Interrupciones de Hardware
Contenido Traducido: Esta es una traducción comunitaria del post Hardware Interrupts. Puede estar incompleta, desactualizada o contener errores. ¡Por favor reporta cualquier problema!
Traducción por @dobleuber.
En esta publicación, configuramos el controlador de interrupciones programable para redirigir correctamente las interrupciones de hardware a la CPU. Para manejar estas interrupciones, agregamos nuevas entradas a nuestra tabla de descriptores de interrupciones, tal como lo hicimos con nuestros manejadores de excepciones. Aprenderemos cómo obtener interrupciones de temporizador periódicas y cómo recibir entrada del teclado.
Este blog se desarrolla abiertamente en GitHub. Si tienes algún problema o pregunta, por favor abre un problema allí. También puedes dejar comentarios al final. El código fuente completo de esta publicación se puede encontrar en la rama post-07.
Tabla de Contenidos
🔗Visión General
Las interrupciones proporcionan una forma de notificar a la CPU sobre dispositivos de hardware conectados. Así que, en lugar de permitir que el kernel verifique periódicamente el teclado en busca de nuevos caracteres (un proceso llamado polling), el teclado puede notificar al kernel sobre cada pulsación de tecla. Esto es mucho más eficiente porque el kernel solo necesita actuar cuando algo ha sucedido. También permite tiempos de reacción más rápidos, ya que el kernel puede reaccionar inmediatamente y no solo en la siguiente consulta.
Conectar todos los dispositivos de hardware directamente a la CPU no es posible. En su lugar, un controlador de interrupciones (interrupt controller) separado agrega las interrupciones de todos los dispositivos y luego notifica a la CPU:
____________ _____
Temporizador ------------> | | | |
Teclado ---------> | Interrupt |---------> | CPU |
Otro Hardware ---> | Controller | |_____|
Etc. -------------> |____________|
La mayoría de los controladores de interrupciones son programables, lo que significa que admiten diferentes niveles de prioridad para las interrupciones. Por ejemplo, esto permite dar a las interrupciones del temporizador una prioridad más alta que a las interrupciones del teclado para asegurar un mantenimiento del tiempo preciso.
A diferencia de las excepciones, las interrupciones de hardware ocurren de manera asincrónica. Esto significa que son completamente independientes del código ejecutado y pueden ocurrir en cualquier momento. Por lo tanto, de repente tenemos una forma de concurrencia en nuestro kernel con todos los posibles errores relacionados con la concurrencia. El estricto modelo de propiedad de Rust nos ayuda aquí porque prohíbe el estado global mutable. Sin embargo, los bloqueos mutuos (deadlocks) siguen siendo posibles, como veremos más adelante en esta publicación.
🔗El 8259 PIC
El Intel 8259 es un controlador de interrupciones programable (PIC) introducido en 1976. Ha sido reemplazado durante mucho tiempo por el nuevo APIC, pero su interfaz aún se admite en sistemas actuales por razones de compatibilidad hacia atrás. El PIC 8259 es significativamente más fácil de configurar que el APIC, así que lo utilizaremos para introducirnos a las interrupciones antes de cambiar al APIC en una publicación posterior.
El 8259 tiene ocho líneas de interrupción y varias líneas para comunicarse con la CPU. Los sistemas típicos de aquella época estaban equipados con dos instancias del PIC 8259, uno primario y uno secundario, conectados a una de las líneas de interrupción del primario:
____________ ____________
Reloj en Tiempo Real --> | | Temporizador -------------> | |
ACPI -------------> | | Teclado-----------> | | _____
Disponible --------> | Secundario |----------------------> | Primario | | |
Disponible --------> | Interrupt | Puerto Serial 2 -----> | Interrupt |---> | CPU |
Ratón ------------> | Controller | Puerto Serial 1 -----> | Controller | |_____|
Co-Procesador -----> | | Puerto Paralelo 2/3 -> | |
ATA Primario ------> | | Disco flexible -------> | |
ATA Secundario ----> |____________| Puerto Paralelo 1----> |____________|
Esta gráfica muestra la asignación típica de líneas de interrupción. Vemos que la mayoría de las 15 líneas tienen un mapeo fijo, por ejemplo, la línea 4 del PIC secundario está asignada al ratón.
Cada controlador se puede configurar a través de dos puertos de I/O, un puerto “comando” y un puerto “datos”. Para el controlador primario, estos puertos son 0x20 (comando) y 0x21 (datos). Para el controlador secundario, son 0xa0 (comando) y 0xa1 (datos). Para más información sobre cómo se pueden configurar los PIC, consulta el artículo en osdev.org.
🔗Implementación
La configuración predeterminada de los PIC no es utilizable porque envía números de vector de interrupción en el rango de 0–15 a la CPU. Estos números ya están ocupados por excepciones de la CPU. Por ejemplo, el número 8 corresponde a una doble falla. Para corregir este problema de superposición, necesitamos volver a asignar las interrupciones del PIC a números diferentes. El rango real no importa siempre que no se superponga con las excepciones, pero típicamente se elige el rango de 32–47, porque estos son los primeros números libres después de los 32 espacios de excepción.
La configuración se realiza escribiendo valores especiales en los puertos de comando y datos de los PIC. Afortunadamente, ya existe una crate llamada pic8259, por lo que no necesitamos escribir la secuencia de inicialización nosotros mismos. Sin embargo, si estás interesado en cómo funciona, consulta su código fuente. Es bastante pequeño y está bien documentado.
Para agregar la crate como una dependencia, agregamos lo siguiente a nuestro proyecto:
# en Cargo.toml
[dependencies]
pic8259 = "0.10.1"
La principal abstracción proporcionada por la crate es la estructura ChainedPics que representa la disposición primario/secundario del PIC que vimos arriba. Está diseñada para ser utilizada de la siguiente manera:
// en src/interrupts.rs
use pic8259::ChainedPics;
use spin;
pub const PIC_1_OFFSET: u8 = 32;
pub const PIC_2_OFFSET: u8 = PIC_1_OFFSET + 8;
pub static PICS: spin::Mutex<ChainedPics> =
spin::Mutex::new(unsafe { ChainedPics::new(PIC_1_OFFSET, PIC_2_OFFSET) });
Como se mencionó anteriormente, estamos estableciendo los desplazamientos para los PIC en el rango de 32–47. Al envolver la estructura ChainedPics en un Mutex, podemos obtener un acceso mutable seguro (a través del método lock), que necesitamos en el siguiente paso. La función ChainedPics::new es insegura porque desplazamientos incorrectos podrían causar un comportamiento indefinido.
