Interrupções de Hardware
Conteúdo Traduzido: Esta é uma tradução comunitária do post Hardware Interrupts. Pode estar incompleta, desatualizada ou conter erros. Por favor, reporte qualquer problema!
Traduzido por @richarddalves.
Nesta postagem, configuramos o controlador de interrupção programável para encaminhar corretamente interrupções de hardware para a CPU. Para manipular essas interrupções, adicionamos novas entradas à nossa tabela de descritores de interrupção, assim como fizemos para nossos manipuladores de exceção. Aprenderemos como obter interrupções periódicas de timer e como obter entrada do teclado.
Este blog é desenvolvido abertamente no GitHub. Se você tiver algum problema ou dúvida, abra um issue lá. Você também pode deixar comentários na parte inferior. O código-fonte completo desta publicação pode ser encontrado na branch post-07.
Tabela de Conteúdos
🔗Visão Geral
Interrupções fornecem uma forma de notificar a CPU de dispositivos de hardware conectados. Então, em vez de deixar o kernel verificar periodicamente o teclado por novos caracteres (um processo chamado polling), o teclado pode notificar o kernel de cada pressionamento de tecla. Isso é muito mais eficiente porque o kernel só precisa agir quando algo aconteceu. Também permite tempos de reação mais rápidos, já que o kernel pode reagir imediatamente e não apenas na próxima verificação.
Conectar todos os dispositivos de hardware diretamente à CPU não é possível. Em vez disso, um controlador de interrupção separado agrega as interrupções de todos os dispositivos e então notifica a CPU:
____________ _____
Timer ------------> | | | |
Teclado ----------> | Controlador|---------> | CPU |
Outro Hardware ---> | de | |_____|
Etc. -------------> | Interrupção|
|____________|
A maioria dos controladores de interrupção são programáveis, o que significa que suportam diferentes níveis de prioridade para interrupções. Por exemplo, isso permite dar às interrupções de timer uma prioridade mais alta que as interrupções de teclado para garantir cronometragem precisa.
Ao contrário de exceções, interrupções de hardware ocorrem assincronamente. Isso significa que são completamente independentes do código executado e podem ocorrer a qualquer momento. Assim, temos repentinamente uma forma de concorrência em nosso kernel com todos os potenciais bugs relacionados à concorrência. O modelo estrito de ownership de Rust nos ajuda aqui porque proíbe estado global mutável. No entanto, deadlocks ainda são possíveis, como veremos mais tarde nesta postagem.
🔗O 8259 PIC
O Intel 8259 é um controlador de interrupção programável (PIC) introduzido em 1976. Ele foi há muito tempo substituído pelo mais novo APIC, mas sua interface ainda é suportada em sistemas atuais por razões de compatibilidade retroativa. O 8259 PIC é significativamente mais fácil de configurar que o APIC, então o usaremos para nos introduzir a interrupções antes de mudarmos para o APIC em uma postagem posterior.
O 8259 tem oito linhas de interrupção e várias linhas para se comunicar com a CPU. Os sistemas típicos daquela época eram equipados com duas instâncias do 8259 PIC, um PIC primário e um secundário, conectado a uma das linhas de interrupção do primário:
____________ ____________
Real Time Clock --> | | Timer -------------> | |
ACPI -------------> | | Teclado-----------> | | _____
Disponível -------> | Controlador|----------------------> | Controlador| | |
Disponível -------> | de | Porta Serial 2 ----> | de |---> | CPU |
Mouse ------------> | Interrupção| Porta Serial 1 ----> | Interrupção| |_____|
Co-Processador ---> | Secundário | Porta Paralela 2/3 > | Primário |
ATA Primário -----> | | Disquete ---------> | |
ATA Secundário ---> |____________| Porta Paralela 1---> |____________|
Este gráfico mostra a atribuição típica de linhas de interrupção. Vemos que a maioria das 15 linhas têm um mapeamento fixo, por exemplo, a linha 4 do PIC secundário é atribuída ao mouse.
Cada controlador pode ser configurado através de duas portas I/O, uma porta “comando” e uma porta “dados”. Para o controlador primário, essas portas são 0x20 (comando) e 0x21 (dados). Para o controlador secundário, elas são 0xa0 (comando) e 0xa1 (dados). Para mais informações sobre como os PICs podem ser configurados, veja o artigo em osdev.org.
🔗Implementação
A configuração padrão dos PICs não é utilizável porque envia números de vetor de interrupção no intervalo de 0–15 para a CPU. Esses números já estão ocupados por exceções de CPU. Por exemplo, o número 8 corresponde a um double fault. Para corrigir esse problema de sobreposição, precisamos remapear as interrupções PIC para números diferentes. O intervalo real não importa desde que não se sobreponha às exceções, mas tipicamente o intervalo de 32–47 é escolhido, porque esses são os primeiros números livres após os 32 slots de exceção.
A configuração acontece escrevendo valores especiais nas portas de comando e dados dos PICs. Felizmente, já existe uma crate chamada pic8259, então não precisamos escrever a sequência de inicialização nós mesmos. No entanto, se você estiver interessado em como funciona, confira seu código-fonte. Ele é bastante pequeno e bem documentado.
Para adicionar a crate como dependência, adicionamos o seguinte ao nosso projeto:
# em Cargo.toml
[dependencies]
pic8259 = "0.10.1"
A principal abstração fornecida pela crate é a struct ChainedPics que representa o layout primário/secundário de PIC que vimos acima. Ela é projetada para ser usada da seguinte forma:
// em src/interrupts.rs
use pic8259::ChainedPics;
use spin;
pub const PIC_1_OFFSET: u8 = 32;
pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
pub static PICS: spin::Mutex<ChainedPics> =
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
Como notado acima, estamos definindo os offsets para os PICs no intervalo 32–47. Ao envolver a struct ChainedPics em um Mutex, obtemos acesso mutável seguro (através do método lock), que precisamos no próximo passo. A função ChainedPics::new é unsafe porque offsets errados poderiam causar comportamento indefinido.
