Async/Await
Conteúdo Traduzido: Esta é uma tradução comunitária do post Async/Await. Pode estar incompleta, desatualizada ou conter erros. Por favor, reporte qualquer problema!
Traduzido por @richarddalves.
Neste post, exploramos multitarefa cooperativa e a funcionalidade async/await do Rust. Fazemos uma análise detalhada de como async/await funciona em Rust, incluindo o design da trait Future, a transformação em máquina de estados e pinning. Então adicionamos suporte básico para async/await ao nosso kernel criando uma tarefa assíncrona de teclado e um executor básico.
Este blog é desenvolvido abertamente no GitHub. Se você tiver algum problema ou dúvida, abra um issue lá. Você também pode deixar comentários na parte inferior. O código-fonte completo desta publicação pode ser encontrado na branch post-12.
Tabela de Conteúdos
🔗Multitarefa
Uma das funcionalidades fundamentais da maioria dos sistemas operacionais é multitarefa, que é a capacidade de executar múltiplas tarefas concorrentemente. Por exemplo, você provavelmente tem outros programas abertos enquanto olha este post, como um editor de texto ou uma janela de terminal. Mesmo se você tiver apenas uma janela de navegador aberta, provavelmente existem várias tarefas em segundo plano gerenciando suas janelas da área de trabalho, verificando atualizações ou indexando arquivos.
Embora pareça que todas as tarefas estão sendo executadas em paralelo, apenas uma única tarefa pode ser executada em um núcleo de CPU por vez. Para criar a ilusão de que as tarefas estão sendo executadas em paralelo, o sistema operacional alterna rapidamente entre as tarefas ativas para que cada uma possa fazer um pouco de progresso. Como os computadores são rápidos, não notamos essas alternâncias na maior parte do tempo.
Enquanto CPUs de núcleo único podem executar apenas uma tarefa por vez, CPUs multi-core podem executar múltiplas tarefas de forma verdadeiramente paralela. Por exemplo, uma CPU com 8 núcleos pode executar 8 tarefas ao mesmo tempo. Explicaremos como configurar CPUs multi-core em um post futuro. Para este post, focaremos em CPUs de núcleo único por simplicidade. (Vale notar que todas as CPUs multi-core começam com apenas um único núcleo ativo, então podemos tratá-las como CPUs de núcleo único por enquanto.)
Existem duas formas de multitarefa: Multitarefa cooperativa requer que as tarefas regularmente cedam o controle da CPU para que outras tarefas possam progredir. Multitarefa preemptiva usa funcionalidades do sistema operacional para alternar threads em pontos arbitrários no tempo, pausando-as forçadamente. A seguir, exploraremos as duas formas de multitarefa em mais detalhes e discutiremos suas respectivas vantagens e desvantagens.
🔗Multitarefa Preemptiva
A ideia por trás da multitarefa preemptiva é que o sistema operacional controla quando alternar tarefas. Para isso, ele utiliza o fato de que recupera o controle da CPU em cada interrupção. Isso torna possível alternar tarefas sempre que uma nova entrada está disponível para o sistema. Por exemplo, seria possível alternar tarefas quando o mouse é movido ou um pacote de rede chega. O sistema operacional também pode determinar o tempo exato que uma tarefa tem permissão para executar configurando um temporizador de hardware para enviar uma interrupção após esse tempo.
O gráfico seguinte ilustra o processo de alternância de tarefas em uma interrupção de hardware:

Na primeira linha, a CPU está executando a tarefa A1 do programa A. Todas as outras tarefas estão pausadas. Na segunda linha, uma interrupção de hardware chega na CPU. Como descrito no post Interrupções de Hardware, a CPU imediatamente para a execução da tarefa A1 e salta para o manipulador de interrupção definido na tabela de descritores de interrupção (IDT). Através deste manipulador de interrupção, o sistema operacional agora tem controle da CPU novamente, o que permite alternar para a tarefa B1 em vez de continuar a tarefa A1.
🔗Salvando o Estado
Como as tarefas são interrompidas em pontos arbitrários no tempo, elas podem estar no meio de alguns cálculos. Para poder retomá-las mais tarde, o sistema operacional deve fazer backup do estado completo da tarefa, incluindo sua pilha de chamadas e os valores de todos os registradores da CPU. Este processo é chamado de troca de contexto.
Como a pilha de chamadas pode ser muito grande, o sistema operacional normalmente configura uma pilha de chamadas separada para cada tarefa em vez de fazer backup do conteúdo da pilha de chamadas em cada alternância de tarefa. Tal tarefa com sua própria pilha é chamada de thread de execução ou thread para abreviar. Ao usar uma pilha separada para cada tarefa, apenas o conteúdo dos registradores precisa ser salvo em uma troca de contexto (incluindo o contador de programa e o ponteiro de pilha). Esta abordagem minimiza a sobrecarga de desempenho de uma troca de contexto, o que é muito importante já que trocas de contexto geralmente ocorrem até 100 vezes por segundo.
🔗Discussão
A principal vantagem da multitarefa preemptiva é que o sistema operacional pode controlar totalmente o tempo de execução permitido de uma tarefa. Desta forma, ele pode garantir que cada tarefa receba uma parcela justa do tempo de CPU, sem a necessidade de confiar que as tarefas cooperarão. Isto é especialmente importante ao executar tarefas de terceiros ou quando múltiplos usuários compartilham um sistema.
A desvantagem da preempção é que cada tarefa requer sua própria pilha. Comparado a uma pilha compartilhada, isso resulta em maior uso de memória por tarefa e frequentemente limita o número de tarefas no sistema. Outra desvantagem é que o sistema operacional sempre tem que salvar o estado completo dos registradores da CPU em cada troca de tarefa, mesmo que a tarefa tenha usado apenas um pequeno subconjunto dos registradores.
Multitarefa preemptiva e threads são componentes fundamentais de um sistema operacional porque tornam possível executar programas de espaço de usuário não confiáveis. Discutiremos esses conceitos em detalhes completos em posts futuros. Para este post, no entanto, focaremos na multitarefa cooperativa, que também fornece capacidades úteis para o nosso kernel.
🔗Multitarefa Cooperativa
Em vez de pausar forçadamente as tarefas em execução em pontos arbitrários no tempo, a multitarefa cooperativa permite que cada tarefa execute até que ela voluntariamente ceda o controle da CPU. Isso permite que as tarefas se pausem em pontos convenientes no tempo, por exemplo, quando precisam esperar por uma operação de E/S de qualquer forma.
Multitarefa cooperativa é frequentemente usada no nível da linguagem, como na forma de corrotinas ou async/await. A ideia é que o programador ou o compilador insira operações de yield no programa, que cedem o controle da CPU e permitem que outras tarefas executem. Por exemplo, um yield poderia ser inserido após cada iteração de um loop complexo.
É comum combinar multitarefa cooperativa com operações assíncronas. Em vez de esperar até que uma operação seja finalizada e impedir outras tarefas de executar durante esse tempo, operações assíncronas retornam um status “não pronto” se a operação ainda não foi finalizada. Neste caso, a tarefa em espera pode executar uma operação de yield para permitir que outras tarefas executem.
🔗Salvando o Estado
Como as tarefas definem seus próprios pontos de pausa, elas não precisam que o sistema operacional salve seu estado. Em vez disso, elas podem salvar exatamente o estado de que precisam para continuar antes de se pausarem, o que frequentemente resulta em melhor desempenho. Por exemplo, uma tarefa que acabou de finalizar um cálculo complexo pode precisar fazer backup apenas do resultado final do cálculo, já que não precisa mais dos resultados intermediários.
Implementações de tarefas cooperativas com suporte da linguagem são frequentemente até capazes de fazer backup das partes necessárias da pilha de chamadas antes de pausar. Como exemplo, a implementação async/await do Rust armazena todas as variáveis locais que ainda são necessárias em uma struct gerada automaticamente (veja abaixo). Ao fazer backup das partes relevantes da pilha de chamadas antes de pausar, todas as tarefas podem compartilhar uma única pilha de chamadas, o que resulta em consumo de memória muito menor por tarefa. Isso torna possível criar um número quase arbitrário de tarefas cooperativas sem ficar sem memória.
🔗Discussão
A desvantagem da multitarefa cooperativa é que uma tarefa não cooperativa pode potencialmente executar por um tempo ilimitado. Assim, uma tarefa maliciosa ou com bugs pode impedir outras tarefas de executar e desacelerar ou até bloquear todo o sistema. Por esta razão, multitarefa cooperativa deve ser usada apenas quando todas as tarefas são conhecidas por cooperar. Como contraexemplo, não é uma boa ideia fazer o sistema operacional depender da cooperação de programas arbitrários de nível de usuário.
No entanto, os fortes benefícios de desempenho e memória da multitarefa cooperativa tornam-na uma boa abordagem para uso dentro de um programa, especialmente em combinação com operações assíncronas. Como um kernel de sistema operacional é um programa crítico em termos de desempenho que interage com hardware assíncrono, multitarefa cooperativa parece uma boa abordagem para implementar concorrência.
🔗Async/Await em Rust
A linguagem Rust fornece suporte de primeira classe para multitarefa cooperativa na forma de async/await. Antes que possamos explorar o que é async/await e como funciona, precisamos entender como futures e programação assíncrona funcionam em Rust.
🔗Futures
Uma future representa um valor que pode ainda não estar disponível. Isso poderia ser, por exemplo, um inteiro que é computado por outra tarefa ou um arquivo que está sendo baixado da rede. Em vez de esperar até que o valor esteja disponível, futures tornam possível continuar a execução até que o valor seja necessário.
🔗Exemplo
O conceito de futures é melhor ilustrado com um pequeno exemplo:

Este diagrama de sequência mostra uma função main que lê um arquivo do sistema de arquivos e então chama uma função foo. Este processo é repetido duas vezes: uma vez com uma chamada read_file síncrona e uma vez com uma chamada async_read_file assíncrona.
Com a chamada síncrona, a função main precisa esperar até que o arquivo seja carregado do sistema de arquivos. Somente então ela pode chamar a função foo, o que requer que ela espere novamente pelo resultado.
Com a chamada async_read_file assíncrona, o sistema de arquivos retorna diretamente uma future e carrega o arquivo assincronamente em segundo plano. Isso permite que a função main chame foo muito mais cedo, que então executa em paralelo com o carregamento do arquivo. Neste exemplo, o carregamento do arquivo até termina antes que foo retorne, então main pode trabalhar diretamente com o arquivo sem mais espera após foo retornar.
🔗Futures em Rust
Em Rust, futures são representadas pela trait Future, que se parece com isto:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>;
}
O tipo associado Output especifica o tipo do valor assíncrono. Por exemplo, a função async_read_file no diagrama acima retornaria uma instância Future com Output definido como File.
O método poll permite verificar se o valor já está disponível. Ele retorna um enum Poll, que se parece com isto:
pub enum Poll<T> {
Ready(T),
Pending,
}
Quando o valor já está disponível (por exemplo, o arquivo foi totalmente lido do disco), ele é retornado encapsulado na variante Ready. Caso contrário, a variante Pending é retornada, que sinaliza ao chamador que o valor ainda não está disponível.
O método poll recebe dois argumentos: self: Pin<&mut Self> e cx: &mut Context. O primeiro se comporta de forma similar a uma referência normal &mut self, exceto que o valor Self é fixado em sua localização na memória. Entender Pin e por que é necessário é difícil sem entender como async/await funciona primeiro. Portanto, explicaremos isso mais tarde neste post.
O propósito do parâmetro cx: &mut Context é passar uma instância Waker para a tarefa assíncrona, por exemplo, o carregamento do arquivo do sistema de arquivos. Este Waker permite que a tarefa assíncrona sinalize que ela (ou uma parte dela) foi finalizada, por exemplo, que o arquivo foi carregado do disco. Como a tarefa principal sabe que será notificada quando a Future estiver pronta, ela não precisa chamar poll repetidamente. Explicaremos este processo em mais detalhes mais tarde neste post quando implementarmos nosso próprio tipo waker.
🔗Trabalhando com Futures
Agora sabemos como futures são definidas e entendemos a ideia básica por trás do método poll. No entanto, ainda não sabemos como trabalhar efetivamente com futures. O problema é que futures representam os resultados de tarefas assíncronas, que podem ainda não estar disponíveis. Na prática, no entanto, frequentemente precisamos desses valores diretamente para cálculos adicionais. Então a questão é: Como podemos recuperar eficientemente o valor de uma future quando precisamos dele?