Ahora podemos inicializar el PIC 8259 en nuestra función init:
// en src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
unsafe { interrupts::PICS.lock().initialize() }; // nuevo
}
Usamos la función initialize para realizar la inicialización del PIC. Al igual que la función ChainedPics::new, esta función también es insegura porque puede causar un comportamiento indefinido si el PIC está mal configurado.
Si todo va bien, deberíamos seguir viendo el mensaje “¡No se ha bloqueado!” al ejecutar cargo run.
🔗Habilitando Interrupciones
Hasta ahora, nada sucedió porque las interrupciones todavía están deshabilitadas en la configuración de la CPU. Esto significa que la CPU no escucha al controlador de interrupciones en absoluto, por lo que ninguna interrupción puede llegar a la CPU. Cambiemos eso:
// en src/lib.rs
pub fn init() {
gdt::init();
interrupts::init_idt();
unsafe { interrupts::PICS.lock().initialize() };
x86_64::instructions::interrupts::enable(); // nuevo
}
La función interrupts::enable de la crate x86_64 ejecuta la instrucción especial sti (“set interrupts”) para habilitar las interrupciones externas. Cuando intentamos cargo run ahora, vemos que ocurre una doble falla:
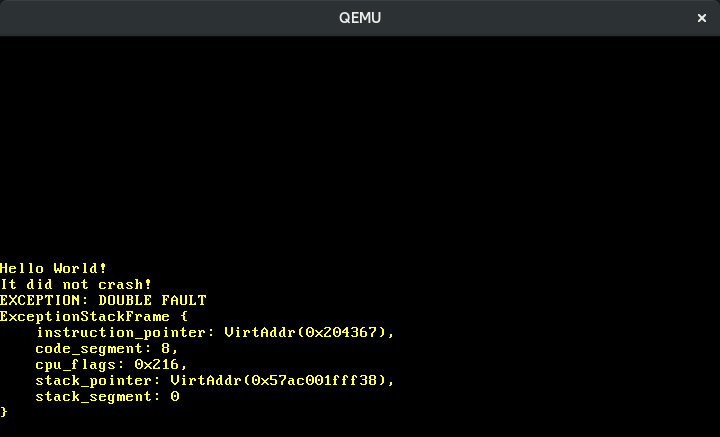
La razón de esta doble falla es que el temporizador de hardware (el Intel 8253, para ser exactos) está habilitado por defecto, por lo que comenzamos a recibir interrupciones de temporizador tan pronto como habilitamos las interrupciones. Dado que aún no hemos definido una función de manejador para ello, se invoca nuestro manejador de doble falla.
🔗Manejando Interrupciones de Temporizador
Como vemos en la gráfica arriba, el temporizador utiliza la línea 0 del PIC primario. Esto significa que llega a la CPU como interrupción 32 (0 + desplazamiento 32). En lugar de codificar rígidamente el índice 32, lo almacenamos en un enum InterruptIndex:
// en src/interrupts.rs
#[derive(Debug, Clone, Copy)]
#[repr(u8)]
pub enum InterruptIndex {
Temporizador = PIC_1_OFFSET,
}
impl InterruptIndex {
fn as_u8(self) -> u8 {
self as u8
}
fn as_usize(self) -> usize {
usize::from(self.as_u8())
}
}
El enum es un enum tipo C para que podamos especificar directamente el índice para cada variante. El atributo repr(u8) especifica que cada variante se representa como un u8. Agregaremos más variantes para otras interrupciones en el futuro.
Ahora podemos agregar una función de manejador para la interrupción del temporizador:
// en src/interrupts.rs
use crate::print;
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
[…]
idt[InterruptIndex::Temporizador.as_usize()]
.set_handler_fn(timer_interrupt_handler); // nuevo
idt
};
}
extern "x86-interrupt" fn timer_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!(".");
}
Nuestro timer_interrupt_handler tiene la misma firma que nuestros manejadores de excepciones, porque la CPU reacciona de manera idéntica a las excepciones y a las interrupciones externas (la única diferencia es que algunas excepciones empujan un código de error). La estructura InterruptDescriptorTable implementa el rasgo IndexMut, por lo que podemos acceder a entradas individuales a través de la sintaxis de indexación de arrays.
En nuestro manejador de interrupciones del temporizador, imprimimos un punto en la pantalla. Como la interrupción del temporizador ocurre periódicamente, esperaríamos ver un punto apareciendo en cada tick del temporizador. Sin embargo, cuando lo ejecutamos, vemos que solo se imprime un solo punto:
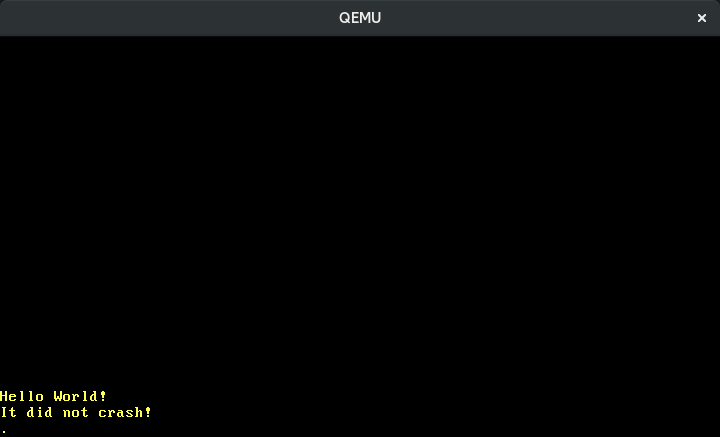
🔗Fin de la Interrupción
La razón es que el PIC espera una señal explícita de “fin de interrupción” (EOI) de nuestro manejador de interrupciones. Esta señal le dice al controlador que la interrupción ha sido procesada y que el sistema está listo para recibir la siguiente interrupción. Así que el PIC piensa que todavía estamos ocupados procesando la primera interrupción del temporizador y espera pacientemente la señal EOI antes de enviar la siguiente.