Agora podemos inicializar o 8259 PIC em nossa função init:
// em src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
unsafe { interrupts::PICS.lock().initialize() }; // novo
}
Usamos a função initialize para realizar a inicialização do PIC. Como a função ChainedPics::new, esta função também é unsafe porque pode causar comportamento indefinido se o PIC estiver mal configurado.
Se tudo correr bem, devemos continuar a ver a mensagem “Não crashou!” ao executar cargo run.
🔗Habilitando Interrupções
Até agora, nada aconteceu porque as interrupções ainda estão desativadas na configuração da CPU. Isso significa que a CPU não escuta o controlador de interrupção de forma alguma, então nenhuma interrupção pode chegar à CPU. Vamos mudar isso:
// em src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
unsafe { interrupts::PICS.lock().initialize() };
x86_64::instructions::interrupts::enable(); // novo
}
A função interrupts::enable da crate x86_64 executa a instrução especial sti (“set interrupts”) para habilitar interrupções externas. Quando tentamos cargo run agora, vemos que ocorre um double fault:
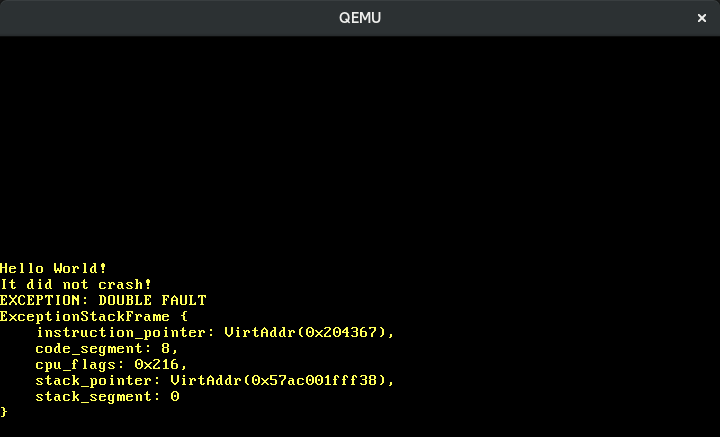
A razão para este double fault é que o timer de hardware (o Intel 8253, para ser exato) é habilitado por padrão, então começamos a receber interrupções de timer assim que habilitamos interrupções. Como ainda não definimos uma função manipuladora para ele, nosso manipulador de double fault é invocado.
🔗Manipulando Interrupções de Timer
Como vemos do gráfico acima, o timer usa a linha 0 do PIC primário. Isso significa que ele chega à CPU como interrupção 32 (0 + offset 32). Em vez de codificar rigidamente o índice 32, o armazenamos em um enum InterruptIndex:
// em src/interrupts.rs
#[derive(Debug, Clone, Copy)]
#[repr(u8)]
pub enum InterruptIndex {
Timer = PIC_1_OFFSET,
}
impl InterruptIndex {
fn as_u8(self) -> u8 {
self as u8
}
fn as_usize(self) -> usize {
usize::from(self.as_u8())
}
}
O enum é um enum similar a C para que possamos especificar diretamente o índice para cada variante. O atributo repr(u8) especifica que cada variante é representada como um u8. Adicionaremos mais variantes para outras interrupções no futuro.
Agora podemos adicionar uma função manipuladora para a interrupção de timer:
// em src/interrupts.rs
use crate::print;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
[…]
idt[InterruptIndex::Timer.as_usize()]
.set_handler_fn(timer_interrupt_handler); // novo
idt
};
}
extern "x86-interrupt" fn timer_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!(".");
}
Nosso timer_interrupt_handler tem a mesma assinatura que nossos manipuladores de exceção, porque a CPU reage identicamente a exceções e interrupções externas (a única diferença é que algumas exceções empurram um código de erro). A struct InterruptDescriptorTable implementa a trait IndexMut, então podemos acessar entradas individuais através da sintaxe de indexação de array.
Em nosso manipulador de interrupção de timer, imprimimos um ponto na tela. Como a interrupção de timer acontece periodicamente, esperaríamos ver um ponto aparecendo a cada tick do timer. No entanto, quando o executamos, vemos que apenas um único ponto é impresso:
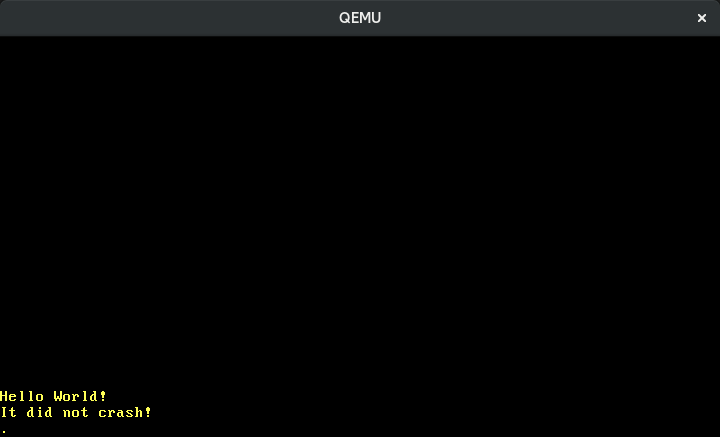
🔗End of Interrupt
A razão é que o PIC espera um sinal explícito de “end of interrupt” (EOI) do nosso manipulador de interrupção. Este sinal diz ao controlador que a interrupção foi processada e que o sistema está pronto para receber a próxima interrupção. Então o PIC pensa que ainda estamos ocupados processando a primeira interrupção de timer e espera pacientemente pelo sinal EOI antes de enviar a próxima.
Para enviar o EOI, usamos nossa struct PICS estática novamente:
// em src/interrupts.rs
extern "x86-interrupt" fn timer_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!(".");
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Timer.as_u8());
}
}
O notify_end_of_interrupt descobre se o PIC primário ou secundário enviou a interrupção e então usa as portas command e data para enviar um sinal EOI aos respectivos controladores. Se o PIC secundário enviou a interrupção, ambos os PICs precisam ser notificados porque o PIC secundário está conectado a uma linha de entrada do PIC primário.