🔗Esperando por Futures
Uma resposta possível é esperar até que uma future se torne pronta. Isso poderia se parecer com algo assim:
let future = async_read_file("foo.txt");
let file_content = loop {
match future.poll(…) {
Poll::Ready(value) => break value,
Poll::Pending => {}, // não faz nada
}
}
Aqui nós ativamente esperamos pela future chamando poll repetidamente em um loop. Os argumentos para poll não importam aqui, então os omitimos. Embora esta solução funcione, ela é muito ineficiente porque mantemos a CPU ocupada até que o valor se torne disponível.
Uma abordagem mais eficiente poderia ser bloquear a thread atual até que a future se torne disponível. Isso é, claro, possível apenas se você tiver threads, então esta solução não funciona para o nosso kernel, pelo menos ainda não. Mesmo em sistemas onde o bloqueio é suportado, frequentemente não é desejado porque transforma uma tarefa assíncrona em uma tarefa síncrona novamente, inibindo assim os benefícios de desempenho potenciais de tarefas paralelas.
🔗Combinadores de Future
Uma alternativa a esperar é usar combinadores de future. Combinadores de future são métodos como map que permitem encadear e combinar futures juntas, similar aos métodos da trait Iterator. Em vez de esperar pela future, esses combinadores retornam uma future eles mesmos, que aplica a operação de mapeamento em poll.
Como exemplo, um simples combinador string_len para converter uma Future<Output = String> em uma Future<Output = usize> poderia se parecer com isto:
struct StringLen<F> {
inner_future: F,
}
impl<F> Future for StringLen<F> where F: Future<Output = String> {
type Output = usize;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<T> {
match self.inner_future.poll(cx) {
Poll::Ready(s) => Poll::Ready(s.len()),
Poll::Pending => Poll::Pending,
}
}
}
fn string_len(string: impl Future<Output = String>)
-> impl Future<Output = usize>
{
StringLen {
inner_future: string,
}
}
// Uso
fn file_len() -> impl Future<Output = usize> {
let file_content_future = async_read_file("foo.txt");
string_len(file_content_future)
}
Este código não funciona perfeitamente porque não lida com pinning, mas é suficiente como exemplo. A ideia básica é que a função string_len encapsula uma determinada instância Future em uma nova struct StringLen, que também implementa Future. Quando a future encapsulada é consultada, ela consulta a future interna. Se o valor ainda não está pronto, Poll::Pending é retornado da future encapsulada também. Se o valor está pronto, a string é extraída da variante Poll::Ready e seu comprimento é calculado. Depois, é encapsulado em Poll::Ready novamente e retornado.
Com esta função string_len, podemos calcular o comprimento de uma string assíncrona sem esperar por ela. Como a função retorna uma Future novamente, o chamador não pode trabalhar diretamente no valor retornado, mas precisa usar funções combinadoras novamente. Desta forma, todo o grafo de chamadas se torna assíncrono e podemos esperar por múltiplas futures eficientemente de uma vez em algum ponto, por exemplo, na função main.
Como escrever funções combinadoras manualmente é difícil, elas são frequentemente fornecidas por bibliotecas. Embora a biblioteca padrão do Rust ainda não forneça métodos combinadores, a crate semi-oficial (e compatível com no_std) futures fornece. Sua trait FutureExt fornece métodos combinadores de alto nível como map ou then, que podem ser usados para manipular o resultado com closures arbitrárias.
🔗Vantagens
A grande vantagem dos combinadores de future é que eles mantêm as operações assíncronas. Em combinação com interfaces de E/S assíncronas, esta abordagem pode levar a desempenho muito alto. O fato de que combinadores de future são implementados como structs normais com implementações de trait permite que o compilador os otimize excessivamente. Para mais detalhes, veja o post Zero-cost futures in Rust, que anunciou a adição de futures ao ecossistema do Rust.
🔗Desvantagens
Embora combinadores de future tornem possível escrever código muito eficiente, eles podem ser difíceis de usar em algumas situações por causa do sistema de tipos e da interface baseada em closures. Por exemplo, considere código como este:
fn example(min_len: usize) -> impl Future<Output = String> {
async_read_file("foo.txt").then(move |content| {
if content.len() < min_len {
Either::Left(async_read_file("bar.txt").map(|s| content + &s))
} else {
Either::Right(future::ready(content))
}
})
}
Aqui lemos o arquivo foo.txt e então usamos o combinador then para encadear uma segunda future baseada no conteúdo do arquivo. Se o comprimento do conteúdo é menor que o min_len dado, lemos um arquivo diferente bar.txt e o anexamos a content usando o combinador map. Caso contrário, retornamos apenas o conteúdo de foo.txt.
Precisamos usar a palavra-chave move para a closure passada a then porque caso contrário haveria um erro de tempo de vida para min_len. A razão para o wrapper Either é que os blocos if e else devem sempre ter o mesmo tipo. Como retornamos diferentes tipos de future nos blocos, devemos usar o tipo wrapper para unificá-los em um único tipo. A função ready encapsula um valor em uma future que está imediatamente pronta. A função é necessária aqui porque o wrapper Either espera que o valor encapsulado implemente Future.
Como você pode imaginar, isso pode rapidamente levar a código muito complexo para projetos maiores. Fica especialmente complicado se empréstimos e diferentes tempos de vida estiverem envolvidos. Por esta razão, muito trabalho foi investido em adicionar suporte para async/await ao Rust, com o objetivo de tornar o código assíncrono radicalmente mais simples de escrever.
🔗O Padrão Async/Await
A ideia por trás de async/await é permitir que o programador escreva código que parece com código síncrono normal, mas é transformado em código assíncrono pelo compilador. Funciona baseado em duas palavras-chave async e await. A palavra-chave async pode ser usada em uma assinatura de função para transformar uma função síncrona em uma função assíncrona que retorna uma future:
async fn foo() -> u32 {
0
}
// o código acima é aproximadamente traduzido pelo compilador para:
fn foo() -> impl Future<Output = u32> {
future::ready(0)
}
Esta palavra-chave sozinha não seria tão útil. No entanto, dentro de funções async, a palavra-chave await pode ser usada para recuperar o valor assíncrono de uma future:
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
Esta função é uma tradução direta da função example de acima que usava funções combinadoras. Usando o operador .await, podemos recuperar o valor de uma future sem precisar de closures ou tipos Either. Como resultado, podemos escrever nosso código como escrevemos código síncrono normal, com a diferença de que este ainda é código assíncrono.
🔗Transformação em Máquina de Estados
Nos bastidores, o compilador converte o corpo da função async em uma máquina de estados, com cada chamada .await representando um estado diferente. Para a função example acima, o compilador cria uma máquina de estados com os seguintes quatro estados:

Cada estado representa um ponto de pausa diferente na função. Os estados “Início” e “Fim” representam a função no começo e no fim de sua execução. O estado “Esperando por foo.txt” representa que a função está atualmente esperando pelo primeiro resultado de async_read_file. Similarmente, o estado “Esperando por bar.txt” representa o ponto de pausa onde a função está esperando pelo segundo resultado de async_read_file.
A máquina de estados implementa a trait Future fazendo cada chamada poll uma possível transição de estado:

O diagrama usa setas para representar mudanças de estado e formas de diamante para representar formas alternativas. Por exemplo, se o arquivo foo.txt não está pronto, o caminho marcado com “não” é tomado e o estado “Esperando por foo.txt” é alcançado. Caso contrário, o caminho “sim” é tomado. O pequeno diamante vermelho sem legenda representa a branch if content.len() < 100 da função example.
Vemos que a primeira chamada poll inicia a função e a deixa executar até alcançar uma future que ainda não está pronta. Se todas as futures no caminho estão prontas, a função pode executar até o estado “Fim”, onde retorna seu resultado encapsulado em Poll::Ready. Caso contrário, a máquina de estados entra em um estado de espera e retorna Poll::Pending. Na próxima chamada poll, a máquina de estados então começa do último estado de espera e tenta novamente a última operação.
🔗Salvando o Estado
Para poder continuar do último estado de espera, a máquina de estados deve acompanhar internamente o estado atual. Além disso, ela deve salvar todas as variáveis de que precisa para continuar a execução na próxima chamada poll. É aqui que o compilador pode realmente brilhar: Como ele sabe quais variáveis são usadas quando, ele pode gerar automaticamente structs com exatamente as variáveis que são necessárias.
Como exemplo, o compilador gera structs como as seguintes para a função example acima:
// A função `example` novamente para que você não precise rolar para cima
async fn example(min_len: usize) -> String {
let content = async_read_file("foo.txt").await;
if content.len() < min_len {
content + &async_read_file("bar.txt").await
} else {
content
}
}
// As structs de estado geradas pelo compilador:
struct StartState {
min_len: usize,
}
struct WaitingOnFooTxtState {
min_len: usize,
foo_txt_future: impl Future<Output = String>,
}
struct WaitingOnBarTxtState {
content: String,
bar_txt_future: impl Future<Output = String>,
}
struct EndState {}
Nos estados “início” e “Esperando por foo.txt”, o parâmetro min_len precisa ser armazenado para a comparação posterior com content.len(). O estado “Esperando por foo.txt” armazena adicionalmente uma foo_txt_future, que representa a future retornada pela chamada async_read_file. Esta future precisa ser consultada novamente quando a máquina de estados continua, então ela precisa ser salva.
O estado “Esperando por bar.txt” contém a variável content para a concatenação de string posterior quando bar.txt estiver pronto. Ele também armazena uma bar_txt_future que representa o carregamento em progresso de bar.txt. A struct não contém a variável min_len porque não é mais necessária após a comparação content.len(). No estado “fim”, nenhuma variável é armazenada porque a função já executou até completar.
Lembre-se que este é apenas um exemplo do código que o compilador poderia gerar. Os nomes das structs e o layout dos campos são detalhes de implementação e podem ser diferentes.
🔗O Tipo Completo da Máquina de Estados
Embora o código exato gerado pelo compilador seja um detalhe de implementação, ajuda no entendimento imaginar como a máquina de estados gerada poderia parecer para a função example. Já definimos as structs representando os diferentes estados e contendo as variáveis necessárias. Para criar uma máquina de estados em cima delas, podemos combiná-las em um enum:
enum ExampleStateMachine {
Start(StartState),
WaitingOnFooTxt(WaitingOnFooTxtState),
WaitingOnBarTxt(WaitingOnBarTxtState),
End(EndState),
}
Definimos uma variante de enum separada para cada estado e adicionamos a struct de estado correspondente a cada variante como um campo. Para implementar as transições de estado, o compilador gera uma implementação da trait Future baseada na função example:
impl Future for ExampleStateMachine {
type Output = String; // tipo de retorno de `example`
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output> {
loop {
match self { // TODO: lidar com pinning
ExampleStateMachine::Start(state) => {…}
ExampleStateMachine::WaitingOnFooTxt(state) => {…}
ExampleStateMachine::WaitingOnBarTxt(state) => {…}
ExampleStateMachine::End(state) => {…}
}
}
}
}
O tipo Output da future é String porque é o tipo de retorno da função example. Para implementar a função poll, usamos uma expressão match no estado atual dentro de um loop. A ideia é que mudamos para o próximo estado enquanto possível e usamos um return Poll::Pending explícito quando não podemos continuar.
Para simplicidade, mostramos apenas código simplificado e não lidamos com pinning, propriedade, tempos de vida, etc. Então este e o código seguinte devem ser tratados como pseudocódigo e não usados diretamente. Claro, o código real gerado pelo compilador lida com tudo corretamente, embora possivelmente de uma forma diferente.
Para manter os trechos de código pequenos, apresentamos o código para cada braço match separadamente. Vamos começar com o estado Start:
ExampleStateMachine::Start(state) => {
// do corpo de `example`
let foo_txt_future = async_read_file("foo.txt");
// operação `.await`
let state = WaitingOnFooTxtState {
min_len: state.min_len,
foo_txt_future,
};
*self = ExampleStateMachine::WaitingOnFooTxt(state);
}
A máquina de estados está no estado Start quando está bem no início da função. Neste caso, executamos todo o código do corpo da função example até o primeiro .await. Para lidar com a operação .await, mudamos o estado da máquina de estados self para WaitingOnFooTxt, que inclui a construção da struct WaitingOnFooTxtState.
Como a expressão match self {…} é executada em um loop, a execução salta para o braço WaitingOnFooTxt em seguida:
ExampleStateMachine::WaitingOnFooTxt(state) => {
match state.foo_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(content) => {
// do corpo de `example`
if content.len() < state.min_len {
let bar_txt_future = async_read_file("bar.txt");
// operação `.await`
let state = WaitingOnBarTxtState {
content,
bar_txt_future,
};
*self = ExampleStateMachine::WaitingOnBarTxt(state);
} else {
*self = ExampleStateMachine::End(EndState);
return Poll::Ready(content);
}
}
}
}
Neste braço match, primeiro chamamos a função poll da foo_txt_future. Se não está pronta, saímos do loop e retornamos Poll::Pending. Como self permanece no estado WaitingOnFooTxt neste caso, a próxima chamada poll na máquina de estados entrará no mesmo braço match e tentará consultar a foo_txt_future novamente.