Para enviar el EOI, usamos nuestra estructura estática PICS nuevamente:
// en src/interrupts.rs
extern "x86-interrupt" fn timer_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!(".");
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Temporizador.as_u8());
}
}
El método notify_end_of_interrupt determina si el PIC primario o secundario envió la interrupción y luego utiliza los puertos de comando y datos para enviar una señal EOI a los controladores respectivos. Si el PIC secundario envió la interrupción, ambos PIC deben ser notificados porque el PIC secundario está conectado a una línea de entrada del PIC primario.
Debemos tener cuidado de usar el número de vector de interrupción correcto; de lo contrario, podríamos eliminar accidentalmente una interrupción no enviada importante o hacer que nuestro sistema se cuelgue. Esta es la razón por la que la función es insegura.
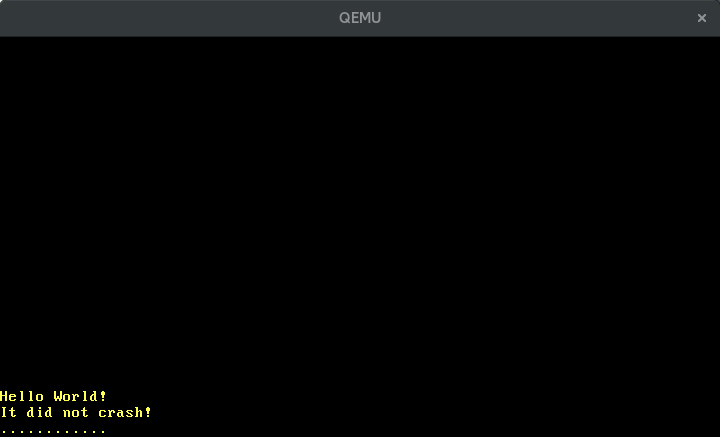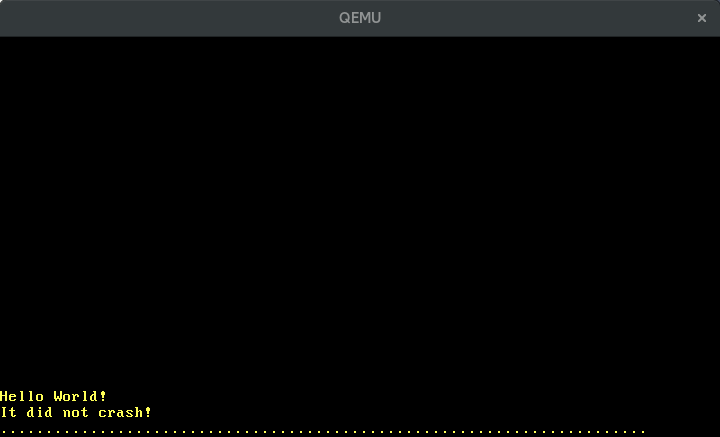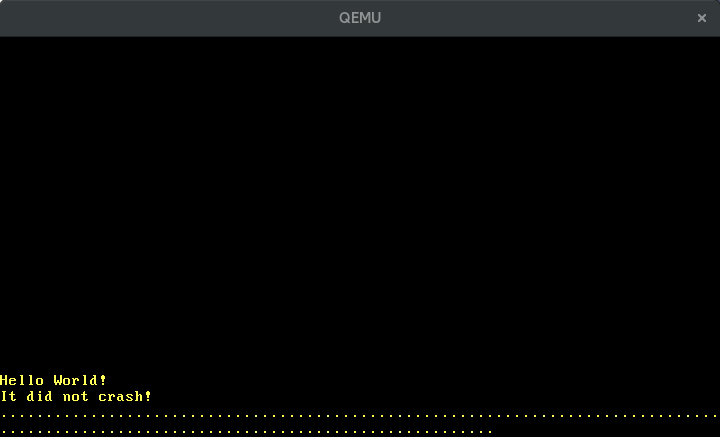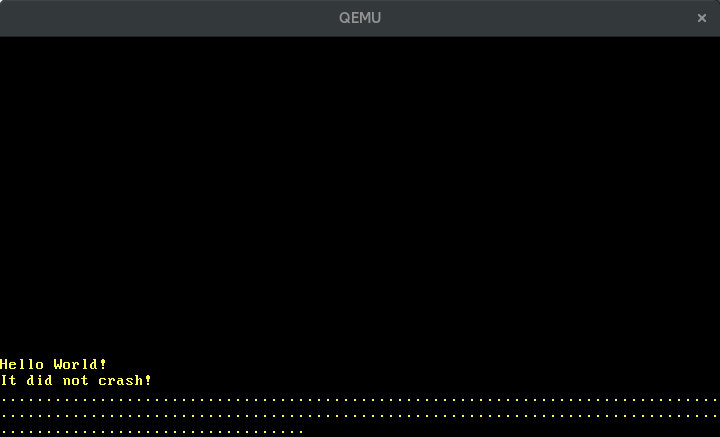
Cuando ejecutamos ahora cargo run, vemos puntos apareciendo periódicamente en la pantalla:
🔗Configurando el Temporizador
El temporizador de hardware que usamos se llama Temporizador de Intervalo Programable (Programmable Interval Timer), o PIT, para abreviar. Como su nombre indica, es posible configurar el intervalo entre dos interrupciones. No entraremos en detalles aquí porque pronto pasaremos al temporizador APIC, pero la wiki de OSDev tiene un artículo extenso sobre la configuración del PIT.
🔗Bloqueos Mutuos
Ahora tenemos una forma de concurrencia en nuestro kernel: Las interrupciones del temporizador ocurren de manera asincrónica, por lo que pueden interrumpir nuestra función _start en cualquier momento. Afortunadamente, el sistema de propiedad de Rust previene muchos tipos de errores relacionados con la concurrencia en tiempo de compilación. Una notable excepción son los bloqueos mutuos (deadlocks). Los bloqueos mutuos ocurren si un hilo intenta adquirir un bloqueo que nunca se liberará. Así, el hilo se cuelga indefinidamente.
