспортирует библиотеку futures-util, но это привело бы к большему количеству зависимостей и более длительному времени компиляции.)
Теперь мы можем импортировать и реализовать трейт Stream:
// src/task/keyboard.rs
use core::{pin::Pin, task::{Poll, Context}};
use futures_util::stream::Stream;
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE.try_get().expect("not initialized");
match queue.pop() {
Some(scancode) => Poll::Ready(Some(scancode)),
None => Poll::Pending,
}
}
}
Сначала мы используем метод OnceCell::try_get для получения ссылки на инициализированную очередь скан-кодов. Это никогда не должно вызывать ошибок, так как мы инициализируем очередь в функции new, поэтому мы можем безопасно использовать метод expect. Далее мы используем метод ArrayQueue::pop для попытки получить следующий элемент из очереди. Если это успешно, мы возвращаем скан-код, обёрнутый в Poll::Ready(Some(…)). Если это не удаётся, это означает, что очередь пуста. В этом случае мы возвращаем Poll::Pending.
🔗Поддержка Waker
Как и метод Futures::poll, метод Stream::poll_next требует от асинхронной задачи уведомить исполнителя, когда она становится готовой после возврата Poll::Pending. Таким образом, исполнителю не нужно повторно опрашивать ту же задачу, пока она не получит сигнал, что значительно снижает накладные расходы на ожидание задач.
Чтобы отправить это уведомление, задача должна извлечь Waker из переданной ссылки Context и сохранить его где-то. Когда задача становится готовой, она должна вызвать метод wake на сохранённом Waker, чтобы уведомить исполнителя о том, что задачу следует опросить снова.
🔗AtomicWaker
Чтобы реализовать уведомление Waker для нашего ScancodeStream, нам нужно место, где мы можем хранить Waker между вызовами poll. Мы не можем хранить его как поле в самом ScancodeStream, потому что он должен быть доступен из функции add_scancode. Решение этой проблемы — использование статической переменной типа AtomicWaker, предоставляемой библиотекой futures-util. Как и тип ArrayQueue, этот тип основан на атомарных инструкциях и может безопасно храниться в static и модифицироваться параллельно.
Давайте используем тип AtomicWaker для определения статической переменной WAKER:
// src/task/keyboard.rs
use futures_util::task::AtomicWaker;
static WAKER: AtomicWaker = AtomicWaker::new();
Идея в том, что реализация poll_next хранит текущий waker в этой статической переменной, а функция add_scancode вызывает функцию wake на ней, когда новый скан-код добавляется в очередь.
🔗Хранение Waker
Контракт, определяемый poll/poll_next, требует, чтобы задача зарегистрировала уведомление для переданного Waker, когда она возвращает Poll::Pending. Давайте изменим нашу реализацию poll_next, чтобы соблюдать это требование:
// src/task/keyboard.rs
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE
.try_get()
.expect("scancode queue not initialized");
// первый путь
if let Some(scancode) = queue.pop() {
return Poll::Ready(Some(scancode));
}
WAKER.register(&cx.waker());
match queue.pop() {
Some(scancode) => {
WAKER.take();
Poll::Ready(Some(scancode))
}
None => Poll::Pending,
}
}
}
Как и прежде, сначала мы используем функцию OnceCell::try_get для получения ссылки на инициализированную очередь скан-кодов. Затем мы оптимистично пытаемся выполнить pop из очереди и возвращаем Poll::Ready, при успехе. Таким образом, мы можем избежать накладных расходов на регистрацию waker, когда очередь не пуста.
Если первый вызов queue.pop() неуспешен, то очередь потенциально пуста. Потенциально, потому что обработчик прерываний мог заполнить очередь асинхронно сразу после проверки. Поскольку это состояние гонки может возникнуть снова для следующей проверки, мы должны зарегистрировать Waker в статической переменной WAKER перед второй проверкой. Таким образом, уведомление может произойти до того, как мы вернём Poll::Pending, но гарантируется, что мы получим уведомление для любых скан-кодов, добавленных после проверки.