Quando a foo_txt_future está pronta, atribuímos o resultado à variável content e continuamos a executar o código da função example: Se content.len() é menor que o min_len salvo na struct de estado, o arquivo bar.txt é lido assincronamente. Novamente traduzimos a operação .await em uma mudança de estado, desta vez para o estado WaitingOnBarTxt. Como estamos executando o match dentro de um loop, a execução salta diretamente para o braço match para o novo estado depois, onde a bar_txt_future é consultada.
Caso entremos no braço else, nenhuma operação .await adicional ocorre. Alcançamos o fim da função e retornamos content encapsulado em Poll::Ready. Também mudamos o estado atual para o estado End.
O código para o estado WaitingOnBarTxt parece com isto:
ExampleStateMachine::WaitingOnBarTxt(state) => {
match state.bar_txt_future.poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(bar_txt) => {
*self = ExampleStateMachine::End(EndState);
// do corpo de `example`
return Poll::Ready(state.content + &bar_txt);
}
}
}
Similar ao estado WaitingOnFooTxt, começamos consultando a bar_txt_future. Se ainda está pendente, saímos do loop e retornamos Poll::Pending. Caso contrário, podemos executar a última operação da função example: concatenar a variável content com o resultado da future. Atualizamos a máquina de estados para o estado End e então retornamos o resultado encapsulado em Poll::Ready.
Finalmente, o código para o estado End parece com isto:
ExampleStateMachine::End(_) => {
panic!("poll chamado após Poll::Ready ter sido retornado");
}
Futures não devem ser consultadas novamente após retornarem Poll::Ready, então entramos em pânico se poll é chamado enquanto já estamos no estado End.
Agora sabemos como a máquina de estados gerada pelo compilador e sua implementação da trait Future poderiam parecer. Na prática, o compilador gera código de forma diferente. (Caso esteja interessado, a implementação é atualmente baseada em corrotinas, mas isso é apenas um detalhe de implementação.)
A última peça do quebra-cabeça é o código gerado para a própria função example. Lembre-se, o cabeçalho da função foi definido assim:
async fn example(min_len: usize) -> String
Como o corpo completo da função agora é implementado pela máquina de estados, a única coisa que a função precisa fazer é inicializar a máquina de estados e retorná-la. O código gerado para isso poderia parecer com isto:
fn example(min_len: usize) -> ExampleStateMachine {
ExampleStateMachine::Start(StartState {
min_len,
})
}
A função não tem mais um modificador async porque agora retorna explicitamente um tipo ExampleStateMachine, que implementa a trait Future. Como esperado, a máquina de estados é construída no estado Start e a struct de estado correspondente é inicializada com o parâmetro min_len.
Note que esta função não inicia a execução da máquina de estados. Esta é uma decisão de design fundamental de futures em Rust: elas não fazem nada até serem consultadas pela primeira vez.
🔗Pinning
Já tropeçamos em pinning múltiplas vezes neste post. Agora é finalmente a hora de explorar o que é pinning e por que é necessário.
🔗Structs Auto-Referenciais
Como explicado acima, a transformação da máquina de estados armazena as variáveis locais de cada ponto de pausa em uma struct. Para exemplos pequenos como nossa função example, isso foi direto e não levou a problemas. No entanto, as coisas se tornam mais difíceis quando variáveis referenciam umas às outras. Por exemplo, considere esta função:
async fn pin_example() -> i32 {
let array = [1, 2, 3];
let element = &array[2];
async_write_file("foo.txt", element.to_string()).await;
*element
}
Esta função cria um pequeno array com o conteúdo 1, 2 e 3. Ela então cria uma referência ao último elemento do array e a armazena em uma variável element. Em seguida, ela escreve assincronamente o número convertido em string para um arquivo foo.txt. Finalmente, ela retorna o número referenciado por element.
Como a função usa uma única operação await, a máquina de estados resultante tem três estados: início, fim e “esperando por escrita”. A função não recebe argumentos, então a struct para o estado de início está vazia. Como antes, a struct para o estado de fim está vazia porque a função está finalizada neste ponto. A struct para o estado “esperando por escrita” é mais interessante:
struct WaitingOnWriteState {
array: [1, 2, 3],
element: 0x1001c, // endereço do último elemento do array
}
Precisamos armazenar tanto as variáveis array quanto element porque element é necessária para o valor de retorno e array é referenciado por element. Como element é uma referência, ela armazena um ponteiro (ou seja, um endereço de memória) para o elemento referenciado. Usamos 0x1001c como um endereço de memória de exemplo aqui. Na realidade, precisa ser o endereço do último elemento do campo array, então depende de onde a struct vive na memória. Structs com tais ponteiros internos são chamadas structs auto-referenciais porque referenciam a si mesmas de um de seus campos.
🔗O Problema com Structs Auto-Referenciais
O ponteiro interno de nossa struct auto-referencial leva a um problema fundamental, que se torna aparente quando olhamos para seu layout de memória:

O campo array começa no endereço 0x10014 e o campo element no endereço 0x10020. Ele aponta para o endereço 0x1001c porque o último elemento do array vive neste endereço. Neste ponto, tudo ainda está bem. No entanto, um problema ocorre quando movemos esta struct para um endereço de memória diferente:

Movemos a struct um pouco então ela agora começa no endereço 0x10024. Isso poderia, por exemplo, acontecer quando passamos a struct como um argumento de função ou a atribuímos a uma variável de pilha diferente. O problema é que o campo element ainda aponta para o endereço 0x1001c mesmo que o último elemento array agora viva no endereço 0x1002c. Assim, o ponteiro está pendente, com o resultado de que comportamento indefinido ocorre na próxima chamada poll.
🔗Soluções Possíveis
Existem três abordagens fundamentais para resolver o problema do ponteiro pendente:
-
Atualizar o ponteiro no movimento: A ideia é atualizar o ponteiro interno sempre que a struct é movida na memória para que ainda seja válido após o movimento. Infelizmente, esta abordagem exigiria mudanças extensas ao Rust que resultariam em potencialmente enormes perdas de desempenho. A razão é que algum tipo de runtime precisaria acompanhar o tipo de todos os campos da struct e verificar em cada operação de movimento se uma atualização de ponteiro é necessária.
-
Armazenar um offset em vez de auto-referências: Para evitar a necessidade de atualizar ponteiros, o compilador poderia tentar armazenar auto-referências como offsets do início da struct. Por exemplo, o campo
elementda structWaitingOnWriteStateacima poderia ser armazenado na forma de um campoelement_offsetcom um valor de 8 porque o elemento do array para o qual a referência aponta começa 8 bytes após o início da struct. Como o offset permanece o mesmo quando a struct é movida, nenhuma atualização de campo é necessária.O problema com esta abordagem é que requer que o compilador detecte todas as auto-referências. Isso não é possível em tempo de compilação porque o valor de uma referência pode depender da entrada do usuário, então precisaríamos de um sistema de runtime novamente para analisar referências e criar corretamente as structs de estado. Isso não apenas resultaria em custos de runtime, mas também impediria certas otimizações do compilador, de modo que causaria grandes perdas de desempenho novamente.
-
Proibir mover a struct: Como vimos acima, o ponteiro pendente só ocorre quando movemos a struct na memória. Ao proibir completamente operações de movimento em structs auto-referenciais, o problema também pode ser evitado. A grande vantagem desta abordagem é que pode ser implementada no nível do sistema de tipos sem custos de runtime adicionais. A desvantagem é que coloca o ônus de lidar com operações de movimento em structs possivelmente auto-referenciais no programador.
Rust escolheu a terceira solução por causa de seu princípio de fornecer abstrações de custo zero, o que significa que abstrações não devem impor custos de runtime adicionais. A API de pinning foi proposta para este propósito na RFC 2349. No que segue, daremos uma breve visão geral desta API e explicaremos como funciona com async/await e futures.
🔗Valores de Heap
A primeira observação é que valores alocados em heap já têm um endereço de memória fixo na maior parte do tempo. Eles são criados usando uma chamada para allocate e então referenciados por um tipo de ponteiro como Box<T>. Embora mover o tipo de ponteiro seja possível, o valor de heap para o qual o ponteiro aponta permanece no mesmo endereço de memória até ser liberado através de uma chamada deallocate novamente.
Usando alocação de heap, podemos tentar criar uma struct auto-referencial:
fn main() {
let mut heap_value = Box::new(SelfReferential {
self_ptr: 0 as *const _,
});
let ptr = &*heap_value as *const SelfReferential;
heap_value.self_ptr = ptr;
println!("heap value at: {:p}", heap_value);
println!("internal reference: {:p}", heap_value.self_ptr);
}
struct SelfReferential {
self_ptr: *const Self,
}
Criamos uma struct simples chamada SelfReferential que contém um único campo de ponteiro. Primeiro, inicializamos esta struct com um ponteiro nulo e então a alocamos no heap usando Box::new. Então determinamos o endereço de memória da struct alocada em heap e o armazenamos em uma variável ptr. Finalmente, tornamos a struct auto-referencial atribuindo a variável ptr ao campo self_ptr.
Quando executamos este código no playground, vemos que o endereço do valor de heap e seu ponteiro interno são iguais, o que significa que o campo self_ptr é uma auto-referência válida. Como a variável heap_value é apenas um ponteiro, movê-la (por exemplo, passando-a para uma função) não muda o endereço da própria struct, então o self_ptr permanece válido mesmo se o ponteiro é movido.
No entanto, ainda há uma forma de quebrar este exemplo: Podemos mover para fora de um Box<T> ou substituir seu conteúdo:
let stack_value = mem::replace(&mut *heap_value, SelfReferential {
self_ptr: 0 as *const _,
});
println!("value at: {:p}", &stack_value);
println!("internal reference: {:p}", stack_value.self_ptr);
Aqui usamos a função mem::replace para substituir o valor alocado em heap por uma nova instância da struct. Isso nos permite mover o heap_value original para a pilha, enquanto o campo self_ptr da struct agora é um ponteiro pendente que ainda aponta para o endereço de heap antigo. Quando você tenta executar o exemplo no playground, vê que as linhas impressas “value at:” e “internal reference:” de fato mostram ponteiros diferentes. Então alocar um valor em heap não é suficiente para tornar auto-referências seguras.
O problema fundamental que permitiu a quebra acima é que Box<T> nos permite obter uma referência &mut T para o valor alocado em heap. Esta referência &mut torna possível usar métodos como mem::replace ou mem::swap para invalidar o valor alocado em heap. Para resolver este problema, devemos evitar que referências &mut para structs auto-referenciais sejam criadas.
🔗Pin<Box<T>> e Unpin
A API de pinning fornece uma solução para o problema &mut T na forma do tipo wrapper Pin e da trait marcadora Unpin. A ideia por trás desses tipos é controlar todos os métodos de Pin que podem ser usados para obter referências &mut ao valor encapsulado (por exemplo, get_mut ou deref_mut) na trait Unpin. A trait Unpin é uma auto trait, que é automaticamente implementada para todos os tipos exceto aqueles que explicitamente desistem dela. Ao fazer structs auto-referenciais desistirem de Unpin, não há forma (segura) de obter uma &mut T de um tipo Pin<Box<T>> para elas. Como resultado, suas auto-referências internas têm garantia de permanecer válidas.
Como exemplo, vamos atualizar o tipo SelfReferential de acima para desistir de Unpin:
use core::marker::PhantomPinned;
struct SelfReferential {
self_ptr: *const Self,
_pin: PhantomPinned,
}
Desistimos adicionando um segundo campo _pin do tipo PhantomPinned. Este tipo é um tipo marcador de tamanho zero cujo único propósito é não implementar a trait Unpin. Por causa da forma como auto traits funcionam, um único campo que não é Unpin é suficiente para fazer a struct completa desistir de Unpin.
O segundo passo é mudar o tipo Box<SelfReferential> no exemplo para um tipo Pin<Box<SelfReferential>>. A maneira mais fácil de fazer isso é usar a função Box::pin em vez de Box::new para criar o valor alocado em heap:
let mut heap_value = Box::pin(SelfReferential {
self_ptr: 0 as *const _,
_pin: PhantomPinned,
});
Além de mudar Box::new para Box::pin, também precisamos adicionar o novo campo _pin no inicializador da struct. Como PhantomPinned é um tipo de tamanho zero, só precisamos de seu nome de tipo para inicializá-lo.