Ya podemos provocar un bloqueo mutuo en nuestro kernel. Recuerda que nuestra macro println llama a la función vga_buffer::_print, que bloquea un WRITER global utilizando un spinlock:
// en src/vga_buffer.rs
[…]
#[doc(hidden)]
pub fn _print(args: fmt::Arguments) {
use core::fmt::Write;
WRITER.lock().write_fmt(args).unwrap();
}
Bloquea el WRITER, llama a write_fmt en él y lo desbloquea implícitamente al final de la función. Ahora imagina que una interrupción ocurre mientras WRITER está bloqueado y el manejador de interrupciones intenta imprimir algo también:
| Timestep | _start | manejador_interrupcion |
|---|---|---|
| 0 | llama a println! | |
| 1 | print bloquea WRITER | |
| 2 | ocurre la interrupción, el manejador comienza a ejecutarse | |
| 3 | llama a println! | |
| 4 | print intenta bloquear WRITER (ya bloqueado) | |
| 5 | print intenta bloquear WRITER (ya bloqueado) | |
| … | … | |
| nunca | desbloquear WRITER |
El WRITER está bloqueado, así que el manejador de interrupciones espera hasta que se libere. Pero esto nunca sucede, porque la función _start solo continúa ejecutándose después de que el manejador de interrupciones regrese. Así, todo el sistema se cuelga.
🔗Provocando un Bloqueo Mutuo
Podemos provocar fácilmente un bloqueo mutuo así en nuestro kernel imprimiendo algo en el bucle al final de nuestra función _start:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…]
loop {
use blog_os::print;
print!("-"); // nuevo
}
}
Cuando lo ejecutamos en QEMU, obtenemos una salida de la forma:
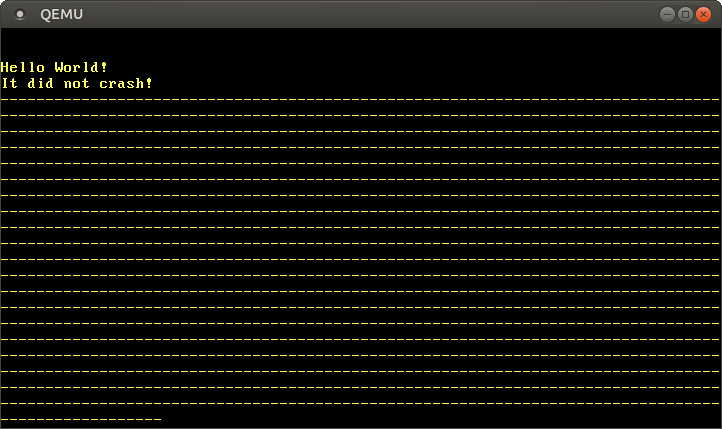
Vemos que solo se imprimen un número limitado de guiones hasta que ocurre la primera interrupción del temporizador. Entonces el sistema se cuelga porque el manejador de interrupciones del temporizador provoca un bloqueo mutuo cuando intenta imprimir un punto. Esta es la razón por la que no vemos puntos en la salida anterior.
El número real de guiones varía entre ejecuciones porque la interrupción del temporizador ocurre de manera asincrónica. Esta no determinación es lo que hace que los errores relacionados con la concurrencia sean tan difíciles de depurar.
🔗Solucionando el Bloqueo Mutuo
Para evitar este bloqueo mutuo, podemos deshabilitar las interrupciones mientras el Mutex está bloqueado:
// en src/vga_buffer.rs
/// Imprime la cadena formateada dada en el búfer de texto VGA
/// a través de la instancia global `WRITER`.
#[doc(hidden)]
pub fn _print(args: fmt::Arguments) {
use core::fmt::Write;
use x86_64::instructions::interrupts; // nuevo
interrupts::without_interrupts(|| { // nuevo
WRITER.lock().write_fmt(args).unwrap();
});
}
La función without_interrupts toma un closure y lo ejecuta en un entorno sin interrupciones. La usamos para asegurarnos de que no se produzca ninguna interrupción mientras el Mutex esté bloqueado. Cuando ejecutamos nuestro kernel ahora, vemos que sigue funcionando sin colgarse. (Todavía no notamos ningún punto, pero esto es porque están deslizándose demasiado rápido. Intenta ralentizar la impresión, por ejemplo, poniendo un for _ in 0..10000 {} dentro del bucle).
Podemos aplicar el mismo cambio a nuestra función de impresión serial para asegurarnos de que tampoco ocurran bloqueos mutuos con ella:
// en src/serial.rs
#[doc(hidden)]
pub fn _print(args: ::core::fmt::Arguments) {
use core::fmt::Write;
use x86_64::instructions::interrupts; // nuevo
interrupts::without_interrupts(|| { // nuevo
SERIAL1
.lock()
.write_fmt(args)
.expect("Error al imprimir por serie");
});
}
Ten en cuenta que deshabilitar interrupciones no debería ser una solución general. El problema es que aumenta la latencia de interrupción en el peor de los casos, es decir, el tiempo hasta que el sistema reacciona a una interrupción. Por lo tanto, las interrupciones solo deben deshabilitarse por un tiempo muy corto.
🔗Solucionando una Condición de Carrera
Si ejecutas cargo test, podrías ver que la prueba test_println_output falla:
> cargo test --lib
[…]
Ejecutando 4 pruebas
test_breakpoint_exception...[ok]
test_println... [ok]
test_println_many... [ok]
test_println_output... [failed]
Error: se bloqueó en 'assertion failed: `(left == right)`
left: `'.'`,
right: `'S'`', src/vga_buffer.rs:205:9
La razón es una condición de carrera entre la prueba y nuestro manejador de temporizador. Recuerda que la prueba se ve así:
// en src/vga_buffer.rs
#[test_case]
fn test_println_output() {
let s = "Una cadena de prueba que cabe en una sola línea";
println!("{}", s);
for (i, c) in s.chars().enumerate() {
let screen_char = WRITER.lock().buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
}
La condición de carrera ocurre porque el manejador de interrupciones del temporizador podría ejecutarse entre el println y la lectura de los caracteres en la pantalla. Ten en cuenta que esto no es una peligrosa data race, que Rust previene completamente en tiempo de compilación. Consulta el Rustonomicon para más detalles.