Precisamos ter cuidado para usar o número de vetor de interrupção correto, caso contrário poderíamos acidentalmente deletar uma importante interrupção não enviada ou fazer nosso sistema travar. Esta é a razão pela qual a função é unsafe.
Quando agora executamos cargo run vemos pontos aparecendo periodicamente na tela:
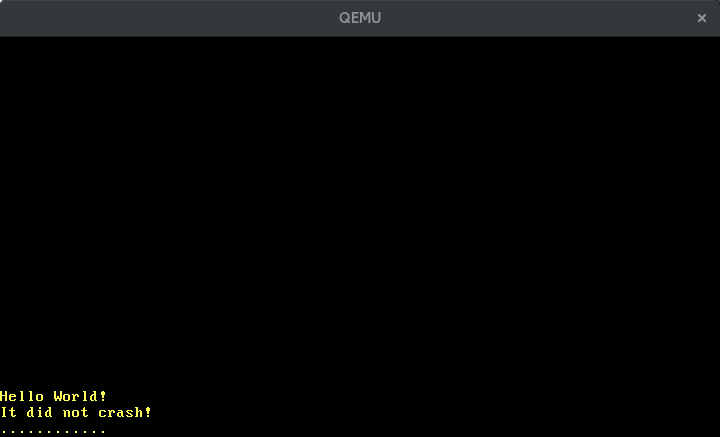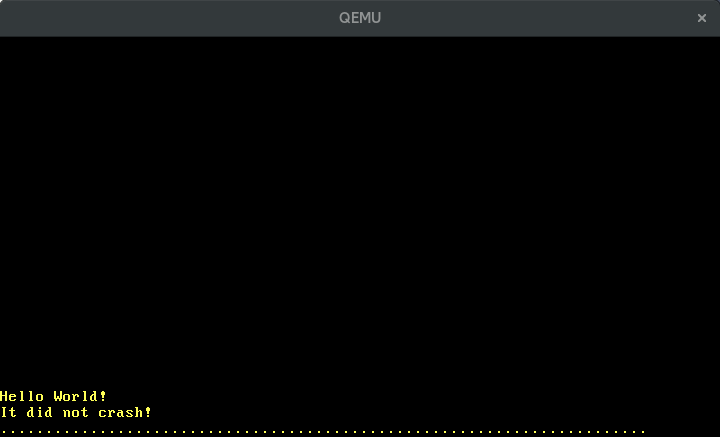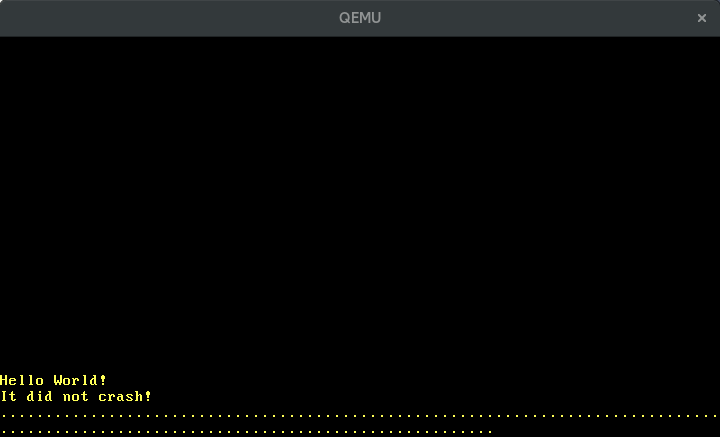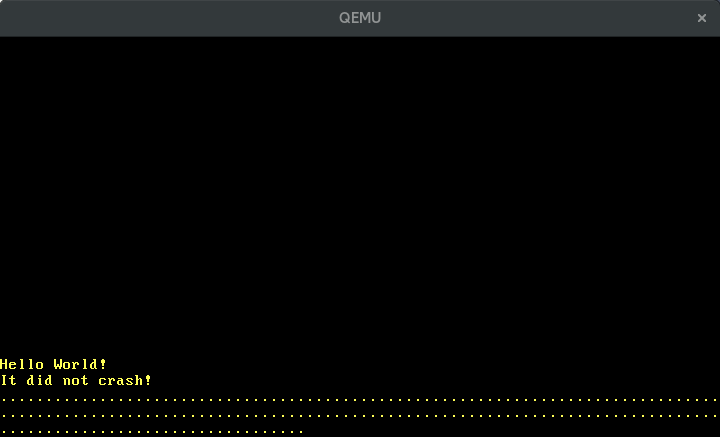
🔗Configurando o Timer
O timer de hardware que usamos é chamado de Programmable Interval Timer, ou PIT, resumidamente. Como o nome diz, é possível configurar o intervalo entre duas interrupções. Não entraremos em detalhes aqui porque mudaremos em breve para o APIC timer, mas a wiki do OSDev tem um artigo extenso sobre configurando o PIT.
🔗Deadlocks
Agora temos uma forma de concorrência em nosso kernel: As interrupções de timer ocorrem assincronamente, então podem interromper nossa função _start a qualquer momento. Felizmente, o sistema de ownership de Rust previne muitos tipos de bugs relacionados à concorrência em tempo de compilação. Uma exceção notável são deadlocks. Deadlocks ocorrem se uma thread tenta adquirir um lock que nunca se tornará livre. Assim, a thread trava indefinidamente.