Quando tentamos executar nosso exemplo ajustado agora, vemos que ele não funciona mais:
error[E0594]: cannot assign to data in dereference of `Pin<Box<SelfReferential>>`
--> src/main.rs:10:5
|
10 | heap_value.self_ptr = ptr;
| ^^^^^^^^^^^^^^^^^^^^^^^^^ cannot assign
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
error[E0596]: cannot borrow data in dereference of `Pin<Box<SelfReferential>>` as mutable
--> src/main.rs:16:36
|
16 | let stack_value = mem::replace(&mut *heap_value, SelfReferential {
| ^^^^^^^^^^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Pin<Box<SelfReferential>>`
Ambos os erros ocorrem porque o tipo Pin<Box<SelfReferential>> não implementa mais a trait DerefMut. Isso é exatamente o que queríamos porque a trait DerefMut retornaria uma referência &mut, que queríamos evitar. Isso só acontece porque tanto desistimos de Unpin quanto mudamos Box::new para Box::pin.
O problema agora é que o compilador não apenas evita mover o tipo na linha 16, mas também proíbe inicializar o campo self_ptr na linha 10. Isso acontece porque o compilador não pode diferenciar entre usos válidos e inválidos de referências &mut. Para fazer a inicialização funcionar novamente, temos que usar o método unsafe get_unchecked_mut:
// seguro porque modificar um campo não move a struct inteira
unsafe {
let mut_ref = Pin::as_mut(&mut heap_value);
Pin::get_unchecked_mut(mut_ref).self_ptr = ptr;
}
A função get_unchecked_mut funciona em um Pin<&mut T> em vez de um Pin<Box<T>>, então temos que usar Pin::as_mut para converter o valor primeiro. Então podemos definir o campo self_ptr usando a referência &mut retornada por get_unchecked_mut.
Agora o único erro restante é o erro desejado em mem::replace. Lembre-se, esta operação tenta mover o valor alocado em heap para a pilha, o que quebraria a auto-referência armazenada no campo self_ptr. Ao desistir de Unpin e usar Pin<Box<T>>, podemos evitar esta operação em tempo de compilação e assim trabalhar com segurança com structs auto-referenciais. Como vimos, o compilador não é capaz de provar que a criação da auto-referência é segura (ainda), então precisamos usar um bloco unsafe e verificar a correção nós mesmos.
🔗Pinning de Pilha e Pin<&mut T>
Na seção anterior, aprendemos como usar Pin<Box<T>> para criar com segurança um valor auto-referencial alocado em heap. Embora esta abordagem funcione bem e seja relativamente segura (além da construção unsafe), a alocação de heap necessária vem com um custo de desempenho. Como Rust se esforça para fornecer abstrações de custo zero sempre que possível, a API de pinning também permite criar instâncias Pin<&mut T> que apontam para valores alocados em pilha.
Diferente de instâncias Pin<Box<T>>, que têm propriedade do valor encapsulado, instâncias Pin<&mut T> apenas emprestam temporariamente o valor encapsulado. Isso torna as coisas mais complicadas, pois requer que o programador garanta garantias adicionais por si mesmo. Mais importante, um Pin<&mut T> deve permanecer fixado por todo o tempo de vida do T referenciado, o que pode ser difícil de verificar para variáveis baseadas em pilha. Para ajudar com isso, crates como pin-utils existem, mas eu ainda não recomendaria fixar na pilha a menos que você realmente saiba o que está fazendo.
Para leitura adicional, confira a documentação do módulo pin e do método Pin::new_unchecked.
🔗Pinning e Futures
Como já vimos neste post, o método Future::poll usa pinning na forma de um parâmetro Pin<&mut Self>:
fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>
A razão pela qual este método recebe self: Pin<&mut Self> em vez do &mut self normal é que instâncias de future criadas a partir de async/await são frequentemente auto-referenciais, como vimos acima. Ao encapsular Self em Pin e deixar o compilador desistir de Unpin para futures auto-referenciais gerados de async/await, é garantido que as futures não sejam movidas na memória entre chamadas poll. Isso garante que todas as referências internas ainda são válidas.
Vale notar que mover futures antes da primeira chamada poll é aceitável. Isso é resultado do fato de que futures são preguiçosas e não fazem nada até serem consultadas pela primeira vez. O estado start das máquinas de estados geradas, portanto, contém apenas os argumentos da função mas nenhuma referência interna. Para chamar poll, o chamador deve encapsular a future em Pin primeiro, o que garante que a future não pode ser movida na memória mais. Como fixar em pilha é mais difícil de acertar, recomendo sempre usar Box::pin combinado com Pin::as_mut para isso.
Caso esteja interessado em entender como implementar com segurança uma função combinadora de future usando fixação em pilha você mesmo, dê uma olhada no código-fonte relativamente curto do método combinador map da crate futures e na seção sobre projeções e fixação estrutural da documentação de pin.
🔗Executores e Wakers
Usando async/await, é possível trabalhar com futures de forma completamente assíncrona e ergonômica. No entanto, como aprendemos acima, futures não fazem nada até serem consultadas. Isso significa que temos que chamar poll nelas em algum ponto, caso contrário o código assíncrono nunca é executado.
Com uma única future, podemos sempre esperar por cada future manualmente usando um loop como descrito acima. No entanto, esta abordagem é muito ineficiente e não prática para programas que criam um grande número de futures. A solução mais comum para este problema é definir um executor global que é responsável por consultar todas as futures no sistema até serem finalizadas.
🔗Executores
O propósito de um executor é permitir spawnar futures como tarefas independentes, tipicamente através de algum tipo de método spawn. O executor é então responsável por consultar todas as futures até serem completadas. A grande vantagem de gerenciar todas as futures em um lugar central é que o executor pode alternar para uma future diferente sempre que uma future retorna Poll::Pending. Assim, operações assíncronas são executadas em paralelo e a CPU é mantida ocupada.
Muitas implementações de executor também podem aproveitar sistemas com múltiplos núcleos de CPU. Eles criam um thread pool que é capaz de utilizar todos os núcleos se há trabalho suficiente disponível e usam técnicas como work stealing para equilibrar a carga entre núcleos. Também existem implementações especiais de executor para sistemas embarcados que otimizam para baixa latência e sobrecarga de memória.
Para evitar a sobrecarga de consultar futures repetidamente, executores tipicamente aproveitam a API de waker suportada pelas futures do Rust.
🔗Wakers
A ideia por trás da API de waker é que um tipo especial Waker é passado para cada invocação de poll, encapsulado no tipo Context. Este tipo Waker é criado pelo executor e pode ser usado pela tarefa assíncrona para sinalizar sua conclusão (parcial). Como resultado, o executor não precisa chamar poll em uma future que previamente retornou Poll::Pending até ser notificado pelo waker correspondente.
Isso é melhor ilustrado por um pequeno exemplo:
async fn write_file() {
async_write_file("foo.txt", "Hello").await;
}
Esta função escreve assincronamente a string “Hello” em um arquivo foo.txt. Como escritas em disco demoram algum tempo, a primeira chamada poll nesta future provavelmente retornará Poll::Pending. No entanto, o driver de disco rígido armazenará internamente o Waker passado para a chamada poll e o usará para notificar o executor quando o arquivo for escrito no disco. Desta forma, o executor não precisa desperdiçar tempo tentando fazer poll da future novamente antes de receber a notificação do waker.
Veremos como o tipo Waker funciona em detalhes quando criarmos nosso próprio executor com suporte a waker na seção de implementação deste post.
🔗Multitarefa Cooperativa?
No início deste post, falamos sobre multitarefa preemptiva e cooperativa. Enquanto multitarefa preemptiva depende do sistema operacional para pausar forçadamente tarefas em execução, multitarefa cooperativa requer que as tarefas cedam voluntariamente o controle da CPU através de uma operação yield regularmente. A grande vantagem da abordagem cooperativa é que as tarefas podem salvar seu próprio estado, o que resulta em trocas de contexto mais eficientes e torna possível compartilhar a mesma pilha de chamadas entre tarefas.
Pode não ser imediatamente aparente, mas futures e async/await são uma implementação do padrão de multitarefa cooperativa:
- Cada future que é adicionada ao executor é basicamente uma tarefa cooperativa.
- Em vez de usar uma operação de yield explícita, futures cedem o controle do núcleo da CPU retornando
Poll::Pending(ouPoll::Readyno final).- Não há nada que force futures a ceder a CPU. Se quiserem, podem nunca retornar de
poll, por exemplo, girando indefinidamente em um loop. - Como cada future pode bloquear a execução das outras futures no executor, precisamos confiar que elas não sejam maliciosas.
- Não há nada que force futures a ceder a CPU. Se quiserem, podem nunca retornar de
- Futures armazenam internamente todo o estado de que precisam para continuar a execução na próxima chamada
poll. Com async/await, o compilador detecta automaticamente todas as variáveis necessárias e as armazena dentro da máquina de estados gerada.- Apenas o estado mínimo necessário para continuação é salvo.
- Como o método
pollcede a pilha de chamadas quando retorna, a mesma pilha pode ser usada para consultar outras futures.
Vemos que futures e async/await se encaixam perfeitamente no padrão de multitarefa cooperativa; eles apenas usam terminologia diferente. No que segue, portanto, usaremos os termos “tarefa” e “future” de forma intercambiável.
🔗Implementação
Agora que entendemos como multitarefa cooperativa baseada em futures e async/await funciona em Rust, é hora de adicionar suporte para ela ao nosso kernel. Como a trait Future é parte da biblioteca core e async/await é uma funcionalidade da própria linguagem, não há nada especial que precisamos fazer para usá-la em nosso kernel #![no_std]. O único requisito é que usemos pelo menos o nightly 2020-03-25 do Rust porque async/await não era compatível com no_std antes.
Com um nightly recente o suficiente, podemos começar a usar async/await em nosso main.rs:
// em src/main.rs
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
A função async_number é uma async fn, então o compilador a transforma em uma máquina de estados que implementa Future. Como a função retorna apenas 42, a future resultante retornará diretamente Poll::Ready(42) na primeira chamada poll. Como async_number, a função example_task também é uma async fn. Ela aguarda o número retornado por async_number e então o imprime usando a macro println.
Para executar a future retornada por example_task, precisamos chamar poll nela até sinalizar sua conclusão retornando Poll::Ready. Para fazer isso, precisamos criar um tipo executor simples.
🔗Tarefa
Antes de começarmos a implementação do executor, criamos um novo módulo task com um tipo Task:
// em src/lib.rs
pub mod task;
// em src/task/mod.rs
use core::{future::Future, pin::Pin};
use alloc::boxed::Box;
pub struct Task {
future: Pin<Box<dyn Future<Output = ()>>>,
}
A struct Task é um tipo newtype wrapper em torno de uma future fixada, alocada em heap e dinamicamente despachada com o tipo vazio () como saída. Vamos passar por ela em detalhes:
- Requeremos que a future associada a uma tarefa retorne
(). Isso significa que tarefas não retornam nenhum resultado, elas são apenas executadas por seus efeitos colaterais. Por exemplo, a funçãoexample_taskque definimos acima não tem valor de retorno, mas ela imprime algo na tela como efeito colateral. - A palavra-chave
dynindica que armazenamos um trait object noBox. Isso significa que os métodos na future são dinamicamente despachados, permitindo que diferentes tipos de futures sejam armazenados no tipoTask. Isso é importante porque cadaasync fntem seu próprio tipo e queremos poder criar múltiplas tarefas diferentes. - Como aprendemos na seção sobre pinning, o tipo
Pin<Box>garante que um valor não pode ser movido na memória colocando-o no heap e impedindo a criação de referências&muta ele. Isso é importante porque futures gerados por async/await podem ser auto-referenciais, ou seja, conter ponteiros para si mesmos que seriam invalidados quando a future é movida.
Para permitir a criação de novas structs Task a partir de futures, criamos uma função new:
// em src/task/mod.rs
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
future: Box::pin(future),
}
}
}
A função recebe uma future arbitrária com um tipo de saída de () e a fixa na memória através da função Box::pin. Então encapsula a future em caixa na struct Task e a retorna. O tempo de vida 'static é necessário aqui porque a Task retornada pode viver por um tempo arbitrário, então a future precisa ser válida por esse tempo também.
Também adicionamos um método poll para permitir que o executor consulte a future armazenada:
// em src/task/mod.rs
use core::task::{Context, Poll};
impl Task {
fn poll(&mut self, context: &mut Context) -> Poll<()> {
self.future.as_mut().poll(context)
}
}
Como o método poll da trait Future espera ser chamado em um tipo Pin<&mut T>, usamos o método Pin::as_mut para converter o campo self.future do tipo Pin<Box<T>> primeiro. Então chamamos poll no campo self.future convertido e retornamos o resultado. Como o método Task::poll deve ser chamado apenas pelo executor que criaremos em um momento, mantemos a função privada ao módulo task.