Para solucionar esto, necesitamos mantener el WRITER bloqueado durante toda la duración de la prueba, para que el manejador de temporizador no pueda escribir un carácter en la pantalla en medio. La prueba corregida se ve así:
// en src/vga_buffer.rs
#[test_case]
fn test_println_output() {
use core::fmt::Write;
use x86_64::instructions::interrupts;
let s = "Una cadena de prueba que cabe en una sola línea";
interrupts::without_interrupts(|| {
let mut writer = WRITER.lock();
writeln!(writer, "\n{}", s).expect("writeln falló");
for (i, c) in s.chars().enumerate() {
let screen_char = writer.buffer.chars[BUFFER_HEIGHT - 2][i].read();
assert_eq!(char::from(screen_char.ascii_character), c);
}
});
}
Hemos realizado los siguientes cambios:
- Mantenemos el escritor bloqueado durante toda la prueba utilizando el método
lock()explícitamente. En lugar deprintln, usamos la macrowritelnque permite imprimir en un escritor que ya está bloqueado. - Para evitar otro bloqueo mutuo, deshabilitamos las interrupciones durante la duración de la prueba. De lo contrario, la prueba podría ser interrumpida mientras el escritor sigue bloqueado.
- Dado que el manejador de interrupciones del temporizador aún puede ejecutarse antes de la prueba, imprimimos una nueva línea adicional
\nantes de imprimir la cadenas. De esta manera, evitamos fallar en la prueba cuando el manejador de temporizador ya ha impreso algunos puntos en la línea actual.
Con los cambios anteriores, cargo test ahora tiene éxito de manera determinista.
Esta fue una condición de carrera muy inofensiva que solo causó una falla en la prueba. Como puedes imaginar, otras condiciones de carrera pueden ser mucho más difíciles de depurar debido a su naturaleza no determinista. Afortunadamente, Rust nos previene de condiciones de data race, que son la clase más seria de condiciones de carrera, ya que pueden causar todo tipo de comportamientos indefinidos, incluyendo bloqueos del sistema y corrupción silenciosa de memoria.
🔗La Instrucción hlt
Hasta ahora, hemos utilizado una simple instrucción de bucle vacío al final de nuestras funciones _start y panic. Esto hace que la CPU gire sin descanso, y por lo tanto funciona como se espera. Pero también es muy ineficiente, porque la CPU sigue funcionando a toda velocidad incluso cuando no hay trabajo que hacer. Puedes ver este problema en tu administrador de tareas cuando ejecutas tu kernel: el proceso de QEMU necesita cerca del 100% de CPU todo el tiempo.
Lo que realmente queremos hacer es detener la CPU hasta que llegue la próxima interrupción. Esto permite que la CPU entre en un estado de sueño en el que consume mucho menos energía. La instrucción hlt hace exactamente eso. Vamos a usar esta instrucción para crear un bucle infinito eficiente en energía:
// en src/lib.rs
pub fn hlt_loop() -> ! {
loop {
x86_64::instructions::hlt();
}
}
La función instructions::hlt es solo un delgado envoltorio alrededor de la instrucción de ensamblador. Es segura porque no hay forma de que comprometa la seguridad de la memoria.
Ahora podemos utilizar este hlt_loop en lugar de los bucles infinitos en nuestras funciones _start y panic:
// en src/main.rs
#[no_mangle]
pub extern "C" fn _start() -> ! {
[…]
println!("¡No se ha bloqueado!");
blog_os::hlt_loop(); // nuevo
}
#[cfg(not(test))]
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
println!("{}", info);
blog_os::hlt_loop(); // nuevo
}
Actualicemos también nuestro lib.rs:
// en src/lib.rs
/// Punto de entrada para `cargo test`
#[cfg(test)]
#[no_mangle]
pub extern "C" fn _start() -> ! {
init();
test_main();
hlt_loop(); // nuevo
}
pub fn test_panic_handler(info: &PanicInfo) -> ! {
serial_println!("[falló]\n");
serial_println!("Error: {}\n", info);
exit_qemu(QemuExitCode::Failed);
hlt_loop(); // nuevo
}
Cuando ejecutamos nuestro kernel ahora en QEMU, vemos un uso de CPU mucho más bajo.
🔗Entrada del Teclado
Ahora que podemos manejar interrupciones de dispositivos externos, finalmente podemos agregar soporte para la entrada del teclado. Esto nos permitirá interactuar con nuestro kernel por primera vez.
Al igual que el temporizador de hardware, el controlador del teclado ya está habilitado por defecto. Así que cuando presionas una tecla, el controlador del teclado envía una interrupción al PIC, que la reenvía a la CPU. La CPU busca una función de manejador en la IDT, pero la entrada correspondiente está vacía. Por lo tanto, ocurre una doble falla.
Así que agreguemos una función de manejador para la interrupción del teclado. Es bastante similar a cómo definimos el manejador para la interrupción del temporizador; solo utiliza un número de interrupción diferente:
// en src/interrupts.rs
#[derive(Debug, Clone, Copy)]
#[repr(u8)]
pub enum InterruptIndex {
Temporizador = PIC_1_OFFSET,
Teclado, // nuevo
}
lazy_static! {
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
[…]
// nuevo
idt[InterruptIndex::Teclado.as_usize()]
.set_handler_fn(keyboard_interrupt_handler);
idt
};
}
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
print!("k");
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Teclado.as_u8());
}
}
Como vemos en la gráfica arriba, el teclado utiliza la línea 1 del PIC primario. Esto significa que llega a la CPU como interrupción 33 (1 + desplazamiento 32). Agregamos este índice como una nueva variante Teclado al enum InterruptIndex. No necesitamos especificar el valor explícitamente, ya que de forma predeterminada toma el valor anterior más uno, que también es 33. En el manejador de interrupciones, imprimimos una k y enviamos la señal de fin de interrupción al controlador de interrupciones.
Ahora vemos que una k aparece en la pantalla cuando presionamos una tecla. Sin embargo, esto solo funciona para la primera tecla que presionamos. Incluso si seguimos presionando teclas, no aparecen más ks en la pantalla. Esto se debe a que el controlador del teclado no enviará otra interrupción hasta que hayamos leído el llamado scancode de la tecla presionada.