После регистрации Waker, содержащегося в переданном Context, через функцию AtomicWaker::register, мы пытаемся выполнить pop из очереди во второй раз. Если теперь это получается, мы возвращаем Poll::Ready. Мы также снова удаляем зарегистрированный waker с помощью AtomicWaker::take, т.к. уведомление waker больше не нужно. Если queue.pop() снова неуспешно, мы возвращаем Poll::Pending, как и прежде, но на этот раз с зарегистрированным уведомлением.
Обратите внимание, что уведомление для задачи, которая ещё не вернула Poll::Pending, может произойти двумя способами. Один из способов — это упомянутое состояние гонки, когда уведомление происходит незадолго до возвращения Poll::Pending. Другой способ — это когда очередь больше не пуста после регистрации waker, так что возвращается Poll::Ready. Поскольку эти ложные уведомления предотвратить невозможно, исполнитель должен уметь правильно с ними справляться.
🔗Пробуждение хранящихся Waker
Чтобы разбудить сохранённый Waker, мы добавляем вызов WAKER.wake() в функцию add_scancode:
// src/task/keyboard.rs
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("WARNING: scancode queue full; dropping keyboard input");
} else {
WAKER.wake(); // новое
}
} else {
println!("WARNING: scancode queue uninitialized");
}
}
Единственное изменение, которое мы внесли, — это добавление вызова WAKER.wake(), если добавление в очередь скан-кодов прошло успешно. Если в статической переменной WAKER зарегистрирован waker, этот метод вызовет одноимённый метод wake на нём, который уведомляет исполнителя. Иначе операция ничего не делает.
Важно, чтобы мы вызывали wake только после добавления в очередь, потому что в противном случае задача может быть разбужена слишком рано, пока очередь всё ещё пуста. Это может, например, произойти при использовании многопоточного исполнителя, который запускает пробуждённую задачу параллельно на другом ядре CPU. Хотя у нас пока нет поддержки потоков, мы добавим её скоро и не хотим, чтобы всё сломалось в этом случае.
🔗Задачи от Клавиатуры
Теперь, когда мы реализовали трейт Stream для ScancodeStream, мы можем использовать его для создания асинхронной задач от клавиатуры (таски):
// src/task/keyboard.rs
use futures_util::stream::StreamExt;
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use crate::print;
pub async fn print_keypresses() {
let mut scancodes = ScancodeStream::new();
let mut keyboard = Keyboard::new(ScancodeSet1::new(),
layouts::Us104Key, HandleControl::Ignore);
while let Some(scancode) = scancodes.next().await {
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
}
}
Код очень похож на тот, который у нас был в нашем обработчике прерываний клавиатуры (keyboard interrupt handler) до того, как мы его изменили в этом посте. Единственное различие в том, что вместо чтения скан-кода из порта ввода-вывода мы берем его из ScancodeStream. Для этого мы сначала создаем новый стрим Scancode, а затем многократно используем метод next, предоставляемый трейтами StreamExt, чтобы получить Future, который разрешается в следующий элемент стрима. Используя оператор await, мы асинхронно ожидаем результат этого Future.
Мы используем while let для цикла, пока стрим не вернет None, сигнализируя о своем завершении. Поскольку наш метод poll_next никогда не возвращает None, это фактически бесконечный цикл, поэтому задача print_keypresses никогда не завершается.
Давайте добавим таску print_keypresses в наш исполнитель в main.rs, чтобы снова получить работающий ввод с клавиатуры:
// src/main.rs
use blog_os::task::keyboard; // новое
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] инициализация всякого, включая init_heap, test_main
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses())); // новое
executor.run();
// […] сообщение "it did not crash", hlt_loop
}
Когда мы выполняем cargo run сейчас, мы видим, что ввод с клавиатуры снова работает:

Если вы будете следить за загрузкой процессора вашего компьютера, вы увидите, что процесс QEMU теперь постоянно загружает CPU. Это происходит потому, что наш SimpleExecutor многократно опрашивает задачи в цикле. Поэтому даже если мы не нажимаем никаких клавиш на клавиатуре, исполнитель снова и снова вызывает poll для нашей задачи print_keypresses, хотя задача не может добиться прогресса и будет каждый раз возвращать Poll::Pending.