🔗Executor Simples
Como executores podem ser bem complexos, deliberadamente começamos criando um executor muito básico antes de implementar um executor com mais funcionalidades mais tarde. Para isso, primeiro criamos um novo submódulo task::simple_executor:
// em src/task/mod.rs
pub mod simple_executor;
// em src/task/simple_executor.rs
use super::Task;
use alloc::collections::VecDeque;
pub struct SimpleExecutor {
task_queue: VecDeque<Task>,
}
impl SimpleExecutor {
pub fn new() -> SimpleExecutor {
SimpleExecutor {
task_queue: VecDeque::new(),
}
}
pub fn spawn(&mut self, task: Task) {
self.task_queue.push_back(task)
}
}
A struct contém um único campo task_queue do tipo VecDeque, que é basicamente um vetor que permite operações de push e pop em ambas as extremidades. A ideia por trás de usar este tipo é que inserimos novas tarefas através do método spawn no final e retiramos a próxima tarefa para execução do início. Desta forma, obtemos uma simples fila FIFO (“first in, first out”).
🔗Waker Dummy
Para chamar o método poll, precisamos criar um tipo Context, que encapsula um tipo Waker. Para começar simples, primeiro criaremos um waker dummy que não faz nada. Para isso, criamos uma instância RawWaker, que define a implementação dos diferentes métodos Waker, e então usamos a função Waker::from_raw para transformá-lo em um Waker:
// em src/task/simple_executor.rs
use core::task::{Waker, RawWaker};
fn dummy_raw_waker() -> RawWaker {
todo!();
}
fn dummy_waker() -> Waker {
unsafe { Waker::from_raw(dummy_raw_waker()) }
}
A função from_raw é unsafe porque comportamento indefinido pode ocorrer se o programador não respeitar os requisitos documentados de RawWaker. Antes de olharmos para a implementação da função dummy_raw_waker, primeiro tentamos entender como o tipo RawWaker funciona.
🔗RawWaker
O tipo RawWaker requer que o programador defina explicitamente uma tabela de métodos virtuais (vtable) que especifica as funções que devem ser chamadas quando o RawWaker é clonado, acordado ou descartado. O layout desta vtable é definido pelo tipo RawWakerVTable. Cada função recebe um argumento *const (), que é um ponteiro type-erased para algum valor. A razão para usar um ponteiro *const () em vez de uma referência apropriada é que o tipo RawWaker deve ser não genérico mas ainda suportar tipos arbitrários. O ponteiro é fornecido colocando-o no argumento data de RawWaker::new, que apenas inicializa um RawWaker. O Waker então usa este RawWaker para chamar as funções da vtable com data.
Tipicamente, o RawWaker é criado para alguma struct alocada em heap que é encapsulada no tipo Box ou Arc. Para tais tipos, métodos como Box::into_raw podem ser usados para converter o Box<T> em um ponteiro *const T. Este ponteiro pode então ser convertido em um ponteiro anônimo *const () e passado para RawWaker::new. Como cada função da vtable recebe o mesmo *const () como argumento, as funções podem com segurança converter o ponteiro de volta para um Box<T> ou um &T para operar nele. Como você pode imaginar, este processo é altamente perigoso e pode facilmente levar a comportamento indefinido em erros. Por esta razão, criar manualmente um RawWaker não é recomendado a menos que seja necessário.
🔗Um RawWaker Dummy
Embora criar manualmente um RawWaker não seja recomendado, atualmente não há outra forma de criar um Waker dummy que não faz nada. Felizmente, o fato de que queremos não fazer nada torna relativamente seguro implementar a função dummy_raw_waker:
// em src/task/simple_executor.rs
use core::task::RawWakerVTable;
fn dummy_raw_waker() -> RawWaker {
fn no_op(_: *const ()) {}
fn clone(_: *const ()) -> RawWaker {
dummy_raw_waker()
}
let vtable = &RawWakerVTable::new(clone, no_op, no_op, no_op);
RawWaker::new(0 as *const (), vtable)
}
Primeiro, definimos duas funções internas chamadas no_op e clone. A função no_op recebe um ponteiro *const () e não faz nada. A função clone também recebe um ponteiro *const () e retorna um novo RawWaker chamando dummy_raw_waker novamente. Usamos estas duas funções para criar uma RawWakerVTable mínima: A função clone é usada para as operações de clonagem, e a função no_op é usada para todas as outras operações. Como o RawWaker não faz nada, não importa que retornamos um novo RawWaker de clone em vez de cloná-lo.
Após criar a vtable, usamos a função RawWaker::new para criar o RawWaker. O *const () passado não importa já que nenhuma das funções da vtable o usa. Por esta razão, simplesmente passamos um ponteiro nulo.
🔗Um Método run
Agora temos uma forma de criar uma instância Waker, podemos usá-la para implementar um método run em nosso executor. O método run mais simples é consultar repetidamente todas as tarefas enfileiradas em um loop até todas estarem prontas. Isso não é muito eficiente já que não utiliza as notificações do tipo Waker, mas é uma forma fácil de fazer as coisas funcionarem:
// em src/task/simple_executor.rs
use core::task::{Context, Poll};
impl SimpleExecutor {
pub fn run(&mut self) {
while let Some(mut task) = self.task_queue.pop_front() {
let waker = dummy_waker();
let mut context = Context::from_waker(&waker);
match task.poll(&mut context) {
Poll::Ready(()) => {} // tarefa concluída
Poll::Pending => self.task_queue.push_back(task),
}
}
}
}
A função usa um loop while let para lidar com todas as tarefas na task_queue. Para cada tarefa, primeiro cria um tipo Context encapsulando uma instância Waker retornada por nossa função dummy_waker. Então invoca o método Task::poll com este context. Se o método poll retorna Poll::Ready, a tarefa está finalizada e podemos continuar com a próxima tarefa. Se a tarefa ainda está Poll::Pending, nós a adicionamos de volta ao final da fila para que seja consultada novamente em uma iteração de loop subsequente.
🔗Experimentando
Com nosso tipo SimpleExecutor, agora podemos tentar executar a tarefa retornada pela função example_task em nosso main.rs:
// em src/main.rs
use blog_os::task::{Task, simple_executor::SimpleExecutor};
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] rotinas de inicialização, incluindo init_heap, test_main
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.run();
// […] mensagem "it did not crash", hlt_loop
}
// Abaixo está a função example_task novamente para que você não precise rolar para cima
async fn async_number() -> u32 {
42
}
async fn example_task() {
let number = async_number().await;
println!("async number: {}", number);
}
Quando executamos, vemos que a mensagem esperada “async number: 42” é impressa na tela:
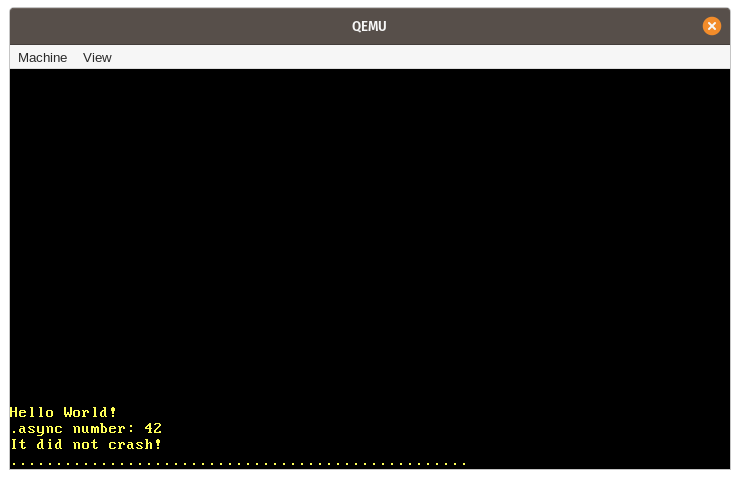
Vamos resumir os vários passos que acontecem neste exemplo:
- Primeiro, uma nova instância do nosso tipo
SimpleExecutoré criada com umatask_queuevazia. - Em seguida, chamamos a função assíncrona
example_task, que retorna uma future. Encapsulamos esta future no tipoTask, que a move para o heap e a fixa, e então adicionamos a tarefa àtask_queuedo executor através do métodospawn. - Então chamamos o método
runpara iniciar a execução da única tarefa na fila. Isso envolve:- Retirar a tarefa do início da
task_queue. - Criar um
RawWakerpara a tarefa, convertê-lo em uma instânciaWaker, e então criar uma instânciaContexta partir dele. - Chamar o método
pollna future da tarefa, usando oContextque acabamos de criar. - Como a
example_tasknão espera por nada, pode executar diretamente até seu fim na primeira chamadapoll. É aqui que a linha “async number: 42” é impressa. - Como a
example_taskretorna diretamentePoll::Ready, ela não é adicionada de volta à fila de tarefas.
- Retirar a tarefa do início da
- O método
runretorna após atask_queuese tornar vazia. A execução de nossa funçãokernel_maincontinua e a mensagem “It did not crash!” é impressa.
🔗Entrada de Teclado Assíncrona
Nosso executor simples não utiliza as notificações Waker e simplesmente faz loop sobre todas as tarefas até estarem prontas. Isso não foi um problema para nosso exemplo já que nossa example_task pode executar diretamente até finalizar na primeira chamada poll. Para ver as vantagens de desempenho de uma implementação Waker apropriada, primeiro precisamos criar uma tarefa que é verdadeiramente assíncrona, ou seja, uma tarefa que provavelmente retornará Poll::Pending na primeira chamada poll.
Já temos algum tipo de assincronia em nosso sistema que podemos usar para isso: interrupções de hardware. Como aprendemos no post Interrupções, interrupções de hardware podem ocorrer em pontos arbitrários no tempo, determinados por algum dispositivo externo. Por exemplo, um temporizador de hardware envia uma interrupção para a CPU após algum tempo predefinido ter decorrido. Quando a CPU recebe uma interrupção, ela transfere imediatamente o controle para a função manipuladora correspondente definida na tabela de descritores de interrupção (IDT).
No que segue, criaremos uma tarefa assíncrona baseada na interrupção de teclado. A interrupção de teclado é uma boa candidata para isso porque é tanto não determinística quanto crítica em latência. Não determinística significa que não há forma de prever quando a próxima tecla será pressionada porque depende inteiramente do usuário. Crítica em latência significa que queremos lidar com a entrada de teclado de forma oportuna, caso contrário o usuário sentirá um atraso. Para suportar tal tarefa de forma eficiente, será essencial que o executor tenha suporte apropriado para notificações Waker.
🔗Fila de Scancode
Atualmente, lidamos com a entrada de teclado diretamente no manipulador de interrupção. Isso não é uma boa ideia a longo prazo porque manipuladores de interrupção devem permanecer o mais curtos possível já que podem interromper trabalho importante. Em vez disso, manipuladores de interrupção devem executar apenas a quantidade mínima de trabalho necessária (por exemplo, ler o scancode do teclado) e deixar o resto do trabalho (por exemplo, interpretar o scancode) para uma tarefa em segundo plano.
Um padrão comum para delegar trabalho para uma tarefa em segundo plano é criar algum tipo de fila. O manipulador de interrupção empurra unidades de trabalho para a fila, e a tarefa em segundo plano lida com o trabalho na fila. Aplicado à nossa interrupção de teclado, isso significa que o manipulador de interrupção lê apenas o scancode do teclado, o empurra para a fila e então retorna. A tarefa de teclado fica no outro extremo da fila e interpreta e lida com cada scancode que é empurrado para ela:

Uma implementação simples dessa fila poderia ser um VecDeque protegido por mutex. No entanto, usar mutexes em manipuladores de interrupção não é uma boa ideia porque pode facilmente levar a deadlocks. Por exemplo, quando o usuário pressiona uma tecla enquanto a tarefa de teclado bloqueou a fila, o manipulador de interrupção tenta adquirir o bloqueio novamente e trava indefinidamente. Outro problema com esta abordagem é que VecDeque aumenta automaticamente sua capacidade realizando uma nova alocação de heap quando fica cheio. Isso pode levar a deadlocks novamente porque nosso alocador também usa um mutex internamente. Problemas adicionais são que alocações de heap podem falhar ou demorar um tempo considerável quando o heap está fragmentado.
Para evitar esses problemas, precisamos de uma implementação de fila que não requer mutexes ou alocações para sua operação push. Tais filas podem ser implementadas usando operações atômicas sem bloqueio para empurrar e retirar elementos. Desta forma, é possível criar operações push e pop que requerem apenas uma referência &self e são, portanto, utilizáveis sem um mutex. Para evitar alocações em push, a fila pode ser apoiada por um buffer pré-alocado de tamanho fixo. Embora isso torne a fila limitada (ou seja, tem um comprimento máximo), frequentemente é possível definir limites superiores razoáveis para o comprimento da fila na prática, então isso não é um grande problema.