🔗Leyendo los Scancodes
Para averiguar qué tecla fue presionada, necesitamos consultar al controlador del teclado. Hacemos esto leyendo desde el puerto de datos del controlador PS/2, que es el puerto de I/O con el número 0x60:
// en src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
print!("{}", scancode);
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Teclado.as_u8());
}
}
Usamos el tipo Port de la crate x86_64 para leer un byte del puerto de datos del teclado. Este byte se llama scancode y representa la pulsación/liberación de la tecla. Aún no hacemos nada con el scancode, excepto imprimirlo en la pantalla:
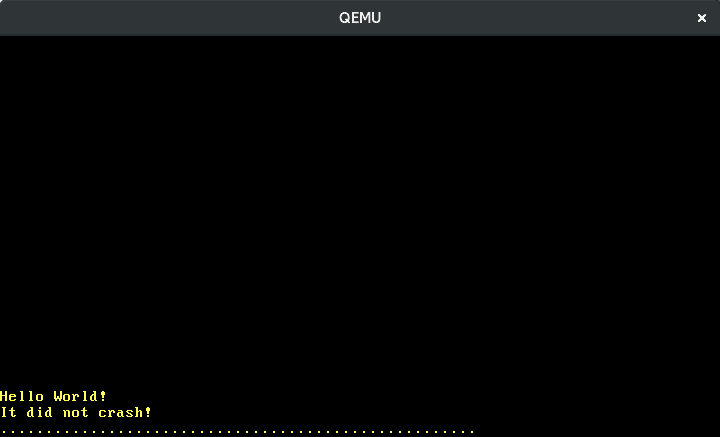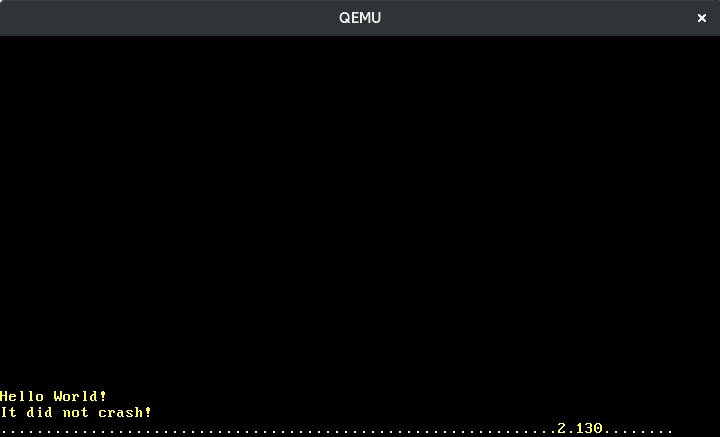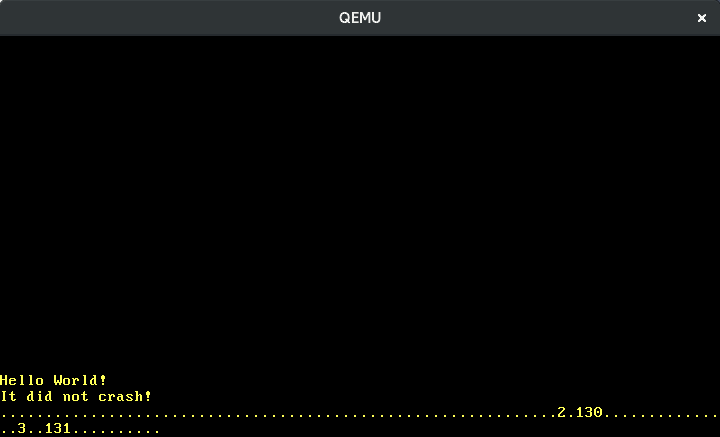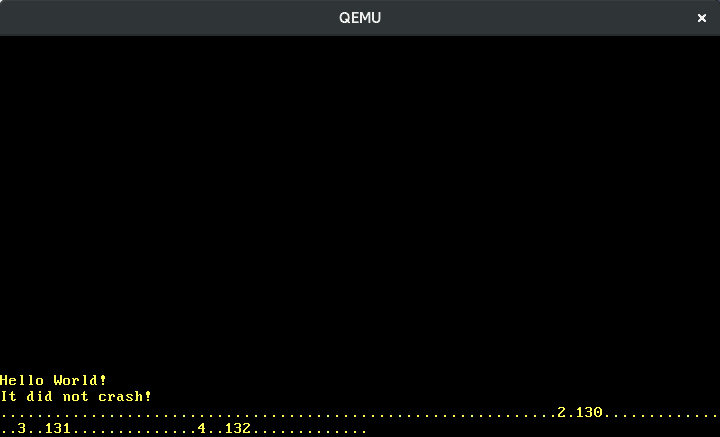
La imagen anterior muestra que estoy escribiendo lentamente “123”. Vemos que las teclas adyacentes tienen scancodes adyacentes y que presionar una tecla causa un scancode diferente al soltarla. Pero, ¿cómo traducimos los scancodes a las acciones de las teclas exactamente?
🔗Interpretando los Scancodes
Existen tres estándares diferentes para el mapeo entre scancodes y teclas, los llamados conjuntos de scancode. Los tres se remontan a los teclados de las primeras computadoras IBM: el IBM XT, el IBM 3270 PC y el IBM AT. Afortunadamente, las computadoras posteriores no continuaron con la tendencia de definir nuevos conjuntos de scancode, sino que emularon los conjuntos existentes y los ampliaron. Hoy en día, la mayoría de los teclados pueden configurarse para emular cualquiera de los tres conjuntos.
Por defecto, los teclados PS/2 emulan el conjunto de scancode 1 (“XT”). En este conjunto, los 7 bits inferiores de un byte de scancode definen la tecla, y el bit más significativo define si se trata de una pulsación (“0”) o una liberación (“1”). Las teclas que no estaban presentes en el teclado original de IBM XT, como la tecla de entrada en el teclado numérico, generan dos scancodes en sucesión: un byte de escape 0xe0 seguido de un byte que representa la tecla. Para obtener una lista de todos los scancodes del conjunto 1 y sus teclas correspondientes, consulta la Wiki de OSDev.
Para traducir los scancodes a teclas, podemos usar una instrucción match:
// en src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use x86_64::instructions::port::Port;
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
// nuevo
let key = match scancode {
0x02 => Some('1'),
0x03 => Some('2'),
0x04 => Some('3'),
0x05 => Some('4'),
0x06 => Some('5'),
0x07 => Some('6'),
0x08 => Some('7'),
0x09 => Some('8'),
0x0a => Some('9'),
0x0b => Some('0'),
_ => None,
};
if let Some(key) = key {
print!("{}", key);
}
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Teclado.as_u8());
}
}
El código anterior traduce las pulsaciones de las teclas numéricas 0-9 y ignora todas las otras teclas. Utiliza una declaración match para asignar un carácter o None a cada scancode. Luego, utiliza if let para desestructurar la opción key. Al usar el mismo nombre de variable key en el patrón, [somos sombras de] la declaración anterior, lo cual es un patrón común para desestructurar tipos Option en Rust.