Já podemos provocar um deadlock em nosso kernel. Lembre-se, nossa macro println chama a função vga_buffer::_print, que trava um WRITER global usando um spinlock:
// em src/vga_buffer.rs
[…]
#[doc(hidden)]
pub fn _print(args: fmt::Arguments) {
use core::fmt::Write;
WRITER.lock().write_fmt(args).unwrap();
}
Ela trava o WRITER, chama write_fmt nele, e implicitamente o destrava no final da função. Agora imagine que uma interrupção ocorre enquanto o WRITER está travado e o manipulador de interrupção tenta imprimir algo também:
| Passo de Tempo | _start | interrupt_handler |
|---|---|---|
| 0 | chama println! | |
| 1 | print trava WRITER | |
| 2 | interrupção ocorre, manipulador começa a executar | |
| 3 | chama println! | |
| 4 | print tenta travar WRITER (já travado) | |
| 5 | print tenta travar WRITER (já travado) | |
| … | … | |
| nunca | destravar WRITER |
O WRITER está travado, então o manipulador de interrupção espera até que se torne livre. Mas isso nunca acontece, porque a função _start só continua a executar após o manipulador de interrupção retornar. Assim, o sistema inteiro trava.
🔗Provocando um Deadlock
Podemos facilmente provocar tal deadlock em nosso kernel imprimindo algo no loop no final de nossa função _start:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
[…]
loop {
use blog_os::print;
print!("-"); // novo
}
}
Quando o executamos no QEMU, obtemos uma saída da forma:
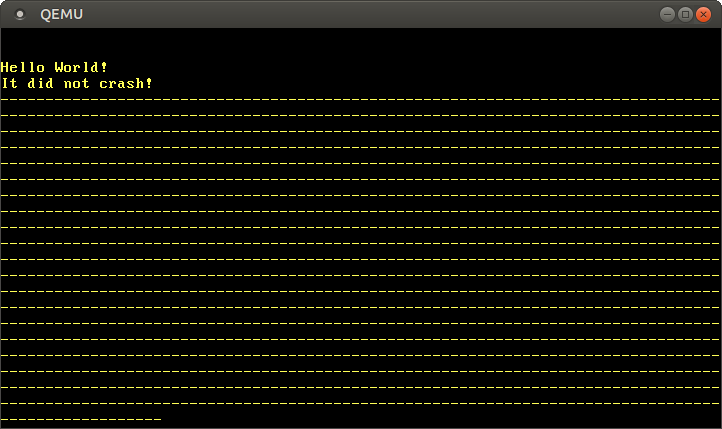
Vemos que apenas um número limitado de hífens são impressos até que a primeira interrupção de timer ocorre. Então o sistema trava porque o manipulador de interrupção de timer entra em deadlock quando tenta imprimir um ponto. Esta é a razão pela qual não vemos pontos na saída acima.
O número real de hífens varia entre execuções porque a interrupção de timer ocorre assincronamente. Este não-determinismo é o que torna bugs relacionados à concorrência tão difíceis de depurar.
🔗Corrigindo o Deadlock
Para evitar este deadlock, podemos desativar interrupções enquanto o Mutex está travado:
// em src/vga_buffer.rs
/// Imprime a string formatada dada no buffer de texto VGA
/// através da instância global `WRITER`.
#[doc(hidden)]
pub fn _print(args: fmt::Arguments) {
use core::fmt::Write;
use x86_64::instructions::interrupts; // novo
interrupts::without_interrupts(|| { // novo
WRITER.lock().write_fmt(args).unwrap();
});
}
A função without_interrupts recebe um closure e o executa em um ambiente livre de interrupções. Usamos isso para garantir que nenhuma interrupção pode ocorrer enquanto o Mutex está travado. Quando executamos nosso kernel agora, vemos que ele continua executando sem travar. (Ainda não notamos nenhum ponto, mas isso é porque eles estão rolando rápido demais. Tente diminuir a velocidade da impressão, por exemplo, colocando um for _ in 0..10000 {} dentro do loop.)
Podemos aplicar a mesma mudança à nossa função de impressão serial para garantir que nenhum deadlock ocorra com ela também:
// em src/serial.rs
#[doc(hidden)]
pub fn _print(args: ::core::fmt::Arguments) {
use core::fmt::Write;
use x86_64::instructions::interrupts; // novo
interrupts::without_interrupts(|| { // novo
SERIAL1
.lock()
.write_fmt(args)
.expect("Impressão para serial falhou");
});
}
Note que desativar interrupções não deve ser uma solução geral. O problema é que isso aumenta a latência de interrupção no pior caso, isto é, o tempo até o sistema reagir a uma interrupção. Portanto, interrupções devem ser desativadas apenas por um tempo muito curto.
🔗Corrigindo uma Race Condition
Se você executar cargo test, pode ver o teste test_println_output falhar:
> cargo test --lib
[…]
Running 4 tests
test_breakpoint_exception...[ok]
test_println... [ok]
test_println_many... [ok]
test_println_output... [failed]
Error: panicked at 'assertion failed: `(left == right)`
left: `'.'`,
right: `'S'`', src/vga_buffer.rs:205:9
A razão é uma race condition entre o teste e nosso manipulador de timer. Lembre-se, o teste se parece com isto:
// em src/vga_buffer.rs
#[test_case]
fn test_println_output() {
let s = "Uma string de teste que cabe em uma única linha";
println!("{}", s);
for (i, c) in s.chars().enumerate() {
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
}
O teste imprime uma string no buffer VGA e então verifica a saída iterando manualmente pelo array buffer_chars. A race condition ocorre porque o manipulador de interrupção de timer pode executar entre o println e a leitura dos caracteres de tela. Note que isso não é uma data race perigosa, que Rust previne completamente em tempo de compilação. Veja o Rustonomicon para detalhes.
Para corrigir isso, precisamos manter o WRITER travado pela duração completa do teste, para que o manipulador de timer não possa escrever um . na tela no meio. O teste corrigido se parece com isto:
// em src/vga_buffer.rs
#[test_case]
fn test_println_output() {
use core::fmt::Write;
use x86_64::instructions::interrupts;
let s = "Uma string de teste que cabe em uma única linha";
interrupts::without_interrupts(|| {
let mut writer = WRITER.lock();
writeln!(writer, "\n{}", s).expect("writeln falhou");
for (i, c) in s.chars().enumerate() {
let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
});
}
Realizamos as seguintes mudanças:
- Mantemos o writer travado pelo teste completo usando o método
lock()explicitamente. Em vez deprintln, usamos a macrowritelnque permite imprimir em um writer já travado. - Para evitar outro deadlock, desativamos interrupções pela duração do teste. Caso contrário, o teste poderia ser interrompido enquanto o writer ainda está travado.