🔗A Crate crossbeam
Implementar tal fila de forma correta e eficiente é muito difícil, então recomendo aderir a implementações existentes e bem testadas. Um projeto popular de Rust que implementa vários tipos sem mutex para programação concorrente é crossbeam. Ele fornece um tipo chamado ArrayQueue que é exatamente o que precisamos neste caso. E temos sorte: o tipo é totalmente compatível com crates no_std com suporte a alocação.
Para usar o tipo, precisamos adicionar uma dependência na crate crossbeam-queue:
# em Cargo.toml
[dependencies.crossbeam-queue]
version = "0.3.11"
default-features = false
features = ["alloc"]
Por padrão, a crate depende da biblioteca padrão. Para torná-la compatível com no_std, precisamos desabilitar suas funcionalidades padrão e em vez disso habilitar a funcionalidade alloc. (Note que também poderíamos adicionar uma dependência na crate crossbeam principal, que reexporta a crate crossbeam-queue, mas isso resultaria em um número maior de dependências e tempos de compilação mais longos.)
🔗Implementação da Fila
Usando o tipo ArrayQueue, agora podemos criar uma fila de scancode global em um novo módulo task::keyboard:
// em src/task/mod.rs
pub mod keyboard;
// em src/task/keyboard.rs
use conquer_once::spin::OnceCell;
use crossbeam_queue::ArrayQueue;
static SCANCODE_QUEUE: OnceCell<ArrayQueue<u8>> = OnceCell::uninit();
Como ArrayQueue::new realiza uma alocação de heap, que não é possível em tempo de compilação (ainda), não podemos inicializar a variável estática diretamente. Em vez disso, usamos o tipo OnceCell da crate conquer_once, que torna possível realizar uma inicialização única segura de valores estáticos. Para incluir a crate, precisamos adicioná-la como uma dependência em nosso Cargo.toml:
# em Cargo.toml
[dependencies.conquer-once]
version = "0.2.0"
default-features = false
Em vez do primitivo OnceCell, também poderíamos usar a macro lazy_static aqui. No entanto, o tipo OnceCell tem a vantagem de que podemos garantir que a inicialização não acontece no manipulador de interrupção, evitando assim que o manipulador de interrupção realize uma alocação de heap.
🔗Preenchendo a Fila
Para preencher a fila de scancode, criamos uma nova função add_scancode que chamaremos do manipulador de interrupção:
// em src/task/keyboard.rs
use crate::println;
/// Chamada pelo manipulador de interrupção de teclado
///
/// Não deve bloquear ou alocar.
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("AVISO: fila de scancode cheia; descartando entrada de teclado");
}
} else {
println!("AVISO: fila de scancode não inicializada");
}
}
Usamos OnceCell::try_get para obter uma referência à fila inicializada. Se a fila ainda não está inicializada, ignoramos o scancode do teclado e imprimimos um aviso. É importante que não tentemos inicializar a fila nesta função porque ela será chamada pelo manipulador de interrupção, que não deve realizar alocações de heap. Como esta função não deve ser chamável de nosso main.rs, usamos a visibilidade pub(crate) para torná-la disponível apenas para nosso lib.rs.
O fato de que o método ArrayQueue::push requer apenas uma referência &self torna muito simples chamar o método na fila estática. O tipo ArrayQueue realiza toda a sincronização necessária por si mesmo, então não precisamos de um wrapper mutex aqui. Caso a fila esteja cheia, também imprimimos um aviso.
Para chamar a função add_scancode em interrupções de teclado, atualizamos nossa função keyboard_interrupt_handler no módulo interrupts:
// em src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame
) {
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
crate::task::keyboard::add_scancode(scancode); // novo
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Keyboard.as_u8());
}
}
Removemos todo o código de manipulação de teclado desta função e em vez disso adicionamos uma chamada para a função add_scancode. O resto da função permanece o mesmo de antes.
Como esperado, pressionamentos de tecla não são mais impressos na tela quando executamos nosso projeto usando cargo run agora. Em vez disso, vemos o aviso de que a fila de scancode está não inicializada para cada pressionamento de tecla.
🔗Scancode Stream
Para inicializar a SCANCODE_QUEUE e ler os scancodes da fila de forma assíncrona, criamos um novo tipo ScancodeStream:
// em src/task/keyboard.rs
pub struct ScancodeStream {
_private: (),
}
impl ScancodeStream {
pub fn new() -> Self {
SCANCODE_QUEUE.try_init_once(|| ArrayQueue::new(100))
.expect("ScancodeStream::new deve ser chamado apenas uma vez");
ScancodeStream { _private: () }
}
}
O propósito do campo _private é evitar a construção da struct de fora do módulo. Isso torna a função new a única forma de construir o tipo. Na função, primeiro tentamos inicializar a estática SCANCODE_QUEUE. Entramos em pânico se ela já estiver inicializada para garantir que apenas uma única instância ScancodeStream pode ser criada.
Para disponibilizar os scancodes para tarefas assíncronas, o próximo passo é implementar um método tipo poll que tenta retirar o próximo scancode da fila. Embora isso soe como deveríamos implementar a trait Future para nosso tipo, isso não se encaixa perfeitamente aqui. O problema é que a trait Future abstrai apenas sobre um único valor assíncrono e espera que o método poll não seja chamado novamente após retornar Poll::Ready. Nossa fila de scancode, no entanto, contém múltiplos valores assíncronos, então está ok continuar consultando-a.
🔗A Trait Stream
Como tipos que produzem múltiplos valores assíncronos são comuns, a crate futures fornece uma abstração útil para tais tipos: a trait Stream. A trait é definida assim:
pub trait Stream {
type Item;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Option<Self::Item>>;
}
Esta definição é bem similar à trait Future, com as seguintes diferenças:
- O tipo associado é chamado
Itemem vez deOutput. - Em vez de um método
pollque retornaPoll<Self::Item>, a traitStreamdefine um métodopoll_nextque retorna umPoll<Option<Self::Item>>(note oOptionadicional).
Há também uma diferença semântica: O poll_next pode ser chamado repetidamente, até retornar Poll::Ready(None) para sinalizar que o stream está finalizado. Neste aspecto, o método é similar ao método Iterator::next, que também retorna None após o último valor.
🔗Implementando Stream
Vamos implementar a trait Stream para nosso ScancodeStream para fornecer os valores da SCANCODE_QUEUE de forma assíncrona. Para isso, primeiro precisamos adicionar uma dependência na crate futures-util, que contém o tipo Stream:
# em Cargo.toml
[dependencies.futures-util]
version = "0.3.4"
default-features = false
features = ["alloc"]
Desabilitamos as funcionalidades padrão para tornar a crate compatível com no_std e habilitamos a funcionalidade alloc para disponibilizar seus tipos baseados em alocação (precisaremos disso mais tarde). (Note que também poderíamos adicionar uma dependência na crate futures principal, que reexporta a crate futures-util, mas isso resultaria em um número maior de dependências e tempos de compilação mais longos.)
Agora podemos importar e implementar a trait Stream:
// em src/task/keyboard.rs
use core::{pin::Pin, task::{Poll, Context}};
use futures_util::stream::Stream;
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE.try_get().expect("não inicializada");
match queue.pop() {
Some(scancode) => Poll::Ready(Some(scancode)),
None => Poll::Pending,
}
}
}
Primeiro usamos o método OnceCell::try_get para obter uma referência à fila de scancode inicializada. Isso nunca deve falhar já que inicializamos a fila na função new, então podemos usar com segurança o método expect para entrar em pânico se não estiver inicializada. Em seguida, usamos o método ArrayQueue::pop para tentar obter o próximo elemento da fila. Se tiver sucesso, retornamos o scancode encapsulado em Poll::Ready(Some(…)). Se falhar, significa que a fila está vazia. Nesse caso, retornamos Poll::Pending.
🔗Suporte a Waker
Como o método Futures::poll, o método Stream::poll_next requer que a tarefa assíncrona notifique o executor quando se torna pronta após Poll::Pending ser retornado. Desta forma, o executor não precisa consultar a mesma tarefa novamente até ser notificado, o que reduz grandemente a sobrecarga de desempenho de tarefas em espera.
Para enviar esta notificação, a tarefa deve extrair o Waker da referência Context passada e armazená-lo em algum lugar. Quando a tarefa se torna pronta, ela deve invocar o método wake no Waker armazenado para notificar o executor que a tarefa deve ser consultada novamente.
🔗AtomicWaker
Para implementar a notificação Waker para nosso ScancodeStream, precisamos de um lugar onde possamos armazenar o Waker entre chamadas poll. Não podemos armazená-lo como um campo no próprio ScancodeStream porque ele precisa ser acessível da função add_scancode. A solução para isso é usar uma variável estática do tipo AtomicWaker fornecido pela crate futures-util. Como o tipo ArrayQueue, este tipo é baseado em instruções atômicas e pode ser armazenado com segurança em um static e modificado concorrentemente.
Vamos usar o tipo AtomicWaker para definir um WAKER estático:
// em src/task/keyboard.rs
use futures_util::task::AtomicWaker;
static WAKER: AtomicWaker = AtomicWaker::new();
A ideia é que a implementação poll_next armazena o waker atual nesta estática, e a função add_scancode chama a função wake nele quando um novo scancode é adicionado à fila.
🔗Armazenando um Waker
O contrato definido por poll/poll_next requer que a tarefa registre um acordar para o Waker passado quando retorna Poll::Pending. Vamos modificar nossa implementação poll_next para satisfazer este requisito:
// em src/task/keyboard.rs
impl Stream for ScancodeStream {
type Item = u8;
fn poll_next(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Option<u8>> {
let queue = SCANCODE_QUEUE
.try_get()
.expect("fila de scancode não inicializada");
// caminho rápido
if let Some(scancode) = queue.pop() {
return Poll::Ready(Some(scancode));
}
WAKER.register(&cx.waker());
match queue.pop() {
Some(scancode) => {
WAKER.take();
Poll::Ready(Some(scancode))
}
None => Poll::Pending,
}
}
}
Como antes, primeiro usamos a função OnceCell::try_get para obter uma referência à fila de scancode inicializada. Então otimisticamente tentamos pop da fila e retornamos Poll::Ready quando tiver sucesso. Desta forma, podemos evitar a sobrecarga de desempenho de registrar um waker quando a fila não está vazia.
Se a primeira chamada para queue.pop() não tiver sucesso, a fila está potencialmente vazia. Apenas potencialmente porque o manipulador de interrupção pode ter preenchido a fila assincronamente imediatamente após a verificação. Como esta condição de corrida pode ocorrer novamente para a próxima verificação, precisamos registrar o Waker no WAKER estático antes da segunda verificação. Desta forma, um acordar pode acontecer antes de retornarmos Poll::Pending, mas é garantido que recebemos um acordar para qualquer scancode empurrado após a verificação.
Após registrar o Waker contido no Context passado através da função AtomicWaker::register, tentamos retirar da fila uma segunda vez. Se agora tiver sucesso, retornamos Poll::Ready. Também removemos o waker registrado novamente usando AtomicWaker::take porque uma notificação de waker não é mais necessária. Caso queue.pop() falhe pela segunda vez, retornamos Poll::Pending como antes, mas desta vez com um acordar registrado.
Note que há duas formas de um acordar acontecer para uma tarefa que não retornou Poll::Pending (ainda). Uma forma é a condição de corrida mencionada quando o acordar acontece imediatamente antes de retornar Poll::Pending. A outra forma é quando a fila não está mais vazia após registrar o waker, de modo que Poll::Ready é retornado. Como esses acordares espúrios não são evitáveis, o executor precisa ser capaz de lidar com eles corretamente.
🔗Acordando o Waker Armazenado
Para acordar o Waker armazenado, adicionamos uma chamada para WAKER.wake() na função add_scancode:
// em src/task/keyboard.rs
pub(crate) fn add_scancode(scancode: u8) {
if let Ok(queue) = SCANCODE_QUEUE.try_get() {
if let Err(_) = queue.push(scancode) {
println!("AVISO: fila de scancode cheia; descartando entrada de teclado");
} else {
WAKER.wake(); // novo
}
} else {
println!("AVISO: fila de scancode não inicializada");
}
}
A única mudança que fizemos é adicionar uma chamada para WAKER.wake() se o push para a fila de scancode tiver sucesso. Se um waker está registrado no WAKER estático, este método chamará o método wake igualmente nomeado nele, que notifica o executor. Caso contrário, a operação é uma no-op, ou seja, nada acontece.