🔗Исполнитель с Поддержкой Waker
Чтобы решить проблему производительности, нам нужно создать исполнитель, который правильно использует уведомления Waker. Так исполнитель будет уведомлен при следующем прерывании клавиатуры и ему не нужно будет постоянно опрашивать задачу print_keypresses.
🔗Id Задачи
Первый шаг в создании исполнителя с правильной поддержкой уведомлений waker — это дать каждой задаче уникальный идентификатор. Это необходимо, потому что нам нужно иметь способ указать, какую задачу следует разбудить. Мы начинаем с создания нового типа-обёртки TaskId:
// src/task/mod.rs
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord)]
struct TaskId(u64);
Структура TaskId — это простая обёртка вокруг u64. Мы добавляем derive для того, что бы она была печатаемой, сравнимой, копируемой и сортируемой. Последнее важно, т.к. в дальнейшем мы хотим использовать TaskId в качестве типа ключа для BTreeMap.
Для создания нового уникального идентификатора мы создаём функцию TaskId::new:
use core::sync::atomic::{AtomicU64, Ordering};
impl TaskId {
fn new() -> Self {
static NEXT_ID: AtomicU64 = AtomicU64::new(0);
TaskId(NEXT_ID.fetch_add(1, Ordering::Relaxed))
}
}
Функция использует статическую переменную NEXT_ID типа AtomicU64, чтобы гарантировать, что каждый идентификатор присваивается только один раз. Метод fetch_add атомарно увеличивает значение и возвращает предыдущее за одну атомарную операцию. Это значит, что даже когда метод TaskId::new вызывается параллельно, каждый идентификатор возвращается ровно один раз. Параметр Ordering определяет, может ли компилятор переупорядочить операцию fetch_add в стриме инструкций. Поскольку мы только требуем, чтобы идентификатор был уникальным, в этом случае достаточно использования упорядочивание Relaxed с самыми слабыми требованиями.
Теперь мы можем расширить наш тип Task, добавив поле id:
// src/task/mod.rs
pub struct Task {
id: TaskId, // новое
future: Pin<Box<dyn Future<Output = ()>>>,
}
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
id: TaskId::new(), // новое
future: Box::pin(future),
}
}
}
Новое поле id позволяет уникально называть задачу, что необходимо для пробуждения конкретной задачи.
🔗Тип Executor
Мы создаем наш новый тип Executor в модуле task::executor:
// src/task/mod.rs
pub mod executor;
// src/task/executor.rs
use super::{Task, TaskId};
use alloc::{collections::BTreeMap, sync::Arc};
use core::task::Waker;
use crossbeam_queue::ArrayQueue;
pub struct Executor {
tasks: BTreeMap<TaskId, Task>,
task_queue: Arc<ArrayQueue<TaskId>>,
waker_cache: BTreeMap<TaskId, Waker>,
}
impl Executor {
pub fn new() -> Self {
Executor {
tasks: BTreeMap::new(),
task_queue: Arc::new(ArrayQueue::new(100)),
waker_cache: BTreeMap::new(),
}
}
}
Вместо хранения задач в VecDeque, как мы делали для нашего SimpleExecutor, мы используем task_queue с идентификаторами задач и BTreeMap с именем tasks, который содержит фактические экземпляры Task. Карта индексируется по TaskId, что позволяет эффективно продолжать выполнение конкретной задачи.
Поле task_queue представляет собой ArrayQueue идентификаторов задач, обёрнутую в тип Arc, который реализует счётчик ссылок (reference counting). Счётчик ссылок позволяет разделять владение значением между несколькими владельцами. Он аллоцирует место куче и записывает туда кол-во активных ссылок. Когда количество активных ссылок достигает нуля, значение больше не нужно и может быть освобождено.