- Como o manipulador de interrupção de timer ainda pode executar antes do teste, imprimimos uma nova linha adicional
\nantes de imprimir a strings. Desta forma, evitamos falha do teste quando o manipulador de timer já imprimiu alguns caracteres.na linha atual.
Com as mudanças acima, cargo test agora tem sucesso deterministicamente novamente.
Esta foi uma race condition muito inofensiva que causou apenas uma falha de teste. Como você pode imaginar, outras race conditions podem ser muito mais difíceis de depurar devido à sua natureza não-determinística. Felizmente, Rust nos previne de data races, que são a classe mais séria de race conditions, já que podem causar todo tipo de comportamento indefinido, incluindo crashes de sistema e corrupções silenciosas de memória.
🔗A Instrução hlt
Até agora, usamos uma simples instrução de loop vazio no final de nossas funções _start e panic. Isso faz a CPU girar infinitamente, e assim funciona como esperado. Mas também é muito ineficiente, porque a CPU continua executando a velocidade máxima mesmo que não haja trabalho a fazer. Você pode ver este problema em seu gerenciador de tarefas quando executa seu kernel: O processo QEMU precisa de perto de 100% de CPU o tempo todo.
O que realmente queremos fazer é parar a CPU até a próxima interrupção chegar. Isso permite que a CPU entre em um estado de sono no qual consome muito menos energia. A instrução hlt faz exatamente isso. Vamos usar esta instrução para criar um loop infinito eficiente em energia:
// em src/lib.rs
pub fn hlt_loop() -> ! {
loop {
x86_64::instructions::hlt();
}
}
A função instructions::hlt é apenas um wrapper fino em torno da instrução assembly. Ela é segura porque não há forma de comprometer a segurança de memória.
Agora podemos usar este hlt_loop em vez dos loops infinitos em nossas funções _start e panic:
// em src/main.rs
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
[…]
println!("Não crashou!");
blog_os::hlt_loop(); // novo
}
#[cfg(not(test))]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
println!("{}", info);
blog_os::hlt_loop(); // novo
}
Vamos atualizar nosso lib.rs também:
// em src/lib.rs
/// Ponto de entrada para `cargo test`
#[cfg(test)]
#[unsafe(no_mangle)]
pub extern "C" fn _start() -> ! {
init();
test_main();
hlt_loop(); // novo
}
pub fn test_panic_handler(info: &PanicInfo) -> ! {
serial_println!("[failed]\n");
serial_println!("Error: {}\n", info);
exit_qemu(QemuExitCode::Failed);
hlt_loop(); // novo
}
Quando executamos nosso kernel agora no QEMU, vemos um uso de CPU muito menor.
🔗Entrada de Teclado
Agora que somos capazes de manipular interrupções de dispositivos externos, finalmente podemos adicionar suporte para entrada de teclado. Isso nos permitirá interagir com nosso kernel pela primeira vez.
Como o timer de hardware, o controlador de teclado já está habilitado por padrão. Então quando você pressiona uma tecla, o controlador de teclado envia uma interrupção para o PIC, que a encaminha para a CPU. A CPU procura por uma função manipuladora na IDT, mas a entrada correspondente está vazia. Portanto, ocorre um double fault.
Então vamos adicionar uma função manipuladora para a interrupção de teclado. É bem similar a como definimos o manipulador para a interrupção de timer; apenas usa um número de interrupção diferente:
// em src/interrupts.rs
#[derive(Debug, Clone, Copy)]
#[repr(u8)]
pub enum InterruptIndex {
Timer = PIC_1_OFFSET,
Keyboard, // novo
}
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
[…]
// novo
idt[InterruptIndex::Keyboard.as_usize()]
.set_handler_fn(keyboard_interrupt_handler);
idt
};
}
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!("k");
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
Como vemos do gráfico acima, o teclado usa a linha 1 do PIC primário. Isso significa que ele chega à CPU como interrupção 33 (1 + offset 32). Adicionamos este índice como uma nova variante Keyboard ao enum InterruptIndex. Não precisamos especificar o valor explicitamente, já que ele assume o valor anterior mais um por padrão, que também é 33. No manipulador de interrupção, imprimimos um k e enviamos o sinal end of interrupt para o controlador de interrupção.
Agora vemos que um k aparece na tela quando pressionamos uma tecla. No entanto, isso só funciona para a primeira tecla que pressionamos. Mesmo se continuarmos a pressionar teclas, nenhum k adicional aparece na tela. Isso ocorre porque o controlador de teclado não enviará outra interrupção até lermos o chamado scancode da tecla pressionada.