Ahora podemos escribir números:
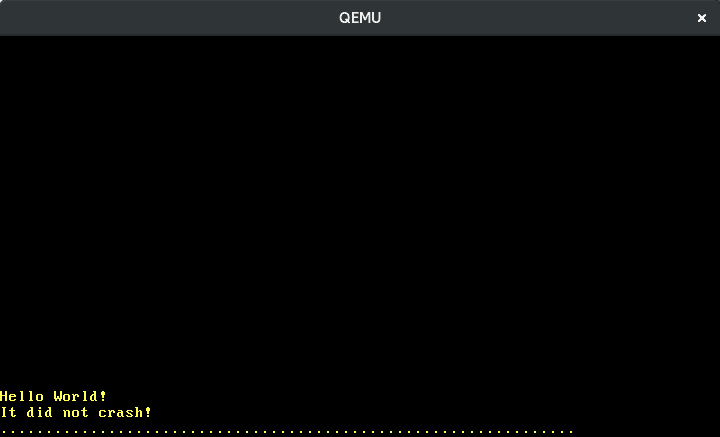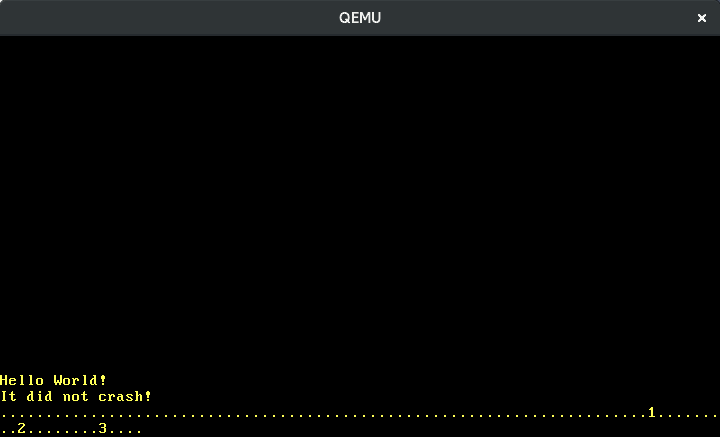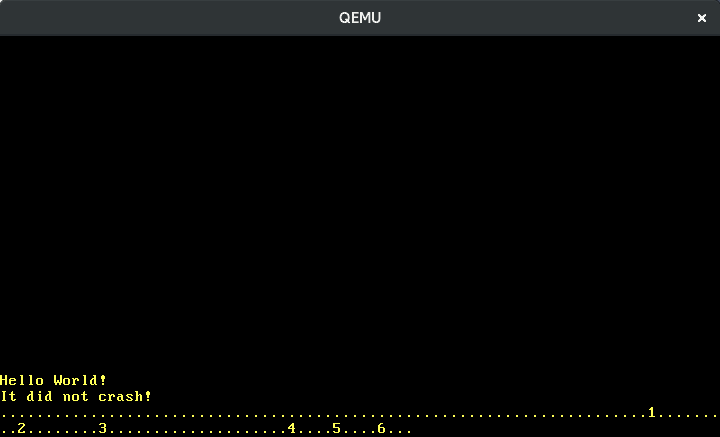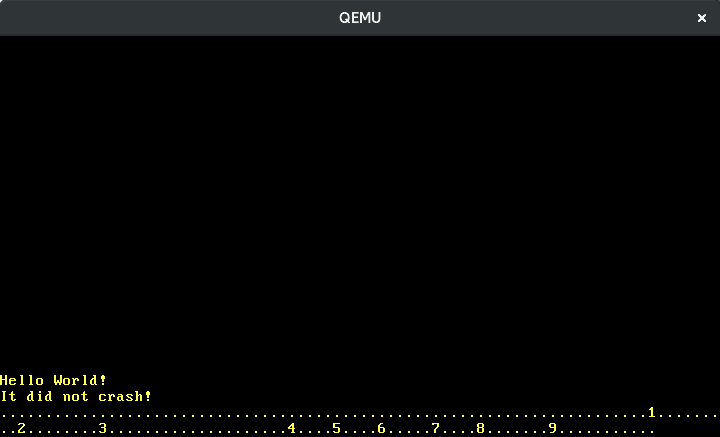
Traducir las otras teclas funciona de la misma manera. Afortunadamente, existe una crate llamada pc-keyboard para traducir los scancodes de los conjuntos de scancode 1 y 2, así que no tenemos que implementar esto nosotros mismos. Para usar la crate, la añadimos a nuestro Cargo.toml e importamos en nuestro lib.rs:
# en Cargo.toml
[dependencies]
pc-keyboard = "0.7.0"
Ahora podemos usar esta crate para reescribir nuestro keyboard_interrupt_handler:
// en src/interrupts.rs
extern "x86-interrupt" fn keyboard_interrupt_handler(
_stack_frame: InterruptStackFrame)
{
use pc_keyboard::{layouts, DecodedKey, HandleControl, Keyboard, ScancodeSet1};
use spin::Mutex;
use x86_64::instructions::port::Port;
lazy_static! {
static ref KEYBOARD: Mutex<Keyboard<layouts::Us104Key, ScancodeSet1>> =
Mutex::new(Keyboard::new(ScancodeSet1::new(),
layouts::Us104Key, HandleControl::Ignore)
);
}
let mut keyboard = KEYBOARD.lock();
let mut port = Port::new(0x60);
let scancode: u8 = unsafe { port.read() };
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
match key {
DecodedKey::Unicode(character) => print!("{}", character),
DecodedKey::RawKey(key) => print!("{:?}", key),
}
}
}
unsafe {
PICS.lock()
.notify_end_of_interrupt(InterruptIndex::Teclado.as_u8());
}
}
Usamos la macro lazy_static para crear un objeto estático Keyboard protegido por un Mutex. Inicializamos el Keyboard con un diseño de teclado estadounidense y el conjunto de scancode 1. El parámetro HandleControl permite mapear ctrl+[a-z] a los caracteres Unicode U+0001 a U+001A. No queremos hacer eso, así que usamos la opción Ignore para manejar el ctrl como teclas normales.
En cada interrupción, bloqueamos el Mutex, leemos el scancode del controlador del teclado y lo pasamos al método add_byte, que traduce el scancode en un Option<KeyEvent>. El KeyEvent contiene la tecla que causó el evento y si fue un evento de pulsación o liberación.