Мы используем тип Arc<ArrayQueue> для task_queue, потому что он будет разделяться между исполнителем и wakers. Идея в том, что wakers добавляют идентификатор разбуженной задачи в очередь. Исполнитель находится на приемной стороне очереди, извлекает разбуженные задачи по их идентификатору из tasks дерева и затем выполняет их. Причина использования фиксированной очереди вместо неограниченной, такой как SegQueue в том, что обработчики прерываний не должны выделять память при добавлении в эту очередь.
В дополнение к task_queue и дереве tasks, тип Executor имеет поле waker_cache, которое также является деревом. Это дерево кэширует Waker задачи после его создания. На это имеется две причины: во-первых, это улучшает производительность, повторно используя тот же waker для нескольких пробуждений одной и той же задачи, вместо создания нового waker каждый раз. Во-вторых, это гарантирует, что wakers с подсчётом ссылок не освобождаются внутри обработчиков прерываний, поскольку это может привести к взаимным блокировкам (подробнее об ниже).
Чтобы создать Executor, мы предоставляем простую функцию new. Мы выбираем ёмкость 100 для task_queue, что должно быть более чем достаточно на обозримое будущее. В случае, если в нашей системе в какой-то момент будет больше 100 параллельных задач, мы можем легко увеличить этот размер.
🔗Spawn Задач
Как и в SimpleExecutor, мы предоставляем метод spawn для нашего типа Executor, который добавляет данную задачу в дерево tasks и немедленно пробуждает её, добавляя её идентификатор в task_queue:
// src/task/executor.rs
impl Executor {
pub fn spawn(&mut self, task: Task) {
let task_id = task.id;
if self.tasks.insert(task.id, task).is_some() {
panic!("task with same ID already in tasks");
}
self.task_queue.push(task_id).expect("queue full");
}
}
Если в карте уже существует задача с тем же идентификатором, метод [BTreeMap::insert] возвращает её. Это никогда не должно происходить, поскольку каждая задача имеет уникальный идентификатор, поэтому в этом случае мы вызываем панику, так как это указывает на ошибку в нашем коде. Аналогично, мы вызываем панику, когда task_queue полна, так как этого никогда не должно происходить, если мы выбираем достаточно большой размер очереди.
🔗Запуск Задач
Чтобы выполнить все задачи в task_queue, мы создаём приватный метод run_ready_tasks:
// src/task/executor.rs
use core::task::{Context, Poll};
impl Executor {
fn run_ready_tasks(&mut self) {
// деструктуризация `self` что бы избежать ошибок проверки заимствования (borrow checker)
let Self {
tasks,
task_queue,
waker_cache,
} = self;
while let Some(task_id) = task_queue.pop() {
let task = match tasks.get_mut(&task_id) {
Some(task) => task,
None => continue, // task больше нету
};
let waker = waker_cache
.entry(task_id)
.or_insert_with(|| TaskWaker::new(task_id, task_queue.clone()));
let mut context = Context::from_waker(waker);
match task.poll(&mut context) {
Poll::Ready(()) => {
// задача готова -> удалить ее и кеширумый waker
tasks.remove(&task_id);
waker_cache.remove(&task_id);
}
Poll::Pending => {}
}
}
}
}
Смысл функции схож со смыслом SimpleExecutor: циклично перебираем все задачи в task_queue, создаём waker для каждой задачи и затем опрашиваем их. Однако вместо того, чтобы добавлять ожидающие задачи обратно в конец task_queue, мы позволяем реализации нашего TaskWaker заботиться о добавлении пробуждённых задач обратно в очередь. Реализация этого типа waker будет показана через мгновение.