🔗Lendo os Scancodes
Para descobrir qual tecla foi pressionada, precisamos consultar o controlador de teclado. Fazemos isso lendo da porta de dados do controlador PS/2, que é a porta I/O com o número 0x60:
// em src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
print!("{}", scancode);
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
Usamos o tipo Port da crate x86_64 para ler um byte da porta de dados do teclado. Este byte é chamado de scancode e representa o pressionamento/liberação de tecla. Ainda não fazemos nada com o scancode, apenas o imprimimos na tela:
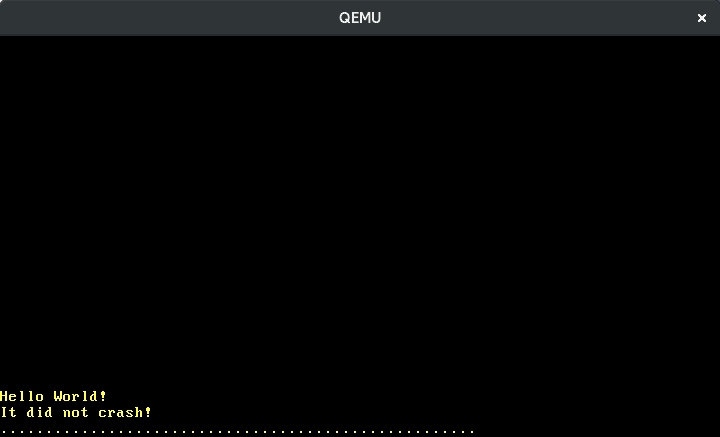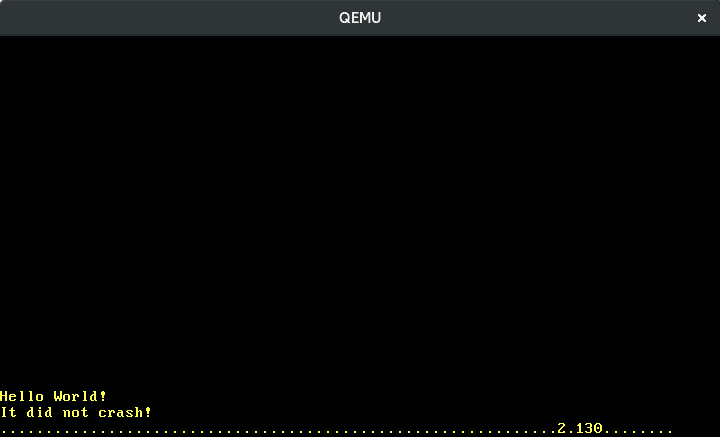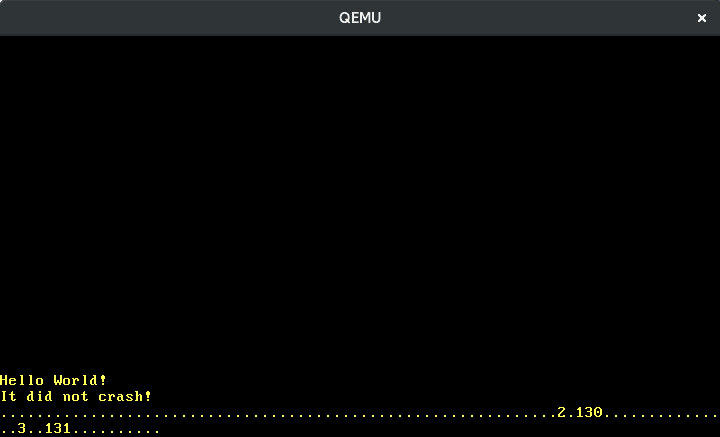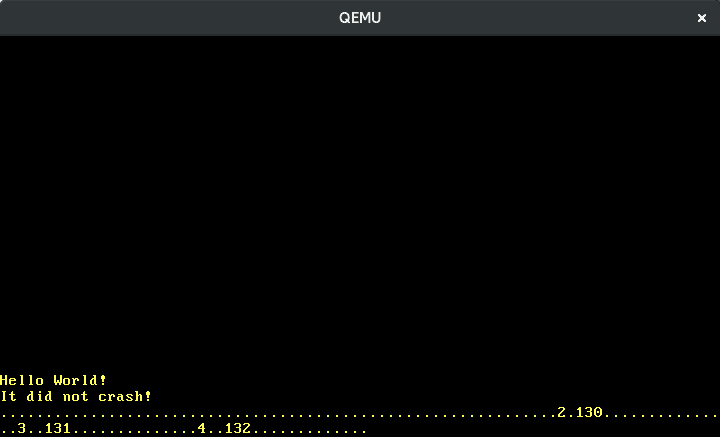
A imagem acima me mostra digitando lentamente “123”. Vemos que teclas adjacentes têm scancodes adjacentes e que pressionar uma tecla causa um scancode diferente de liberá-la. Mas como traduzimos exatamente os scancodes para as ações reais de tecla?
🔗Interpretando os Scancodes
Existem três padrões diferentes para o mapeamento entre scancodes e teclas, os chamados conjuntos de scancode. Todos os três remontam aos teclados de computadores IBM antigos: o IBM XT, o IBM 3270 PC, e o IBM AT. Felizmente, computadores posteriores não continuaram a tendência de definir novos conjuntos de scancode, mas em vez disso emularam os conjuntos existentes e os estenderam. Hoje, a maioria dos teclados pode ser configurada para emular qualquer um dos três conjuntos.
Por padrão, teclados PS/2 emulam o conjunto de scancode 1 (“XT”). Neste conjunto, os 7 bits inferiores de um byte de scancode definem a tecla, e o bit mais significativo define se é um pressionamento (“0”) ou uma liberação (“1”). Teclas que não estavam presentes no IBM XT original, como a tecla enter no teclado numérico, geram dois scancodes em sucessão: um byte de escape 0xe0 e então um byte representando a tecla. Para uma lista de todos os scancodes do conjunto 1 e suas teclas correspondentes, confira a Wiki OSDev.
Para traduzir os scancodes para teclas, podemos usar uma instrução match:
// em src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
// novo
let key = match scancode {
0x02 => Some('1'),
0x03 => Some('2'),
0x04 => Some('3'),
0x05 => Some('4'),
0x06 => Some('5'),
0x07 => Some('6'),
0x08 => Some('7'),
0x09 => Some('8'),
0x0a => Some('9'),
0x0b => Some('0'),
_ => None,
};
if let Some(key) = key {
print!("{}", key);
}
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
O código acima traduz pressionamentos das teclas numéricas 0-9 e ignora todas as outras teclas. Ele usa uma instrução match para atribuir um caractere ou None a cada scancode. Então usa if let para desestruturar o key opcional. Ao usar o mesmo nome de variável key no padrão, sombreamos a declaração anterior, que é um padrão comum para desestruturar tipos Option em Rust.