Para interpretar este evento de tecla, lo pasamos al método process_keyevent, que traduce el evento de tecla a un carácter, si es posible. Por ejemplo, traduce un evento de pulsación de la tecla A a un carácter minúscula a o un carácter mayúscula A, dependiendo de si la tecla de mayúsculas (shift) estaba presionada.
Con este manejador de interrupciones modificado, ahora podemos escribir texto:
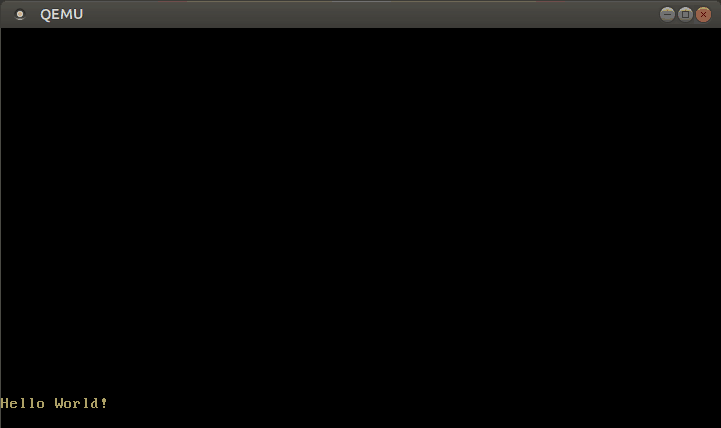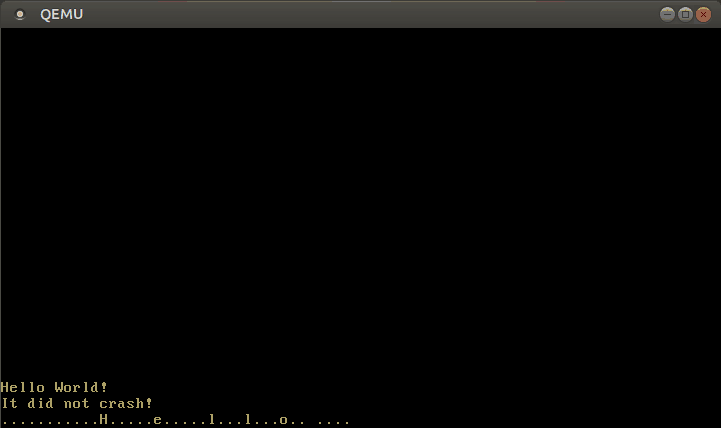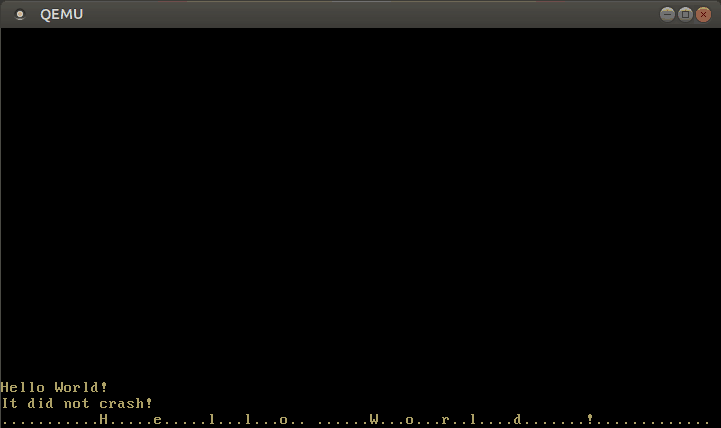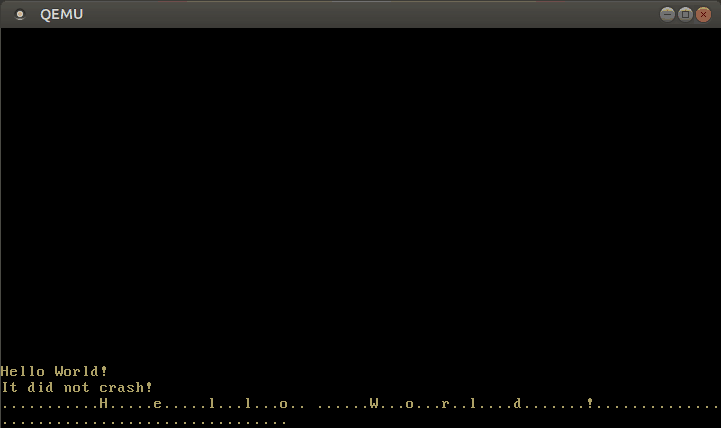
🔗Configurando el Teclado
Es posible configurar algunos aspectos de un teclado PS/2, por ejemplo, qué conjunto de scancode debe usar. No lo cubriremos aquí porque esta publicación ya es lo suficientemente larga, pero la Wiki de OSDev tiene una visión general de los posibles comandos de configuración.
🔗Resumen
Esta publicación explicó cómo habilitar y manejar interrupciones externas. Aprendimos sobre el PIC 8259 y su disposición primario/secundario, la reasignación de los números de interrupción y la señal de “fin de interrupción”. Implementamos manejadores para el temporizador de hardware y el teclado y aprendimos sobre la instrucción hlt, que detiene la CPU hasta la siguiente interrupción.
Ahora podemos interactuar con nuestro kernel y tenemos algunos bloques fundamentales para crear una pequeña terminal o juegos simples.
🔗¿Qué sigue?
Las interrupciones de temporizador son esenciales para un sistema operativo porque proporcionan una manera de interrumpir periódicamente el proceso en ejecución y permitir que el kernel recupere el control. El kernel puede luego cambiar a un proceso diferente y crear la ilusión de que varios procesos se están ejecutando en paralelo.
Pero antes de que podamos crear procesos o hilos, necesitamos una forma de asignar memoria para ellos. Las próximas publicaciones explorarán la gestión de memoria para proporcionar este bloque fundamental.
Comentarios
¿Tienes algún problema, quieres compartir comentarios o discutir más ideas? ¡No dudes en dejar un comentario aquí! Por favor, utiliza inglés y sigue el código de conducta de Rust. Este hilo de comentarios se vincula directamente con una discusión en GitHub, así que también puedes comentar allí si lo prefieres.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Por favor deja tus comentarios en inglés si es posible.