Давайте рассмотрим некоторые детали реализации этого метода run_ready_tasks:
-
Мы используем деструктуризацию destructuring, чтобы разделить
selfна три поля, чтобы избежать некоторых ошибок компилятора. В частности, наша реализация требует доступа кself.task_queueизнутри замыкания, что в данный момент пытается полностью заимствоватьself. Это фундаментальная проблема компилятора, которая будет решена в RFC 2229, проблема. -
Для каждого извлеченного идентификатора задачи мы получаем мутабельную ссылку на соответствующую задачу из дерева
tasks. Поскольку наша реализацияScancodeStreamрегистрирует wakers перед проверкой, нужно ли задачу отправить в сон, может случиться так, что произойдёт пробуждение для задачи, которой больше не существует. В этом случае мы просто игнорируем пробуждение и продолжаем со следующим идентификатором из очереди. -
Чтобы избежать накладных расходов на создание waker при каждом опросе, мы используем дерево
waker_cacheдля хранения waker для каждой задачи после ее создания. Для этого мы используем методBTreeMap::entryв сочетании сEntry::or_insert_withдля создания нового waker, если он ещё не существует, а затем получаем на него мутабельную ссылку. Для создания нового waker мы клонируемtask_queueи передаём его вместе с идентификатором задачи в функциюTaskWaker::new(реализация ниже). Посколькуtask_queueобёрнута вArc,cloneтолько увеличивает счётчик ссылок на значение, но всё равно указывает на ту же выделенную в куче очередь. Обратите внимание, что повторное использование wakers таким образом, невозможно для всех реализаций waker, но наш типTaskWakerэто позволит.
Задача считается завершённой, когда она возвращает Poll::Ready. В этом случае мы удаляем её из дерева tasks с помощью метода BTreeMap::remove. Мы также удаляем её кэшированный waker, если он существует.
🔗Архитектура Waker
Задача waker — добавить идентификатор разбуженной задачи в task_queue исполнителя. Мы реализуем это, создавая новую структуру TaskWaker, которая хранит идентификатор задачи и ссылку на task_queue:
// src/task/executor.rs
struct TaskWaker {
task_id: TaskId,
task_queue: Arc<ArrayQueue<TaskId>>,
}
Поскольку владение task_queue разделяется между исполнителем и wakers, мы используем обёртку типа Arc для реализации совместного владения с подсчётом ссылок.
Реализация операции пробуждения довольно проста:
// src/task/executor.rs
impl TaskWaker {
fn wake_task(&self) {
self.task_queue.push(self.task_id).expect("task_queue full");
}
}
Мы добавляем task_id в ссылку на task_queue. Поскольку модификации типа ArrayQueue требуют только совместной ссылки, мы можем реализовать этот метод на &self, а не на &mut self.
🔗Трейт Wake
Чтобы использовать наш тип TaskWaker для опроса futures, нам нужно сначала преобразовать его в экземпляр Waker. Это необходимо, потому что метод Future::poll принимает экземпляр Context в качестве аргумента, который можно создать только из типа Waker. Хотя мы могли бы сделать это, предоставив реализацию типа RawWaker, проще и безопаснее реализовать трейт Wake на основе Arc и затем использовать реализации From, предоставленные стандартной библиотекой, для создания Waker.
Реализация трейта выглядит следующим образом:
// src/task/executor.rs
use alloc::task::Wake;
impl Wake for TaskWaker {
fn wake(self: Arc<Self>) {
self.wake_task();
}
fn wake_by_ref(self: &Arc<Self>) {
self.wake_task();
}
}
Поскольку wakers обычно разделяются между исполнителем и асинхронными задачами, методы трейта требуют, чтобы экземпляр Self был обёрнут в тип Arc, который реализует владение с подсчётом ссылок. Это означает, что нам нужно переместить наш TaskWaker в Arc, чтобы вызвать их.
Разница между методами wake и wake_by_ref заключается в том, что последний требует только ссылки на Arc, в то время как первый забирает владение Arc и, следовательно, часто требует увеличения счётчика ссылок. Не все типы поддерживают пробуждение по ссылке, поэтому реализация метода wake_by_ref является необязательной. Однако это может привести к лучшей производительности, так как избегает ненужных модификаций счётчика ссылок. В нашем случае мы можем просто перенаправить оба метода трейта к нашей функции wake_task, которая требует только совместимой ссылки &self.