É importante que chamemos wake apenas após empurrar para a fila porque caso contrário a tarefa pode ser acordada muito cedo enquanto a fila ainda está vazia. Isso pode, por exemplo, acontecer ao usar um executor multi-threaded que inicia a tarefa acordada concorrentemente em um núcleo de CPU diferente. Embora ainda não tenhamos suporte a threads, adicionaremos isso em breve e não queremos que as coisas quebrem então.
🔗Tarefa de Teclado
Agora que implementamos a trait Stream para nosso ScancodeStream, podemos usá-la para criar uma tarefa de teclado assíncrona:
// em src/task/keyboard.rs
use futures_util::stream::StreamExt;
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use crate::print;
pub async fn print_keypresses() {
let mut scancodes = ScancodeStream::new();
let mut keyboard = Keyboard::new(ScancodeSet1::new(),
layouts::Us104Key, HandleControl::Ignore);
while let Some(scancode) = scancodes.next().await {
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
}
}
O código é muito similar ao código que tínhamos em nosso manipulador de interrupção de teclado antes de modificá-lo neste post. A única diferença é que, em vez de ler o scancode de uma porta de E/S, nós o pegamos do ScancodeStream. Para isso, primeiro criamos um novo Scancode stream e então usamos repetidamente o método next fornecido pela trait StreamExt para obter uma Future que resolve para o próximo elemento no stream. Usando o operador await nele, aguardamos assincronamente o resultado da future.
Usamos while let para fazer loop até o stream retornar None para sinalizar seu fim. Como nosso método poll_next nunca retorna None, este é efetivamente um loop infinito, então a tarefa print_keypresses nunca termina.
Vamos adicionar a tarefa print_keypresses ao nosso executor em nosso main.rs para obter entrada de teclado funcionando novamente:
// em src/main.rs
use blog_os::task::keyboard; // novo
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] rotinas de inicialização, incluindo init_heap, test_main
let mut executor = SimpleExecutor::new();
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses())); // novo
executor.run();
// […] mensagem "it did not crash", hlt_loop
}
Quando executamos cargo run agora, vemos que a entrada de teclado funciona novamente:

Se você ficar de olho na utilização de CPU do seu computador, verá que o processo QEMU agora mantém continuamente a CPU ocupada. Isso acontece porque nosso SimpleExecutor consulta tarefas repetidamente em um loop. Então mesmo se não pressionarmos nenhuma tecla no teclado, o executor chama repetidamente poll em nossa tarefa print_keypresses, mesmo que a tarefa não possa fazer progresso e retornará Poll::Pending cada vez.
🔗Executor com Suporte a Waker
Para corrigir o problema de desempenho, precisamos criar um executor que utilize adequadamente as notificações Waker. Desta forma, o executor é notificado quando a próxima interrupção de teclado ocorre, então não precisa continuar consultando a tarefa print_keypresses repetidamente.
🔗Task Id
O primeiro passo na criação de um executor com suporte adequado para notificações de waker é dar a cada tarefa um ID único. Isso é necessário porque precisamos de uma forma de especificar qual tarefa deve ser acordada. Começamos criando um novo tipo wrapper TaskId:
// em src/task/mod.rs
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord)]
struct TaskId(u64);
A struct TaskId é um tipo wrapper simples em torno de u64. Derivamos várias traits para ela para torná-la imprimível, copiável, comparável e ordenável. Esta última é importante porque queremos usar TaskId como o tipo de chave de um BTreeMap daqui a pouco.
Para criar um novo ID único, criamos uma função TaskId::new:
use core::sync::atomic::{AtomicU64, Ordering};
impl TaskId {
fn new() -> Self {
static NEXT_ID: AtomicU64 = AtomicU64::new(0);
TaskId(NEXT_ID.fetch_add(1, Ordering::Relaxed))
}
}
A função usa uma variável estática NEXT_ID do tipo AtomicU64 para garantir que cada ID seja atribuído apenas uma vez. O método fetch_add incrementa atomicamente o valor e retorna o valor anterior em uma operação atômica. Isso significa que mesmo quando o método TaskId::new é chamado em paralelo, cada ID é retornado exatamente uma vez. O parâmetro Ordering define se o compilador tem permissão para reordenar a operação fetch_add no fluxo de instruções. Como apenas requeremos que o ID seja único, a ordenação Relaxed com os requisitos mais fracos é suficiente neste caso.
Agora podemos estender nosso tipo Task com um campo id adicional:
// em src/task/mod.rs
pub struct Task {
id: TaskId, // novo
future: Pin<Box<dyn Future<Output = ()>>>,
}
impl Task {
pub fn new(future: impl Future<Output = ()> + 'static) -> Task {
Task {
id: TaskId::new(), // novo
future: Box::pin(future),
}
}
}
O novo campo id torna possível nomear exclusivamente uma tarefa, o que é necessário para acordar uma tarefa específica.
🔗O Tipo Executor
Criamos nosso novo tipo Executor em um módulo task::executor:
// em src/task/mod.rs
pub mod executor;
// em src/task/executor.rs
use super::{Task, TaskId};
use alloc::{collections::BTreeMap, sync::Arc};
use core::task::Waker;
use crossbeam_queue::ArrayQueue;
pub struct Executor {
tasks: BTreeMap<TaskId, Task>,
task_queue: Arc<ArrayQueue<TaskId>>,
waker_cache: BTreeMap<TaskId, Waker>,
}
impl Executor {
pub fn new() -> Self {
Executor {
tasks: BTreeMap::new(),
task_queue: Arc::new(ArrayQueue::new(100)),
waker_cache: BTreeMap::new(),
}
}
}
Em vez de armazenar tarefas em um VecDeque como fizemos para nosso SimpleExecutor, usamos uma task_queue de IDs de tarefa e um BTreeMap chamado tasks que contém as instâncias Task reais. O mapa é indexado pelo TaskId para permitir continuação eficiente de uma tarefa específica.
O campo task_queue é um ArrayQueue de IDs de tarefa, encapsulado no tipo Arc que implementa contagem de referência. Contagem de referência torna possível compartilhar propriedade do valor entre múltiplos proprietários. Funciona alocando o valor no heap e contando o número de referências ativas a ele. Quando o número de referências ativas chega a zero, o valor não é mais necessário e pode ser desalocado.
Usamos este tipo Arc<ArrayQueue> para a task_queue porque ela será compartilhada entre o executor e wakers. A ideia é que os wakers empurram o ID da tarefa acordada para a fila. O executor fica na extremidade receptora da fila, recupera as tarefas acordadas por seu ID do mapa tasks, e então as executa. A razão para usar uma fila de tamanho fixo em vez de uma fila ilimitada como SegQueue é que manipuladores de interrupção não devem alocar ao empurrar para esta fila.
Além da task_queue e do mapa tasks, o tipo Executor tem um campo waker_cache que também é um mapa. Este mapa armazena em cache o Waker de uma tarefa após sua criação. Isso tem duas razões: Primeiro, melhora o desempenho reutilizando o mesmo waker para múltiplos acordares da mesma tarefa em vez de criar um novo waker cada vez. Segundo, garante que wakers contados por referência não sejam desalocados dentro de manipuladores de interrupção porque isso poderia levar a deadlocks (há mais detalhes sobre isso abaixo).
Para criar um Executor, fornecemos uma função new simples. Escolhemos uma capacidade de 100 para a task_queue, que deve ser mais que suficiente para o futuro previsível. Caso nosso sistema tenha mais de 100 tarefas concorrentes em algum ponto, podemos facilmente aumentar esse tamanho.
🔗Spawnando Tarefas
Como para o SimpleExecutor, fornecemos um método spawn em nosso tipo Executor que adiciona uma determinada tarefa ao mapa tasks e imediatamente a acorda empurrando seu ID para a task_queue:
// em src/task/executor.rs
impl Executor {
pub fn spawn(&mut self, task: Task) {
let task_id = task.id;
if self.tasks.insert(task.id, task).is_some() {
panic!("tarefa com o mesmo ID já em tasks");
}
self.task_queue.push(task_id).expect("fila cheia");
}
}
Se já houver uma tarefa com o mesmo ID no mapa, o método [BTreeMap::insert] a retorna. Isso nunca deve acontecer já que cada tarefa tem um ID único, então entramos em pânico neste caso porque indica um bug em nosso código. Similarmente, entramos em pânico quando a task_queue está cheia já que isso nunca deve acontecer se escolhermos um tamanho de fila grande o suficiente.
🔗Executando Tarefas
Para executar todas as tarefas na task_queue, criamos um método privado run_ready_tasks:
// em src/task/executor.rs
use core::task::{Context, Poll};
impl Executor {
fn run_ready_tasks(&mut self) {
// desestruturar `self` para evitar erros do borrow checker
let Self {
tasks,
task_queue,
waker_cache,
} = self;
while let Some(task_id) = task_queue.pop() {
let task = match tasks.get_mut(&task_id) {
Some(task) => task,
None => continue, // tarefa não existe mais
};
let waker = waker_cache
.entry(task_id)
.or_insert_with(|| TaskWaker::new(task_id, task_queue.clone()));
let mut context = Context::from_waker(waker);
match task.poll(&mut context) {
Poll::Ready(()) => {
// tarefa concluída -> removê-la e seu waker em cache
tasks.remove(&task_id);
waker_cache.remove(&task_id);
}
Poll::Pending => {}
}
}
}
}
A ideia básica desta função é similar ao nosso SimpleExecutor: Fazer loop sobre todas as tarefas na task_queue, criar um waker para cada tarefa e então consultá-las. No entanto, em vez de adicionar tarefas pendentes de volta ao final da task_queue, deixamos nossa implementação TaskWaker cuidar de adicionar tarefas acordadas de volta à fila. A implementação deste tipo waker será mostrada daqui a pouco.
Vamos olhar alguns dos detalhes de implementação deste método run_ready_tasks:
- Usamos desestruturação para dividir
selfem seus três campos para evitar alguns erros do borrow checker. Nomeadamente, nossa implementação precisa acessar oself.task_queuede dentro de uma closure, o que atualmente tenta emprestarselfcompletamente. Este é um problema fundamental do borrow checker que será resolvido quando RFC 2229 for implementado.
Nota do tradutor (Richard Alves): Na data desta tradução (2025), verifiquei que o RFC 2229 já foi implementado.
-
Para cada ID de tarefa retirado, recuperamos uma referência mutável à tarefa correspondente do mapa
tasks. Como nossa implementaçãoScancodeStreamregistra wakers antes de verificar se uma tarefa precisa ser colocada para dormir, pode acontecer que um acordar ocorra para uma tarefa que não existe mais. Neste caso, simplesmente ignoramos o acordar e continuamos com o próximo ID da fila. -
Para evitar a sobrecarga de desempenho de criar um waker em cada poll, usamos o mapa
waker_cachepara armazenar o waker para cada tarefa após ter sido criado. Para isso, usamos o métodoBTreeMap::entryem combinação comEntry::or_insert_withpara criar um novo waker se ele ainda não existir e então obter uma referência mutável a ele. Para criar um novo waker, clonamos atask_queuee a passamos junto com o ID da tarefa para a funçãoTaskWaker::new(implementação mostrada abaixo). Como atask_queueestá encapsulada em umArc, ocloneapenas incrementa a contagem de referência do valor, mas ainda aponta para a mesma fila alocada em heap. Note que reutilizar wakers assim não é possível para todas as implementações de waker, mas nosso tipoTaskWakerpermitirá isso.
Uma tarefa está finalizada quando retorna Poll::Ready. Nesse caso, nós a removemos do mapa tasks usando o método BTreeMap::remove. Também removemos seu waker em cache, se existir.
🔗Design do Waker
O trabalho do waker é empurrar o ID da tarefa acordada para a task_queue do executor. Implementamos isso criando uma nova struct TaskWaker que armazena o ID da tarefa e uma referência à task_queue:
// em src/task/executor.rs
struct TaskWaker {
task_id: TaskId,
task_queue: Arc<ArrayQueue<TaskId>>,
}
Como a propriedade da task_queue é compartilhada entre o executor e wakers, usamos o tipo wrapper Arc para implementar propriedade compartilhada contada por referência.
A implementação da operação de acordar é bem simples:
// em src/task/executor.rs
impl TaskWaker {
fn wake_task(&self) {
self.task_queue.push(self.task_id).expect("task_queue cheia");
}
}
Empurramos o task_id para a task_queue referenciada. Como modificações ao tipo ArrayQueue requerem apenas uma referência compartilhada, podemos implementar este método em &self em vez de &mut self.