Agora podemos escrever números:
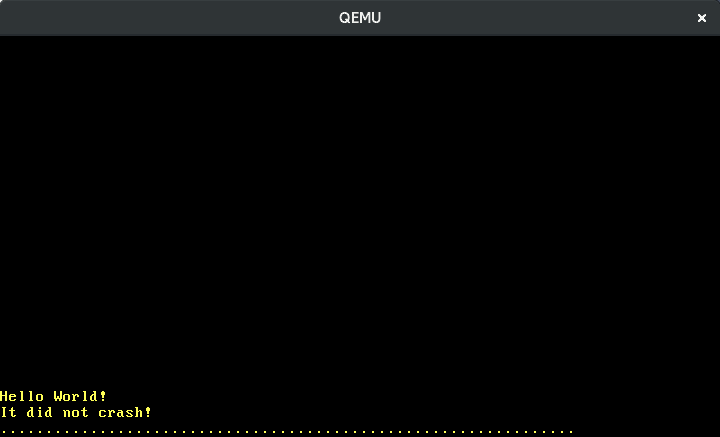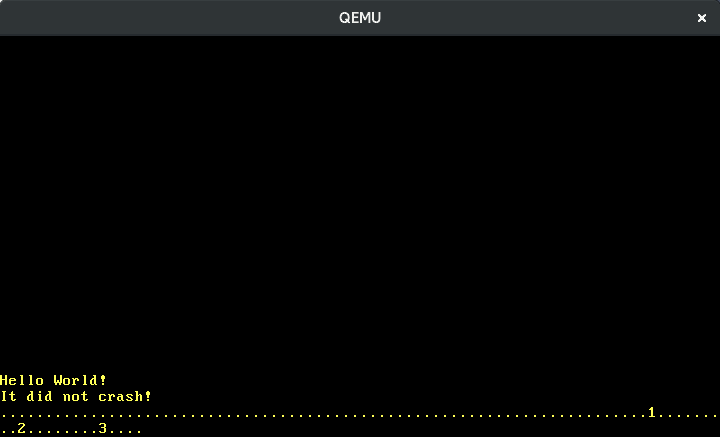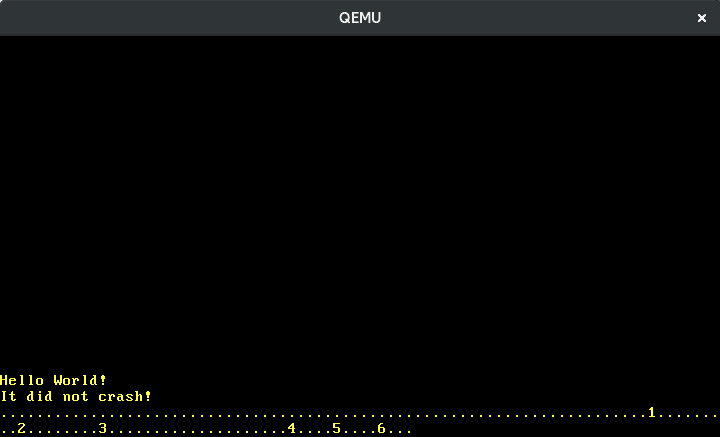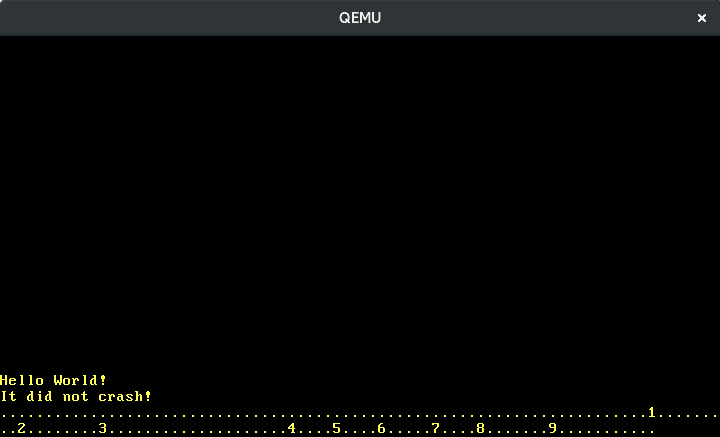
Traduzir as outras teclas funciona da mesma forma. Felizmente, existe uma crate chamada pc-keyboard para traduzir scancodes dos conjuntos de scancode 1 e 2, então não precisamos implementar isso nós mesmos. Para usar a crate, a adicionamos ao nosso Cargo.toml e a importamos em nosso lib.rs:
# em Cargo.toml
[dependencies]
pc-keyboard = "0.7.0"
Agora podemos usar esta crate para reescrever nosso keyboard_interrupt_handler:
// em/src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use spin::Mutex;
use x86_64::instructions::port::Port;
lazy_static! {
static ref KEYBOARD: Mutex<Keyboard<layouts::Us104Key, ScancodeSet1>> =
Mutex::new(Keyboard::new(ScancodeSet1::new(),
layouts::Us104Key, HandleControl::Ignore)
);
}
let mut keyboard = KEYBOARD.lock();
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
Usamos a macro lazy_static para criar um objeto Keyboard estático protegido por um Mutex. Inicializamos o Keyboard com um layout de teclado americano e o conjunto de scancode 1. O parâmetro HandleControl permite mapear ctrl+[a-z] aos caracteres Unicode U+0001 através de U+001A. Não queremos fazer isso, então usamos a opção Ignore para manipular o ctrl como teclas normais.
Em cada interrupção, travamos o Mutex, lemos o scancode do controlador de teclado, e o passamos para o método add_byte, que traduz o scancode em um Option<KeyEvent>. O KeyEvent contém a tecla que causou o evento e se foi um evento de pressionamento ou liberação.
Para interpretar este evento de tecla, o passamos para o método process_keyevent, que traduz o evento de tecla em um caractere, se possível. Por exemplo, ele traduz um evento de pressionamento da tecla A em um caractere a minúsculo ou um caractere A maiúsculo, dependendo se a tecla shift foi pressionada.