🔗Создание Wakers
Поскольку тип Waker поддерживает преобразования From для всех значений, обёрнутых в Arc и реализующих трейт Wake, мы теперь можем реализовать функцию TaskWaker::new, необходимую для метода Executor::run_ready_tasks:
// src/task/executor.rs
impl TaskWaker {
fn new(task_id: TaskId, task_queue: Arc<ArrayQueue<TaskId>>) -> Waker {
Waker::from(Arc::new(TaskWaker {
task_id,
task_queue,
}))
}
}
Мы создаём TaskWaker, используя переданные task_id и task_queue. Затем мы оборачиваем TaskWaker в Arc и используем реализацию Waker::from, чтобы преобразовать его в Waker. Этот метод from заботится о создании экземпляра RawWakerVTable и RawWaker для нашего типа TaskWaker. Если вам интересно, как это работает в деталях, ознакомьтесь с реализацией в crate alloc.
🔗Метод run
С нашей реализацией waker мы наконец можем создать метод run для нашего исполнителя:
// src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
}
}
}
Этот метод просто вызывает функцию run_ready_tasks в цикле. Хотя теоретически мы могли бы выйти из функции, когда карта tasks станет пустой, этого никогда не произойдёт, так как наша keyboard::print_keypresses никогда не завершается, поэтому простого loop будет достаточно. Поскольку функция никогда не возвращается, мы используем тип возвращаемого значения !, чтобы пометить функцию как расходящуюся для компилятора.
Теперь мы можем изменить наш kernel_main, чтобы использовать наш новый Executor вместо SimpleExecutor:
// src/main.rs
use blog_os::task::executor::Executor; // новое
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] инициализация всякого, включая init_heap, test_main
let mut executor = Executor::new(); // новое
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses()));
executor.run();
}
Нам нужно только изменить импорт и имя типа. Поскольку наша функция run помечена как расходящаяся, компилятор знает, что она никогда не возвращается, поэтому нам больше не нужно вызывать hlt_loop в конце функции kernel_main.
Когда мы теперь запускаем наше ядро с помощью cargo run, мы видим, что ввод с клавиатуры всё ещё работает:

Однако, загрузка процессора QEMU не уменьшилась. Причина в том, что мы по-прежнему загружаем процессор всё время. Мы больше не опрашиваем задачи, пока они не будут пробуждены снова, но мы всё же проверяем task_queue в цикле с занятым ожиданием. Чтобы это исправить, нам нужно перевести процессор в спящий режим, если больше нет работы.
🔗Спать если Idle
Основная идея в том, чтобы выполнять инструкцию hlt при пустой task_queue. Эта инструкция ставит процессор в спящий режим до следующего прерывания. Факт, что процессор немедленно активируется снова при возникновении прерывания, обеспечивает возможность прямой реакции, когда обработчик прерываний добавляет задачу в task_queue.
Для реализации этого мы создаём новый метод sleep_if_idle в нашем исполнителе и вызываем его из метода run:
// src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
self.sleep_if_idle(); // новое
}
}
fn sleep_if_idle(&self) {
if self.task_queue.is_empty() {
x86_64::instructions::hlt();
}
}
}
Поскольку мы вызываем sleep_if_idle сразу после run_ready_tasks, который циклично выполняется до тех пор, пока task_queue не станет пустой, проверка очереди может показаться ненужной. Однако аппаратное прерывание может произойти сразу после того, как run_ready_tasks возвращает, поэтому в момент вызова функции sleep_if_idle может оказаться новая задача в очереди. Только если очередь всё ещё пуста, мы ставим процессор в спящий режим, выполняя инструкцию hlt через обёрточную функцию instructions::hlt, предоставляемую библиотекой x86_64.