🔗A Trait Wake
Para usar nosso tipo TaskWaker para consultar futures, precisamos convertê-lo em uma instância Waker primeiro. Isso é necessário porque o método Future::poll recebe uma instância Context como argumento, que só pode ser construída a partir do tipo Waker. Embora pudéssemos fazer isso fornecendo uma implementação do tipo RawWaker, é tanto mais simples quanto mais seguro em vez disso implementar a trait Wake baseada em Arc e então usar as implementações From fornecidas pela biblioteca padrão para construir o Waker.
A implementação da trait parece com isto:
// em src/task/executor.rs
use alloc::task::Wake;
impl Wake for TaskWaker {
fn wake(self: Arc<Self>) {
self.wake_task();
}
fn wake_by_ref(self: &Arc<Self>) {
self.wake_task();
}
}
Como wakers são comumente compartilhados entre o executor e as tarefas assíncronas, os métodos da trait requerem que a instância Self seja encapsulada no tipo Arc, que implementa propriedade contada por referência. Isso significa que temos que mover nosso TaskWaker para um Arc para chamá-los.
A diferença entre os métodos wake e wake_by_ref é que o último requer apenas uma referência ao Arc, enquanto o primeiro toma propriedade do Arc e, portanto, frequentemente requer um incremento da contagem de referência. Nem todos os tipos suportam acordar por referência, então implementar o método wake_by_ref é opcional. No entanto, pode levar a melhor desempenho porque evita modificações desnecessárias da contagem de referência. No nosso caso, podemos simplesmente encaminhar ambos os métodos da trait para nossa função wake_task, que requer apenas uma referência compartilhada &self.
🔗Criando Wakers
Como o tipo Waker suporta conversões From para todos os valores encapsulados em Arc que implementam a trait Wake, agora podemos implementar a função TaskWaker::new que é requerida por nosso método Executor::run_ready_tasks:
// em src/task/executor.rs
impl TaskWaker {
fn new(task_id: TaskId, task_queue: Arc<ArrayQueue<TaskId>>) -> Waker {
Waker::from(Arc::new(TaskWaker {
task_id,
task_queue,
}))
}
}
Criamos o TaskWaker usando o task_id e task_queue passados. Então encapsulamos o TaskWaker em um Arc e usamos a implementação Waker::from para convertê-lo em um Waker. Este método from cuida de construir um RawWakerVTable e uma instância RawWaker para nosso tipo TaskWaker. Caso esteja interessado em como funciona em detalhes, confira a implementação na crate alloc.
🔗Um Método run
Com nossa implementação de waker em vigor, finalmente podemos construir um método run para nosso executor:
// em src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
}
}
}
Este método apenas chama a função run_ready_tasks em um loop. Embora teoricamente pudéssemos retornar da função quando o mapa tasks se torna vazio, isso nunca aconteceria já que nossa keyboard_task nunca termina, então um simples loop deve ser suficiente. Como a função nunca retorna, usamos o tipo de retorno ! para marcar a função como divergente para o compilador.
Agora podemos mudar nosso kernel_main para usar nosso novo Executor em vez do SimpleExecutor:
// em src/main.rs
use blog_os::task::executor::Executor; // novo
fn kernel_main(boot_info: &'static BootInfo) -> ! {
// […] rotinas de inicialização, incluindo init_heap, test_main
let mut executor = Executor::new(); // novo
executor.spawn(Task::new(example_task()));
executor.spawn(Task::new(keyboard::print_keypresses()));
executor.run();
}
Só precisamos mudar a importação e o nome do tipo. Como nossa função run é marcada como divergente, o compilador sabe que nunca retorna, então não precisamos mais de uma chamada para hlt_loop no final de nossa função kernel_main.
Quando executamos nosso kernel usando cargo run agora, vemos que a entrada de teclado ainda funciona:

No entanto, a utilização de CPU do QEMU não melhorou. A razão para isso é que ainda mantemos a CPU ocupada o tempo todo. Não consultamos mais tarefas até serem acordadas novamente, mas ainda verificamos a task_queue em um loop ocupado. Para corrigir isso, precisamos colocar a CPU para dormir se não há mais trabalho a fazer.
🔗Dormir se Inativo
A ideia básica é executar a instrução hlt quando a task_queue está vazia. Esta instrução coloca a CPU para dormir até a próxima interrupção chegar. O fato de que a CPU imediatamente se torna ativa novamente em interrupções garante que ainda podemos reagir diretamente quando um manipulador de interrupção empurra para a task_queue.
Para implementar isso, criamos um novo método sleep_if_idle em nosso executor e o chamamos de nosso método run:
// em src/task/executor.rs
impl Executor {
pub fn run(&mut self) -> ! {
loop {
self.run_ready_tasks();
self.sleep_if_idle(); // novo
}
}
fn sleep_if_idle(&self) {
if self.task_queue.is_empty() {
x86_64::instructions::hlt();
}
}
}
Como chamamos sleep_if_idle diretamente após run_ready_tasks, que faz loop até a task_queue se tornar vazia, verificar a fila novamente pode parecer desnecessário. No entanto, uma interrupção de hardware pode ocorrer diretamente após run_ready_tasks retornar, então pode haver uma nova tarefa na fila no momento em que a função sleep_if_idle é chamada. Apenas se a fila ainda estiver vazia, colocamos a CPU para dormir executando a instrução hlt através da função wrapper instructions::hlt fornecida pela crate x86_64.
Infelizmente, ainda há uma condição de corrida sutil nesta implementação. Como interrupções são assíncronas e podem acontecer a qualquer momento, é possível que uma interrupção aconteça logo entre a verificação is_empty e a chamada para hlt:
if self.task_queue.is_empty() {
/// <--- interrupção pode acontecer aqui
x86_64::instructions::hlt();
}
Caso esta interrupção empurre para a task_queue, colocamos a CPU para dormir mesmo que agora haja uma tarefa pronta. No pior caso, isso poderia atrasar o tratamento de uma interrupção de teclado até o próximo pressionamento de tecla ou a próxima interrupção de temporizador. Então como evitamos isso?
A resposta é desabilitar interrupções na CPU antes da verificação e atomicamente habilitá-las novamente junto com a instrução hlt. Desta forma, todas as interrupções que acontecem no meio são atrasadas após a instrução hlt para que nenhum acordar seja perdido. Para implementar esta abordagem, podemos usar a função interrupts::enable_and_hlt fornecida pela crate x86_64.
A implementação atualizada de nossa função sleep_if_idle parece com isto:
// em src/task/executor.rs
impl Executor {
fn sleep_if_idle(&self) {
use x86_64::instructions::interrupts::{self, enable_and_hlt};
interrupts::disable();
if self.task_queue.is_empty() {
enable_and_hlt();
} else {
interrupts::enable();
}
}
}
Para evitar condições de corrida, desabilitamos interrupções antes de verificar se a task_queue está vazia. Se estiver, usamos a função enable_and_hlt para habilitar interrupções e colocar a CPU para dormir como uma única operação atômica. Caso a fila não esteja mais vazia, significa que uma interrupção acordou uma tarefa após run_ready_tasks retornar. Nesse caso, habilitamos interrupções novamente e continuamos a execução diretamente sem executar hlt.
Agora nosso executor coloca adequadamente a CPU para dormir quando não há trabalho a fazer. Podemos ver que o processo QEMU tem uma utilização de CPU muito menor quando executamos nosso kernel usando cargo run novamente.
🔗Extensões Possíveis
Nosso executor agora é capaz de executar tarefas de forma eficiente. Ele utiliza notificações de waker para evitar consultar tarefas em espera e coloca a CPU para dormir quando atualmente não há trabalho a fazer. No entanto, nosso executor ainda é bem básico e há muitas formas possíveis de estender sua funcionalidade:
- Agendamento: Para nossa
task_queue, atualmente usamos o tipoVecDequepara implementar uma estratégia first in first out (FIFO), que também é frequentemente chamada de agendamento round robin. Esta estratégia pode não ser a mais eficiente para todas as cargas de trabalho. Por exemplo, pode fazer sentido priorizar tarefas críticas em latência ou tarefas que fazem muita E/S. Veja o capítulo de agendamento do livro Operating Systems: Three Easy Pieces ou o artigo da Wikipedia sobre agendamento para mais informações. - Spawning de Tarefa: Nosso método
Executor::spawnatualmente requer uma referência&mut selfe, portanto, não está mais disponível após invocar o métodorun. Para corrigir isso, poderíamos criar um tipoSpawneradicional que compartilha algum tipo de fila com o executor e permite criação de tarefas de dentro das próprias tarefas. A fila poderia ser a própriatask_queuediretamente ou uma fila separada que o executor verifica em seu loop de execução. - Utilizando Threads: Ainda não temos suporte para threads, mas o adicionaremos no próximo post. Isso tornará possível lançar múltiplas instâncias do executor em threads diferentes. A vantagem desta abordagem é que o atraso imposto por tarefas de longa execução pode ser reduzido porque outras tarefas podem executar concorrentemente. Esta abordagem também permite utilizar múltiplos núcleos de CPU.
- Balanceamento de Carga: Ao adicionar suporte a threading, torna-se importante saber como distribuir as tarefas entre os executores para garantir que todos os núcleos de CPU sejam utilizados. Uma técnica comum para isso é work stealing.
🔗Resumo
Começamos este post introduzindo multitarefa e diferenciando entre multitarefa preemptiva, que interrompe forçadamente tarefas em execução regularmente, e multitarefa cooperativa, que permite que tarefas executem até voluntariamente cederem o controle da CPU.
Então exploramos como o suporte do Rust para async/await fornece uma implementação no nível da linguagem de multitarefa cooperativa. Rust baseia sua implementação em cima da trait Future baseada em polling, que abstrai tarefas assíncronas. Usando async/await, é possível trabalhar com futures quase como com código síncrono normal. A diferença é que funções assíncronas retornam uma Future novamente, que precisa ser adicionada a um executor em algum ponto para executá-la.
Por trás dos bastidores, o compilador transforma código async/await em máquinas de estados, com cada operação .await correspondendo a um possível ponto de pausa. Ao utilizar seu conhecimento sobre o programa, o compilador é capaz de salvar apenas o estado mínimo para cada ponto de pausa, resultando em um consumo de memória muito pequeno por tarefa. Um desafio é que as máquinas de estados geradas podem conter structs auto-referenciais, por exemplo quando variáveis locais da função assíncrona se referenciam. Para evitar invalidação de ponteiro, Rust usa o tipo Pin para garantir que futures não possam mais ser movidas na memória após serem consultadas pela primeira vez.
Para nossa implementação, primeiro criamos um executor muito básico que consulta todas as tarefas spawnadas em um loop ocupado sem usar o tipo Waker de forma alguma. Então mostramos a vantagem das notificações de waker implementando uma tarefa de teclado assíncrona. A tarefa define uma SCANCODE_QUEUE estática usando o tipo ArrayQueue sem mutex fornecido pela crate crossbeam. Em vez de lidar com pressionamentos de tecla diretamente, o manipulador de interrupção de teclado agora coloca todos os scancodes recebidos na fila e então acorda o Waker registrado para sinalizar que nova entrada está disponível. Na extremidade receptora, criamos um tipo ScancodeStream para fornecer uma Future resolvendo para o próximo scancode na fila. Isso tornou possível criar uma tarefa print_keypresses assíncrona que usa async/await para interpretar e imprimir os scancodes na fila.
Para utilizar as notificações de waker da tarefa de teclado, criamos um novo tipo Executor que usa uma task_queue compartilhada com Arc para tarefas prontas. Implementamos um tipo TaskWaker que empurra o ID de tarefas acordadas diretamente para esta task_queue, que então são consultadas novamente pelo executor. Para economizar energia quando nenhuma tarefa é executável, adicionamos suporte para colocar a CPU para dormir usando a instrução hlt. Finalmente, discutimos algumas extensões potenciais ao nosso executor, por exemplo, fornecer suporte multi-core.
🔗O Que Vem a Seguir?
Usando async/await, agora temos suporte básico para multitarefa cooperativa em nosso kernel. Embora multitarefa cooperativa seja muito eficiente, ela leva a problemas de latência quando tarefas individuais continuam executando por muito tempo, impedindo assim outras tarefas de executar. Por esta razão, faz sentido também adicionar suporte para multitarefa preemptiva ao nosso kernel.
No próximo post, introduziremos threads como a forma mais comum de multitarefa preemptiva. Além de resolver o problema de tarefas de longa execução, threads também nos prepararão para utilizar múltiplos núcleos de CPU e executar programas de usuário não confiáveis no futuro.
Comentários
Teve algum problema, quer deixar um feedback ou discutir mais ideias? Fique à vontade para deixar um comentário aqui! Por favor, use o inglês e siga o código de conduta do Rust. Este tópico de comentários está diretamente vinculado a uma discussão no GitHub, então você também pode comentar lá se preferir.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor, deixe seus comentários em inglês se possível.