Com este manipulador de interrupção modificado, agora podemos escrever texto:
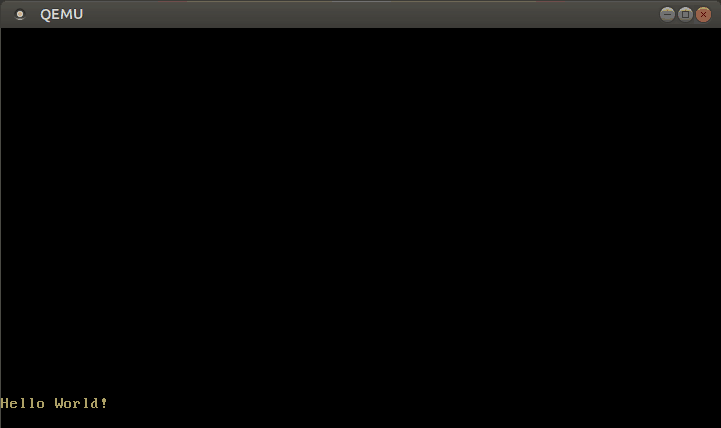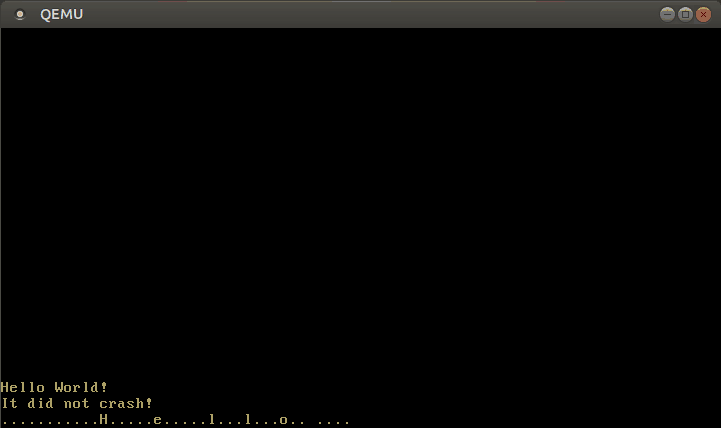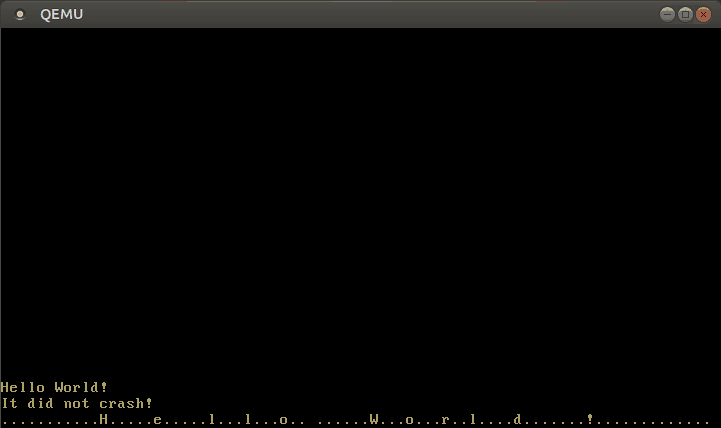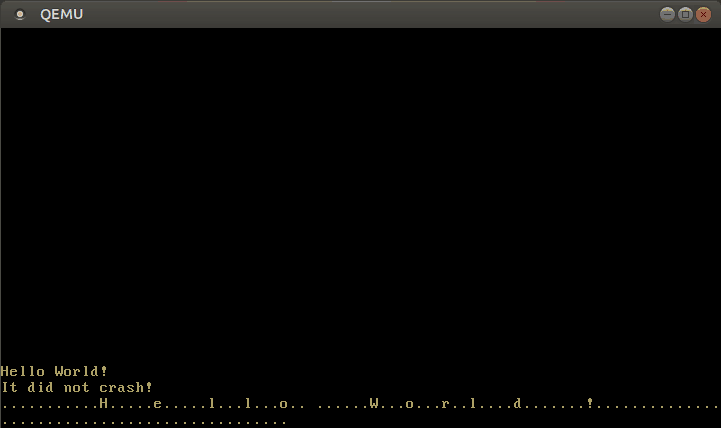
🔗Configurando o Teclado
É possível configurar alguns aspectos de um teclado PS/2, por exemplo, qual conjunto de scancode ele deve usar. Não cobriremos isso aqui porque esta postagem já está longa o suficiente, mas a Wiki do OSDev tem uma visão geral dos possíveis comandos de configuração.
🔗Resumo
Esta postagem explicou como habilitar e manipular interrupções externas. Aprendemos sobre o 8259 PIC e seu layout primário/secundário, o remapeamento dos números de interrupção, e o sinal “end of interrupt”. Implementamos manipuladores para o timer de hardware e o teclado e aprendemos sobre a instrução hlt, que para a CPU até a próxima interrupção.
Agora somos capazes de interagir com nosso kernel e temos alguns blocos fundamentais para criar um pequeno shell ou jogos simples.
🔗O Que Vem a Seguir?
Interrupções de timer são essenciais para um sistema operacional porque fornecem uma forma de interromper periodicamente o processo em execução e deixar o kernel retomar o controle. O kernel pode então mudar para um processo diferente e criar a ilusão de múltiplos processos executando em paralelo.
Mas antes de podermos criar processos ou threads, precisamos de uma forma de alocar memória para eles. As próximas postagens explorarão gerenciamento de memória para fornecer este bloco fundamental.
Comentários
Teve algum problema, quer deixar um feedback ou discutir mais ideias? Fique à vontade para deixar um comentário aqui! Por favor, use o inglês e siga o código de conduta do Rust. Este tópico de comentários está diretamente vinculado a uma discussão no GitHub, então você também pode comentar lá se preferir.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor, deixe seus comentários em inglês se possível.