К сожалению, в этой реализации всё ещё присутствует небольшой race condition. Т.к. прерывания асинхронные и могут происходить в любое время, возможно, что прерывание произойдёт сразу между проверкой is_empty и вызовом hlt:
if self.task_queue.is_empty() {
/// <--- прерывание может быть тут
x86_64::instructions::hlt();
}
Если это прерывание добавляет задачу в task_queue, мы ставим процессор в спящий режим, даже несмотря на то, что теперь есть готовая задача. В худшем случае это может задержать обработку прерывания клавиатуры до следующего нажатия клавиши или следующего таймерного прерывания. Как же нам этого избежать?
Ответ заключается в том, чтобы отключить прерывания на процессоре перед проверкой и атомарно включить их снова вместе с инструкцией hlt. Таким образом, все прерывания, которые происходят между этими действиями, будут отложены после инструкции hlt, чтобы не пропустить никаких пробуждений. Для реализации этого подхода мы можем использовать функцию interrupts::enable_and_hlt, предоставляемую библиотекой x86_64.
Обновлённая реализация нашей функции sleep_if_idle выглядит следующим образом:
// src/task/executor.rs
impl Executor {
fn sleep_if_idle(&self) {
use x86_64::instructions::interrupts::{self, enable_and_hlt};
interrupts::disable();
if self.task_queue.is_empty() {
enable_and_hlt();
} else {
interrupts::enable();
}
}
}
Чтобы избежать состояний гонки, мы отключаем прерывания перед проверкой, пуста ли task_queue. Если она пуста, мы используем функцию enable_and_hlt, чтобы включить прерывания и поставить процессор в спящий режим в рамках одной атомарной операции. Если очередь больше не пуста, это означает, что прерывание пробудило задачу после возврата run_ready_tasks. В этом случае мы снова включаем прерывания и продолжаем выполнение, не выполняя hlt.
Теперь наш исполнитель правильно ставит процессор в спящий режим, когда задач нет. Мы можем видеть, что загрузка процессора QEMU значительно снизилась, когда мы снова запускаем наше ядро с помощью cargo run.
🔗Возможные Расширения
Наш исполнитель теперь способен эффективно выполнять задачи. Он использует уведомления waker, чтобы избежать опроса ожидающих задач, и переводит процессор в спящий режим, когда задач нет. Однако наш исполнитель всё ещё довольно примитивный, и существует множество способов расширить его функциональность:
- Планирование: Для нашей
task_queueмы в настоящее время используем типVecDequeдля реализации стратегии первый пришёл — первый вышел (FIFO), которая часто также называется круговым планированием. Эта стратегия может быть не самой эффективной для произвольной нагрузки. Например, имеет смысл приоритизировать таски, где критична задержка или таски, выполняющие много ввода-вывода. Для получения дополнительной информации смотрите главу о планировании книги Operating Systems: Three Easy Pieces или статью в Википедии о планировании. - Создание задач: Сейчас метод
Executor::spawnтребует ссылки&mut self, и поэтому он недоступен после вызова методаrun. Чтобы это исправить, мы могли бы создать дополнительный типSpawner, который делит какую-то очередь с исполнителем и позволяет создавать задачи изнутри самих задач. Очередь может бытьtask_queueнапрямую или отдельной очередью, которую исполнитель проверяет в своём цикле выполнения. - Использование потоков: У нас пока нет поддержки потоков, но мы добавим её в следующем посте. Это сделает возможным запуск нескольких экземпляров исполнителя в разных потоках. Преимущество этого подхода заключается в том, что задержка, вызванная длительными задачами, может быть уменьшена, так как другие задачи могут выполняться параллельно. Этот подход также позволяет использовать несколько ядер процессора.
- Балансировка нагрузки: При добавлении поддержки потоков становится важно быть в курсе, как распределяются задачи между исполнителями, чтобы обеспечить использование всех ядер процессора. Распространённой техникой для этого является work stealing.
🔗Итоги
Мы начали этот пост с обсуждения многозадачности и различий между вытесняемой, которая регулярно прерывает выполняющиеся задачи, и кооперативной, позволяющей задачам работать до тех пор, пока они не добровольно отдадут управление процессором.
Затем мы исследовали, как поддержка Rust async/await предоставляет реализацию кооперативной многозадачности на уровне языка. Rust основывает свою реализацию на опросном (polling-based) трейте Future, который абстрагирует асинхронные задачи. С использованием async/await возможно работать с futures почти так же, как с обычным синхронным кодом. Разница заключается в том, что асинхронные функции снова возвращают Future, который в какой-то момент должен быть добавлен в исполнителя для запуска.
За кулисами компилятор преобразует код async/await в конечный автомат, при этом каждая операция .await соответствует возможной точке остановки. Используя свои знания о программе, компилятор может сохранять только минимальное состояние для каждой точки остановки, что приводит к очень низкому потреблению памяти на задачу. Одной из проблем является то, что сгенерированные автоматы могут содержать самоссылающиеся структуры, например, когда локальные переменные асинхронной функции ссылаются друг на друга. Чтобы избежать недействительных указателей, Rust использует тип Pin, чтобы гарантировать, что futures не могут быть перемещены в памяти после их первого опроса.
Для нашей реализации мы сначала создали очень простой исполнитель, который опрашивает все запущенные задачи в цикле с занятым ожиданием, не используя тип Waker. Затем мы продемонстрировали преимущество уведомлений waker, реализовав асинхронную задачу клавиатуры. Задача определяет статический SCANCODE_QUEUE, используя неблокирующий тип ArrayQueue, предоставленный библиотекой crossbeam. Вместо непосредственной обработки нажатий клавиш, обработчик прерываний клавиатуры теперь помещает все полученные скан-коды в очередь и затем пробуждает зарегистрированный Waker, чтобы сигнализировать, что новый ввод доступен. На принимающей стороне мы создали тип ScancodeStream, чтобы предоставить Future, разрешающийся в следующий скан-код в очереди. Это сделало возможным создание асинхронной задачи print_keypresses, которая использует async/await для интерпретации и вывода скан-кодов в очереди.
Чтобы использовать уведомления waker для тасков клавиатуры, мы создали новый тип Executor, который использует task_queue на основе Arc для готовых задач. Мы реализовали тип TaskWaker, который добавляет идентификаторы разбуженных задач непосредственно в эту task_queue, которые затем снова опрашиваются исполнителем. Чтобы сэкономить энергию, когда нет запущенных задач, мы добавили поддержку перевода процессора в спящий режим с использованием инструкции hlt. Наконец, мы обсудили некоторые потенциальные расширения для нашего исполнителя, например, предоставление поддержки мультипроцессинга.
Для обработки клавиатурных тасков мы использования уведомления о пробуждении (waker notifications). Для этого реализовали новый тип Executor, который использует Arc-общую task_queue для готовых задач. Мы реализовали тип TaskWaker, который добавляет идентификаторы разбуженных задач в task_queue, которая затем опрашивается исполнителем. Чтобы сэкономить энергию, когда нет запущенных задач, мы добавили поддержку перевода процессора в спящий режим с использованием инструкции hlt.
🔗Что Далее?
Используя async/await, мы теперь имеем базовую поддержку кооперативной многозадачности в нашем ядре. Хотя кооперативная многозадачность очень эффективна, она может привести к проблемам с задержкой, когда отдельные задачи выполняются слишком долго, тем самым препятствуя выполнению других задач. По этой причине имеет смысл также добавить поддержку вытесняющей многозадачности в наше ядро.
В следующем посте мы введём потоки как наиболее распространённую форму вытесняющей многозадачности. В дополнение к решению проблемы длительных задач, потоки также подготовят нас к использованию нескольких ядер процессора и запуску ненадежных пользовательских программ в будущем.
Комментарии
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English and follow Rust's code of conduct. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Пожалуйста, оставляйте комментарии на английском по возможности.